面向多源传感事件序列的时序依赖关联挖掘方法
2021-11-22何逸茹杨中国
何逸茹,刘 晨,杨中国
(北方工业大学 大规模流数据集成与分析技术北京市重点实验室,北京 100144)
(北方工业大学 信息学院,北京 100144)
1 引 言
预测性维护的目的是预测设备故障,提前安排纠正性维护,提高工业设备的可靠性.随着物联网的飞速发展,工业设备上部署了大量传感器来监控其健康状况.异常检测技术是预测性维护的重要手段,能够监视来自多变量时间序列的传感器数据或异常事件[1].
单个变量的异常检测被称为“单变量异常”,近些年来,已经有学者进行了广泛的研究[2,3].但是,在实际应用中,挖掘和分析“单变量异常”事件之间的时序依赖关系是一个更值得研究的问题.因为可以从事件间的依赖关系中发现新的异常类型或找到异常发生的根本原因[4,5].
第2节展示了一个“单变量异常”事件中的时序依赖关系的简单示例.实际上,在复杂的工业系统中,异常或故障并不总是独立存在的.由于物理相互作用的模糊性,微小的异常会在不同的传感器和设备之间传播,并逐渐演变为某些设备中的严重故障[6].挖掘此类问题的时序依赖关系非常有价值,它可以帮助提前预测未来的异常或者故障,并识别设备异常和故障的原因.
本文提出一种新的预测异常的方法.首先,从多源传感器数据中检测“单变量异常”事件,并输出异常事件序列.然后,通过识别异常事件序列之间的频繁共现模式,提出一种新的时序依赖挖掘算法.最后在实验中,将挖掘出的时序依赖关系连接起来,形成基于图的异常预测模型.实验结果表明,该方法基于燃煤电厂的真实数据集有效.
2 问题定义
异常事件携带许多有关异常的信息,如发生时间,来源和类型.这里使用一个4元组来描述一个异常事件:f=(timestamp,eventid,sourceid,eventtype),其中timestamp是事件f发生的时间;eventid是事件f的唯一标识符;sourceid是源传感器的唯一标识符;eventtype是异常事件的类型.
表1为一个电厂发生的几个异常事件.来自同一个传感器的事件按照时间顺序构造了一个事件序列Fi={f1,f2,…,fm}.所有事件序列构成事件空间Θ={F1,F2,…,Fn}.这些事件并不是彼此独立的,它们之间有着复杂的时序依赖关系.
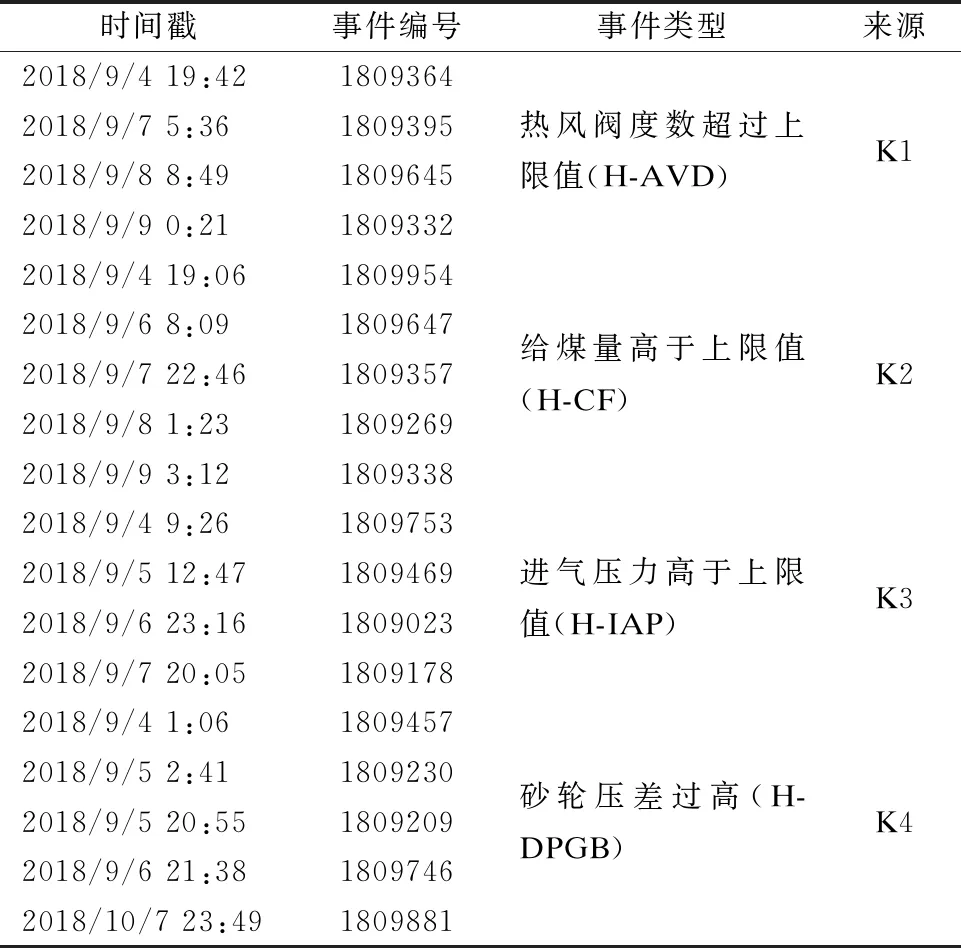
表1 事件信息
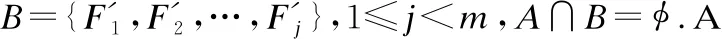
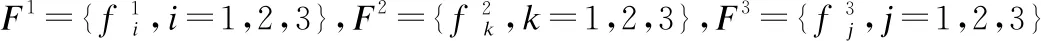

图1 事件序列之间的时序依赖关系
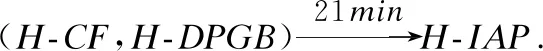
因此,如果可以发现多个事件之间的时序依赖关系,就可以预测异常事件发生的根本原因.
3 时序依赖关系的挖掘
为了从多个事件序列中发现事件的时序依赖关系,提出了本文的框架,如图2所示.

图2 本文方法框架
目前许多研究人员已经研究了单变量事件的检测技术[8].常见的方法包括基于范围的检测方法,异常点检测方法和异常序列检测方法[3].基于范围的检测方法是基于人工经验、传感器和设备的说明书等为单个传感器定义值边界,超出值边界的值被视为异常事件.异常点检测方法将传感器值中与大多数值偏离较大的值定义为离群值[9].异常序列检测方法是找出序列中与其他序列最不相似的子序列[10].利用这些成果,可以从传感器数据中生成异常事件.
挖掘时序依赖关系的主要思想是将时序依赖关系转换为跨多个事件序列的频繁共现模式.本质上来说,时序依赖关系是指在事件集A发生后的时间间隔Δt内发生事件集B的现象频繁发生.换句话说,时序依赖关系是对象和对象之间,在一定的时间间隔内,以频繁共现的模式出现的关系.因此,可以通过挖掘事件序列的频繁共现模式,来发现事件之间的时序依赖关系.
3.1 频繁共现模式挖掘
首先列出一些与频繁共现模式挖掘相关的概念.
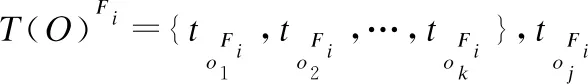
传统的频繁共现模式挖掘算法只关注一组无序对象的出现频率[11,12],不能识别具有时序依赖关系的两个事件集之间的时间延迟.因此设计一个算法来发现有时间约束的频繁共现模式.该模式由两个对象组组成,这两个对象组组内对象无序,组间对象按照时间排序,所有对象之间的时间跨度不超过Δt,这种模式称为跨多事件序列的频繁共现模式.
跨多事件序列的频繁共现模式.对于在一组事件序列l{F1,F2,…,Fl}中发生的共现模式E={Epre∪Epost},当E满足以下条件时,Epre和Epost将形成多维共现模式(Multi-dimensional co-occurrence mode),写成MCM(Epre,Epost):1)每一个对象ei∈Epre∪Epost来自不同的事件序列;2)Epost中的对象总是在Epre中的对象出现之后出现;3)max{T(Epost)}-min{T(Epre)}≤Δt,其中Δt为滞后时间,Epre包含m个事件,Epost包含n个事件,因此,MCM(Epre,Epost) 又可以写成MCMm,n(Epre,Epost).如果在事件序列l{F1,F2,…,Fl}中,MCMm,n(Epre,Epost)出现次数超过k次,则将MCMm,n(Epre,Epost)视为多维频繁共现模式(Multi-dimensional frequent co-occurrence mode),表示为MFCM(Epre,Epost)或MFCMm,n(Epre,Epost).其中,Epre是前因事件,Epost是后果事件,Δt是事件之间的时间差.
3.2 MFCM挖掘算法
本文用γ(A,B)表示事件序列之间的时序依赖关系,用γ(A,B).sup表示在已知A发生的情况下B的发生概率.
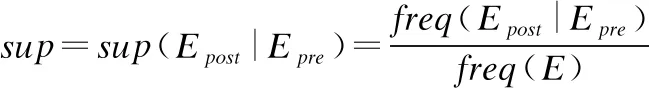
其中,freq(Epost|Epre)是Epost在Epre出现之后出现的频率,freq(E)是E出现的频率.
假设出现阈值freqmin=supmin(supmin为支持阈值),并假设FP是Θ中所有MFCM构造的集合.集合R是所有满足sup>supmin的时序依赖关系集合.对于∀γ(Fi,Fj)∈R,如果有且仅有一个MFCM(Epre,Epost)∈FP与之对应,则Epre和Epost的时序依赖关系为γ(Fi,Fj),反之亦然.同时可以证明,对于∀γ(Fi,Fj)∈R,有且只有一个MFCM(Epre,Epost)∈FP满足γ(Fi,Fj),则γ(Fi,Fj)为Epre和Epost的时序依赖关系.
因此,如果能得到Θ中的所有的MFCM,就可以计算出时序依赖的支持度,并筛选出满足条件的候选时序依赖集.所以,在传统的频繁共现模式挖掘方法的基础上,本文提出了一种“GFE挖掘”方法(Generation-Filter-Extension Mining),该过程分为3个阶段,即“生成-过滤-扩展”的MFCM挖掘方法.
给定频繁共现模式MFCM(Epre,Epost),频数为freq(MFCM(Epre,Epost)),满足freq(MCM(Epre,Epost))=γ(Epre,Epost).sup.如果freqmin=supmin,则对于满足γ(Fi,Fj).sup>supmin的任何时序依赖关系γ(Fi,Fj),都存在freq(MCM(Fi,Fj))≥freqmin,说明MCM(Fi,Fj)是MFCM.因此,对于任何事件f∈Fi∪Fj,它以某种顺序出现的次数都满足freq(f)≥freqmin.因此,挖掘MFCM的第一步是找到所有出现次数超过freqmin的事件,表示为F1.该步骤与频繁共现模式挖掘的传统方法一致.
根据以上分析,事件集和目标事件集中任何支持度大于事件关联阈值的事件,只能由F1中的事件组成.因此,可以组合F1中事件集和目标事件集中的事件,然后过滤得到支持度大于事件时序依赖阈值的事件.
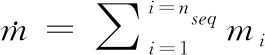
因此,基于以下定理,设计一个扩展策略来避免这个问题.

根据定理,可以推断出对于任何γ(Fi,Fj)(支持度超过阈值),假设|Fi|>1,|Fi|>1,可以通过扩展一些MFCM({εα},{εβ})(εα∈Fi,εβ∈Fj),来得到MFCM(Fi,Fj)的γ(Fi,Fj).
将F1中的事件组合成({εα},{εβ})的模式,然后验证该模式是否满足γ({εα},{εβ}).sup≥supmin,并过滤得到支持程度超过阈值的时序依赖关系MFCM({εα},{εβ}).然后选择F1中的剩余事件来扩展MFCM({εα},{εβ}) 的前因事件和后果事件.同时,验证前因事件和后果事件的时序依赖支持度是否大于阈值.
基于以上阶段,挖掘全过程如下:
·计算每个序列中事件的发生次数freq(e),如果freq(e)>freqmin,则将对应的事件插入F1;
·将F1中的事件组成如 ({εα},{εβ})的模式,保留满足条件({εα},{εβ}).sup≥supmin的模式,即MFCM({εα},{εβ});
·选择F1中的剩余事件分别扩展所保留模式的前因事件和后果事件;
·重复过滤和扩展阶段,直到过滤结果为空或扩展了F1中的所有事件.
算法1是挖掘时序依赖关系的伪代码.
算法1.GFE挖掘算法
输入:Θ:包含多个事件序列的事件空间
δt∈[Δtmin,Δtmax]:时间滞后跨度
supmin:支持度阈值
输出:R:Θ中所有的时序依赖关系
1. for eachseqi∈Θ //生成阶段
2. put the events intoF1//出现次数超过supmin的事件;
3. for eachεα,εβ∈F1
4. initialize theFi={εα},Fj={εβ} andP=φ;//P是 MFCM
5. if(isMFCM(Fi,Fj,δt))//过滤阶段
6.P←TFCM(Fi,Fj);
7. for eachε∈F1&&ε>Fi//ε大于Fi
8. extend(Fi,ε,δt);//扩展阶段,扩展前因事件
9. for eachMFCM(Fp,Fq)∈P
10. for eachε″∈F1&&ε″>Fj
11. extend(Fq,ε″,δt);//扩展后果事件
12. For eachMFCM(Fu,Fv)∈P
13.R←(Fu,Fv,MFCM(Fu,Fv).Δt,MFCM(Fu,Fv).freq);//P中MFCM的前因事件和后果事件构成集
14. returnR;
15. isMFCM(Fi,Fj,δt)://判断Fi和Fj是否以δt为条件构造MFCM(Fi,Fj);
16. if(MFCM(Fi,Fj).Δt=max{MCM(Fi,Fj).Δt}&&MFCM(Fi,Fj).Δt≤δt)
17. return true;
18.extend((Fi,Fj),target,ε,δt):

20.Fi←ε;
22.Fj←ε;
23. IF(isTFCM(Fi,Fj,δt))
24.P←TFCM(Fi,Fj);
25. for eachε′∈F1&&ε′>Fi
26.extend((Fi,Fj),target,ε′,δt);
GFE挖掘算法:首先从事件空间Θ中找出发生次数超过supmin的事件,并将其放入F1(第1-2行).然后,将任意两个事件以模式(εα,εβ)来建模,并验证该模式是否为MFCM(第3-6行).然后使用extend()函数(第18-26行)递归地扩展MFCM1,1的前因事件(第7-8行).直到扩展的模式不是MFCM或者F1中没有对象可以扩展时,扩展过程中断.然后再使用extend()函数递归地扩展MFCM1,1的后果事件(第9-11行).最后,将所有的MFCM放入集合P中,P中前因和后果事件之间的事件关系构成集合R.
4 实验与评价
4.1 实验环境与数据
本节用实际电厂生产中的真实数据集,来验证本文方法的有效性.
实验是在装有4个Intel Core i5-6300HQ CPU 2.30GHz和16.00 GB RAM的PC上完成的.操作系统是Centos 6.4.所有算法均使用JDK 1.8.5在Java中实现.
实验数据详细信息见表2.在8个设备上总共部署了357个传感器.每个传感器每秒生成一条,记录.

表2 实验中的真实传感器数据
数据集分为训练数据集和测试数据集.训练时间为2018-11-01 00:00:00-2019-04-28 23:59:59.测试时间为2019-05-01 00:00:00-2019-05-31 23:59:59.
使用2018-07-01 00:00:00-2019-06-30 23:59:59电厂电力维护记录中的实际故障来做验证实验.
4.2 实验过程与指标
首先对训练集进行挖掘,找出时序依赖关系,得到从训练数据中挖掘出的的时序依赖关系数量(TDQ).在不同的参数和不同的数据集时间下,观察TDQ的变化趋势.
然后,选择和连接挖掘出的时序依赖关系,建立异常事件的有向图预测模型.该图定义为G=
当一个异常发生时,首先使用BFS算法[13]对图进行搜索,找到与之直接或间接连接的邻域异常事件.输出一组异常事件的预测.
基于异常预测图,将异常预测模型与基于距离的异常检测方法和离群点异常检测方法两种典型的方法进行了比较.采用以下性能指标对实验进行评估.
时序依赖关系数量(TDQ):从数据集中挖掘出的时序依赖关系的数量;
警告时间:警告时间是一个方法对一个故障发出维修警告的时间戳与该故障发生的时间之间的差;
准确率:对照故障记录,精度表示有多少异常是准确的;
召回率:召回率代表有多少正确的故障被预测出.
4.3 实验结果与讨论
4.3.1 不同参数的TDQ
首先研究关键参数supmin和时间阈值Δt是如何影响时序依赖关系数量的.
对于不同的supmin和Δt值,使用时序依赖挖掘算法对训练数据集进行挖掘,并计算TDQ.其中,supmin的值设置为:supmin∈{0.5,0.6,0.7,0.8},Δt的值从5min增加到60min.图3展示了不同参数下TDQ的平均值.
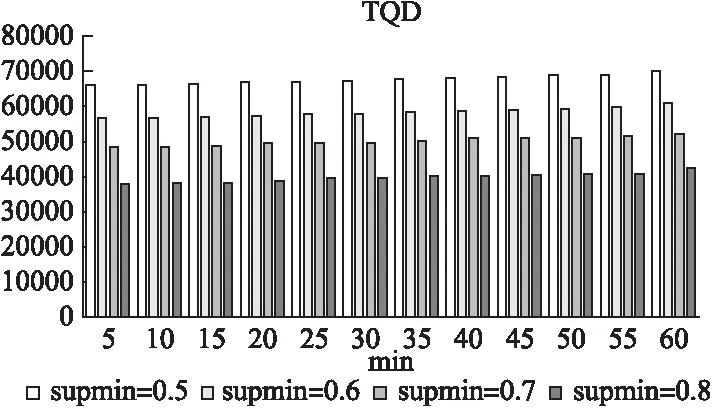
图3 不同参数下TDQ的实验结果
从图中可知,TDQ的平均值是随着supmin的增加而降低的.正常情况下,在每一个Δt值下,相邻的supmin值之间的降数有一个增长的趋势.异常情况下,递减数在supmin=0.6-0.7之间达到最小值.此外,对于每两个相邻的值的supmin,随着Δt的增长,递减数略有增加.
从图中还可以看出,平均TDQ是随着Δt的增加而增加的.相邻的Δt值之间的升序值总体上变小.在每个supmin的值下,升序值的峰值出现在Δt=10min-15min之间.最小值可能出现在Δt=55min和60min之间,Δt=50min和55min之间,或者Δt=40min和45min之间.
然后进行实验来验证当参数supmin=0.8,Δt=35min时,在不同数据量和不同的时间范围里,TDQ值是如何变化的.数据量从1个月递增到6个月的数据集,每次增加1个月.本实验以不小于0.8的概率(即supmin=0.8)挖掘时序依赖关系.表3显示了TDQ的结果.

表3 不同数据量下TDQ的实验结果(supmin=0.8,Δt=35min)
表3显示,随着数据集大小的增加,总TDQ也呈上升趋势.但是,TDQ与数据集大小之间没有线性相关性.数据集的规模从1个月上升到6个月,产生的TDQ相对接近,总是在4000到5000之间.结果表明,随着时间的推移,TDQ缓慢上升,并且可以控制在一定范围内.原因在于,随着时间的推移,时序依赖关系的种类逐渐增加,但增长速度是稳定的.结果表明,该算法具有一定的鲁棒性.
4.3.2 不同方法的对比
表4为不同方法的异常预警时间的实验结果.通常,基于范围的检测方法最先发出警告.因为如果传感器数据超出一个范围,故障会立即发生.但是,有些故障是由多个不超过范围的异常形成的.因此它大多数时候都没有发出预警.
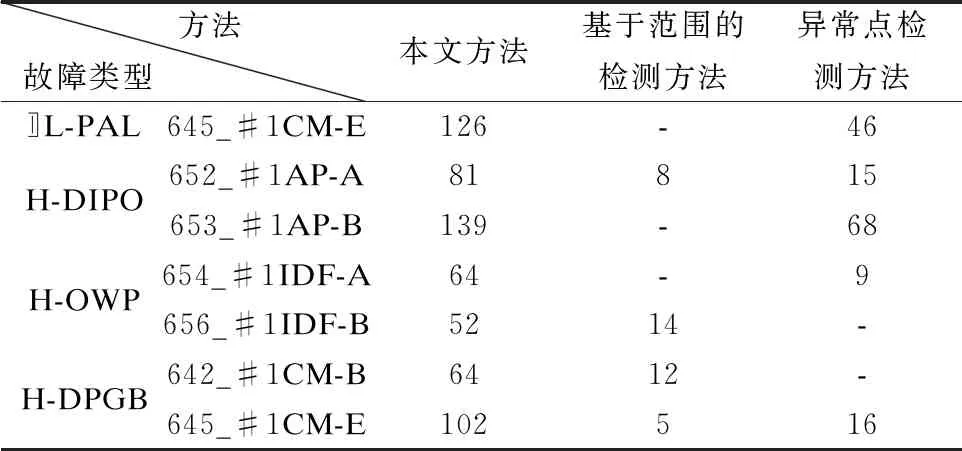
表4 异常预警时间(单位:分钟)
异常点检测方法有时也无法发出警告,因为该方法不能检测出传感器数据缓慢地上升或下降的这种异常行为.另外,如果传感器数据序列具有类似的子序列,当数据突然下降时,异常序列检测方法无法检测出此类子序列.
此外,还比较了不同方法的准确率结果和召回率结果(本文只考虑在训练集和测试集中都发生最终失败的预测事件).
由图4可以看出,本文方法在这3种方法中达到了最高的准确率和召回率.准确率和召回率分别为89.87%和83.67%.不准确的部分一方面是由于训练过程中挖掘出的一些异常传播路径在测试集中无法检测到.另一方面,由于流数据的不确定性,对于同一类型的故障,测试数据集中挖掘出的异常传播路径与训练集相比发生了变化,因此没有检出.
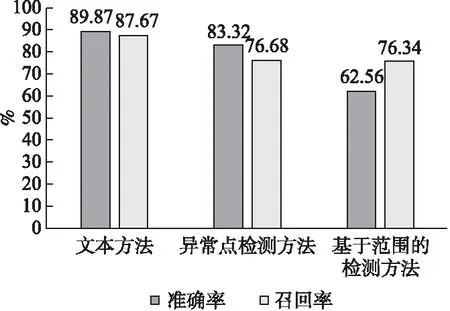
图4 不同方法下的准确率和召回率实验结果
基于范围的检测方法和异常点检测方法的准确率分别为62.56%和83.32%,召回率分别为76.34%和76.68%.这两种方法都是基于单传感器数据的检测方法.无法检测出由多个异常引起的故障.而本文方法能发现多个传感器之间的相关性,形成异常传播路径,发现更多的隐藏异常.
以上结果表明,时序依赖关系在构建故障预测逻辑和故障检测中有着有效的作用.
5 相关工作
近年来,研究人员已经提出了多种方法来解决预测性维护中的异常预测问题.目前,一些学者提出了几种定量模型,包括简单的线性判别分析,更复杂的逻辑回归分析和神经网络[14].文献[15]提出了一种基于LSTM神经网络预测IT系统故障的系统,该系统可自动分析流式控制台日志并检测预警信号.文献[16]提出了一种基于Spark平台的并行KNN异常检测算法,提高KNN算法在大规模数据上的异常检测效率.文献[17]提出一种基于深度信念网络的高维传感器数据异常检测算法,该方法首先将原始数据降维,然后将QSSVM(Quarter-Sphere Support Vector Machine)与滑动窗口模型相结合,实现了在线的异常检测.文献[18]提出了一种利用短时傅立叶变换(STFT)对传感器信号进行预处理的方法.
上述工作对于单变量异常的检测具有良好的效果.但是,越来越多的物联网应用,特别是工业生产,需要分析和识别异常的根本原因,而这些方法并不能从根本上解决问题.
挖掘时序依赖关系为识别异常之间的因果关系提供了重要线索.从实际问题出发,研究人员归纳并研究了几种依赖模式挖掘任务.Song等人挖掘活动依赖项(即控制依赖项和数据依赖项),当事件日志无法满足完整性标准时能发现流程实例[4].但是作者没有考虑事件之间的依赖关系.Plantevit等人提出了一种基于区间的事件流之间的时序依赖关系挖掘方法[5].
6 结 论
本文提出了一种基于多源传感器事件序列时序依赖关系挖掘的异常预测方法.首先,从多源传感器数据中检测“单变量异常”事件,并输出多源传感器事件序列.然后,将时序依赖关系挖掘问题转化为频繁共现模式挖掘问题.然后,选择和连接挖掘出的时序依赖关系,建立异常事件的有向图预测模型,并通过大量的实验验证了该方法的有效性.未来将研究并行优化算法,来加快本文方法.
