基于HDFS开源架构的异常数据实时检测算法
2021-11-17陈国瑞袁旭华
陈国瑞,袁旭华
(1.长江大学计算机科学学院,湖北荆州 434000;2.延安大学数学与计算机科学学院,陕西延安 716000)
1 引言
目前网络技术高速发展,网络应用逐渐深入到人们生活的各个方面,面对海量的数据信息,需要更高的网络安全性能[1]。网络上各类攻击手段屡见不鲜,全网流量的测量以及大规模数据处理相对困难。在某些情形下,异常数据实时检测可发挥重要作用,依据获取的异常数据,判断突发事件是否发生,例如突发地震、突发火灾等[2]。
为此相关学者对其进行了研究,并取得了一定的研究成果,文献[3]提出基于链路状态数据库的数据中心网络异常检测算法,搜集链路状态数据库,采用改进路由算法,得到全网路由形成路由域信息库数据,对比准确关联链路和路由变化,检测链路异常并定位故障。该算法能够快速发现拓扑变化,检测时间较短,但该算法的误报率较高。文献[4]提出基于边缘计算的传感数据异常实时检测算法,采用“时间序列”形式表示传感数据,构建传感数据异常检测模型,运用时间序列相关特性,检测实时传感数据异常,输出融合处理检测结果。该算法的检测准确性较高,但检测运行时间较长。
针对上述问题,提出了基于HDFS开源架构的异常数据实时检测算法,依据基于HDFS数据分布式云存储体系所获数据,使用多级哈希表搜索算法,完成异常数据查询,采用基于支持向量数据描述,实现异常数据实时检测。该算法具有较高的检测能力,能够有效降低误报率,缩短运行时间。
2 基于HDFS开源架构的异常数据实时检测算法
2.1 检测算法框架
基于HDFS开源架构的异常数据实时检测算法是在Hadoop开源架构上,搭建基于HDFS的数据分布式云存储体系,实现异常数据实时检测。检测算法框架如图1所示。

图1 检测算法框架
基于HDFS的数据分布式云存储体系,通过布设在各区域的数据采集终端,采集异常检测相关数据,并将数据存储于各个二级数据中心的实体存储节点中,将各二级数据中心的数据汇总后,存储至数据中心,该数据中心可为数据查询模块和异常检测模块提供数据支撑[5]。数据查询模块采用多级哈希算法完成数据查询,异常检测模块基于支持向量数据描述完成异常数据实时检测。
2.2 基于多级哈希算法的数据查询
依据基于HDFS数据分布式云存储体系所获数据建立分布式哈希表,并设计多级哈希表搜索算法,完成数据查询。当请求数据查找时,先检索第一级哈希索引表,再检索第二级哈希索引表,进入第二级哈希索引表之前要依据(key,value)内key对应的value值进入,一级哈希表内分化出的数据信息存在二级哈希索引表,循环以上过程直至该数据被找到结束[6]。
使用此算法需在多级索引表内存放全部数据对应信息所需的索引。用O(log(m1+m2+…))表示算法的时间复杂度,第一级索引的信息条数用m1表示,第二级索引的信息条数用m2表示,逐次向下使用此方式对各级索引表的key列进行检索[7]。因为各表的索引条目在设计的多级索引表算法中数量一致,所以对此时间复杂度进行简化,用O(logm*n)表示简化后的时间复杂度,其内索引的级数用n表示,单个索引表内信息条数用m表示。
O(logN)+O(logM)用来表示常规哈希算法的时间复杂度。平均从异常数据表内查找所需数据的key所用的时间用O(logN)表示,平均从一条拥有各个数据量记录内查找指定信息的时间用O(logM)表示。m、n、M、N等值决定了两种算法的时间复杂度,而m、n、M、N的参数值由数据量大小和多级索引的设计方式决定。由于搜索路由表时需要大量时间,常规哈希算法的总开销超过了多级哈希算法。
2.3 基于支持向量数据描述的异常数据实时检测
2.3.1 支持向量数据描述分类器
支持向量数据描述为一种数据描述算法,是基于支持向量机形成。其主要内容是:通过计算最小超球体边界形容数据的分布范围,其最小超球体边界涵盖一组数据。
设定一个数据集{xi,i=1,…N},其中包含N个数据对象,设定一个根据中心a和半径R>0确定的超球体,其中容纳此数据集,该数据集用体积最小的超球体来表示,为寻求一个体积最小的超球体,使用支持向量数据描述通过最小化R2来寻找,使此球体能容纳所有(或更多)的xi。在超球体外侧存放异常点,将异常点排除在超球体外侧是为了达到减轻异常点的影响,利用松弛变量ξi进行排除[8]。上述过程可形容为二次规划问题,由如下式(1)表示
(1)
式(1)中,控制球体体积与误差之间折中得出常数用C表示。其约束条件可表示
(xi-a)T(xi-a)≤R2+ζ2
∀iζ≥0
(2)
根据拉格朗日泛函的鞍点给出上述问题最优解,可表示为
(3)
式(3)内,拉格朗日系数用ai≥0,γi≥0表示。该泛函对R,a和ζi的偏倒数设为等于零,以获取最小值表示为
(4)
(5)
C-ai-γi=0,i=1,…N
(6)
根据上述公式可得,线性加权组合加权系数ai与数据对象xi可获得最小超球体的中心。对偶问题的最大化问题可由最小化问题转化可表示为
(7)
由式(8)表示其约束条件
(8)

假如球体的半径等于或大于新数据对象z到球体之间的距离,则此数据对象可称为正常数据,反之为异常数据表示为
(z-a)T(z-a)≤R2
(9)
数据空间在球形的分布可由上述方法描述。现实情况中,呈现球状分布的紧凑数据依然不能由去掉异常数据之后获取。内积形式描述式(7)最大值求解问题,为获取一个更精准的数据描述,利用满足Mercer定理的核函数[9]K(xi·xj)替代内积(xi·xj),表示为
(10)
正常数据是指该测试对象满足上述公式,不满足为异常数据。核函数用K(x·y)表示,通常使用以下核函数
多项式核:K(x·y)=(x·y+1)d
Sigmoid核:K(x·y)=tanh(v(x·y)+c)
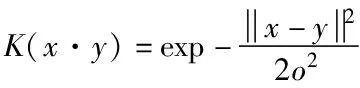
经广泛研究,对于大量不同类型的分类问题,更适合应用较广的高斯核函数,因为其具有较强的泛化学习能力,所以本文使用高斯核函数。
2.3.2 支持向量数据描述异常检测分类器优化求解
设计最小闭包球算法优化求解支持向量数据描述异常检测分类器,通过找到最小闭包球解决支持向量机问题,用来降低训练算法的时间和空间复杂度。支持向量数据描述通常解决单类问题,其也可表示为一个最小闭包球问题。最小闭包球问题形式化描述及求解算法过程如下:

用以下式(11)形容支持向量数据描述问题
(11)
上述式(11)中,从输入空间至高维特征空间的映射用φ(xi)表示。
用矩阵描述与式(11)对应的对偶问题
(12)
上述式(12)内,核函数矩阵是K=[k(xi,xj)];拉格朗日系数[11]是a=[a1,…,am]。
式(12)为二次规划问题,依据求解a可得
(13)
R=a’diag(K)-a′Ka
(14)
可用最小闭包球问题表示式(12)形式的优化问题[12]。
用以下过程表示求解最小闭包球问题的算法:
假设用St、ct与Rt描述算法在第t次迭代中球的核心集、中心与半径。将M(S)的(1+ε)近似为球B(cB,rB)、ε>0给出,球B的中心与半径依次用cB与rB描述。

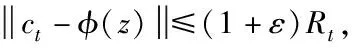
步骤4:对新的最小闭包球MEB(St+1)采用式(14)进行寻找;然后对新球的中心与半径采用式(15)(16)来计算;用ct+1=cMEB(St+1)、Rt+1=rMEB(St+1)表示。
步骤5:t=t+1,转到步骤2;
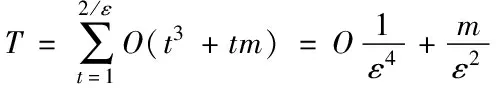
步骤4内找寻新的最小闭包球可以探知算法的空间复杂度,在找寻新的最小闭包球时,式(13)与式(14)的二次规划问题计算才采用核心集。用O(|St|2)表示空间复杂度,其在第t次迭代中需要使用。O(1/ε2)表示整个算法的空间复杂度,源于算法收敛之前最多循环2/ε次。算法的空间复杂度线性和样本点数集m不发生关系,基于ε是不变的。
对上述算法分析,分析时间和空间复杂度,得知此算法空间复杂度与样本点数m无关,但时间复杂度与样本点数m呈线性。通过上述步骤,利用最小闭包球算法,根据样本数量的增多,使该优化算法的时间、空间复杂度缓慢增长,对于高维大规模数据集求解,优化求解支持向量数据描述异常检测分类器,实现异常数据实时检测。
3 实验分析
为了验证基于HDFS开源架构的异常数据实时检测算法的有效性,在Redis网络数据集(https:∥github.com/microsoftarchive/redis/releases)中选取4000个数据,分别采用文献[3]算法、文献[4]算法和所提算法,在MATLAB软件平台上进行对比测试,分析不同算法检测网络异常数据的通信开销比值,实验结果如图2所示。
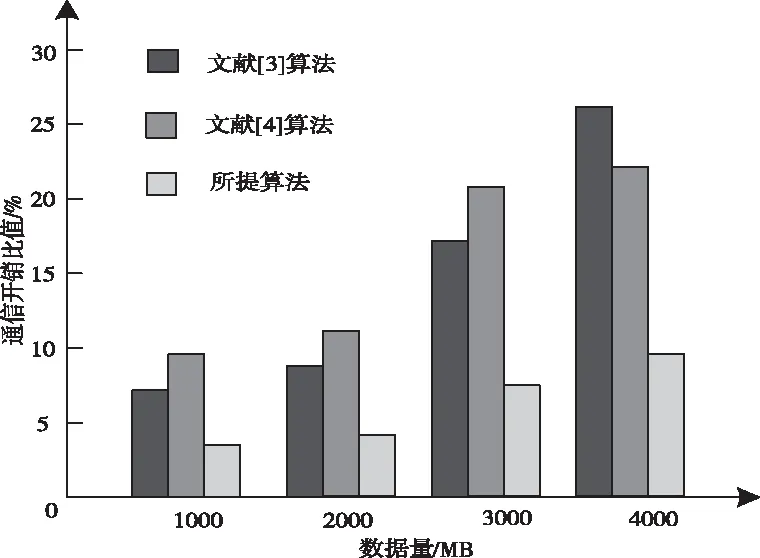
图2 不同算法的通信开销对比
由图2实验结果可知,随着数据量的增加,不同算法的通信开销比值随之增大,当数据量为4000MB时,文献[3]算法的通信开销比值为28%,文献[4]算法的通信开销比值为22%,而所提算法的通信开销比值为10%。由此可知,所提算法的通信开销比值较小,在异常数据检测时,可有效节省通信开销。
进一步验证基于HDFS开源架构的异常数据实时检测算法的检测运行时间,在数据量不同时,分析不同算法的检测运行时间,结果如图3所示。
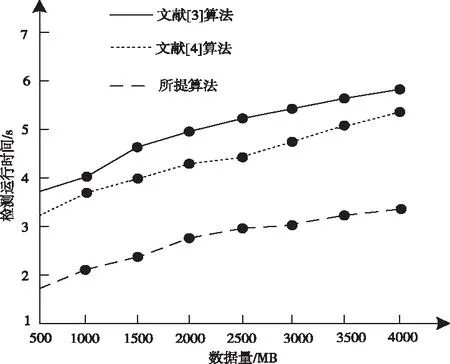
图3 不同算法的检测运行时间对比
分析图3可知,随着数据量的增加,不同算法的检测运行时间随之增加。当数据量达到4000MB时,文献[3]算法的平均检测运行时间为5.3s,文献[4]算法的平均检测运行时间为4.6s,而所提算法的平均检测运行时间仅为2.5s。由此可知,所提算法的检测运行时间较短。因为所提算法利用线性关系描述时间复杂度,对于高维大规模数据集求解,根据样本数量的增多,优化算法时间,从而有效缩短检测运行时间。
在此基础上,对比不同算法的异常数据检测率,对比结果如图4所示。

图4 不同算法的异常数据检测率对比
根据图4可知,当数据量达到4000MB时,文献[3]算法的平均异常数据检测率为89.6%,文献[4]算法的平均异常数据检测率为91.2%,而所提算法的平均异常数据检测率高达98%。由此可知,所提算法的异常数据检测率较高,具有较高的检测能力。因为所提算法对于求解高维大规模数据集,采用最小闭包球算法,随着样本数量增长,其空间复杂度较为缓慢,从而提高了异常数据检测率。
为了验证所提算法的准确性,在数据量不同时,对比不同算法的误报率,结果如图5所示。
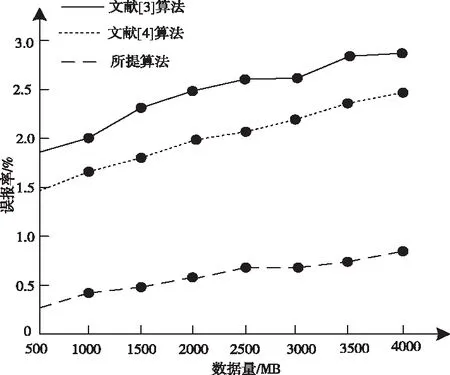
图5 不同算法的误报率对比
由图5可知,随着数据规模的增大,不同算法的误报率逐渐增高,当数据量为4000MB时,文献[3]算法与文献[4]算法的最高误报率为2.8%、2.48%,而所提算法的最高误报率为0.8%,低于其它两种算法,且所提算法的误报率始终保持在1.0%以下,由此可知,所提算法的误报率较低。因为所提算法设计最小闭包球算法优化求解支持向量数据描述异常检测分类器,通过最小闭包球解决支持向量机问题,从而降低训练算法的误报率。
4 结论
为了提高异常数据实时检测算法检测率,降低误报率高,缩短运行时间,提出基于HDFS开源架构的异常数据实时检测算法。根据HDFS建立数据分布式云存储体系,设计多级哈希表搜索算法查询异常数据,采用支持向量数据描述,结合最小闭包球算法,降低训练算法的时间和空间复杂度的同时,实现异常数据检测。该算法可以有效提高检测率,降低误报率,缩短运行时间。在未来仍需进一步研究,对于数据的海量增长继续对算法性能进行改善,尽可能实时检测更多的异常数据。
