基于视觉传达的多帧图像高分辨率重建仿真
2021-11-17李博
李 博
(中国医科大学,辽宁 沈阳 110000)
1 引言
图像处理技术不断发展,视觉传达技术和高分辨率重建技术在图像处理中的应用日益广泛。与此同时,人们对视频图像的分辨率要求也日益提升。但由拍摄环境、经济成本等因素影响,重构图像分辨率较低,无法满足医疗放射学、航天飞行、遥感测绘等应用领域的实际需要[1]。基于视觉传达技术的多帧图像高分辨率重建方法采用结合稀疏表示算法和深度学习算法满足上述领域的高分辨率图像,无需改变当前应用的硬件系统,在重建质量上具有非常大的优势,所以近年来,国防、医学、智能交通、公共安全领域都获得了广泛的应用[2]。
三次样条插值法是常用的一种方法[3],通常情况下是以单帧图像进行空间像素点扩展,在重建过程中难以避免边缘模糊,导致重建效果不好。文献[4]方法在重建过程中,对于某些帧像素点匹配时误差较大,致使最终重建后的图像细节不够丰富清晰。为此,本文提出基于视觉传达的多帧图像高分辨重建方法。相对于以上两种方法,本文方法重建后的图像质量较好,可以保留更多的图像细节。
2 相关理论
2.1 ScSR算法及局限性分析
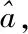

(1)

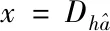
(2)
多帧高分辨图像重构时,基于稀疏表示的高分辨率重建方法是选出梯度相对较大的数值用于后续候选字典原子的构建[8]。
然而,相对图像的纹理信息极为复杂,使梯度的边缘构造大于纹理值的变化。假如候选字典原子是通过梯度特征来选取,那么建立的字典边缘构造将会偏重,致使重构后的高分辨率图像纹理结构极为平滑,影响高分辨图像重建质量。因此,通过人工手段建立的基于稀疏表示的高分辨率重建方法属于低层级特征字典,字典在一些领域上具有局限性。对图像的深层次特征进行获取,需要创建新的字典,高分辨率图像特征表述方法,是后续提高重建图像质量的必然手段[9]。
2.2 基于深度学习的深层次特征提取模型
PCANet是通过深度学习理论和卷积神经网络为基础的一种较为简易的深度学习方法。PCANet是由两个PCA(主成分分析法)滤波层、一个哈希层、一个直方图计算层构成的,可实现提取高分辨率图像的深层次特征[10]。但是与通常使用的网络不同的是,PCANet的滤波器计算效率更高。PCANet不是通过训练所得,而是通过获取高分辨率图像部分区域映射结果,再采用PCA(主成分分析法)提取高分辨率图像主成分,各个主成分为一个独立的滤波器[11]。
当样本图像采用此滤波器,并提取特征时,无需进行多次迭代运算获取最优权值,由此减少了计算时间。
为了进一步论述PCANe深度网络提取高分辨率图像特征的优势,设定输入图像为N个,大小为8×8,移动距离为1的窗口遍布多帧高分辨率图像。采用PCA计算该映射特征L1的主要部分,将L1个主要部分调试为L1个滤波器,最后得到和普通CNN一样L1个特征映射;然后,第2层与第1层处理方式相同,而第3层能够得出L2个映射特征。而PCANet的特征就是L2个映射特征,所以能够为之后的图像处理提供一个可靠的数据[12]。
因此,PCANet在提取图像特征时,实质是对图像像素点直接处理,且操作阶段加入了分块处理过程,深度网络输出的图像块数量相比之前有所增加。PCANet采用深度网络学习过程进行提取图像的特征,通过PCANet提取的图像特征与通过人工规则所获取的特征相比,其细节信息更加丰富,纹理结构更加突出,为后续高分辨率重建提供丰富的先验知识,较好的填充了低分辨率图像细节,便于超分辨率图像重建。
3 基于视觉传达的多帧图像高分辨率重建方法
文中将PCANet与基于稀疏表示的高分辨率重建方法的优点相结合,提出基于视觉传达的多帧图像高分辨率重建方法。对于多帧图像高分辨率重建方法,先假设高分辨率图像和低分辨率图像是对于各自字典所具备的稀疏表达方式,接着通过PCANet深度网络而得到图像样本特征,对字典的结合获得一对过完备字典Dh与D1。高分辨率图像重建阶段,对低分辨率图像采用相同的方式进行处理,通过PCANet方式进行深层次特征提取,将低分辨率图像特征D1稀疏所表达的系数直接作用在Dh上,就能获得相对应的高分辨率特征图像。实现低分辨率图像的高分辨率重建。在通过PCANet深度网络进行图像样本的挖掘,能够获取相对非深度网络更好的图像特征,建立的深层特征字典,也可以提升其描述能力,对图像重建后的质量有着显著的提升。
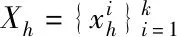

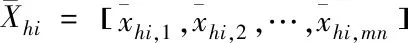
(3)
以上述所得数据矩阵X来提取特征,将提取出来的特征视为ScSR模型中的特征样本,代入PCANet的特征字典中。


(4)
通过和高分辨率图像同样的处理过程,给出提取低分辨率图像深层次细节特征结果,即

(5)
式中:Fhi与Fli分别代表高分辨率图像和低分辨率图像的特征提取结果;Bhist代表直图像编码的经过;B代表分割图像样本块数。
文中通过结合稀疏编码方法,在ScSR框架中训练字典,目标是获取一组能够表示复杂的特征样本字典对Dh与D1。使K对图像生成的深层次细节特征Fhi与Fli,在Dh与D1上有着同样的稀疏表示,且Fhi与Fli是有相同的描述系数,即
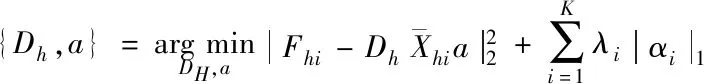
(6)
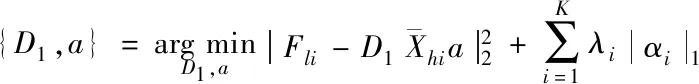
(7)


(8)
式中:N与M分别表示图像的高、低分辨率特征块元素值所进行列矢量的维度重排,1/N与1/M是采用平衡式(6),(7)的Dh与D1之间的代价,为便于后续计算,将式(8)重构得到
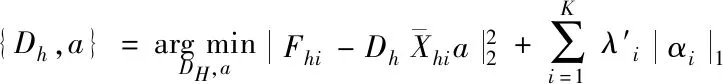
(9)
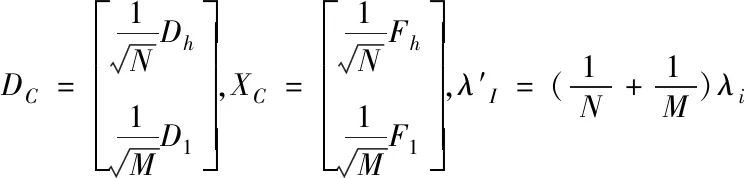
(10)
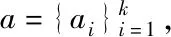
在获得字典对DC后,采用基于稀疏正则模型的高分辨率图像重建方法得出LR图像Y的重建HR图像X。
图像重建阶段,受到外界环境噪声干扰,图像中存在部分噪声,在重建后的图像会出现块效应以及图像的模糊伪影。考虑到通常情况下,采用常规的反向投影模型,不能确保图像重建之后的图像质量;在非部分局部相似性先验约束下,通过图像与图像之间的相似块进行匹配,来更好地保存图像的细节。相对重建后存在的图像块效应和模糊伪影,进行消除,在反向投影全局优化的基础上引进非局部的相似性经验约束,来优化HR图像。文中的全局约束与非全局约束模型X*的表达式为
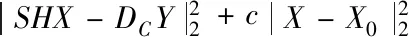

(11)

4 实验结果与分析
4.1 实验环境与参数分析
仿真环境为Pentium M1.60GHz CPU,760M RAM。为了证明本文方法的效果,对本文方法与文献[4]方法和三次样条插值法进行对比分析。
结合相关仿真工具对图像模拟实验。假如使用高斯模糊模型,设定3×3区域不变的高斯滤波器,将其采样因子设定为4,对所有低分辨率图像都加进高斯噪音,满足信噪比为30dB。
4.2 实验结果分析
图1分别是几幅测试图像使用各个算法重建的图像结果。图像像素为512×512。

图1 仿真结果
根据图1可以看出,三次样条插值方法通过图像单帧像素点进行空间扩展,在重建过程中难以避免导致边缘模糊,重建效果一般。文献[4]方法对于某些帧像素点匹配时误差较大,致使最终重建后的图像细节不够丰富清晰,重建效果劣于三次样条插值方法。相比之下可以看出,本文方法相较于其它两种方法,在高分辨率图像重构中具有明显的优势。
高频残差分量块和中频残差分量块绝对差和间的关系,如图2所示。
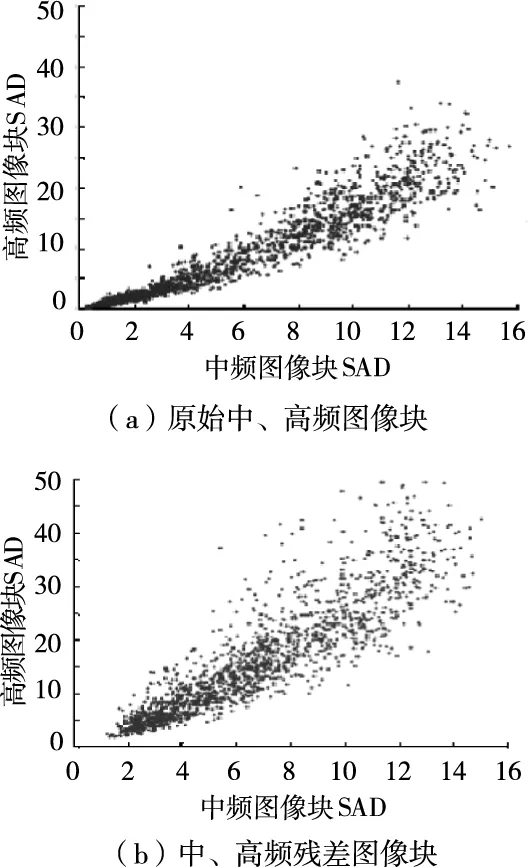
图2 中、高频图像块间的相关性
由上图可以看出,两幅图都呈现出正相关的特性,虽然残差图像块间的相关性较原始图像块的相关性相对弱一些,但从图中可见,相关性仍是非常明显的,足够支持本章算法的思路,可以利用中频残差信息来预测高频残差信息。

图3 各种方法对图像重建的结果
由上图可以看出,文献[4]方法由于帧像素点匹配时误差较大,重建图像质量没有明显的提升。三次样条插值方法具有明显的锯齿现象,且边界的锐化保持度不明显。所提方法不仅可以重建明显的边界轮廓,对不明显的边界纹理也有改善。主要原因在于所提方法通过PCANet深度网络进行图像样本的挖掘,能够获取相对非深度网络更好的图像特征,建立的深层特征字典,也可以提升其描述能力,对图像重建后的质量有着显著的提升。
均方误差(MSE)单位为常数、结构相似度(SSIM)单位为%。选取均方误差(MSE)、峰值信噪比(PSNR)以及结构相似度(SSIM)这3个评价指标进行测试。SSIM参数用来评价图像与图像之间结构失真。
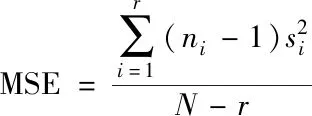
(12)

(13)

(14)
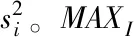

表1 仿真数值的结果标准
结合图1、2与表1结果可以看出,文献[4]方法的均方误差(MSE)的指标为30.12%,峰值信噪比(PSNR)的指标为18.65%,结构相似度(SSIM)指标为0.43%;三次样条插值方法的均方误差(MSE)的指标为26.54%,峰值信噪比(PSNR)的指标为19.58%,结构相似度(SSIM)指标为0.57%;本文方法的均方误差(MSE)的指标为5.54%,峰值信噪比(PSNR)的指标为33.25%,结构相似度(SSIM)指标为0.95%。无论从均方误差(MSE)、峰值信噪比(PSNR)以及结构相似度(SSIM)这3种指标上,还是从主观视觉角度来看,本文提出的方法重建效果均优于其它两种方法,图像重建后细节更丰富,质量更好。
5 结论
本文提出的重建方法,通过获取多帧图像的深层次特征,来增强高分辨率字典以及低分辨率字典描述图像细节信息以及框架结构的能力,保持重建后的图像具有丰富细节信息。本文方法在主观评价与客观评价上均较优,重建后的图像细节信息更丰富,图像质量更好。
未来阶段将优化重建方法的计算时间,对于影响图像的重建众多因素进行详细分析,进一步提升基于视觉传达的多帧图像高分辨率重建效率。
