基于BERT预训练模型的即时通讯情感分析方法
2021-11-19
(黎明职业大学信息与电子工程学院,福建 泉州 362000)
在即时通讯软件的使用过程中,用户会产生大量的对话信息,他们会在某个时段针对某个话题表达个人的想法和情绪。在一个多人多事务的即时通讯系统中[1],主话题可嵌入子话题,形成一棵话题树,用户在某个子话题树中发表分组信息,具有逻辑上的连续性,从整体上可以反映出用户对某个具体话题的意见和情绪[2]。管理员创建一个主话题,一般是为了完成一项核心任务和其他子任务,任务组成员有时不方便直接在群组里表达意见或表露真实情绪,由于群内成员众多,发言内容也比较繁杂,话题管理员不一定能发现用户的真实情感,话题管理员如果能及时地发现任务组成员存在的不满和看法,消除任务沟通存在的问题和风险,将有助于任务的顺利完成。
情感分析是自然语言处理(natural language processing,NLP)的热点领域。情感分析即情感倾向性分类,指的是识别主观性文本的倾向是肯定还是否定的,或者是正面还是负面的。NLP是一项研究人与机器间使用自然语言进行信息交互的技术理论和方法,是一项融合计算机、语言学、数学等各个学科的方法[3]。传统的情感分析是将词句视为一个词袋,并查阅“积极”和“消极”单词的参照列表,以确定该句子的情绪。情感分析主要有基于情感词典的方法、基于机器学习的方法和基于深度学习的方法,国外对于机器学习方法的研究较多,国内倾向于情感词典方法的研究。自从深度学习在情感分析上取得较好的分类效果后,深度学习成为国内外的主要研究方向[4]。本文使用深度学习技术对用户发言进行情感分析。近年来,预训练语言模型(pre-trained language models,PLM)在各种下游自然语言处理任务中表现出卓越的性能,受益于预训练阶段的无监督学习目标,预训练语言模型可以有效地捕获文本中的语法和语义,并为下游 NLP 任务提供蕴含丰富信息的语言表示[5]。预训练语言模型的思路是首先在大规模语料库中预训练模型,然后在各种下游任务中对这些模型进行微调,以达到最先进的结果。BERT(bidirectional encoder representation from transformers)[6]是Google 2018年推出的通用的基于Transformer用于深度双向语言表征模型,在BERT发表时提出的11个NLP下游子任务中取得当时最好的成绩。由于 Transformer模型的表现十分优异,几乎所有的预训练语言模型都采用了Transformer作为骨干网络。
鉴于BERT的优良表现,本文提出对即时通讯产生的分组文本进行分析时,采用BERT预训练模型的手段。由于即时通讯平台收集到语料加标注需要的人工成本较高,所以选取相对少量数据与基线语料相组合,作为微调(fine-tuning)输入数据。
1 相关工作
1.1 Transformer模型
随着深度学习的普遍应用,有关NLP的特征提取器不断发展,包括循环神经网络(recurrent neutral network,RNN)、长短时记忆神经网络(long short term memory,LSTM)以及现阶段主流模型Transformer及其衍生模型。Transformer在NLP领域已经产生重要影响。相对于RNN得通过循环按顺序串行处理句子出现的词,Transformer可以并行处理句子中出现的每个词,训练速度更快。基于Transformer的BERT预训练模型产生后,在文本分类、机器翻译、情感分析、问答等许多NLP领域都有优异表现和应用,其中BERT预训练模型采用的Transformer结构起到关键作用。Transformer模型结构如图1所示。Transformer模型的优异表现主要来自以下几个关键设计:
1)词向量化是Transformer的核心之一,使用词嵌入技术embedding,将句子中的每一个词映射为一个向量,同时为了表示词在句中的位置,则在词向量中加入位置信息,即使用位置编码,将位置矩阵PE加到前面的embedding矩阵,从而得到包含位置信息的句子矩阵。
2)编码设计也很精巧,在得到句子矩阵后,将其传给编码器进行编码,在Transformer设计中编码使用了自注意力机制(self-attention)。在自注意力层中词向量与3个可训练的、维度相同的WQ、WK、WV矩阵相乘,分别得到Query、Key和Value3个向量。Query是查询向量,Key和Value是键值对,通过查询找到相关性较大的Key,再以此作为权重与Value相乘输出。自注意力结构见图2。图2中的掩盖(Mask)是消除对块输入进行补全操作带来的影响,一般是设置为极大的负数,从而使得在softmax层上输出概率为0,而相关性较高的输出值就相对较高。再用归一化函数值softmax乘以值向量Value得到Z矩阵,最后对Z矩阵进行求和就得到了自注意力值。自注意力机制不是Transformer独有的,相对于采用卷积神经网络(convolutional neural network,CNN)设置超参数卷积窗的方式实现自注意力机制[7],它的引入不仅简化了模型的复杂度,而且使得词向量不仅包含单词本身,还包含了与上下文关系,词向量传送给前馈神经网络继续进行编码。自注意力计算公式如下:
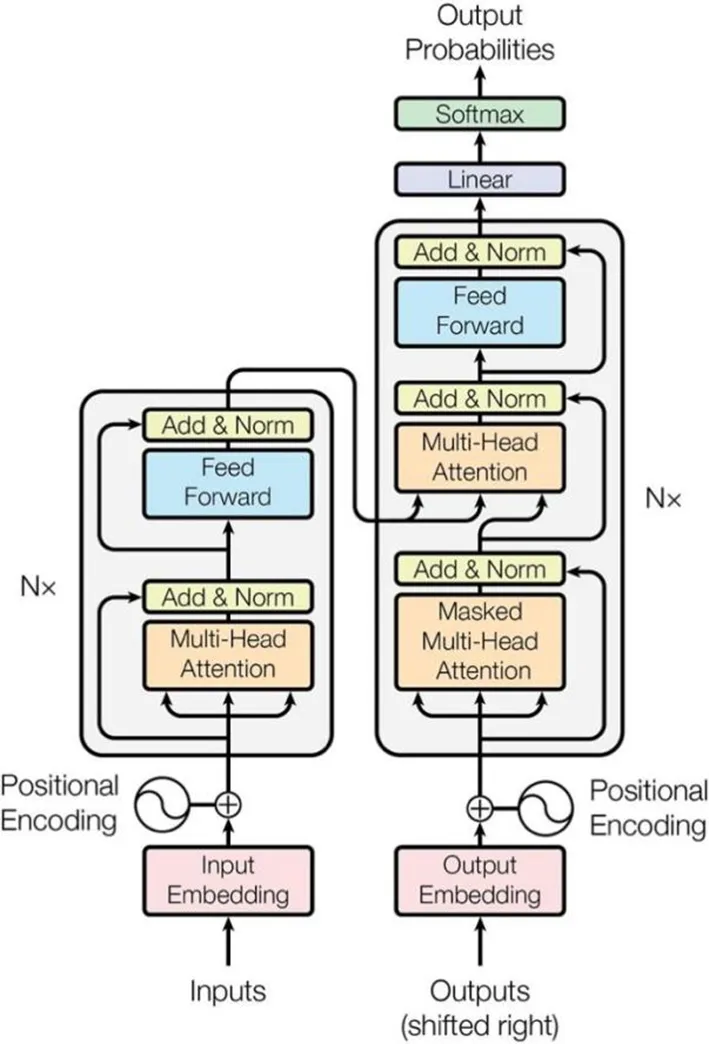
图1 Transformer模型结构Fig.1 Transformer model structure
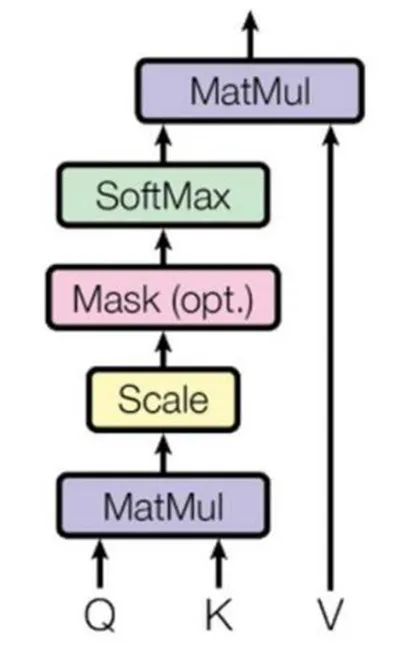
图2 自注意力结构图Fig.2 Self-attention structure diagram
1.2 BERT预训练
以BERT为代表的NLP领域预训练模型以及特征提取器Transformer取得了十分显著的成效,有关预训练模型的有效性也受到深入研究。BERT预训练过程包括两个步骤:
1)先随机用字符[MASK]遮盖15%的词汇,让模型根据上下文对被遮盖词汇进行预测,初步训练模型参数。
2)把句子样本分成相等的两部分,一半是有上下文关系,一半是上下文没有关系。将样本数据输入模型,通过判断两条句子是否是上下文来继续训练模型参数。损失函数是两部分的平均值。这两步预训练结束后的Transformer 模型是通用的语言表征模型。
Google在使用了大量的数据和计算时间,训练并公开了几种BERT预训练模型,其中包括中文版本,也是本文实验中预训练选择的版本。该模型包括12层Transformer的编码器、768个隐藏单元和12个注意力头,含有110 M个参数[6]。BERT在提出之后又在NLP中文任务中持续改进,包括全字掩码(whole word masking),解决了预训练过程中随机掩盖导致的部分掩盖的弊端。Cui Yiming等[8]对中文文本也进行了全字掩码。
BERT预训练完成之后,需要在具体任务进行微调。微调任务分为:基于句子对的分类任务和基于单个句子的分类任务;情感分析属于基于单个句子的分类任务。根据[CLS]标志生成一组特征向量C,C通过一个softmax层或者二分类函数Sigmoid输出分类结果。本文在该步骤中提出增加输入数据的情感部分,让模型学习不同领域的情感信息,以增强领域敏感度。
2 模型训练
本文提出的模型训练方法是一个有监督的训练过程,首先把获得的语料数据按标签进行分类后输入到BERT中进行特征提取,然后编码嵌入更新生成词向量,使用词向量进行深度学习,训练得到模型,对模型进行评估。然后再用得到的模型对目标数据进行测试,得到实际预测结果。实验流程如图3所示。
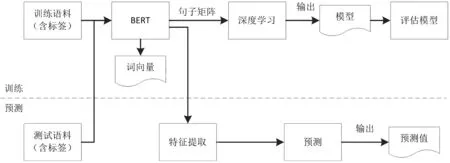
图3 模型训练及预测流程图Fig.3 Model training and prediction flowchart
2.1 模型和语料准备
从BERT官网下载支持中文的预训练模型[9],再从GitHub获取新浪微博情感分析标记语料共10万条,其中带情感标注的正负向评论各约5万条[10],用数据分析工具Pandas查看数据序号、标签及微博内容,其中标签值1 表示正向评论,0 表示负向评论。选取其中几条内容(表1),列出了微博的序号、标签和内容,内容中的文字包括表情符号、账号(昵称)、标点符号等。

表1 含情感标记的新浪微博部分语料
2.2 划分语料
BERT要划分训练集、验证集和测试集。将新浪微博情感分析标记语料按99∶1比例分为训练集、验证集。测试集按长度不少于10个字符的规则,筛选出即时通讯数据库中的数据,共提取2 000条记录,将这2 000条记录人工标注为0,1。
2.3 微调API
Google已经针对中文完成了BERT的预训练模型,所以使用时运行run_classsifier.py进行模型分类任务的fine-tuning。执行步骤如下:BERT代码中的Processor类负责对输入数据的处理,这里按照BERT既定的使用方法,继承DataProcessor类并命名为WeiboProcessor,重载get_labels、get_train_examples,get_dev_examples和get_test_examples这几个方法,其中get_labels方法用于判断情感二分类,简单返回0和1。get_train_examples,get_dev_examples和get_test_examples方法分别用于训练、交叉验证和测试任务数据。接下来打开BERT下载文件中的bert_config.json,设置的运行参数。最后执行run_classsifier.py进行模型的训练。
3 跨领域迁移
3.1 情感词对分类的影响
BERT经过train训练集训练之后,模型基于dev验证集评估出正确率指标,结果显示test集与dev集准确率相比有5%的下降。在分析数据时,发现源领域的情感分类数据对目标领域的数据进行分类存在困难。有些词在微博和通讯聊天中存在不同的情感倾向,这类问题在许多文章中已经都有分析[11],对于情感分类的词有两个维度:1) 词对分类任务的重要性;2) 词的情感倾向。有的词在不同领域的情感倾向对分类也很重要,例如上述引用论文中提到单词 good ,对电影领域和电子设备领域的分类重要性都很高,并且在两个领域的情感倾向是一致的。而 unpredictable 这样的单词对电影领域和电子设备领域的情感分类都很重要,但是在这两个领域的情感倾向不一样(在电影领域表示给人惊喜,而在电子设备领域通常会指不可预期的故障)。在跨领域情感分类问题中,涉及枢轴(pivot)和非枢轴(non-pivot)概念,枢轴是指情感不随领域变化的单词,非枢轴是指情感随领域变化的单词。识别枢轴词和非枢轴词对跨领域情感分类有很大作用。从文献[12]的实验数据可以看出,跨领域情感分类任务中学习构建枢轴特征可以提升模型性能。
中文也存在类似问题,例如下列两个句子:
电子产品领域:这个屏幕很好,很清晰。
餐饮领域:他们的服务不错,很周到。
在这个例子中,“很好”是领域不变特征,即在不同领域的解释都是正向的,而“清晰”和“周到”是特定领域特征。由于领域的差异可能造成在源域中训练的情感分类器用在目标域性能下降。
3.2 解决方法
从BERT预训练任务之一的下一句预测(next sentence prediction,NSP)任务得到启发,设计一种领域迁移的模型训练任务。不同于NSP之处在于,该任务是预训练模型已经完成之后执行,目的是抽取领域不变的特征,从而克服领域间的差异。完成分类之后将[CLS]向量通过softmax层输出。任务中的文本分为源领域和目标领域,源领域即预训练的领域,目标领域是要迁移的领域。构造三类句子对:第一类全部是源领域句子,第二类是上下句分别是源领域句子和目标领域句子,第三类全部是目标领域句子。句子对的组合是随机采样的。由于目标领域的语料数量较少,因此设置这三类数据集的比例为98∶1∶1。句子格式及标记如下:
输入1:
[CLS]这个太赞了,生活大爆炸第六季马上要出啦[SEP]
[SEP]终于收工啦,脚丫子快冻掉了[SEP]。
标记:same
输入2:
[CLS]这个手机的屏幕很好,信号也很好[SEP]
[SEP]天气太冷了,要多穿衣服[SEP]。
标记:diff
上述例子中,[SEP]表示分句,[CLS]放在段落开头,不表示明显语义,只表示融合段落其他字词语义信息的分类特征。标记same表示是同一领域,diff表示上下句不是同一个领域。最后用条件概率表示,公式如下:
P=softmax(CWT),其中C是[CLS]向量,W是学习的权重矩阵,T表示词向量。
为验证该模型的有效性,采用BERT基础模型(BERT base model)和相同语料库作为基线模型进行对比,句子也是随机采样。不同之处在于,基线模型构造两类句子对,上下句和不是上下句各占50%。
4 实验与分析
4.1 实验环境
本文实验的硬件环境是Intel© CoreTMi7-7770的CPU和Titan 2080Ti 11GB RAM显卡的工作站,软件环境是操作系统Anaconda 1.9.12、Tensorflow 1.14.0、Python 3.6.8。
4.2 实验结果及分析
4.2.1 评估指标
对二分类问题的建模后的模型评估指标常用的包括:准确率(accuracy)、精确率(precision)、召回率(recall)、综合评价指标F1值(F-measure)。准确率是最常见的评价指标,指的是预测正确的样本数占所有的样本数的比例,在正负样本均衡的情况下,准确率越高分类器越好;综合评价指标F1值兼顾了精准率和召回率,F1较高说明分类器比较有效。
指标指标公式中包括TP、TN、FP、FN4个参数,其中涉及正例和反例的概念,分别为上述的正向评论数和负向评论数。TP为真正例,将正例预测为正例的数量;TN为真负例,将负例预测为负例的数量;FP为假正例,将负例预测为正例的数量;FN为假负例,将正例预测为负例的数量。指标公式为
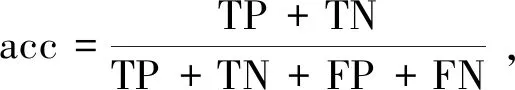
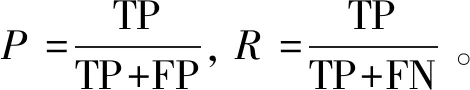
4.2.2 参数设置
微调参数大部分与预训练相同,如激活函数、dropout等都保持不变。超参数是根据类似模型或者实践得出的经验值,其中batch_size的值是每个批次训练的句子数。如果设置过小,会延长训练实践;如果过大,则当损失函数曲线较为平坦时,导致训练结果无法得到最佳模型。此外还要考虑硬件条件等因素,硬件性能较为一般时,batch_size不能设置过大。在参考了预训练模型和硬件条件,以及测试了几个近似值之后,对超参数中的学习率、训练周期和batch_size参数设置如表2。

表2 微调参数设置
4.2.3 对比实验
实验选择的数据集是上述划分的dev验证集和test测试集, BERT基础模型作为基线模型,该模型已经具备注意力机制、掩码等感知能力,相较于本文提出的BERT基础模型加上领域迁移(transfer),基础模型不具备对不同领域数据的感知能力。在前两种BERT之外选择Attention-based RNN作为参照,该网络是在循环神经网络RNN的前端输入分词后的文本,在分类输出前采用Attention机制融合输入各个词对应的隐状态。
4.2.4 结果与分析
实验结果如表3所示,dev acc是验证集的正确率,test acc是测试集的正确率,一般情况下验证集的正确率要高于测试集的正确率,符合预期。从表3可以看出,在BERT预训练基础上增加了跨领域模型迁移,实验取得更好的结果,第3组数据比第2组数据的测试集正确率提升了2.1%,比RNN模型的各项指标都更具优势。由此可见本研究采用BERT+跨领域模型迁移的方案设计有助于模型优化,提高预测的准确率。采用Transformer结构的BERT在改进了数据的语义表达和训练参数之后,在无需增加模型复杂度的情况下,即可较大提升BERT的性能。
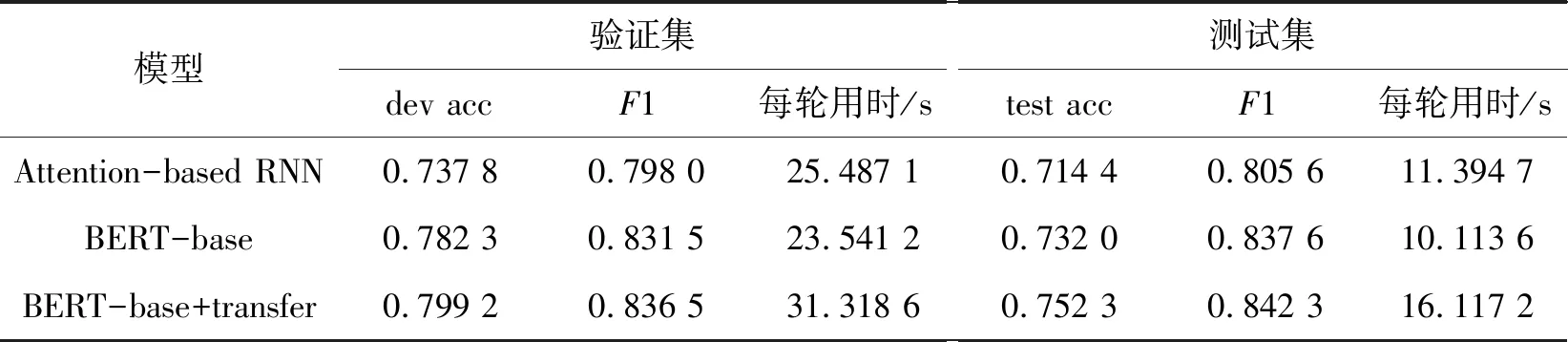
表3 实验结果对比
5 结语
本文提出的多人多事务即时通讯系统的场景中,每个主话题对应一项工作任务,群内成员众多,发言内容比较繁杂,为了方便群管理员发现成员在聊天文本中透露出的负面情绪,及时消除对任务不利的人员因素,提出一种解决分组信息的情感分析手段。在研究过程中发现跨领域对情感分析的结果影响较大。接下来在面向文本的跨领域情感分析问题中,采用基于BERT预训练语言模型的微调方法,提出一种跨领域模型迁移方法以进一步提高模型情感预测的准确率。结果表明相对于基线模型正确率提升了2.1%,相对于RNN模型,在测试集和验证集下的正确率和F1指标都更具优势。从测试集的实验数据可以看出跨领域模型可以满足应用场景的需求。
后续将在跨领域分类问题上,继续对领域自适应问题进行研究。即时通讯分组产生的信息不仅仅包括句子、段落等非结构化数据,还有结构化数据,如表格、图片、视频等,如何让预训练语言模型接收结构化数据是现在NLP领域研究的方向,还有待进一步研究。目前来看,预训练模型加微调是NLP实践的一个方向。现在处理结构化数据的预训练模型有VideoBERT[13]等,但VideoBERT只实现了BERT编码器功能,仅能学习图像和语言标记序列的双向联合分布,必须另外训练一个视频到文本的解码器,从而导致预训练模型到微调之间的偏差。后续研究中将继续完善对其他结构类型数据的建模能力,在即时通讯应用中提供更加有效的情感判断。
