云计算下通信大数据多属性特征引导融合仿真
2021-11-17李洪波周春姐
李洪波,周春姐
(鲁东大学信息与电气工程学院,山东 烟台 264025)
1 引言
计算机技术水平发展的同时,现代企业和个人所需要的信息数据要求也越来越高,造成了现代网络数据中心面临无法有效调配、汇总数据以及无法满足当前网络用户对信息数据量稳定性、安全性以及加密性的各方面需求的双重矛盾。在这样的情况下,寻求一种基于当前通信大数据特征属性,进行通信大数据引导融合的方法成为了当前网络数据中心研究领域亟待解决的核心问题[1]。
由于目前绝大多数通信网络由多种网络节点构成,其目的就是综合网络大数据,满足云计算下的用户要求。所以有关人员相继提出根据网络节点和辐射区进行属性特征融合的数据融合策略,这种策略可以简称为“节点融合”[2]。节点融合主要依靠PHD节电传感器,根据滤波算法模拟出各节点的状态特征,计算数据关联度,并采用协方差交流法,实现数据引导融合。此外还有人提出了基于支持向量机的属性融合方法和基于深度学习的属性融合方法。前者通过训练传感器的属性信息融合度预测值,以此获取数据融合阈值,根据阈值的高低能否达到标准值,获取最终的融合结果;二者需汇聚网络中全部数据节点特征,并利用CNNM模型获取每个节点终端的数据原始特征,在此基础上,将得到的特征结果及融合数据传输到汇聚节点,完成数据融合。
上述几种通信大数据属性引导融合方法均存在属性节点生存期较短的问题,究其根本在于,对当前数据进行粗犷式融合,没有真正做到数据属性特征梳理,导致节点属性很容易同化或错乱[3]。为了有效解决属性节点生存期较短问题,提出新型云计算下通信大数据特征融合技术。
2 通信数据特征融合技术设计
2.1 信息数据团集成
在对当前通信大数据多属性特征引导融合过程中,因为数据堆积环境的负载特殊性,需要将当前用户所需要的特征数据先划分为不同的数据团,根据每个数据团最关键的属性信息,划分为各个数据块,并求得数据块密度[4],以数据块密度作为数据团集成标签,最终完成信息数据团集成。以下为具体集成步骤:
假设A代表当前数据G的最高有效连续性矩阵,V,E代表当前通信数据的实际节点以及数据边的集合,P代表当前数据的预设划分,Gi代表当前划分P的一个实际数据团,Vi,Ei分别代表当前数据团Gi的实际节点和边的数据集合,根据式(1)将当前用户信息全部划分为不同中的数据团,其表达式为
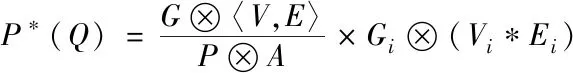
(1)
对获取的数据团进行数据划分,得到划分后的数据模块p(g),其表达式为
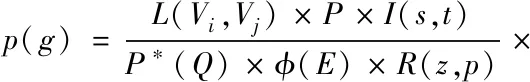
(2)
式中,L(Vi,Vj)代表当前节点集合的实际边数据量,I(s,t)代表当前通信大数据的实际信息增益值,ϖ(E)代表不同连度下的节点数据量,R(z,p)代表当前大数据的属性划分,ϑ(h)代表各个节点对当前数据模块的实际贡献值[5]。
在式(2)的基础上,对数据模块的密度μ*(s)进行计算,其计算公式为
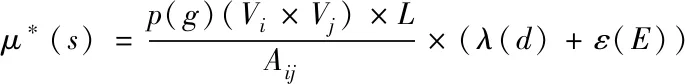
(3)
式中,Aij代表当前通信大数据之间的连接性矩阵,L代表数据节点V和Vj之间数据边界的数量,则可以根据公式直接定义当前数据模块的密度,λ(d)代表当前数据节点的实际原始数据,ε(E)代表不同数据之间的属性值关联类别和规则[6-7]。
通过上述步骤完成数据块的密度求解,数据块密度可视为数据团的集成标签,根据标签能够实现数据团进行集成划分。在此基础上需要计算集成标签的初始重要程度。
假设RC(ei→ej)代表当前数据块ei和ej之间的相对距离,根据式(4)计算当前数据块的实际权值。其计算公式为
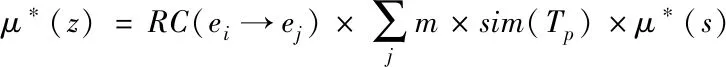
(4)
式中,m代表当前通信大数据基础数据团的总量,sim(Tp)代表任意两个数据聚类之间的实际关系距离的平均值[8]。
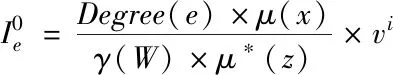
(5)
式中,vi代表当前数据内部的实际节点总量,Degree(e)代表当前模式图G中,数据表e的相对节点数量,γ(W)代表用户核心数据样本类型数据集,μ(x)为样本中的数据种类比[9]。
利用R,S分别指代当前大数据网络用户所需要的不同数据聚类主题,则根据数据源的聚类思想,将不同类型数据团进行有效集成,作为当前大数据信息不同数据类别的主题组,根据式(6)进行表述。
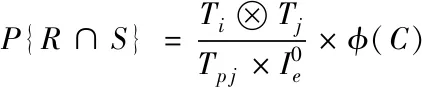
(6)
式中,Ti和Tj分别代表当前数据组中的数据表,Tp代表关系数据表Ti的权值。φ(C)代表当前数据团集成聚类的结果数量[10]。
综上所述可以确定,对当前数据堆积环境下的使用用户,在进行通信大数据分类过程中,可以采用上述方法将其全部转化为不同类型的数据团,再根据数据聚类思想将数据团中的通信数据信息和数据属性特征优化成不同的数据组,以此实现数据海量堆积情况下的数据团集成。
2.2 数据属性特征计算
通过上述聚类集成方法将数据信息进行高度集成以后,即可将集成获取的信息团进行分解,对信息属性特征进行计算。采用粗糙集计算方法,对当前集成信息团的数据属性进行评估,从而为后续特征引导融合提供数据基础[11-12]。
设E为当前数据决策树的属性描述数值,D为当前数据属性架构的集合,则信息团分解公式为
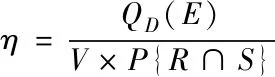
(7)
式中,QD(E)表示当前信息特征属性E对当前属性架构集合D的正域描述,V表示当前数据特征集合的实际基数。根据式(7)对分解后的信息团进行属性特征计算,其表达式为
η′=η-Dj
(8)
式中,Dj表示数据属性的对应条件依赖程度,即该数据在特征数据集中的权重[12]。
根据粗糙集来确定数据属性特征比例关系,需要对当前通信大数据特征权重值进行计算,其详细步骤如下:
step1:根据运算数据能够获取的计算属性值,可以获取当前数据集属性集合权重,即数据集属性集合依赖值,计算公式如下
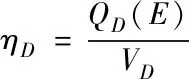
(9)
setp2:根据式(9)获取的数据,进一步计算当前属性Dk对当前数据属性SE的依赖性,即
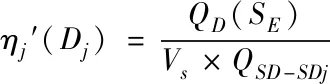
(10)
setp3:根据以下公式计算当前数据集第j个数据属性的归一性系数。
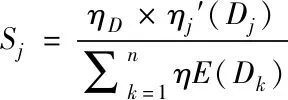
(11)
根据上述的公式可以对当前数据属性权重进行计算,以最大权值作为模糊决策树的根节点、然后开始进行特征计算。
设通信大数据构成集合可以用Y={(yj,zj)|j=1,2…,e}表示,其中,yj=(yj1,yj2,…yje)能够用于描述当前数据的权值集合;(B1,B2,…,Be)用于描述当前数据的对应属性值。根据下列公式可以确定当前数据特征集合的综合期望值。
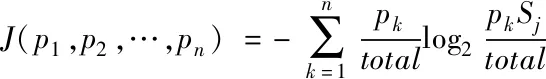
(12)
假设,当前的数据属性为Bg(g=1,2,…,e),拥有r个不同属性的信息权值,则将其属性分解沟可以获取如下描述
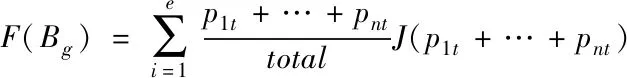
(13)
利用当前公式可计算的数据属性Bg可以确定其信息增益对比值。
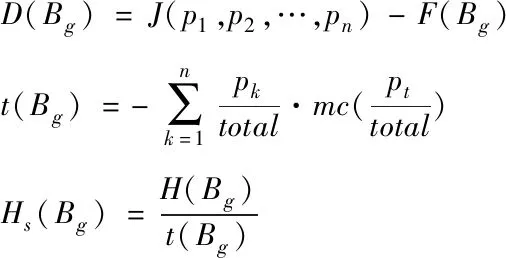
(14)
根据以下公式数据,可以针对上述计算获取的增益对比值,建立优化决策树
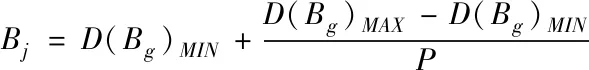
(15)
将当前信息的增益比最大值数据作为数据决策树的各项分支数据,以此建立决策数据节点。再根据节点信息属性权重,设置对应分支,从而获取下级对应子节点,完成整个决策树的建立。
根据上述阐述的方法,可以计算数据属性的信息量,从而进行数据特征挖掘,完成数据属性的特征计算。
2.3 信息属性排序
属性特征计算完毕后,需要对其进一步排序,才能进行最后的属性引导融合。通过输入输出关联法,排序和计算当前决策树信息属性特征权值。同时,采用分离法对去掉部分属性的当前信息进行信息组内距离间距比值的计算,并根据联系法对输入和输出特征的属性关联度进行计算,其计算公式为
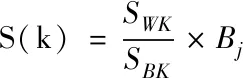
(16)
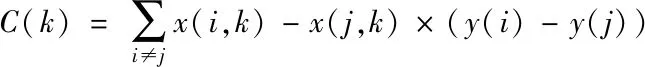
(17)
在式(16)与式(17)中,S(k)表示当前数据属性下实际输入值的关联梯度;C(k)表示当前数据属性下实际分离值的关联梯度;sign代表当前数据符号函数;SWK代表去k特征数据间的组内距离;SBK代表去k特征数据之间的组间距离。x(i,k)和y(i)分别表示当前样本数据的属性值和输出值,此时数据k属性的权值可以根据以下公式进行计算。
R(k)=αS(k)+(1-α)C(k)
(18)
式中,α为常数项,其值为0到1之间。
式(18)中,通信数据属性的原始数据较大,也会导致其属性特征权值增大。反之则会减小。这就导致了在后续特征引导时会出现信息数据属性误差,因此需要对当前数据特征属性进行归一化处理,从而有效消除数据误差。设计采用最大规范法,对当前原始数据进行线性交叉,设minA和maxA分别表示当前数据实行的最大值和最小值,计算式如下:
(nmax(A)-min(A)+nmin(A))
(19)
通过上述公式,可以获取对当前通信信息排序的方法,输入和输出的数据关联公式如下
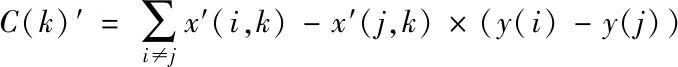
(20)
根据以上关系式和通信大数据样本值的计算变化,可以获取当前特征输入值和输出值的重要性衡量,对于特征数据库属性样本值,输入和输出变化越大,属性的重要程度就越高,再根据当前数据信息量计算重要性进行排序计算,即可完成最终结果排序。
2.4 实现数据融合
通过寻找和提取数据特征,尽可能明确当前通信数据的特征子集,在利用上述计算公式对特征进行过滤式选取。在2.3节提出的特征排序的基础上,利用比对法筛选当前大数据的特征属性需求性。
通过相似性度量方法对不同数据样本的数据相似程度进行描述,描述过程通常采用欧氏距离计算,该算法表示为
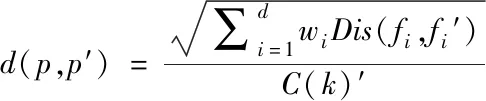
(21)
式中,p和p′表示当前通信数据,d(p,p′)为数据中的信息需求实际差异性,fi和fi′分别表示数据内p,和p′中第i个特征数取值。wi取值为1时,表示当前特征没有被融合;d表示数据维数。
利用相似数据K对当前通信数据进行估算,在选择同类型数据后,需要对其进行调整,确定数据评估结果。利用平均值法,选择数据K作为平均值估算样本数据,并根据相似性进行引导融合,融合公式为
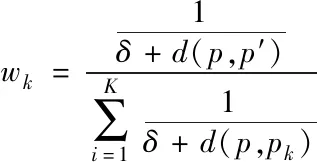
(22)
式中,pk代表当前数据p特征属性最相近的数据,d(p,pk)表示数据之间的实际距离;δ表示常数。
根据上述论述,在对当前云计算通信数据特征属性计算和排序后,利用当前数据用户信息间的数据相关性进行数据度量,可以实现数据属性的初选,再确定特征子集,最终实现多属性的引导融合。
3 仿真研究
为了证明上述设计的云计算下通信大数据多属性特征引导融合方法的可用性,需要进行仿真。本文仿真平台采用Weak3.08,凭借Weak3.08高效的数据特征仿真能力,对本文方法的有效性开展实验。
仿真从当前CUI数据库中,调借了4个无任何标签的模块化数据集(KGE、Docword、USC_nytimes、Househoid),实验通过比较上述设计的融合方法和传统基于支持向量机的特征融合方法的仿真特性进行有效性判别,特征参数选取数据节点融合能耗以及节点挖掘率。表1给出了实验所用的五组数据集具体情况。
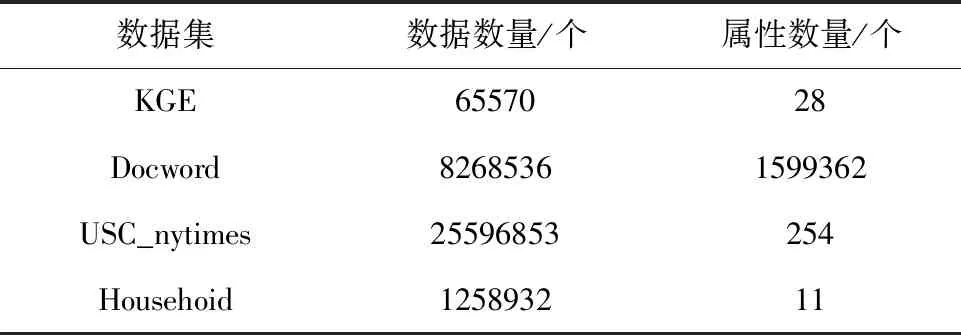
表1 实验用数据集
仿真具有多个数据约简方法,通过对数据需求的特征识别和融合分类完成实验。图1给出了实验中两种方法的节点融合耗能,其结果如下。
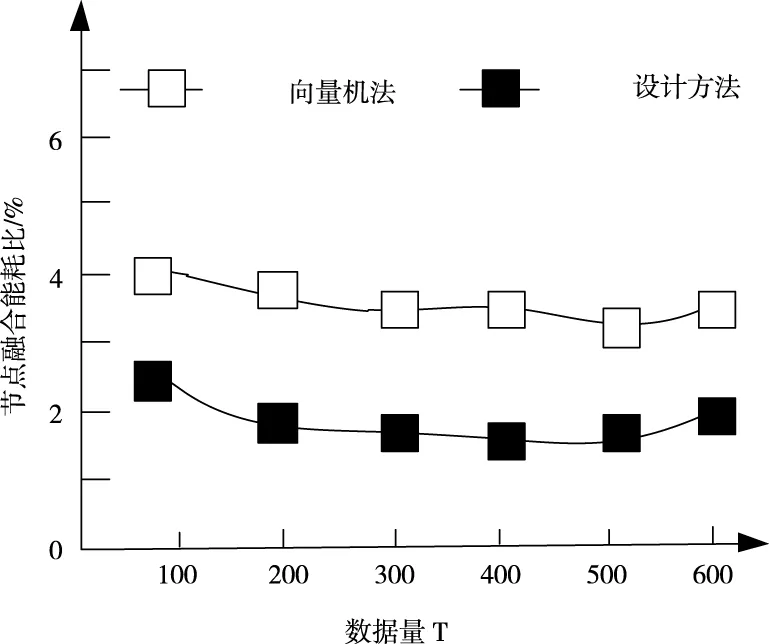
图1 融合能耗对比
根据图1能耗数据可以看出,随着数据量的叠加,两种方法的能耗没有明显的增减变化,证明两种方法均存在较高的稳定性。但是根据数据结果可以看出,此次设计的融合方法与传统向量机法相比,综合能耗更小,平均能耗比例均在3%以下。
在相同的实验环境下,通过对比10组不同的实验数据的节点挖掘率,进一步验证设计方法的有效性,其中A表示当前组别序号,X表示设计方法的挖掘率,Y表示传统方法的挖掘率。具体数据如下。
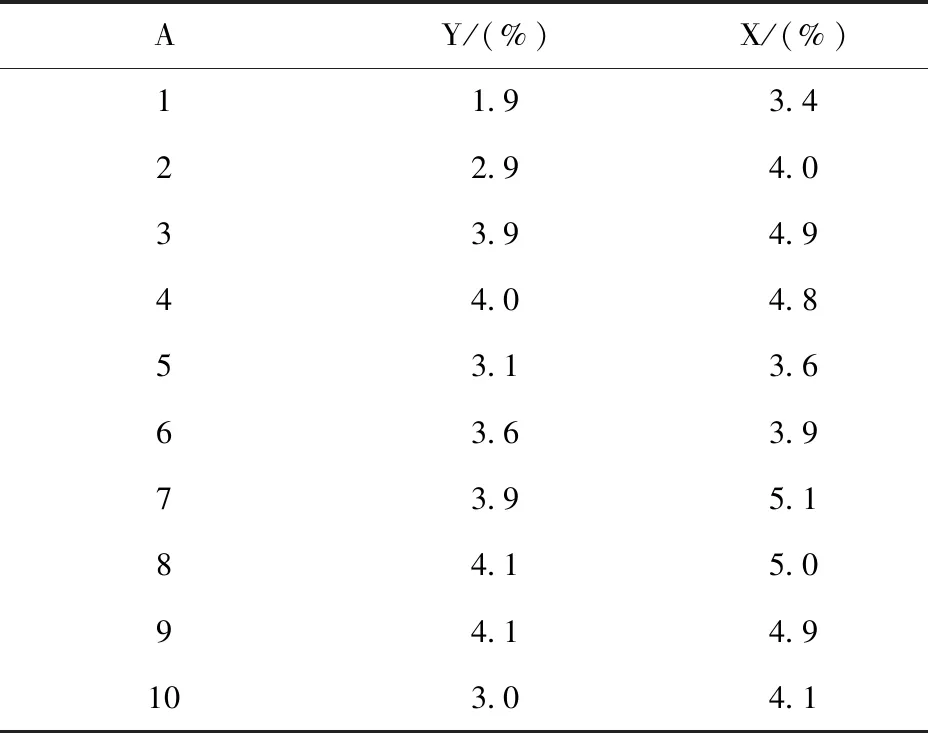
表2 挖掘率对比表
因为数据挖掘样本完全随机选择,其数据类型和数据量较为多元化,所以两个实验组获取的挖掘率没有明显的规律。但是通过数据统计可以确定,上述设计方法的实际挖掘率明显高于传统方法,再次验证了本文方法的优越性能。
4 结束语
高速增长的通信数据是现代网络资源整理汇总的核心,也是未来数据管理领域面临的重要挑战。提出的通信大数据多属性特征引导融合方法可以有效提高节点存活周期,从而实现特征引导融合效率的提高。
