基于布谷鸟优化轻量梯度提升机的泥石流预测
2021-11-22李丽敏温宗周张明岳魏雄伟
李丽敏, 张 俊, 温宗周, 张明岳, 魏雄伟
(西安工程大学电子信息学院, 西安 710600)
泥石流灾害的发生,常常导致大量人员伤亡和经济损失,对防灾减灾工作提出了严峻考验。国家相关部门和相关单位高度重视这种突发性灾害的预防工作,并分别在空间上对泥石流危险区域进行预测,在时间上对泥石流历时进行预警,以保障人民生命财产安全。
针对泥石流危险区域进行预测是预测预警工作中重要的基础环节。相关学者各有不同的方法和观点,并且随着研究的进行,不断有新的方法和理论,给研究带来活力和新思路。田述军等[1]对研究区降雨状况进行组合,采用Logistic回归分析出不同降雨量对应泥石流的发生情况和等级,但此种研究方法影响因子相对单一,只适用于降雨型泥石流灾害预测。余斌等[2]针对沟床启动型泥石流,有序地分析出地形、地质和降雨条件下的影响因子,建立泥石流预报模型,但对各个影响因子间存在的相关性并没有进行进一步分析,可能导致因子信息相互叠加影响预报精度。周伟等[3]根据当地环境因素,采用Boruta算法筛选出数据中最有价值的两个影响因子作为预测因子,根据Fisher判别法最大化类间差异最小化类内差异从而取得不错的分类效果,然而Fisher判别分析在预测过程中极易陷入局部极值,影响预测准确度。丁桂伶等[4]运用多种自动化监测设备组建自动监测网络,对研究区环境进行实时监测,并总结出多参数联动的思想对泥石流灾害进行综合预测。刘永垚等[5]针对汶川地震重灾区建立随机森林模型,分析出泥石流关键影响因子的贡献率,并得出泥石流空间分布特征,研究结果表明了机器学习算法在地质灾害领域的有效性和可行性。
同时,LightGBM作为一种高效、分布式决策树算法框架,在预测方面不仅快速且具有较强的解释性。徐磊等[6]针对韩城高速公路交通流量,提出经奇异谱分解优化的LightGBM交通流量数据预测模型,并获得较为接近真实值的预测效果。高治鑫等[7]通过贝叶斯优化算法对LightGBM参数进行调优,并将调优后的模型应用于大坝变形预测,取得较好的预测精度和泛化效果。张爱枫等[8]根据数据间的差异,通过卷积神经网络调整相应参数,并采用LightGBM对数据进行分类,从而获得较好的预测精度和相率。
为进一步提升泥石流预测精度,现根据研究区实际状况,提取出降雨量、土壤含水率、岩性、崩滑比、植被覆盖率以及沿沟松散物6种影响因子作为预测因子,避免因影响因子单一导致的预测准确度低问题;采用核线性判别分析(kernel linear discriminant analysis,KLDA)降维算法,对影响因子进行高维变换与分析,解决影响因子之间可能存在的相关性问题;之后,将经布谷鸟算法(cuckoo search,CS)优化算法优化的轻量梯度提升机(light gradient boosting machine,LightGBM)运用于泥石流预测预报中。通过CS算法确定LightGBM模型中存在的超参数,权衡评估点分布,解决梯度提升树算法易陷入局部最优的问题,提高模型预测准确性。最后通过与其他预测算法进行验证对比,体现出模型在泥石流预测中良好的预测能力。以期为泥石流灾害预测方面的研究提供新的思路。
1 KLDA降维方法
线性判别分析(linear discriminant analysis,LDA)作为一种经典线性降维方法,通过非线性映射转换,将低维空间的线性不可分数据映射到高维空间,使原始数据在高维空间变成线性可分。但是在高维空间的样本数据在进行LDA降维时,虽然原始样本已知,但是从低维空间到高维空间的映射未知,所以无法计算两个样本在高维空间的内积。基于以上原因,相关学者引入核函数的思想将高维空间中样本的内积计算对应成为低维空间样本中的核函数计算。所以只需找到适合的核函数就能替代高维空间样本向量内积的计算[9]。而这种将核函数用于线性判别分析的方式即为KLDA。


(1)

(2)

(3)
为选择合适的投影方向,使得投影后类间差异最小化,类内差异最大化。即可得优化目标为

(4)
(5)
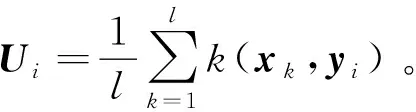
同理可得
(6)
因此J(W)求可变换为

(7)
之后,对J(a)求导,并使其导数为零。即
(aTUa)Va=(aTVa)Ua
(8)
因而,a=V-1(U2-U1)。
新的投影公式为

(9)
式(9)中:ai为a矩阵中的单个样本。降维后的样本及样本集为
di=WTφ(xi)
(10)
D={(di,yi),i=1,2,…,N}
(11)
式中:xi为原始样本集单个样本;di为经过降维后样本集的单个样本;D为降维后所有样本集。
2 LightGBM模型
LightGBM 是一种基于GBDT算法的实现框架,通过构造分布直方图遍历数据,从而不断拟合模型残差,把弱学习器训练成强学习器。同时,LightGBM根据具有深度限制的叶子生长策略进行迭代,在保证预测高精度的同时,大大提高了模型预测效率。
假设经处理后得到具有Q维特征的数据集为
D={(di,yi),i=1,2,…,N}
(12)
式(12)中:di为输入特征向量{di1,di2,…,din}。
首先对模型进行初始化。根据模型损失函数和正则化项得出模型目标函数为

(13)


ft(di)]+Ω(ft)
(14)
式(14)中:ft(di)为模型迭代时形成的新树。
根据泰勒公式对目标函数的误差项进行泰勒二阶展开:
(15)


(16)


(17)
根据不同排列结构,选择出目标函数最小,即最优的树。之后,根据分裂增益公式求解。

(18)
根据计算出的信息增益Gain决定出最佳分裂点和最佳分裂特征。其中,GL、HL和GR、HR为左右节点的一阶导数和二阶导数。最后,若增益为正,则分裂后可提高模型性能,若增益为负,则停止分裂。
经过不断地重复迭代,最终得到决策树模型组合的LightGBM强学习器算法模型:
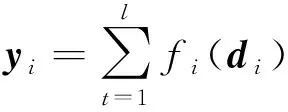
(19)
LightGBM训练框架具体如图1所示。

图1 LightGBM模型训练框架Fig.1 Training framework of LightGBM model
3 布谷鸟优化算法
在应用LightGBM模型解决泥石流预测问题时,需要确定最优超参数[10];因此,选择布谷鸟算法解决算法建模过程中遇到的局部最优问题,对参数进行优化,提高预测精度。布谷鸟算法作为一种仿生智能优化算法,参数少、操作简单并且易实现。其基本思想在于模仿自然界布谷鸟寻窝的习性,通过孵卵寄生的方式实现基因的延续,与传统的遗传算法相比,收敛速度更快,计算效率更高。
首先,将LightGBM中待优化参数作为目标函数f(x)。假设参数初始化群体为
Xi={x1,x2,…,xd}T,i=1,2,…,n
(20)
式(20)中:n为种群规模;d为维度。
布谷鸟寻优搜索的位置和路径公式:
(21)
L(s,λ)~s-λ, 1<λ≤3
(22)
式(22)中:s为由莱维飞行得到的随机步长。
按照式(20)和式(21)的方式更新新一代鸟窝的位置:

(23)
将新一代鸟窝和上一代进行对比,并保留适应度较好的鸟窝作为当代鸟窝:

(24)
采用随机产生的服从[0,1]分布的数值R与外来蛋被发现的概率Pa进行比较。若R>Pa,则改变gt的鸟窝位置,并得到新一组鸟窝位置。
4 仿真验证与结果分析
4.1 研究区概况
鹅项沟坐落于陕西蓝田东南,处于秦岭北部边缘地区,沟地全长约3.7 km,沟顶高达2 100 m,沟口高约1 240 m,地域呈漏斗形,四面环山。由于秦岭北接渭河,连年受到洪流切割,同时在多次构造运动之后,沟谷两侧山体坡度变得极陡峭,山体破碎区较多,大量危险掩体。伴随而来的崩塌和滑坡时有发生,造成沟道中堆积大量山体破碎体,逐步发展成泥石流发生的物源之一。同时,鹅项沟四季冷暖分明,冷气流遇山体阻隔形成暴雨,造成年平均降雨达720 mm,并且主要集中于7—9月天气由暖转冷时节,为泥石流灾害发生提供大量的水资源。在丰富的物源和降雨条件之下,泥石流灾害成为该地区的一大安全隐患[11]。
4.2 泥石流预测总体框架
选取降雨量、土壤含水率、岩性、崩滑比、植被覆盖率、沿沟松散物6个泥石流诱发条件作为泥石流预测原始影响因子。通过对原始数据进行“清洗”和降维处理,从而提高原始数据的预测质量,使数据更加适用于此次预测[12]。最后将处理后的数据作为输入,训练出经CS优化后的LightGBM模型,经过测试得出模型评价结果。具体研究路线如图2所示。

图2 预测路线图Fig.2 Roadmap of prediction
4.3 数据清洗
基于陕西省蓝田县国家重点地质灾害监测项目监测站的历史数据,结合专家经验以及当地环境因素,选取450组泥石流数据作为研究样本。由传感器直接检测到的数据,因自然环境的不可控因素干扰,难以避免地会存在数据的缺失、不统一等现象,非常不利于预测模型的训练[13]。因此,首先对原始数据进行数据清洗,得到标准且连续的干净数据。通过缺失值填补、异常值剔除以及规范化等方式,对原始“脏数据”进行处理,得到标准且规范的“干净”数据。
(1)缺失值填补。若数据集中变量的缺失值超过80%,且特征重要性较低,则直接删除整列;此外,若缺失值在35%~80%范围内,则根据数据分布特点为均匀分布或是倾斜分布,选择均值或中数进行填充;而对于缺失值较少的变量,则一律用众数进行填充[14]。
(2)异常值剔除。根据样本集中不同标签下各列数据观测值与其平均值的距离大小,判断出远离其他对象的异常点。根据异常点的数量和影响程度,考虑是否采用中位数或平均数对其进行替换。
(3)规范化。由于样本集中特征之间存在数值差距较大的情况,在进行数据分析时会影响分析结果。因此需要对数据进行缩放操作,使其值落在一定范围内,便于分析处理。(本文模型属于决策树模型,因此可不用进行规范化处理,规范化主要针对对比实验模型。
(4)针对“清洗”前后的数据,使用CS-LightGBM模型对其进行仿真训练,即可得数据清洗前后结果对比如表1和图3所示。
从表1和图3可以看出,对于“清洗”前的数据,模型增量周期数达到1 400时,模型预测精度才趋于稳定,并最终维持在79.89%。而对于“清洗”后数据,模型增量周期数达到500时,模型预测精度便稳定维持在93.97%,相较于“清洗”前数据,预测精度能更快达到稳定,使模型拥有更好的预测准确率。

表1 数据清洗前后对比Table 1 Comparison before and after data cleaning

图3 数据清洗前后结果对比Fig.3 Comparison of results before and after data cleaning
4.4 KLDA降维
由于样本特征之间并非完全相互独立,而是存在一定相关性,易影响模型预测精度。因此提出KLDA算法对数据进行降维,避免直接分析导致实验结果偏离预期。KLDA作为一种有监督降维方法,在对特征空间进行降维的过程中,会将清洗后的6维特征样本集作为输入,对应样本所产生的泥石流灾害结果作为输入标签,通过训练得出样本特征变量的个体辨识力,如图4所示。

图4 KLDA特征降维Fig.4 Dimension reduction of features by KLDA
图4中,数据集由原来的6维经KLDA处理后降成(y-1)维(y为样本类别)。因实验样本类别为两类,所以数据降维将样本投影至一维空间,大大降低样本复杂度。且降维后特征累计辨识力满足选取精度标准,在避免特征值相互叠加的同时映射出各个特征信息,为模型建立提供合适的数据基础。
4.5 参数选择
LightGBM算法在泥石流预测时需要调优的参数主要包括:学习率(learning rate)、叶子深度(max_depth)、叶子数量(num_leaves)、最小数据数(min_data_in_leaf)4个参数。选择CS优化算法对以上参数进行优化,并对比遗传算法(genetic algorithm,GA)和人工蜂群算法(artificial bee colony,ABC),在相同条件下对LightGBM模型参数进行寻优。3种优化算法对比结果如表2所示。

表2 模型参数优化对比图Table 2 Model parameters are optimized for comparison
为便于观察比较,针对三种寻优算法建立寻优仿真模型,得出3种寻优算法适应度值曲线随迭代次数变化过程,如图5所示。

图5 寻优算法适应度曲线对比图Fig.5 A comparison chart of the adaptability curve of the optimization algorithm
设置3种算法迭代次数均为50次,从图5可知,CS算法相比较于GA算法和ABC算法,能够取得更小的适应度值。CS算法在优化过程中,寻优效率最高,是以上3种算法当中的最佳选择。
4.6 CS-LightGBM模型预测
将经过数据“清洗”、并通过KLDA重构后的数据按照7∶3的比例分为训练集和测试集,同时保证泥石流发生样本和未发生样本均匀分布排列[15]。实验采用LightGBM作为泥石流灾害预测模型,并用CS优化算法对模型中参数最优值寻优。同时,通过在相同条件下与随机森林(random forest,RF)、支持向量机(support vector classifier,SVC)、以及LightGBM模型预测效果进行对比。最后,通过验证集验证得出各个模型预测结果混淆矩阵如图6所示。其各个色块代表含义如表3所示,其中(1,1)为真阳性(true positive,TP),(0,1)为假阴性(false negative,FN),(1,0)为假阳性(false positive,FP),(0,0)为真阴性(true negative,TN)。

1为标签为不发生泥石流样本;0为标签为发生泥石流样本图6 不同模型结果的混淆矩阵对比图Fig.6 Comparison of confusion matrix of the prediction results by different methods

表3 列联表Table 3 Contingency table
此外,通过图6和表3中计算公式即可得出各模型ROC(receiver operating characteristic curve)曲线对比,如图7所示。实验模型的优劣取决于ROC曲线下方面积(area under curve,AUC)值的大小,曲线下方面积AUC值越大,说明模型预测效果越好。各模型具体AUC值如表4所示。

图7 不同模型ROC曲线对比Fig.7 Comparison of ROC curves of different models

表4 4种模型AUC均值对比Table 4 Comparison of AUC mean for 4 models
从表4可以看出,本文提出的CS-LightGBM模型AUC均值为95.4%,相比较于SVC高出8.2%,比RF高出3.8%以及比LightGBM模型高出1.3%。实验对比结果说明,本文CS-LightGBM预测方法相比较于SVM、RF以及LightGBM,具有更优的预测精度和效果,结合LightGBM算法本身高效的预测效率,在泥石流预测中能够取得更好的效果。
5 结论
采用KLDA算法和经过CS算法参数优化的LightGBM建立泥石流灾害预测模型。针对鹅项沟泥石流研究区,分析了泥石流成灾影响因子与灾害发生之间的关系。同时,根据与相同条件下的SVC模型、RF模型以及未经CS参数优化的LightGBM模型进行比较。通过对比验证,证明出选用的CS-LightGBM在泥石流预测方面的准确性和稳定性。具体研究过程如下。
(1)从泥石流形成所需条件出发,根据物源、水源以及地形的特点,监测出不同成灾因子作为模型数据预测因子。在对监测到的数据进行数据清洗的基础上,采用核线性判别分析对数据进行降维处理,将原始6维数据降到1维,减小影响因子之间的相关性,降低模型复杂度,提高模型预测效率。
(2)将梯度提升树在预测方面的高效精准应用于泥石流预测中。相较于传统算法,LightGBM算法具有更高的预测准确性以及泛化能力,在与另外两种算法的比较中,展现出更好的效果。同时选用CS优化算法对LightGBM中的参数寻优,避免模型陷入局部极值,从而进一步提高模型预测准确性。
(3)最后将验证样本集输入预测模型中,得出的ROC曲线和对应点额AUC均值体现出高的准确性和可行性。实验证明该模型的泥石流预测工作是可行有效的,为相关部门在地质灾害预防方面提供了新的思路和方法。
(4)主要针对泥石流在空间分布方面进行预测,而对于灾害发生时间的预测还需进一步开展。同时泥石流灾害形成过程复杂多样,且受地形因素影响巨大,本文提出的模型在实际问题中还需进一步改进与完善,以便更好地应用于泥石流预防工程中。
