面向突发事件的网络舆情可信度评估及政务微博引导研究*
2021-11-22李一铭徐绪堪王普查
李一铭 徐绪堪 王普查
(1.河海大学商学院 常州 213022;2.河海大学统计与数据科学研究所 常州 213022;3.常州市工业大数据挖掘与知识管理重点实验室 常州 213022)
当前我国处于社会转型的关键时期,致灾因子高度集中,突发事件频发,例如:SARS危机、“8·12”天津港爆炸事故、“6·22”杭州保姆纵火案、2020年的新冠肺炎疫情事件。突发事件涉及的数据呈现容量大、流动快、形态多以及价值密度低的特点[1],为突发事件的快速响应带来巨大挑战。随着网络的快速发展,数据增速变快,利用效率低下,大量的不可信数据因而滋生,影响着突发事件的发展进程,舆情数据的涟漪式传播,不仅会加重原事件带来的后果,甚至会产生一系列的衍生事件,造成对社会的二次影响。
优质的应急情报服务需要保证数据的可信度,因此,本文面向重大突发事件,构建了基于高斯过程分类的网络舆情可信度评估模型。通过追溯数据源计算全局可信度,识别谣言信息,防止因数据失实舆情失控给社会造成严重的损失,并以政府数据共享、公共价值最大化为导向,舆情可信度评估为数据支撑,融合政务新媒体等要素,提出多元协同的突发事件网络舆情引导机制,为提升突发事件响应过程中的情报感知能力提供新思路。
1 国内外相关研究述评
1.1政务微博舆情研究述评随着“互联网+政务服务”的有效推进,政务新媒体在突发事件响应中发挥了重要的舆论引导作用。唐梦斐等[2]以“上海外滩踩踏事件”为研究对象,引入影响力和影响效果两个指标,分析了政务微博在突发事件辟谣过程中存在的问题。王国华等[3]针对“深圳山体滑坡”突发事件,借助社会网络分析法,探讨了政务微博引导舆情走向的联动效应规律。翟冉冉等[4]为研究政府在网络舆情应对中的有效回应方式,从各类突发公共事件情境出发,对政务微博的回应内容进行了编码,分析其特征规律。陈娟等[5]基于政务微博的内容和文本特征,构建了传播效果回归模型,谣言类型、内容长度、信息情感倾向等显著影响着政务微博的辟谣传播效果。张雪梅等[6]引入道格拉斯生产函数和DEA模型,对政务微博舆情数据传播效率评价指标体系的投入、产出指标进行投影分析,研究政务微博传播效率较低的原因。冯小东等[7]从个体参与政务微博传播的微观视角出发,给出了一种基于文本挖掘的度量方法,发现公众兴趣和社会信任是影响政务微博传播效果的重要因素。沈霄等[8]研究了近三年政务微博蹭热点的案例,针对政务微博如何有效利用热点现象,从情感偏向、语言风格、内容属性、立场倾向四维度进行深入剖析。姜景等[9]比较了政务微博和政务抖音信息发布和传播的特征和差异,提出在应对突发事件的舆情时,政务微博和政务抖音应实现矩阵互补、双微联动。邓喆等[10]从疫情响应、议题设置、传播效果、网络交互四个角度,对比了政务微博在疫情防控期间舆论引导的内容特征,探究政务微博的和声共振模式,联合发声、协同响应可增强政务微博的矩阵效应。
1.2网络舆情可信度评估述评近年来,网络舆情数据的可信度评估获得了国内外学者越来越多的关注,研究的视角集中于舆情来源的可信度、传播渠道的可信度,信息内容的可信度[11-12]。舆情数据的可信度评估模型主要基于机器学习、统计分析。滕婕等[13]考虑个体的异质性,构建了基于Multi-Agent的信任识别模型,在网络舆情事件爆发时,对信息主体进行有效的信任识别。张子良等[14]针对数据传播路径中信息缺失的问题,应用数据溯源技术,结合传播路径的用户可信度,构建了PROV评估模型,有效量化微博的可信度。王芳等[15]基于信息生态学视角,引入谣言真实度参数,研究了公共危机谣言与正面信息交互时的真实度衡量问题。A.Farasat等[16]基于社交网络中的数据传播路径,提出了融合多源数据的数据质量计算方法。况湘玲等[17]考虑舆情传播过程对信任权值的影响,构建了多社团复杂信任网络,量化了信任值动态演化的过程。李明等[18]在知识内容、知识来源、用户特征的三个基础维度上,增加了知识反馈、主观感知等维度,完善了突发事件环境下知识可信度的评估指标。李保珍等[19]引入贝叶斯推理模型,对网络信息内容的可信度进行了定量测度。孙鹏等[20]通过结构化分解多媒体情报内容,融合文本、图像、音频等数据形式,构建了面向视频情报内容可信度评估的量化模型,为不同结构的舆情数据可信度衡量提供了新的研究思路。曾子明等[21]将LDA主题模型与随机森林相结合,挖掘文本的深层次语义信息,结合用户可信度和微博影响力特征,较为准确的识别了雾霾事件的谣言数据。
综上所述,政务微博是政府实现精准服务和舆情引导的重要工具,在突发事件的响应过程中,政务微博及时的数据共享,不仅可以有效疏解网民的负面情绪,降低事件演化态势恶化的可能性,还可以释放微博信息的潜在公共价值,提升政府的公信力。目前,舆情数据可信度研究侧重于信息可信度的影响因素分析、可信度指标体系的完善,学者们常常将数据的信度评估转化为分类问题,并不断优化创新分类模型,但模型的准确率和效率还有待提高,大多模型只是识别是否为谣言数据,未能直观的衡量和比较数据的可信任程度。基于此,本文提取突发事件舆情数据的关键词特征、数据源特征,引入高斯过程分类模型,衡量突发事件多源数据的可信程度,快速感知异常数据,并面向政务微博,以精准防控为导向,提出多元主体协同的舆情引导机制,减少谣言的滋生,推进“互联网+政务服务”。
2 考虑关键节点的数据可信度评估模型构建
2.1方法选择高斯过程是基于贝叶斯原理和统计学的机器学习方法,具有容易实现,超参数自适应获取、输出的结果具有概率意义等优点,多用于遥感、工业领域[22]。针对突发事件涉及的数据非线性、高维多源、难以预估的特点,高斯过程分类模型具有较强的适应性[23]。输入数据、数据源特征的各类指标,应用基于高斯过程原理的分类算法,GPC算法(Gaussian Process Classification),可有效识别可信度低的数据,输出概率值衡量数据的可信任度。
高斯过程分类的思想是基于函数空间角度,定义高斯过程用以描述函数分布,并进行贝叶斯推理。根据输入的训练数据集,通过映射函数,将自变量映射到高维函数空间,最后输出自变量属于某类标签的概率值。
2.2基于高斯过程分类的数据可信度评估模型考虑关键节点的突发事件可信度评估模型构建步骤共分为七步:a.确定突发事件的热度话题,构建可信度评估的指标体系,通过网络爬虫,实时获取目标数据。b.提取数据特征,包括主题词、数据的影响力。提取数据源特征,即数据源的可信度衡量指标。c.对数据进行标准化处理,划分训练集、测试集。d.设置初始参数、选择合适的核函数,建立高斯过程分类模型进行评估。e.计算测试数据的可信度概率值,识别谣言数据。f.输出数据的全局可信度衡量值。g.关键节点识别,监测可信度较低的数据大量涌现的节点。具体算法流程如图1所示:
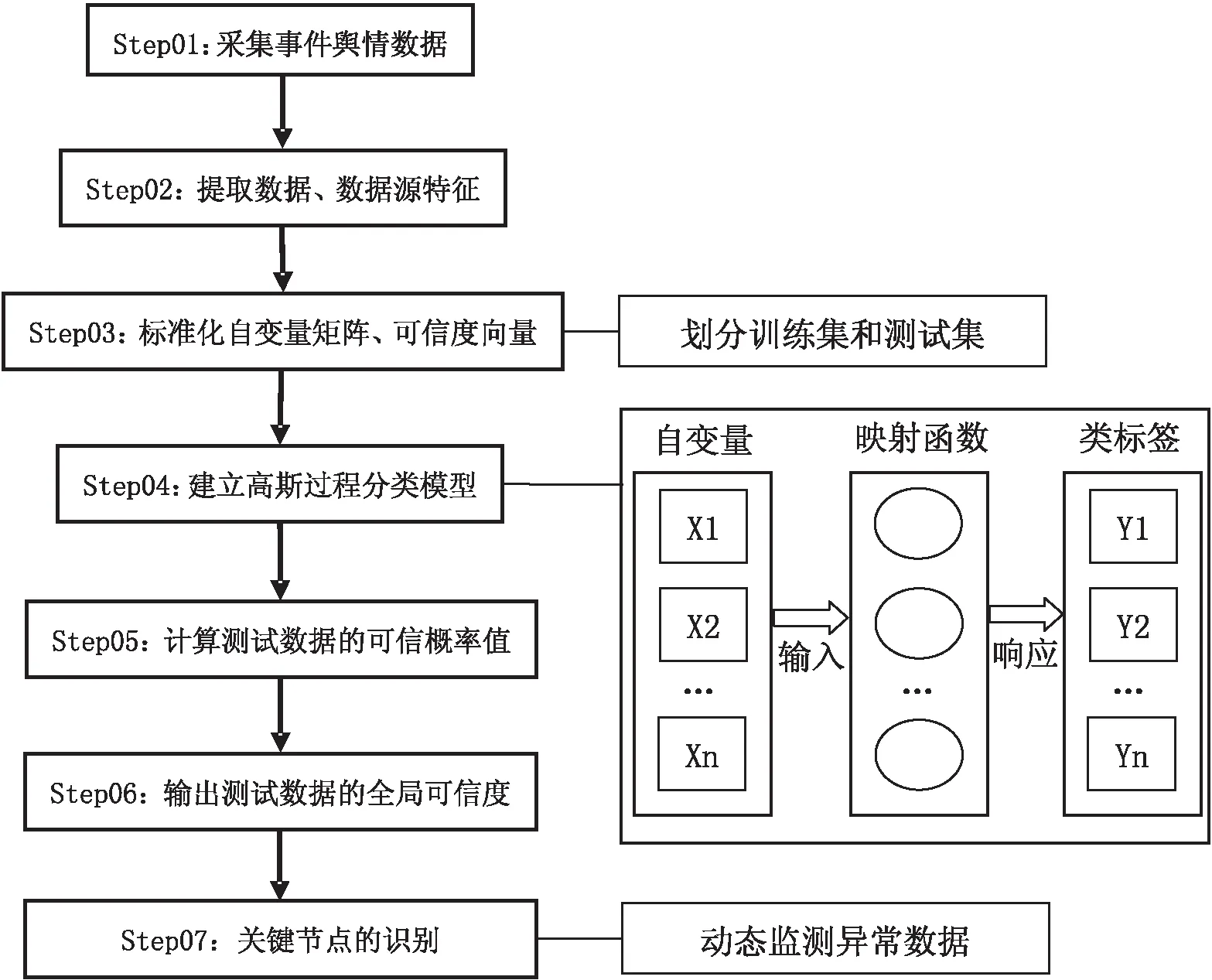
图1 基于高斯过程分类的数据可信度评估流程
2.2.1 提取特征向量
a.构建数据、数据源特征指标。基于新浪微博的数据环境,构建数据、数据源的特征指标体系。数据特征向量包括两大指标,主题分布和数据影响力,数据源的特征向量主要是衡量数据源的专业度、活跃情况。具体如表1所示:

表1 特征指标
b.实时获取目标数据。考虑到数据获取对象、方式、频度等对数据可信度有着一定的影响,以细化数据需求为导向,借助网络数据采集技术和工具,有效的获取目标数据。在微博环境中,确定需要采集的突发事件话题,使用网络爬虫软件,爬取话题下的实时微博数据。一级指标中,主题分布指标由发布微博的文本内容决定,数据源可依赖性指标数据刻画了微博用户的信任特征,短时间内不会有大幅度的变化,因此,考虑爬取数据的时间维度,主题分布和数据源可依赖性两大指标的数据获取采用周期性的方式,频度为每小时更新一次,但数据影响力指标中,微博数据的转发数、评论数、点赞数、传播热度和评论态度需要实时监测,以能够及时预警网络舆情演化过程的异常节点,数据影响力指标的数据获取采取云采集的方式,工作状态为24小时*60min,设置数据采集频度为每分钟更新一次。
c.处理数据,提取特征向量。将爬取的突发事件网络舆情数据进行预处理,删除重复、无关数据,去除停用词,进行文本分词。针对可信度评估的二级指标中,提取主题词特征时,使用LDA文档主题模型,将微博文本数据中出现的最高频率的关键词作为该文本的主题。提取数据影响力特征时,微博数据的转发数、评论数、点赞数由网络爬虫直接爬取获得,数据的创作类型由人工辨别并提取,评论态度的特征提取需要对微博下的评论内容进行情感分析,借助自然语言处理工具包平台,输入评论的文本内容,对态度倾向进行分类,确定情感态度。微博数据源的是否认证、认证类型、微博总数、关注数、粉丝数由网络爬虫直接爬取获得。
综合数据特征指标和数据源特征指标,进行标准化处理。默认情况下,按均值为0,方差为1的形式进行标准化。将所有的特征指标转化为矩阵形式,将可信度设为向量形式。
2.2.2 计算全局可信度 高斯过程是任意有限随机变量的集合,且这任意有限随机变量均服从高斯分布。设数据和数据源的特征指标X和可信度y之间的潜在函数f(x)的先验分布为高斯分布,则可得公式(1),其中,使用极大似然法可估计正定协方差函数的超参数θ,k表示对称且正定的m阶协方差矩阵,Kij=k(xi,xj,θ),k(*)为由θ决定的正定协方差函数。
p(f|X,θ)=N(0,k)
(1)
训练样本集为DataTrain={(xm,ym)|m=1,2,…n},输入数据集为X=[x1,x2,…xμ]T,输出集合为y=[y1,y2,…yμ]T,潜在函数值fm=f(xm)。类标签y为独立分布,基于高斯过程原理的二分类,样本数据x属于类标签y的概率值表示为公式(2)。
p(ym|fm)=Sig(ymfm)
(2)
其中,Sig()为高斯过程分类的响应函数,可将输出值转换为属于某类标签的概率值,基于此,可得到似然函数,如公式(3)。
(3)
由贝叶斯原理可得预测值的后验概率计算公式,如公式(4)。
(4)
将测试数据DataPred代入公式(4),得到对应的预测值的后验概率值,如公式(5)。其中,Xpred表示测试的数据,fpred表示测试数据DataPred的潜在函数值。
(5)
最后,计算预测值fpred所对应的分类预测概率值,如公式(6)。其中,ypred为测试数据的可信度。
(6)
2.2.3 识别关键节点 根据李纲等[24]提出的大数据可信度度量方法,可得以下定义。
定义1 数据源:指在大数据环境下的数据提供者。
定义2 数据:由多个属性构成,记作:data={d1,d2,…dn}。
定义3 可信网络:由数据源实体以及链接数据源之间的有向链路组成的网络。
网络舆情监测区间的分层可信网络演化如图2所示,其中,W={W1,W2,…Wn}为可信度子网集合,可信数据与谣言数据的交互传播,形成不同时刻节点下的可信度子网。Tn时刻数据的可信度网络如图3所示,舆情数据的可信度衡量中,除了与本身的数据特征指标有关,还与发布数据的数据源有着直接关联,在各个有着关联关系的数据源之中,数据通过有向的链路进行传播,形成了一个分层可信网络。

图2 可信网络演化过程

图3 舆情数据传递网络
在突发事件舆论爆发的关键节点,存在着放大效应,且极易滋生大量谣言数据,常有大量的营销账号、网络水军,迅速传播谣言数据,制造可信假象,恶意引导普通用户的情绪,引发舆情爆点,为防止关键节点的失控,基于可信网络,考虑可信数据和谣言数据的交互,通过监测可信度较低数据的浓度来识别舆情演化的异常节点。
3 实证分析
2020年初,全球范围内爆发了新型冠状病毒肺炎,事发突然,疫情快速蔓延。国内各地快速启动一级响应,世界卫生组织将新型肺炎疫情评为国际关注的突发公共卫生事件。本文选取新型肺炎疫情事件验证建立的数据可信度评估模型,具有一定代表性,能为突发事件的高效响应提供支撑。
3.1数据来源从网页版新浪微博中爬取围绕“新冠肺炎”话题下,2020年1月20日至2月15日发布的微博,采集了2 486条数据,包括微博的文本内容、评论文内容,转发数、评论数、点赞数,微博的发表时间,发表微博的用户昵称,用户是否认证,用户关注数、粉丝数、该用户已发微博的总量。
3.2数据和数据源特征向量筛选删除2 486条微博数据中的重复数据、无关数据,根据构建的数据、数据源特征指标整理有效数据,最后得1 000条有效数据。基于R语言环境,调用jiebaR程序包进行分词,调用LDA程序包进行主题建模。计算不同主题数下的困惑度,如图4所示,根据困惑度最小原则,选取主题参数K为8。设置迭代次数G为5000,文档中的主题稀疏性超参数alpha=0.10,主题中的单词稀疏性超参数beta=0.02。超参数alpha、beta与主题参数相互关联,一般情况下,alpha的初始取值接近于1/k,根据输入的数据文档,通过迭代方法更新超参数[25]。
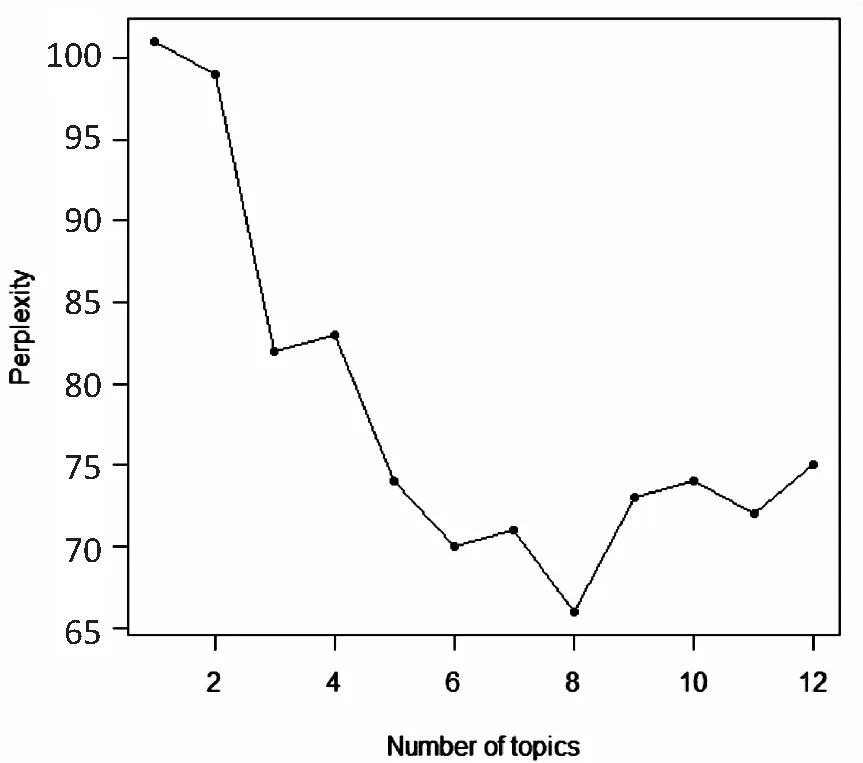
图4 主题困惑度
迭代结束,可得主题分布结果,每个主题取前五个关键词,关键词分布比例情况如表2所示:
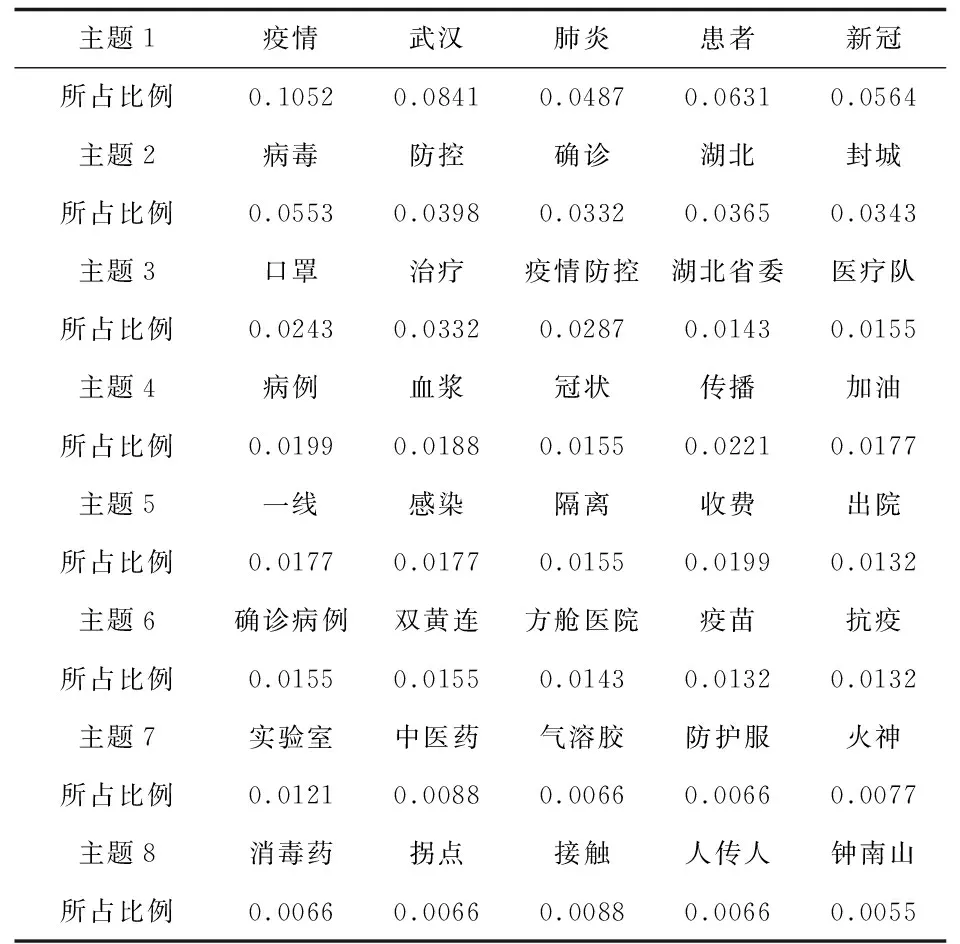
表2 主题分布
3.3全局可信度值以中央网信办违法和不良信息举报中心下的中国互联网联合辟谣平台曝光的谣言信息作为谣言识别的基准,将数据的70%设为样本训练集,数据的30%设为测试集。高斯过程模型的类型参数type设置为分类classification,核函数设置为径向基核函数,即kernel=rbfdot,tol参数为终止条件的容忍度,设置为1e-5,指定cross=5,算法对训练集执行5折交叉验证来评估模型的质量。使用构建好的高斯过程分类模型进行预测,选取部分预测结果展示,并与支持向量机与随机森林模型的分类结果作比较,其中,基于支持向量机和随机森林的两列中,1代表是可信数据,-1代表谣言信息。如表3所示:
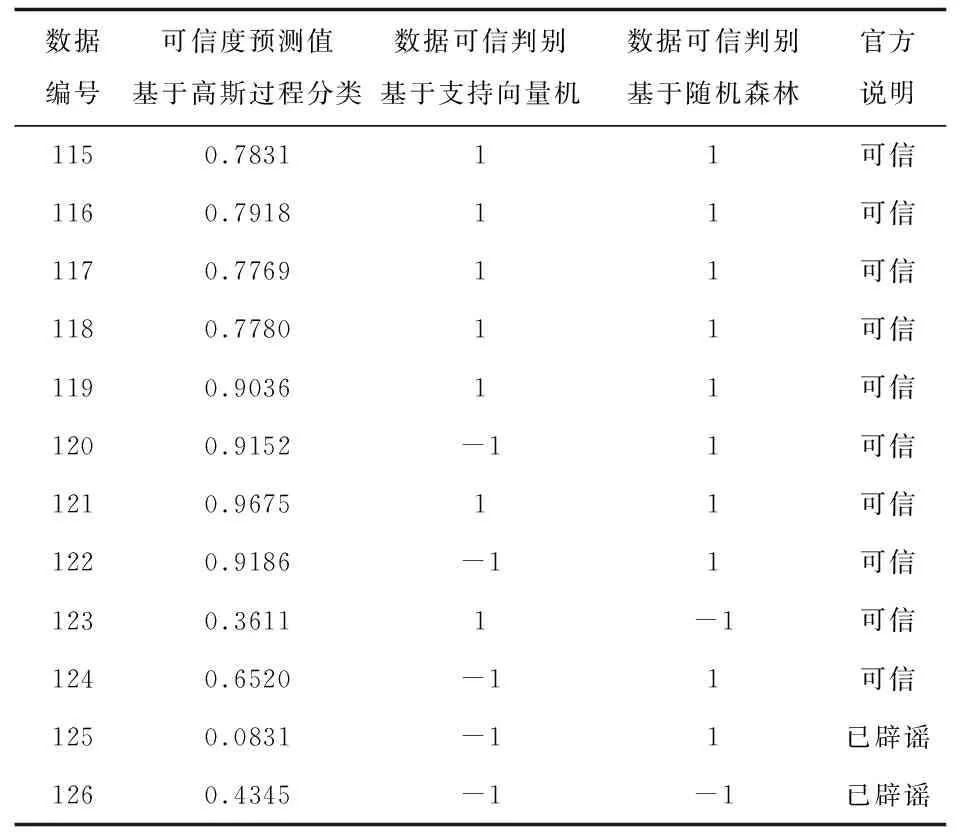
表3 预测结果
在高斯过程二分类模型的预测结果中,概率值低于0.5时,说明数据为谣言数据,概率值大于0.5时,说明数据可信。可信度值大于0.9的数据源大部分为得到微博认证的用户,粉丝数量大,且发布微博的转发数,评论数、点赞数也较多。数据源的影响力在一定程度上决定着数据传播的广度,当影响力越大的用户发布谣言信息时,谣言数据扩散的速度越快,涉及的范围越广,更容易导致网络舆情的失控,造成不可挽回的损失,数据可信度评估模型更应对此类数据进行有效监测。在问题数据中,编号123的微博数据是由官方认证的账号发布的疫情真实信息,用户的注册微博的时间较短,微博总数较少,这类数据源虽然具有较高的专业权威性,但受关注程度低,传播热度低,从而导致模型计算的数据信任度低于了可信标准。相比之下,支持向量机、随机森林这两种机器学习方法虽然也能对突发事件的可信数据与谣言数据分类,但是只是给出了类别,是否为谣言,而高斯过程分类模型可以将预测结果转化为概率,更能直观的衡量数据的信任度,量化数据的可信程度。因此,高斯过程分类模型更适合应用于突发事件数据的可信度衡量,可行度高且能有效监测突发事件舆情数据中的失真信息。
选取监测区间的部分数据,如图5所示,观察可信数据和谣言数据的变化情况,当可信度低于0.5的数据大量涌现时,快速感知异常节点。
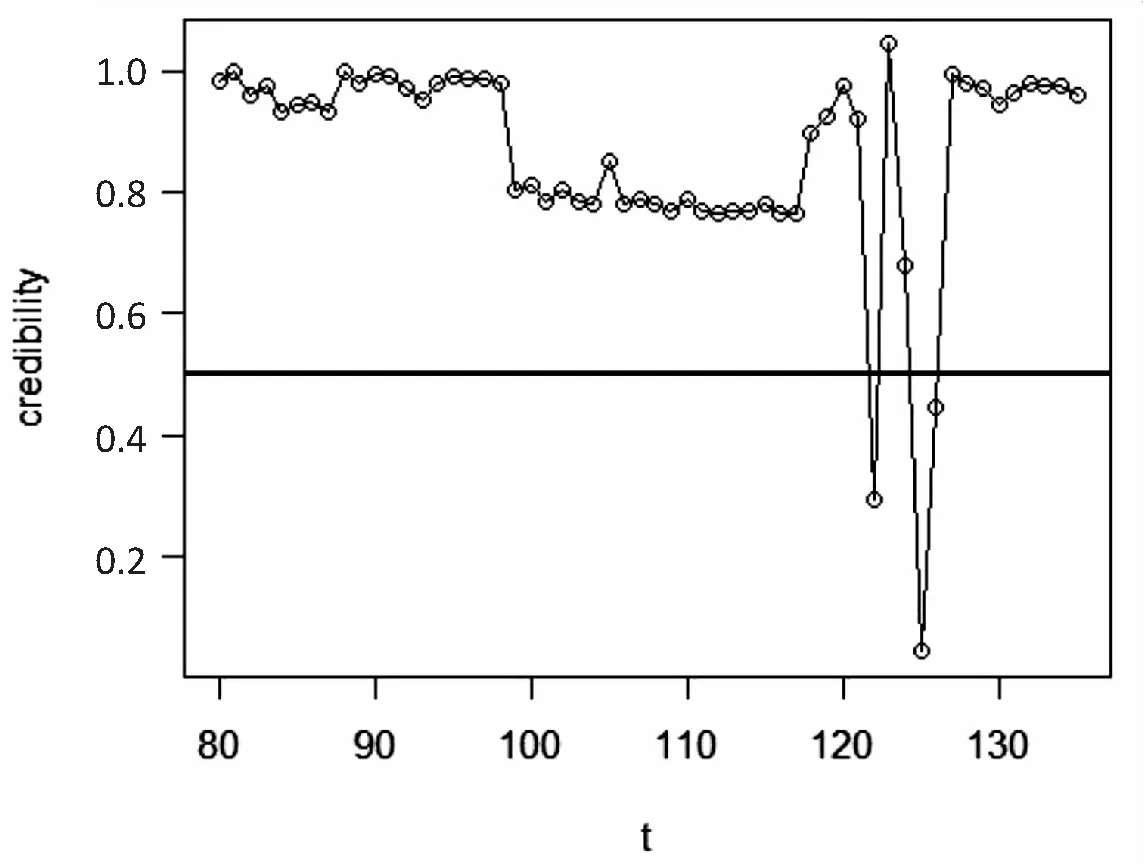
图5 异常节点监测
4 政务微博协同的网络舆情引导机制
重大突发事件情境下,大量的失真数据存在于网络中,尤其是突发事件演化过程中的关键节点,网络谣言极易滋生,网民不良情绪的聚积,若不加以思想引领,会导致舆情的爆发,或引发二次衍生事故等更严重的后果。舆情的引导,需要政府的及时有效的回应,政府权威数据的公布,对化解网络舆情起着关键的作用,随着“互联网+政务”的推进,突发事件的响应更需要政府数据的共享与各部门的协同联动。然而,政府在治理网络舆情中还存在协同机制缺乏、效率低下、数据难以有效共享等问题。作为政务新媒体的“主力军”,政务微博的互动和时效优势突出,在重大突发事件的响应中影响更为广泛[9]。因此,本文以公共价值最大化为导向,构建政务微博联动响应的网络引导机制,如图6所示。

图6 突发事件网络舆情引导机制
围绕“快速有效”的突发事件响应目标,从政务创新的视角出发,以公共价值理论、协同共享理论为理论支撑,为促进政府数据的共享,信息资源的公开透明,融合政务新媒体等要素,构建多主体协同的网络舆情引导机制,引入高斯过程分类等机器学习模型和大数据分析方法,以舆情数据可信度评估为数据支撑,有效辨别网络谣言,同时,实时监测突发事件的情景演化,预测关键节点,基于微博环境,判断情感倾向,通过政务微博发布权威信息,及时疏解群众的负面情绪,防止舆情的爆发给社会带来严重的影响。
政务微博是政府部门与群众互动沟通的媒介,及时共享突发事件的数据资源、发布权威信息进行辟谣,一方面可以抑制谣言的肆意传播,另一方面也可以提高政府的公信力,推进舆情管理的精准政务服务。政务微博参与的网络舆情引导机制强调的是多元协同联动、信息资源的及时共享。突发事件发生后,政务微博除了需要在第一时间作出回应,形成政务微博矩阵式信息传播,还应保证发布的微博质量,发挥政务微博的潜在价值。
5 结 语
应急响应是一个不断及时反馈、多部门协同联动的过程,情报贯穿突发事件的不同阶段,发挥着重要的决策支撑作用,情报的质量决定着应急响应的效果。本文将高斯过程分类引入到突发事件的数据评估中,在突发事件的情境下,基于高斯过程原理,输出舆情数据的可信概率值,量化舆情数据的信任度,动态识别突发事件关键节点的谣言数据,提出政务微博协同的网络舆情引导机制,促进政务信息的共享,为突发事件精准预警和快速响应提供可信度高的数据支撑,有效避免事件误判。下一步研究将侧重探讨数据传播路径中的数据源可信度变化,从数据溯源全程进行突发事件的数据质量控制,促进有价值的应急情报产生,为网络舆情管理提供更加精准的优质服务。
