融合多源信息的平行语料库相似句段去重算法
2021-11-17左世亮刘稳良
左世亮,刘稳良
(上海应用技术大学,上海201418)
1 引言
我国和沿线国家之间的交流愈发紧密,各类深度合作项目日益增多,这对语言服务企业与人才能力都设定了更高的标准要求[1-2]。语言服务企业为支撑翻译生产,创建了一系列平行语料库,为多元化语言服务需求提供充足便利。但在多源信息发展的今天,随着语料数量持续增长,出现越来越多的相似语句,为翻译工作带来诸多困扰[3],由此要对相似句段进行去重,保障语言服务效率与水平。
关于文本去重问题,陈平华[4]等提出一种采用签名与哈希技术的云存储去重方案,在数据去重过程中运用双层校验机制审计数据完整性,校验文件完整性并精确定位损坏数据块;构造Merkle哈希树生成校验值,计算去重标签,确保检测到重复数据。但该方法局限性高,不易广泛推广。邓玉辉[5]等提出一种基于混合页面的磁盘缓存去重策略。在磁盘缓存中引入混合页机制,保留基页增加巨页,自适应调整巨页大小让命中率最大化;监测基页、巨页冷热程度,将重复率高的冷巨页拆分为基页,实现基页、巨页动态转换;利用重删技术对基页、巨页依次实施去重,在命中率最大化同时保持去重率,但方法去重速率缓慢。
综合以上内容,本文创建一种基于词频-逆向文件频率(term frequency-inverse document frequency,TF-IDF)的平行语料库相似句段去重算法。对齐平行语料库互为对应关联的句子,推导句段相似程度,加强后续去除速度,融合TF-IDF技术与单词主题相关性,计算关键词权重,删除高权重句段,达到平行语料库句段去重目的。
2 平行语料库句子对齐计算
为平行语料库创建句子以及对齐关联,明确源语言句段内哪些句子和语料库语言中的句段互为译文。句子对齐关联可能包含多种形式,最常见的是源语言句段内一个句子与目标语言句段内的一个句子对应[6],此外还包含如下几种状况:源语言中一个句子与目标语言内两个或若干个句子对应;源语言中两个或若干个句子与目标语言中一个句子对应;源语言中两个或若干个句子与目标语言中两个或若干个句子相对。在特殊情况下,翻译与原文存在较大差距,省略不译状况时有发生,同时为了让目标语言更便于理解,增添解释性语言。此时会产生某种语言文本的句子与其它语言没有句子相互对应的现象。本文使用召回率与精确率,按照特有参照对句子对齐算法性能实施评估。
若一段对齐的双语句段是〈S,T,Ar〉,Ar为参考对齐,针对随机一个和Ar相同级别的对齐A,A内准确的双语句段数和Ar全部双语句段数的比率就是A对应于Ar的对齐召回率,计算过程为
Recall(A,Ar)=|A∩Ar|/|Ar|
(1)
从上式可知,对齐召回率是在对齐内准确的双语句段数和全部准确双语句段数的比值,证明A内获得正确对齐句段的个数越多。
如果一段对齐的双语句段为〈S,T,Ar〉,Ar为参考对齐,关于随机一个和AR拥有相等对齐长度的对齐A,A内准确的双语句段和A内全部双语句段的比率为对齐精确率,即
Precision(A,Ar)=|A∩Ar|/|A|
(2)
在真实运用中,通常采用F评估法当作权衡对齐性能的指标,该方法是对齐精确率与召回率的调和均值。
传统对齐方法依靠句段内的单词个数,没有考虑单词自身形态与含义。在此前提下,创设一个概率模型,同时挑选最大概率路径当作对齐输出,该模型的参数涵盖句段类别概率与长度相对概率[7]。
使用基于长度的句子对齐方法,其核心思想是句子长度越相近,则变成对译句段的概率越大。
3 句段相似度分析
按照源语言文本,从大范围多源信息平行语料库内找到最为接近的翻译范例,确保译员准确高效地完成翻译工作,这就是句段相似度计算的根本任务[8]。现阶段对于相似度暂无一个确切定义,在不同实际应用中,相似度内涵各不相等。本文依照如下内容进行相似度类型区分:A和B间的相似度与它们的共性及区别有关,共性数量越多,相似度越高;区别越多,相似度越小。文中的相似度代表两个句段字符重复水准,按照句段相似水平将去重句段划分为以下几种:句段全部重复、句段内涵重复、句型转换和少部分同义词变换。
将句段描述为单词集合
π(S)={W1,W2,…,Wn}
(3)
式中,S代表句段,Wi是句段内的单词。
句段S1与句段S2之间的表层相似度为
Sim(S1,S2)=2*Γ(π(S1)Iπ(S2))
/(Len(S1)+Len(S2))
(4)
式中,I代表集合的求交运算,Γ是集合的因子数量,Len是句段长度,也就是句段内包含的单词个数。
两个句段表层相似度越高,输入的待翻译句段和翻译实例相同的单词越多,保障了平行语料库译文的高质量。
句段中词汇信息熵值越高,表明该词汇在语料库内出现的频率越小,对分辨句段相似度的作用越好,计算流程为
H(w)=lg(M/m)
(5)
式中,w为词汇,M是平行语料库内的句段总数,m是出现词汇w的句段数量。
相似度临界值可以更好地约束句子相似度运算精度,将临界值设定在0.6~0.7之间。句段S1与句段S2的信息熵相似度临界值计算过程为
SimH=∑H(wi)
(6)
实施待选实例搜索过程中,在多源信息下的平行语料库内挑选一定数量的句段,再使用式(6)的信息熵相似度临界值计算过程,从句段中选出某些句子。
值得注意的是,本文方法无法在全部平行语料库内直接使用式(6)择取待选实例。原因在于,假如在全部平行语料库中直接使用信息熵相似度临界值筛查待选模式,就会给某种特殊用词过多比重,致使筛选出的翻译句段和预期翻译结果相差较多[9],降低了译文整体翻译质量。
使用基于泛化的匹配度计算,在泛化前提下算出待选实例和输入的待翻译句段之间的模糊匹配度。按照待翻译的输入句子对翻译实例的有关语法单位实施泛化,构成拥有相对复杂特征的参变量,凭借泛化实例类比推导组建输入句段的译文。
类比推理是一个变量属性收敛匹配的过程,译文结构利用对泛化实例采取替换、拷贝、删除等动作来实现。实施泛化匹配过程中,要考虑词形、词类、词的同义、反义和涵盖的语境信息[10]。
词语泛化匹配度代表输入句段内的某个词语和翻译实例内的某个词语能够互相替换的几率,与词汇相似度具有密切关联。将词语泛化匹配度的计算方程描述为
LGMD(w1,w2)=f(SimLex,SimPos,SimCon)
(7)
式中,α、β、γ为三个系数,代表不同状况下的可信度权值,SimLex为词汇相似度,SimPos为词性相似度,SimCon是语境相似度。SimLex的运算过程如下
SimLex(w1,w2)
(8)
式中,dis_sem(w1,w2)代表词汇w1、w2之间的语义距离,α为权值系数。语义距离的运算使用基于HowNet方法,该方法提供的义原分类树,用树的模式呈现出每个义原及其关联,树内父节点与子节点的义原拥有上下位关联[11],采用义原分类树推算两个词语间的语义距离。
SimPos推导公式为
(9)
其中,Pos(w)为词汇w处于句段中的词类标注属性。
SimCon推导公式为:
(10)
式中,ω是权值系数,dis_con(w1,w2)是单词w1、w2的上下文偏移间距。
句子泛化匹配度是翻译实例以范例形式,对输入句段实施类比翻译的可靠度,计算过程为:
(11)
式中,分母内的Len(s1)、Len(s2)依次代表输入句段与翻译实例的句段长度。
最终句段相似度计算公式为:
similarity(s1,s2)=a·SGMD(s1,s2)
+β·Sims(s1,s2)+γ·SimH
(12)
通过以上过程,就能从平行语料库中找出最相近的翻译句子,提升后续相似句段去重效果。
4 基于TF-IDF技术的平行语料库相似句段去重算法
传统相似句段去重将文档分词识别获得的关键词当作特征值,权重是关键词出现的数量。词性与词长是权衡单词权重的主要元素,全方位呈现句段具体内容,提升相似句段去重精确率。权重只取决于单词出现的次数,句段内的某些核心内容会发生损坏,大幅减少了去重精度。为处理这一难题,本文运用TF-IDF技术与单词主题相关性推算关键词权重,剔除权重值较高的句段,实现准确高效的平行语料库句段去重目标。
TF-IDF技术主要计算关键词在句段内的重要程度,TF是关键词在句段内出现的频度,将关键词ti的TF描述成
(13)
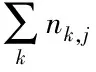
逆向文本频率IDF,代表关键词所在句段处于句段集合中的比例,记作
(14)
式中,|D|是ti句段集合内的句段总数,|{j:ti∈dj}|为包含关键词的句段个数,并保证是ni,j不等于零的句段。
关键词i在句段j中的TF-IDF定义是
tf-idfi,j=tfi,j×idfi
(15)
TF-IDF技术的有限性在于,句段出现次数越高,重要程度就越低,这对于某些句段而言拥有一定偏差,某类关键词汇在句段中出现的次数也很多,要赋予此类词汇更多的权重。
本文使用单词主体相关性当作附加权重,把专业术语单词长度设定为辨别单词主体相关性的凭据。选择平行语料库内的关键词为数据集合[12],计算数据集合内20000个中文术语长度,同时实施正态拟合,其结果如图1所示。
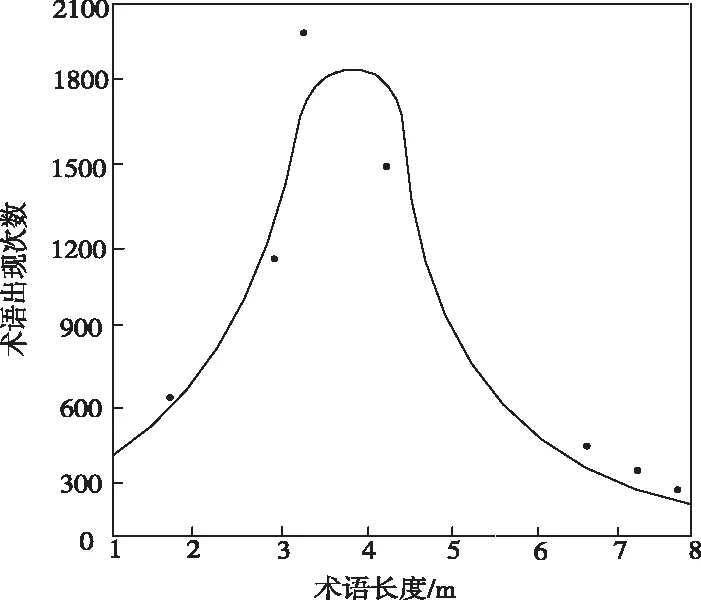
图1 中文译文长度拟合示意图
图1内的拟合正态分布函数是
(16)
将拟合后获得的拟合函数确定系数书写成Rsquare,该系数越趋近于1,证明拟合函数对真实数据的诠释性能越强。
单词长度约接近5,伴随函数值的升高,单词主题相关性也随之上升。
运用单词主题相关性函数当作附加权重,能提升TF-IDF技术对权重计算的准确性。最后得到关键词e的权重计算方程为
w(e)=tfe,j×idfe×(1+len(x))
(17)
以下为相似句段去重的具体步骤:在待检测的文本内选择一个句段Si和目前已知的句段集合S,将Si与集合内的句段按一定顺序分别计算其权重,假如某个句段Sj和Si的权重超出设定的临界值,那么Si就无法作为一个全新的句段放入S中,反之将其添加至S中。
5 实验分析
为证明所提方法去重成效,对该算法与文献[4]、文献[5]方法进行实验分析,开发语言为Java。图2是三种方法在相同状况下对同一文本集句段进行去重的运算时间。
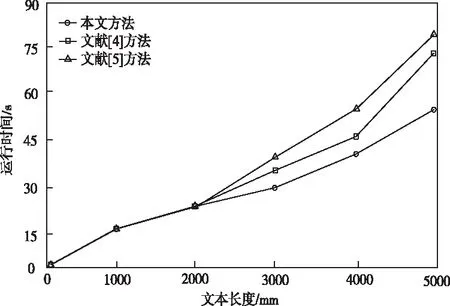
图2 不同方法下的去重运算时间
从图2中可知,在句段数据量较小时,三种方法均耗费很少的运算时间,去重时间近乎相等。但在实验数据量逐步上升后,所有方法的时间呈现指数形式增长,文献[5]方法所耗时间最长,其次为文献[4]方法,所提方法耗费的运行时间最短。出现此种现象的原因是,本文方法充分考虑了句段相似度在不同情况下的重复模式,可使用在任何长度的语句比对中,增强了算法去重识别速率。
利用去重召回率与精确率权衡算法的实用性,把去重的关键放在短句与长句比率在0.3~0.9之间的句子。通过多次实验,设定的平衡参数λ1与λ2如表1所示,相似度临界值为0.6。

表1 平衡参数设定
实验第一组数据为自主研发的样本150个句段,第二、三、四组数据从互联网中得到,分别为750、630、480个句段,实验结果如表2所示。
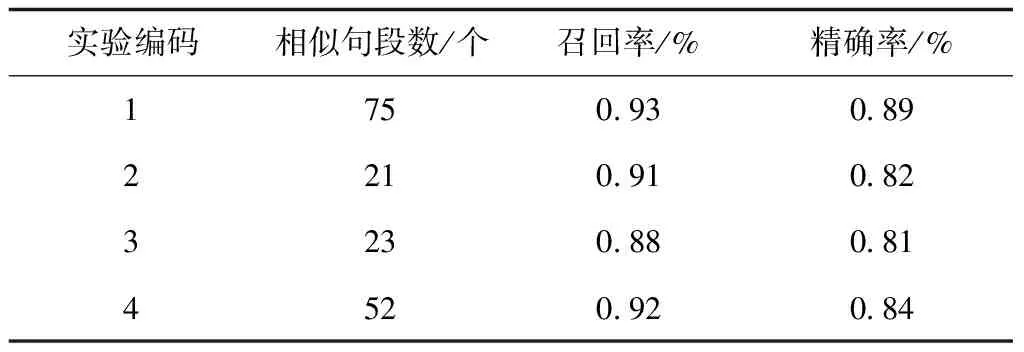
表2 算法召回率和精确率实验结果
从表2中可以看到,本文方法召回率与精确率均为最高的,另外三组数据均存在一定的误判现象。在实际操作中,在相关度分析时制作一个分析报表,报表内记载被系统认为相似的句段编码与内容,再利用人工判别是否相似,去除误判结果。
使用自主研发样本数据,通过更改临界值大小,观测临界值对本文方法召回率与精确率的影响,如图3所示。
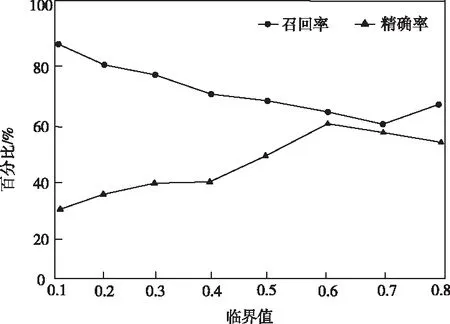
图3 临界值对本文方法去重效果的影响
从图3看出,阈值在0.6~0.7之间时,召回率与精确率实现很好的均衡,这与上文设定结果相同,以此也证明了本文方法的可靠性。
6 结论
为提升语言服务企业翻译工作时效性,提出一种基于TF-IDF技术的平行语料库相似句段去重算法。该算法对整体重复与特别相近的句段拥有极强的去重效果,但该方法研究语义相似性的内容较少,后续会对此点进行改进,深入提升算法去重的完整性。
