一种基于核典型关联分析的短语音说话人嵌入向量算法
2021-11-22瞿于荃
龙 华,瞿于荃,段 荧
1(昆明理工大学 信息工程与自动化学院,昆明 650000)
2(昆明理工大学 云南计算机国家重点实验室,昆明 650000)
1 引 言
硬件设施的更新迭代加速模式识别这一大领域的发展,图像,文本,语音领域的技术得到突飞猛进的进展.作为信号处理和语音处理领域一个重要分支,许多声纹研究者开始触碰说话人识别这一领域.文本相关方向的说话人识别已初出茅庐,得到了大多数群众的认可和使用,并且有关文本相关的具体技术也已商业落地,比如小度,Siri,Ok google等.它们的出现使得人们的生活更加便利和畅通,人们渐渐离不开说话人识别技术的广泛应用,说话人识别技术也正在便捷人们的生活.而作为另一个方面的文本无关的说话人识别有仍许多挑战未解决,尽管已在有关技术在公安机关实现运用并落地,正在进行着追捕漏网犯罪嫌疑人的声纹识别工作,但面对复杂环境下,传统基于统计的说话人模型全局变异空间的鲁棒性有待商榷.如今的文本无关的说话人识别正面临着噪声干扰,多收集信道以及短语音等等的挑战.短语音问题[1]一直是让研究员犯难的问题之一,由于现实环境中,从目标说话人端收集语音信息较难,说话人也不可能对着收集设备一直注册几十秒甚至是几分钟的时间,而对于一个生物识别技术的考验之一,便是便捷性,时效性.相较我们熟悉的虹膜以及人脸识别等这类的身份识别技术,虽然说话人识别有着自身的优点,但短语音似乎是现阶段基于文本无关的说话人识别最需要解决的阻碍的其中之一,这也成为说话人识别一系列技术能够商用的关键步骤.
针对短语音这一重要难点问题,研究人员早在二十一世纪的初期就展开了探索.高斯混合模型的提出代替了矢量量化[2]方法,但因为训练每一个说话人的高斯模型都需要大量的目标说话人语料去拟合,这无疑增大了训练说话人模型的难度.通用背景模型[3]的提出解决了这一问题,用一个通用数据集预训练通用说话人模型,随后只需要相对少量的样本即可适应得到每一个目标说话人模型.随后的因子分析方法将说话人模型分别按照说话人身份差异空间和信道差异空间分别建模,但需要估计和计算的量过于偏大.2011年,Kenny P等人将说话人差异空间和信道差异空间共同建模,提出全局变异空间的概念,从中提取出固定维度的说话人embedding向量,i-vector[4].可以说,i-vector的出现将基于统计模型下的说话人识别技术推向了高潮,而高性能的i-vector也成为近十年来许多世界级说话人识别挑战赛上的基线系统.i-vector虽然简单并且计算量小,但在面对不同注册和测试时长下,也出现了在短语音条件下识别性能急剧下降的情况,说明说话人信息的不足直接导致了对语音后验概率估计的不足,针对这一点,王铮[5]等人利用加入历史测试语音信息和通用背景模型的参数信息增强说话人信息,孙念[6]等人提出了多特征的声学特征增强i-vector的方法,周萍[7]等人提出基于伽马通倒谱系数的特征融合方法,但是从声学特征的融合来说,只能改善短语音环境下的说话人识别性能,对于不同时长和环境不匹配的鲁棒性来说,并不能从根本消除短语音所带来的影响.
深度学习中各式各样的网络层出不穷,语音识别最早掀起深度学习的浪潮,深度神经网络的应用让识别率得到的提升.学者们将目光放在了说话人识别上面,google最早应用的基于深度神经网络框架下的说话人识别[8]成为第一个纯正使用深度学习并且完全抛开传统说话人框架的模型.初次尝试深度学习让研究人员尝到了大量语料库堆叠下的甜头,各式各样的深度框架随即应用在说话人识别上,至此说话人识别技术由此进入一个崭新的时期.结合深度学习,王昕[9]等人提出利用DNN输入带噪语音增强i-vector鲁棒性.另外,人们利用深度学习可以抛去传统的物理声学特征,将深度神经网络看作是一个提取器,比如酆勇[10]等人提出从高斯伯努利受限玻尔兹曼机中提取说话人非线性特征,田垚[11]等人提出基于深度神经网络的瓶颈特征的提取,突破传统声学特征的束缚.模型结构上,各式各样层出不穷.2018年,Amirsina[12]等人提出的3D-CNN网络首次提出说话人话语级特征这一概念并将CNN代替DNN作为说话人模型,同年,snyder[13]等人利用时延神经网络对帧级信息进行整合成为话语级信息,提取embedding向量x-vector,成为近几年短语音说话人识别技术上的热点.
本文针对短语音环境下,说话人时域信息较少导致说话人识别性能不足的问题,提出一种利用核函数关联分析方法融合说话人嵌入向量的算法,旨在融合深层次说话人嵌入特征,以此增强短语音环境下说话身份信息,由此提高说话人识别等误差率和最小检测代价.
2 全局变异空间模型
联合因子分析对一段语音中包含的信息进行了分析:说话人的信息大部分都蕴含在每个人的高斯均值超向量内,而利用全局变异空间的方法建模对每个人的高斯均值超矢量做出了很好的表达:每个人语音中所蕴含的信息可以被两部分表示,分别是话者自身固有表达自身身份的信息以及才收集话者语音时不同采集设备带来的信道和环境噪声两部分组成,具体的表示:
M=m+Tω
(1)
上式中,T是代表全局变异空间的变换矩阵,即T矩阵,而M作为某个说话人一句语音中的高斯均值超矢量被分解为一个与特定说话人和信道无关的通用背景模型均值超矢量m以及在T矩阵上进行投影所得到一个固定低维向量,我们称之为全局变异空间因子向量ω,该向量是包含了整段语音中说话人和信道信息,而这就是身份向量i-vector.i-vector模型技术的重点就是全局变异空间矩阵的估计和i-vector的提取.
2.1 全局变异空间矩阵的估计
全局变异空间矩阵的估计方面,首先需要提取鲍姆威尔琦(Baum-welch,BW)统计量,接着在E步计算全局变异空间隐变量因子的后验分布,M步最大化T矩阵,经过迭代多次直至停止,最后得到全局变异空间矩阵.而上述的基础条件是我们已经用一个无关背景的数据集训练好了通用背景模型的情况下.给定第s个说话人的第h句话语,有若干帧{Y1,Y2,Y3,…}所组成,那么对于每一个高斯分量c,我们需要计算它的零阶,一阶BW的统计量如下:
(2)
(3)
其中mc是第c个高斯混合模型的分量所对应的均值矢量,对于t时刻,γt(c)的意思则是在t时刻Yt语音分布落入第c个高斯模型状态的后验概率,如下式计算:
(4)

E步:对于第s位话者的第h句话语有:它的身份向量i-vector的表示记作ωs,h,并令l(s)=I+TTΣ-1Nh(s)T,则:
(5)
(6)
M步:接着我们需要更新参数矩阵和最大化似然函数值,参数矩阵如下:
(7)
(8)
这里为T矩阵迭代便捷,φ,φ是推导得出的更新步骤的结论,记高斯混合度为c=1,2,…,C,提取的特征参数维度f=1,2,…,P,令i=(c-1)P+f,式(9)所需要估计的矩阵,按照行来进行估计,Ti表示T的第i行,φi表示φ的第i行,则说话人全局变异空间矩阵T的更新公式如下:
(9)
2.2 身份向量的提取和分析
训练完T矩阵后,通过测试集和注册集语音,我们就可以利用式(5)得到每个说话人对应的身份向量i-vector.从2.1节所示,话者的身份向量i-vector的提取与T全局变异矩阵的训练有着密不可分的关系,倘若我们进行注册和测试的话语能够为我们提供充足的γt(c),那么全局变异矩阵的充足训练会让我们所提取的i-vector在表征话者身份方面有着较好的诠释.在短语音下的说话人识别,从根本上来说就是{Y1,Y2,Y3,…,Yt}的减少,继而满足不了零阶和一阶BW统计量,而语音数据量过少势必造成统计量估计的偏差.对于GMM-UBM以及i-vector等基于语音概率分布进行建模的统计模型来讲,短语音缺少信息量的前提下使得对语音分布存在的偏差,继而生成的说话人身份向量在统计上变得并不准确,这似乎也成为i-vector不可逾越的最大弊端.
3 时滞神经网络
使用一个较为低维的向量去包含一个具有身份的对象这就是嵌入(Embedding)技术的初衷所在.在说话人识别中,这里的对象指的是说话人的语音.嵌入向量能够表达对应对象的某些特征,也可以说将对象进行了稠密地浓缩,将其特性包含在了一个向量之中.说话人识别深受影响,Snyder等人提出使用时延神经网络[14](Time Delay Neural Networks,TDNN)提取说话人语音的embeddings 特征,这就是x-vector的由来.架构如图1所示,将语音处理后分块输入至5层的时滞神经网络,之后是一个统计池化层,它的目的是将帧级(frame level)特征整合至话语级(uttenarence level)特征上,具体是计算帧级特征的均值以及标准差.紧接着的使用两层全连接层充当嵌入层用于对话语级语音进行抽取embedding向量,网络最后一层为softmax层用于对训练集的分类,输出的神经元个数和训练网络中说话人数.由于TDNN 可以看作是一个一维的卷积,利用其时滞的优点可以捕捉任何时段的信息,这也让x-vector 在短语音上表现上优于i-vector.

图1 基于时滞神经网络的x-vector提取图
4 核典型关联分析
4.1 说话人嵌入向量
基于全局变异空间模型所提取的说话人向量i-vector和基于时滞神经网络所提取的x-vector,虽然一个基于统计模型一个基于深度框架,但从某种意义上来讲,i-vector说话人向量和x-vector向量都属于embedding嵌入技术的一种,我们也叫它们嵌入向量[15].原因在于它们将可变长度的说话人语音映射成为固定维度的说话人嵌入向量来表征.将原始语音从时域变换为频域后进行简单处理,后得到说话人浅层声学特征如梅尔频率倒谱系数等,经过训练全局变异空间模型和时滞神经网络后,通过注册和测试集抽取得到i-vector,x-vector这类深层说话人特征.在这两个分别独立进行识别得说话人系统里面,无独有偶,被提取出来的i-vector和x-vector也可以单独代表该说话人进行下一步的相似度判别分析,例如余弦距离等.
4.2 基于核典型关联分析的短语音说话人嵌入向量
作为生物识别的其中之一,对于说话人识别的前沿技术许多都是从人脸识别的技术上总结而来的,比如概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)[16],最新的Facenet[17]以及三元组损失[18]等.核典型关联分析(Kernel Canonical Correlation Analysis,KCCA)[19]也是在人脸识别多视图学习中较为常用得一种.对于一维向量之间的相似度关联关系来说,皮尔逊相关系数可以很好的解决这一问题,而面对两组随机变量时,寻找两者的线性投影的最大程度上的相关,这就是典型关联分析.它是一种将高维变量降维至一维的方法,从而分析其一维情况下的线性关联关系的方法,而KCCA则通过核函数将两组样本投影至高维空间上进行分析,从而减少降维所带来的信息量损失.
基于KCCA的说话人嵌入向量融合方法,旨在学习i-vector和x-vector两种说话人深层次嵌入向量之中的非线性关联关系.本文提出利用核典型关联分析方法分析抽取得到的说话人嵌入向量之中得非线性特征信息,学习全局变异空间模型中i-vector和时滞神经网络下的x-vector的非线性映射关系,从中提取经过非线性映射所得到得投影向量a和b,以此增强说话人识别在短语音下的信息不足问题.
首先,在训练阶段,经由训练集我们训练好全局变异空间和时滞神经网络.将注册和测试集阶段将每一个人每句话的i-vector和x-vector提取出来,假设说话人的i-vector为I=(i1,…,in),x-vector为X=(x1,…,xs),这里将多者进行截取的操作,最终的维度为p维,则KCCA将数据通过两个非线性φ,η映射至一个高维特征空间F上,由下式表示:
(10)
其中φ(I),η(X)∈F空间,设核函数为ki和kx,则令:
(11)
KCCA的目标与典型关联分析类似,只不过是在高维空间里去寻找投影方向上得αφ,βη在相关性最大下式:
(12)
其中,向量αφ是存在于i-vector向量所映射在的高维空间之中,αφ存在于φ(I)=(φ1(i),…,φp(i)所表示的高纬度空间之中,则存在N维的向量ζ使得αφ=φ(I)ζ,并且βη也存在于η(X)=(η1(x),…,ηp(x)之中,故存在N维向量ψ让βη=η(X)ψ,于是可以到的:
(13)
我们将KCCA转为约束问题,则约束条件为:
(14)
则我们的优化目标则仅剩下式(13)中的分子项,用拉格朗日乘子法来求解分子项的最优化问题,如下式子:
(15)
其中,λ1和λ2为拉格朗日乘子,若令λ1=λ2,分别对式(15)中ξ和ψ求导,然后令其等式等于0,即可解出ξ,ψ,接着可得到I,X之间的非线性投影向量组为:
(16)
至此,利用KCCA获得i-vector与x-vector非线性相关的特征向量a和b后,即仿射向量,两者的维度都为p×1,将其二者结合,即得到新的说话人向量,称为k-xi向量.综上,基于KCCA的说话人嵌入向量融合方法步骤如图2所示.

图2 基于KCCA的说话人嵌入向量方法流程图
5 实验结果与分析
5.1 实验语料库
实验语料库为Librispeech英文名著读物语料库,和aidatatang中文普通话语料库以及实验室自建普通话语料库所组成的混合语料库,语料库总人数为975人,将其分为开发集,训练集,注册集以及测试集.注册集设置为100人,测试集人数与注册集保持相一致.开发集设置100人,目的是对可调参数进行实验,选取最优应用至注册和测试集内,其余人数全部归为训练集之中.语音预处理方面,采样率统一为16Khz,预加重系数0.9375,对信号分帧处理帧长设置为25毫秒,帧移为10毫秒,对信号加窗类型为汉明窗,使用基于谱熵的话音检测来除去静音段语音,原因主要是语料库种大多说话人语音采集场景接近场景下,实验在验证短语音下说话人嵌入向量识别性上尽量避免其余的干扰信息.而在后端处理上,采用LDA对说话人嵌入向量进行降维处理,信道补偿和相似度打分采用概率线性判别分析的方法.
5.2 基线系统
本文基线系统分别设置为基于全局变异空间所提取的i-vector向量,基于深度神经网络提取的d-vector向量和基于时滞神经网络提取的x-vector这3种说话人embedding向量.评价指标方面:本次实验选取最为常用的误差率(Equal Error Rate,EER)和NIST SRE 2010说话人挑战赛所提出最小检测代价(Minimum Detection Cost Function,minDCF).
实验对比模型方面,选择3种说话人识别框架和一种分数融合方法.分别是基于全局变异空间的i-vector,基于深度神经网络的d-vector和基于时滞神经网络的x-vector 3种说话人嵌入模型以及将i-vector与x-vector说话人向量在相似度判决后的最后得分进行加权平均的方法.全局变异空间模型方面设置,输入特征为20维梅尔倒谱系数,一阶差分以及二阶差分系数的拼接组合,全局变异空间矩阵维度为600.深度神经网络方面,取24维Filterbank作为输入特征,深度网络为四层全连接,后两层设置dropout,系数为0.5,末端为softmax层,输出节点数是训练集人员的个数.从最后一层全连接层提取嵌入向量,即为d-vector说话人向量.时滞神经网络方面,网络节点与文献[13]保持一致,输入特征为24维Fbank特征,网络训练优化器采用Adam,我们在实验之中也发现了在语料库有限的情况下Adam优化器在e轮次上比SGD优化器收敛速度更迅速许多,网络最后端为softmax分类器,输出节点与训练集人保持一致.在x-vector框架的全连接层第一层提取出说话人嵌入向量x-vector,全连接第一层输出节点为512.
5.3 实验结果与分析
完成准备工作后,使用基线系统与k-xi向量进行说话人识别性能的比较情况,以研究从全局变异空间模型和时滞神经网络中所获取的互补信息并以此增强说话人身份信息的有效性.
首先,在建立的开发集上对KCCA以及核函数等超参数和多选项进行了测试实验选择,选取最优以便进一步的使用,3种核函数分别是:线性核函数,多项式核函数以及高斯核函数.首先是线性核函数并没有专门需要设置的参数,而对于多项式核函数超参数为d以及高斯核函数中σ值采用交叉验证的方法进行验证来确定超参值.
从图3,图4中可确定σ,d,的值分别为0.5,5.确定好参数后,进行下一步核函数的选择工作,从图5中可看出,高斯核函数表现最优,这也印证了在核函数的选择上,对于特征参数纬度较大的工作来说,高斯核函数较为合适,且多项式核函数的d为高阶时.参数过多容易造成计算量的增加,故本文采用σ值为0.5的高斯核函数对说话人嵌入向量进行下一步的处理工作.

图3 不同σ值下高斯核函数对说话人识别的等误差率

图4 各d值下多项式核函数对说话人识别的等误差率

图5 不同核函数对说话人识别性能的影响
表1和表2报告了本研究中使用的不同说话人识别嵌入向量在不同测试语音下的性能指标.首先看来,在全时长测试语音下,4种嵌入向量之中比较,基于分数融合方法的等误差率在五者中较低,而minDCF上面,融合方法同为最低.这说明在全时长注册和测试的情况下,基于全局变异空间的i-vector和时滞神经网络的x-vector在分数上的融合已经能达到较好的性能.刨去分数融合的方法,令人眼前一亮的是i-vector在全时长测试语音下的EER上表现最优,相比之下的基于时滞神经网络的x-vector并没有像文献[20]所指出的那样性能比i-vector好,原因可能是在以下3点:预处理阶段本次实验未对时滞神经网络的输入特征进行3秒窗口内的归一化操作,分数判决打分阶段未使用分数归一化的操作在去除混语料库下的多信道影响,以及未添加噪音和回响去增强x-vector的鲁棒性所导致.而k-xi嵌入向量在全时长的表现,相较于x-vector时提升了等误差率,相较于i-vector反而变成冗余部分,并且在面对同为融合思想下的分数融合法,在全时长下并未凸显出自身学习双方非线性相关的优势所在.好在10秒测试语音长度下,本文所提出的k-xi嵌入向量相比i-vector,d-vector,x-vector以及分数融合在等误差率方面降低了17.02%,19.49%,1.34%,0.96%;minDCF方面相比i-vector和d-vector和分数融合下降了14.67%,7.24%,1.54%,相比x-vector反而上升了3.12%.在测试语音长度为5秒时,k-xi嵌入向量在等误差率方面,对比前四者分别下降了14.84%,20.45%,1.95%,0.98%;minDCF方面相比i-vector和d-vector同比下降3.79%,6.58%,且与x-vector和融合算法保持一致.在极短测试语音2秒条件下,等误差率上k-xi向量比i-vector,d-vector和x-vector和融合方法下降了17.01%,21.21%,5.05%,4.54%;minDCF方面同比下降了5.62%,7.68%,2.33%,4.55%.
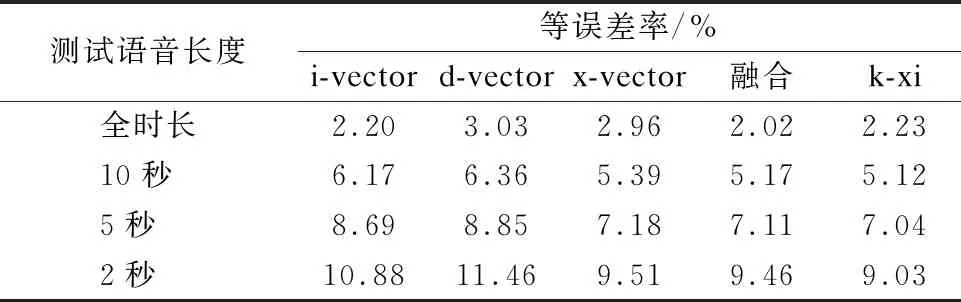
表1 不同测试语音长度下说话人嵌入向量的等误差率

表2 不同测试语音长度下说话人嵌入向量的最小权衡代价
随着测试时间的缩短,k-xi向量在等误差率和minDCF上相比其他四者有了很大程度上的降低,尤其在测试语音3秒的情况下,降低幅度较大,这也反映了短语音下基于全局变异空间对于语音概率估计不足的问题随着时长的缩短开始明显起来,这个弊端与第2节中所分析的基本一致.而基于DNN的d-vector在提供同层之间的关联信息的方面上,而在上下层的信息关联方面,相对于x-vector有些欠缺.x-vector是当前3种基线系统内,短语音下表现较优秀的说话人嵌入向量,但语音特征在输入层被分块的操作虽然加快模型的运算速度,但此举更加压缩了说话人的信息,并不能在上下文关系上给予充足的信息共享.视线转向后端分数融合的方法,虽然在全时长测试语音的环境下,融合分数的方法增强了说话人在后端的判别能力,其表现在五种方法下表现较优,但随着测试时长的缩短,融合方法的鲁棒性欠佳的缺点也显露出来,分数融合的策略欠缺些许考虑,且统计模型下的i-vector在短语音测试下性能的波动致使融合分数会受到一方的影响而不得不进行折中的判决,等误差率的提高趋于缓慢,在最小权衡代价方面也会出现时而高于x-vector的表现,表明分数融合的方法并不稳定.参考两者的得分综合判断的操作,则必会受到两者系统不同程度上的影响.
由此可见,k-xi在4种说话人嵌入向量和一种分数融合方法下表现出较好的识别性能和鲁棒性需求.实验也证明了本文基于KCCA融合基于全局变异空间模型i-vector和时滞神经网络的x-vector提取出新的说话人嵌入向量k-xi的有效性.
5.4 t分布随机邻近嵌入算法可视化
t分布随机邻近嵌入(t-distributed stochastic neighbor embedding,t-SNE)[21]是一种可以将高维信息降维并可视化的技术.我们使用t-SNE对4种说话人嵌入向量降维至平面,并进行可视化操作.从测试集中随机抽取注册集5名说话人,每人5句2至5秒不等的语音,同时提取4种说话人嵌入向量并降维至二维投影至平面分析,所得到t-SNE可视化图如图6所示,t-SNE展示了说话人身份向量的分布情况.在图6(a)中i-vector所表达说话人的方式过于紧凑,以至于5名说话人的嵌入向量都拥挤在一起,过多注意类内之间的距离,而忽略了类间之间的距离.图6(b)和图6(c)所表示的d-vector和x-vector都是依靠模型中最尾端的softmax进行分类,所以从图中可以看出,d-vector和x-vector这类判别式分类模型与i-vector不同的点在于,d-vector与x-vector更加注重在于类间之间的差异,而对每个说话人的内部差异却没有一个很好的表达,导致每个说话人自身之间的表达缺少了聚合点.从图6(d)中可以看出,k-xi嵌入向量结合了i-vector与x-vector的特征,更好的从类内聚合和类间距离两种方式上表达了说话人身份向量.

图6 各个说话人嵌入向量的t-SNE可视化图
5.5 实验对比
最后,我们将本文算法与文献[6],文献[7],文献[9],文献[12]在不同测试时长下对等误差率进行比较.如图7所示.本文所提出的k-xi向量相对于文献[6],文献[7],文献[9],文献[12]在测试时间为10秒时,等误差率相比下降17.82%,14.81%,16.34%,11.27%;测试时长为5秒时,等误差率相比下降13.51%,16.69%,13.51%,10.43%;当测试时长降至2秒时,等误差率同比下降了15.76%,17.0%,10.24%,9.43%.文献[6]与文献[7]都是基于多特征的说话人识别技术,虽然增加声学特征的维数是一种在输入层面对说话人信息增强的传统技术,维数的增加会造成计算量的冗余,如果像文献[6]所述的使用PCA进行降维,也会造成原始信息的缺失.文献[9]的方法从嵌入层出发,将加噪i-vector和纯净i-vector输入进DNN网络学习非线性关系,但主动的加噪操作也会造成最终的i-vector存在带噪的成分,从而干扰识别的判定.与此同时,我们在研究发现本文所抽取的向量k-xi也存在些许的不足之处需要改进的空间,在时效性上相比上述几种文献有些许差距.总体来讲,针对短语音条件下所提出基于KCCA的说话人嵌入向量提取的算法,经过短测试语音条件的测试,证明了联合i-vector与x-vector所提取出的说话人向量k-xi算法的有效性.

图7 基于KCCA的说话人嵌入向量方法流程图
6 结 语
针对短语音环境下,本文提出一种基于核典型关联分析的短语音说话人嵌入向量的方法.该方法首先需要分别训练全局变异空间和时滞神经网络模型,在注册和测试阶段从中提取i-vector和x-vector嵌入向量,经过KCCA将两者变换至高维空间分析其非线性关联特征,最终提取出融合后的说话人向量k-xi.该向量也是从嵌入层出发,通过KCCA学习i-vector向量与x-vector向量非线性特性,以此增强由于短语音环境下的说话人信息不足的问题.上述实验验证了本文所提出的方法有效降低短语音环境下说话人识别的等误差率和最小权衡代价,具有可行性和有效性.在未来的工作中,主要研究分为两部分展开:一是向极短语音(1秒,0.5秒)条件下探索,二是针对基于核典型关联分析的短语音说话人嵌入向量方法的时效性加以优化.
