结合注意力卷积神经网络的图像检索技术研究
2021-11-22严正怡
魏 赟,严正怡
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
图像检索技术是指按照文本或内容对大规模图像数据库进行检索,从而实现对图像数据库的管理.基于文本的图像检索技术(TBIR)采用人工标注与图像特征相关的关键词,完成匹配.基于内容的图像检索技术(CBIR)采用语义化图像特征,实现特征提取.随着大型图像数据库的出现,在CBIR中发展出基于卷积神经网络(CNN)的图像检索技术,提取特征更准确[1].
研究者们一直致力于提升基于CNN的图像检索技术的效率,提出了多种改进方法.在文献[2]中,Babenko提出适合图像检索的神经编码(Neural Codes),通过PCA压缩和反复训练提升特征提取性能.为解决神经编码空间显著描述弊端,Babenko继续提出求和池化(Sum-pooling)[3]实现卷积降维,Kalantidis提出对图像空间(Spatial)和通道(Channel)加权[4],但检索精度不高.随后滑框技术出现,在文献[5]中,出现了结合滑框和CNN的MOP方法.为了增强局部区域化,Tolias提出利用最大池化(Max-pooling)滑框的R-mac方法[6],Gordo在此基础上加入数据清洗方法[7],提升检索精度.随着越来越多的CNN网络模型出现,研究者们开始对适用于图像检索的模型进行改进,在文献[8]中对比VGG和AlexNet网络模型,得出5.8%的检索精度差,并且加入BN操作得以提升两倍的收敛速度.Qin提出将Encoder和Deep-CNN混合的模型[9],减少检索时间和特征维度.单对模型的改进不足以满足对检索精度和速率的要求,融合注意力模型开始成为研究热点.
近年来深度学习结合注意力模型发展不断,在文献[10]中,Goole Mind团队在RNN上递归使用注意力模型进行图像检索,但在encoder模块中图像压缩过度.为防止过度压缩,Bahanau在将注意力应用到自然语言处理[11]时,决策出与输出相关的输入.随后CNN与注意力模型结合迅猛发展,出现了四种改进模型,基于注意力的Transformer网络结构[12]、基于空间注意力的空间变换网络(STN)[13]、基于通道注意力的SENet模型[14]、基于注意力的可堆叠残差学习网络(RAN)[15],但改进模型效率主要取决于结合的CNN模型.其中效果比较显著的是与VGG模型的结合,在文献[16]中,李将注意力模型融合到VGG网络模型的最后一个卷积层后,提高检索的精度,但效率不高.对于注意力模型与CNN模型的结合还亟待提升,从而达到以更少的能耗实现对检索图像关键位置的映射.本文尝试串行Channel-Attention模型和Spatial-Attention模型,并在池化部分增加Stochastic-pooling池化,从而提升映射效率.
本文提出了改进的注意力卷积神经网络模型(VGG-NA).在基础模型VGG-16上进行改进,VGG-16模型缺少BN层,因此在ReLU计算前加入BN层,使得卷积后特征呈正态分布;为了映射图像关键位置、提升准确率,并行CS-Attention注意力模型,使得卷积后的特征向量得以重构.经过多次卷积和池化,进入替换的Mean-pooling和增加的SP金字塔池化,可以更多保留次要元素、增强通用性;为了弥补之前的时间损失,再进入简化的全连接层,从而提高图像特征提取速度.计算图像相似度,检索出相似度大的前n个图像,此时的新模型效率提高.本文进行大量对比实验,结果表明本文所提出的改进算法优于原算法,在MAP、Recall和检索时间上都得到提升.
2 相关工作
2.1 卷积神经网络模型(CNN)
CNN通过网络模型来提取图像特征,包括图像的色彩、边缘、纹理等,得到图像的特征向量.CNN包含输入层、卷积层、池化层、全连接层以及softmax分类函数[17].其中CNN的核心卷积层输出的特征见公式(1):
(1)
2.2 注意力模型(Attention Model)
注意力模型可以在全局图像中寻找关键的目标信息,忽略无用信息,与CNN结合生成图像显著区.注意力模型分为更关注点的硬注意力模型和更关注区域和通道的软注意力模型,软注意力模型又被分为Spatial注意力模型(STN模型为代表)和Channel注意力模型(SENet模型为代表).本文用到的是改进的串行注意力模型(CS-Attention).
3 算法框架
3.1 基于CNN的图像检索流程
该流程是基于VGG-NA的图像检索流程,用户将图像库中的训练集和验证集进行尺寸处理、去均值、归一化后,统一图像大小为224×224.将预处理完的图像输入VGG-NA模型中进行训练,提取特征、得到特征向量,并记录到图像特征库中.与待检索图像的特征向量进行余弦相似度计算并排序,输出相似度最大的n张图片,检索完成(如图1所示).

图1 基于CNN的图像检索流程
3.2 图像预处理
对图像库数据进行预处理操作,可以使得改进后的VGG-NA模型在进行训练、特征提取的时候更快地收敛,提高检索结果准确率.
1)图像尺寸处理(crop和wrap).本文采用的图像数据库的图像大小为384×256和256×384,大小存在不一致情况,将大小处理成224×224.保持原有的特征,记录尺寸处理比例.
2)去均值、归一化处理.去均值处理,从RGB三维度减去其均值,将图像数据中心化为0,防止拟合,见公式(2).归一化处理,计算RGB最值,将图像数据压缩在0-1之间,提高收敛度,见公式(3).
(2)
(3)
3.3 改进VGG-16模型(VGG-N)
VGG-16模型[18]一共包含13个卷积层(CONV)、5个最大池化层(Max-pooling)以及3个全连接层(FC)和softmax分类函数.其中CONV卷积核大小为33、步长为1,Max-pooling卷积核为2×2、步长为2,所有卷积层隐层的激活单元采用ReLU函数.本文为了提高特征提取的效率,在VGG-16模型的基础上进行改进,提出VGG-N模型,改进如下所示.
1)加入BN层(Batch Normalization).BN层借助变换重构对经过CONV操作后产生的紊乱特征分布进行恢复,从而将CONV操作的输出特征限定为均值为0、方差为1的正态分布,且不破坏原始特征分布.在VGG-16模型中没有BN层,且隐藏ReLU计算,所以考虑在卷积层的CONV操作后添加BN操作.VGG-N模型的卷积操作实际变成CONV+BN+ReLU.本文BN层引入可学习参数γ和β,见公式(4).
(4)
在本文VGG-N模型中BN层一次前向传导过程为:设参数调整样本mini-batch的x值为ζ={x1…m},计算出mini-batch的平均值,见公式(5);计算出min-batch的方差,见公式(6);进行归一化操作,见公式(7);调整均值和方差来得到BN操作的输出结果,见公式(8).
(5)
(6)
(7)
BNγ,β(xj)=yj=γzj+β
(8)
2)替换Max-pooling.本文在Tensorflow框架下,在ILSVRC数据集上采用控制变量法,保持VGG-16模型其余部分不变,对比最后一层池化层Max-pooling和Mean-pooling对检索错误率的影响,结果如表1所示.在表1中当检索返回图像数量为1和5时,后者比前者的错误率低2.2%和1.7%,这就说明Mean-pooling能够降低邻域大小造成的误差、更多保留图像背景,从而提升检索精度,而Max-pooling仅仅偏向于降低卷积参数造成的误差.因此为有效提取到经过最后一层CONV操作的图像全局信息,更多保留pooling层内“次重要”元素,用均值池化层代替最后一层最大池化层,且设定Mean-pooling的卷积核大小是7×7.7×7卷积核在保持VGG-16模型特征提取效果的同时,减少模型参数.此时Mean-pooling的步长为2,池化后输出的中间特征大小由7×7×512变为2×2×512.

表1 VGG-16中不同池化的错误率
3)加入空间金字塔池化层(Spatial Pyramid pooling).图像经过预处理之后,以固定大小为224×224进入CNN模型中.为了增强模型的通用性和鲁棒性,在全连接层前面加入SP金字塔池化层.此时图像以不同大小进入VGG-N模型中,仍可以固定大小进入全连接层,这样增加了模型的鲁棒性.
4)减少全连接层.通过对VGG-16模型各个层对图像特征提取影响的研究,发现越靠近顶层的操作对图像特征提取影响越小[19].同时前两层FC的参数量占比较多,分别是103M和17M,其有效权重都仅为4%,而最后一层FC的有效权重为23%.所以为了减少网络计算量、提升训练速率,删除前两层FC,保留最后一层FC.在后续的实验结果表明,在删除前两层FC之后,MAP提升3.37%的同时,时间损失相比较未删除时得到降低,证明提升有效.此时最后一层FC输出的大小为1×1×1000,整个VGG-N网络的参数量由138M变为16M.
改进后的VGG-N模型一共包含13个卷积层、4个最大池化层、1个平均池化层、1个SP金字塔池化层以及1个FC层.改进后的VGG-N模型并行CS-Attention模型,组合成本文的最终模型VGG-NA.
3.4 串行注意力模型(CS-Attention)
由于通道和空间注意力模型具有不同的功能,所以两个模型的顺序和连接方式可能会影响整体模型的检索性能.因此本文在Tensorflow框架下,通过对数据集ImageNet-1K进行检索,比较附加于基础模型VGG-16上的通道注意力模型(VGG-16+Channel)、串行的先通道后空间注意力模型(VGG-16+Channel+Spatial)、串行的先空间后通道注意力模型(VGG-16+Spatial+Channel)以及并行通道空间注意力模型(VGG-16+Channel&Spatial)的返回一个图像的错误率(Top-1 Error)和返回5个图像的错误率(Top-5 Error),实验结果如表2所示.由表中结果可得,在Top-n等于1和5时,串行的先通道后空间注意力模型的检索错误率最低.同时多注意力模型检索错误率低于单注意力模型检索错误率,串行连接注意力模型检索错误率低于并行连接注意力模型检索错误率.因此,为了达到最佳检索效果,本文注意力模型是由通道注意力模块和空间注意力模块串行组合而成的串行注意力模型(CS-Attention).

表2 不同注意力模型的错误率
3.4.1 通道注意力模块(Channel-Attention)
图像首先进入通道注意力模块,过程如下:
1)中间特征图进入通道注意力后,经过最大池化(Max-pooling)、平均池化(Mean-pooling)和随机池化(Stochastic-pooling)3种池化后得到相同维度的多个具有全局意义的实数.
2)进入共享网络(Shared MLP),减少不同通道的差异性,得到3个MLP操作后的向量.
3)将3个向量各个元素相加组成一维向量,使用ReLU函数激活,变换一维向量元素为0-1,得到经过通道注意力模块的中间向量.
4)通过公式(10)实现对输入的特征图的通道进行加权(过程如图2(A)所示).
通道注意力计算为公式(9)、输出特征图为公式(10):
(9)
其中δ为ReLU函数,V0和V1是共享网络权重.
K′=(Vc(K)+1)⊗K
(10)
其中K为进入通道注意力模块的特征图,K′为通道注意力输出的特征图,VC为通道注意力计算,⊗为矩阵相乘.
3.4.2 空间注意力模块(Spatial-Attention)
将经过通道注意力模块的中间特征图传入到空间注意力模块,过程如下:

2)将输出的3个特征矩阵合成一个,进行Conv操作,得到卷积后的注意力特征图.
3)使用RELU函数激活,得到经过空间注意力模块、范围为0-1的注意力图.
4)通过公式(12)实现对输入特征图的空间加权(过程如图2(B)所示).
空间注意力计算为公式(11)、输出特征图为公式(12):
(11)
其中F为卷积操作.
K″=(Vs(K′)+1)⊗K′
(12)
其中K″为空间注意力输出的特征图,Vs为空间注意力计算.
由通道和空间注意力串行组成的串行注意力模型CS-Attention(如图2所示).

图2 串行注意力模型(CS-Attention)
3.5 注意力卷积神经网络(VGG-NA)
VGG-NA模型由VGG-N模型和CS-Attention模型并行组合而成,其中VGG-N模型(如图3(A)为VGG-N的一个模块)为用于特征提取的CNN基础模型,CS-Attention模型为用于加权的注意力模型,CS-Attention模型被应用于全网VGG-N模型.图像数据集经过预处理进入VGG-NA模型进行训练,池化前的中间特征向量由两部分相乘得到:第1部分是多组CONV+BN+ReLU的卷积操作,其中卷积核为3×3、步长为1;第2部分是CS-Attention注意力模型加权映射.之后送入池化层,包括4个Max-pooling池化层、1个Mean-pooling池化层和1个SP金字塔池化层.最后经过1个FC层和Softmax分类函数,完成特征提取(如图3所示).

图3 VGG-NA模型
3.6 相似性检索算法
本文通过向量表示经训练模型VGG-NA提取的图像特征,因此选取余弦相似度算法(Cosine Similarity)来计算向量夹角的余弦值,比较图像相似度.余弦值越接近1,夹角越接近0,相似度越高.本文相似度算法步骤如下:
1)设经过VGG-NA模型特征提取后的两张图像的特征向量为X=(a1a2a3… am),Y=(b1b2b3… bm);
2)向量X和向量Y的余弦相似度为公式(13):
(13)
3)由于两个向量的夹角在(0,180)度之间,所以余弦相似度计算结果在(-1,1)之间.本文将余弦相似度计算值归一化修正,修正结果控制在(0,1)之间,修正计算公式为(14):
h=0.5×S(X,Y)+0.5
(14)
4)对求得的修正余弦相似度h进行排序,找到前n个相似度最大的图像,即本文检索结果.
4 实验与分析
4.1 实验环境
本文实验运行的操作系统为macOS Catalina,CPU为2.6GHz的6核Intel Core i7,GPU为Intel UHD Graphics 630,内存为8GB,程序的编程语言为Python 3.7,基于的深度学习框架为Tensorflow.
4.2 数据集
本文使用Corel-1000和Corel5K图像集作为实验数据集.Corel-1000一共10类1000张图片,被分为雪山、大海、古罗马建筑、公共汽车等10个语义主题.Corel5K一共50类5000张图片,被分为赛车、战斗机、熊、海滩等50个语义主题.其中4000张作为训练集,500张作为验证集,500张作为测试集.本文所选的图像集中同一个类的图像具有颜色、角度、形状、尺寸和背景等差异,所以图像集检索出的效果具有一定的泛化性.
4.3 评价指标
评价指标使用一种基于排名的评价标准[20].对于本文的图像检索,计算待检索图像特征向量和图像特征库中特征向量的余弦相似度,得到排名前n的图像.检索一幅图像的平均精度(AP)为公式(15):
(15)
其中f(j)为图像库中的n个图像的第j个图像与待检索图像的相似关系,如待检索图像和检索得到的图像标签一致,f(j)的值为1,反之则为0.
对于k次检索,其平均精度均值(MAP)为:
(16)
查全率(Recall)为评价图像检索效果的另一个关键指标:
(17)
其中b为图像库中与待检索图像相似的图像总数目.
4.4 参数设置
本文使用高斯分布[21]随机产生权值,初始VGG-NA网络参数;本文模型加入BN层防止过拟合[22],去除Dropout层;根据本文数据集,设置L2惩罚系数为0.0001;模型mini-batch大小为256、梯度下降动量为0.9,初始学习率(LR)为0.002,学习率衰减为0.9.
4.5 算法对比实验
4.5.1 不同算法MAP对比
利用7种不同的模型进行结果比较,包括4种不同算法比较和3种本文算法提升比较,证明VGG-NA模型改进的有效性.这7种对比算法分别是:SIFT、SVM主动学习、LeNet-5、LeNet-L、VGG-16、VGG-N以及VGG-NA,模型说明如表3所示.

表3 不同的对比模型
本文对比的7种模型中,SIFT算法结合K_means聚类算法,可以实现对小规模简单图像的快速检索,属于传统图像检索算法.SVM主动学习算法借助分类器,利用最大化间隔找到最优的检索目标,速度相对较快.LeNet-5和LeNet-L是CNN模型以及其改进模型,其结构比较简单清晰,参数量中等,是对比其他网络的最佳选择.VGG-16、VGG-N和VGG-NA是本文基础模型及其改进模型,网络层数为16层,参数量超过138million,是本文改进的最佳选择.下面是对于在不同的数据集Corel-1000和Corel5K,这7种模型的MAP随返回图像数的变化趋势.
根据表4可得,对于相同的Top_n,本文方法明显优于SIFT(K_means)以及其他CNN模型(LeNet-5),同时随着返回图像数量的增加,VGG-NA依然可以保持较高的MAP.在数据集Corel-1000中,VGG-NA比SIFT方法的MAP平均提升约12.6%,比SVM主动学习方法的MAP平均提升约16.3%,比LeNet-L方法的MAP平均提升约2.8%,说明本文模型相比较其他模型在MAP上效果明显.再由表4可得,对于数据集Corel-1000,VGG-NA比VGG-16方法提升约3.4%,VGG-NA比VGG-N方法提升约2.3%,这表明本文提出的模型改进对提升精度有效.同时由图4(A)可知,随着Top_n增加,本文和其他对比算法的MAP都在不断的下降,其中SVM主动学习和LeNet-5方法的MAP以大概4.6%的趋势下降,SIFT、LeNet-L、VGG16和VGG-N以大概2.0%的趋势下降,本文VGG-NA方法以大概0.9%的趋势下降,体现了本文方法的泛化性.

表4 不同算法在数据集Corel-1000上的MAP

图4 MAP、Recall随Top_n的变化
为了更近一步验证本文算法改进的有效性,以及对比其他算法的提升,在Corel5K数据集上测试了本文VGG-NA算法和其他算法的MAP.实验结果如表5所示,对于数据集Corel5K上的MAP,VGG-NA比SIFT提升约14.0%,比SVM主动学习提升约18.5%,比LeNet-5提升约21.2%,比LeNet-L提升约3.1%.同时又可得,经过改进的CNN模型能够将MAP提升至80%以上,而基于CNN基础模型或者传统内容的检索算法的MAP相对较低,约在70%.由此验证本文改进后的VGG-NA模型对在不同数据集上提升MAP具有有效作用,相比较同类算法提升明显.

表5 不同算法在数据集Corel5K上的MAP
4.5.2 不同算法Recall对比
在数据集Corel-1000上的Recall实验结果如图4(B)所示.相同Top_n时,本文方法VGG-NA的Recall明显高于LeNet-5、SIFT和LeNet-L.并且当Top_n越大,每个方法的Recall相差也越大,证明本文改进算法的有效性.同时本文还利用实验,探究了MAP随Recall的变化关系,如图5所示.当Recall越高,MAP就越低,两个呈反比趋势.同时在相同Recall时,本文方法VGG-NA的MAP明显高于其他3种方法,且当Recall达到90%时,MAP仍能够保持20%,验证本文算法的性能较好.
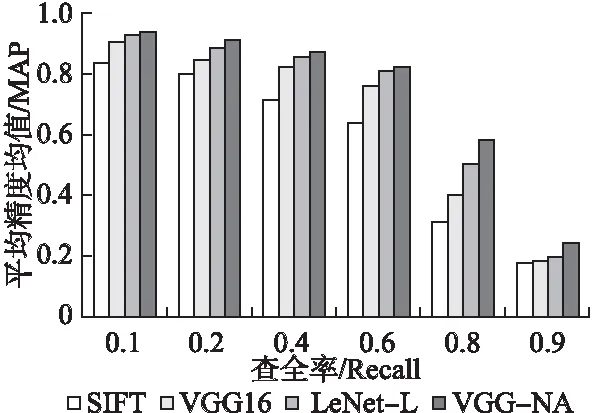
图5 MAP随Recall的变化
4.5.3 不同算法时间对比
本文通过实验将VGG-NA与其他的算法在Corel5K和Corel-1000上的检索时间进行对比,如图6所示.从图6中可以看出,除去检索时间最低、MAP最低的LeNet-5算法,VGG-NA检索时间明显低于SIFT、SVM主动学习和LeNet-L算法,同时VGG-NA相比较其改进前模型VGG16、VGG-N检索速度提升明显,从而验证本文改进对检索效率提升的可行性.本文在增加BN计算、多个pooling层和加权注意力的同时,减少FC层,缩短检索时间.

图6 图像检索时间对比
5 结 论
本文通过改进VGG-16模型得到VGG-N模型,通过改进Attention模型得到CS-Attention模型,并行两个改进模型得到新的模型VGG-NA模型.在相同数据集下,VGG-NA相比较原模型在MAP上提升约3.4%、检索时间上提升约9.4%、Recall突破70%以上,提升明显,证明了本文算法改进的有效性.
本文模型VGG-NA主要有3个创新部分:第1部分是对基础网络模型VGG-16的改进,在CONV和ReLU之间加入BN计算、替换Max-pooling为Mean-pooling、增加SP金字塔池化、简化FC层,得到新模型VGG-N;第2部分是对注意力模型的改进,在串行的空间和通道注意力模型的池化部分加入stochastic-pooling,得到新串行注意力模型CS-Attention;第3部分是将VGG-N模型与CS-Attention模型并行加权融合,重构特征向量,得到本文VGG-NA模型.同时在不同的数据集上,设计对比实验,对比多种算法,证明本文算法改进的可行性,为图像检索提供了一个新思路.之后将会对VGG-NA模型进行更多改进,从而提升准确率和效率.
