基于行为数据的急性心肌梗塞患病风险预测
2021-11-17杨楚诗张朋柱
杨楚诗,张朋柱
(上海交通大学安泰经济与管理学院,上海 200030)
1 引言
我国心血管病患病率处于持续上升阶段,据推算,心血管病现患病人数2.9亿,且至2016年,心血管病死亡率仍居首位,高于肿瘤等其它疾病。随着我国心血管病负担日渐加重,已成为重大的公共卫生问题,防治心血管病刻不容缓[1]。急性心肌梗死(AMI)作为一种常见的心血管疾病,是冠状动脉急性、持续性缺血缺氧所引起的心肌坏死,具有发病急、死亡率高等特点,在欧美较为常见。中国在世界上属低发区,但近年来患病率也有上升趋势。据统计,中国2002年至2015年,AMI死亡率总体呈上升态势。
学者多采用计量的方法,根据每个因素的卡方值、P值确定每个因素的显著性水平,进而确定AMI的主要危险因素[5][9]。学者一般会设置对照组以及观察组,对照组为未患AMI的患者,而观察组为患有AMI的患者。实际上,高血压、血脂异常等危险因素难以在对照组患者中体现,观察组患者的某些指标也与对照组患者明显不同。因此利用DID思想,根据卡方值、P值确定的AMI危险因素在实际中解释性不强,无法直接根据AMI危险因素进行AMI的预防、管控。因此,采用机器学习方法,基于危险因素,对心血管疾病发生的可能性进行预测便应运而生。
AMI是多个疾病的并发症,受多种危险因素影响,且发病急,因此仅基于心血管疾病的传统危险因素来预测,准确度低,解释性不强。因此,对AMI的预测需要基于更多的变量,并尝试不同的机器学习算法。有学者利用不限于患者生理学指标的变量,以及神经网络算法,对AMI进行预测。
与以往研究不同,本文的患者数据的特征值涵盖丰富的人口学指标,包括患者的教育水平、经济情况、住宅附近楼房的密集程度;丰富的生理学指标,包括过去一年各类与心血管疾病相关或者不相关的疾病的诊断情况;丰富的患者行为指标,过去一年的服药情况、身体检查情况等。a)本文将患者的行为纳入对AMI的预测中,充分考虑近期行为会对疾病产生影响(特征选择的创新);b)基于2016年患者的各项指标和行为,预测2017年患者患AMI的可能性(数据时间跨度的创新)。相较于以往的设置对照组与观察组的研究模式,考虑到AMI是急性病,短期的行为相较于长期的行为,对AMI的解释程度更高,即近一年内被诊断为糖尿病相较于十年的糖尿病病史更可能是导致AMI病发的原因;c)对比了不同的算法对AMI预测的准确性以及算法的泛化能力强弱(算法的创新)。
2 理论支持
2.1 医疗大数据
狭义的大数据被定义为难以用现有的一般技术管理的大数据的集合,广义上其数据量(Volume)含义可以扩展延伸到数据的产生速度(Velocity)、多样性(Variety)和价值(Value)[14]。通常所说的医疗大数据,泛指所有与医疗和生命健康相关的数字化的极大量数据,种类繁多,来源广泛。可分为医院医疗大数据、区域卫生服务平台大数据、基于大量人群的医学研究或疾病监测大数据、自我量化大数据、网络大数据、生物信息大数据等六大类[14]。
2.2 机器学习
机器学习(Machine Learning),为一项多领域综合学科,涉及算法复杂度理论、逼近论、统计学及概率论等多项理论。此学科将计算机如何模拟及实现人类学习行为作为主要研究内容,探究计算机获取新知识、技能方式,将已存在知识结构予以重新组织,实现自身性能不断优化。一般包括监督、半监督、无监督学习问题。在监督学习中,数据输入对象会预先分配标签,通过数据训练出模型,然后利用模型进行预测。无监督学习中,数据没有标签。其重点在于分析数据的隐藏结构,发现是否存在可区分的组或集群。
若脱离实际,那么大数据是毫无意义的,将大数据运用到实际的决策中,才赋予了大数据意义[15]。机器学习算法是大数据分析的重要工具,为大数据赋予了实际的意义。分析师以大数据集为数据支持,利用机器学习算法,构建、评估以及不断优化模型,最终赋予模型对事件进行预测的功能。机器学习算法在医疗大数据分析中发挥着重要的作用,临床应用的机器学习算法包括浅层机器学习算法,如回归分析、决策树、基于内核的算法、降低维度的算法等;还包括深度学习算法模型,如卷积神经网络(CNN)、循环神经网络(RNN)、深度信念网络(DBN)等[16]。上述算法在分析不同类型的医疗健康大数据、预测不同类型的疾病等领域各有运用。
3 对象与方法
3.1 数据
本文数据由美国商业保险公司哈门那公司(Humana)提供,总计10万条标签数据。标签为是否在2017年第1季度被诊断为AMI,若被诊断为AMI,则AMI_FLAG=1;若未被诊断为AMI,则AMI_FLAG=0。指标包括人口学指标、生理学指标、购买药物行为、接受CMS(美国联邦医疗保险暨补助服务中心)服务情况、目前投保情况等。每个大类下的细分类目见表1。

表1 依据变量分类数据
其中,女性人数与男性人数的比例为1.31。均为40岁及以上的患者数据,年龄分布大致呈正态分布。女性AMI_FLAG=1的人数占比2.28%,男性AMI_FLAG=1的人数占比3.31%。总的AMI_FLAG=1的患者数量为2743,约占比2.8%。可见数据存在严重的正负样本不平衡问题,数据处理的第一步即为解决该问题。

图1 不同性别是否患AMI对比

图2 数据年龄段分布
3.2 数据预处理
3.2.1 缺失值处理
针对缺失值较少的变量,直接删除对应数据,比如直接删除将没有性别标签(SEX_CD)的数据;针对缺失值占比较高且对因变量可能产生影响的变量,设置一个新类(如“空类”)。

图3 数据缺失情况
3.2.2 解决正负样本不平衡问题
Chawla等人2002年提出解决正负样本不平衡问题的算法,即SMOTE算法。现实世界中的数据集只有一小部分异常示例,同样的情况下,将异常示例错误地分类为正常示例的成本比将正常示例错误地分类为异常示例的成本要高得多。Chawla等人通过将过采样类和前采样类相结合的方式,获得了更好的分类器性能[21]。
基本思想是与原样本,按照以下公式构建新的样本:
利用SMOTE算法对原样本中的负样本进行拓展,保证正负样本比例达到1:1。
3.3 特征选择预处理
3.3.1 移除低方差特征值
使用方差选择法,计算各个特征的方差值。根据事先设定好的阈值,选择方差大于阈值的特征。若方差值较小,说明该特征在所有样本上的值离散程度低,该特征的解释性不强;若方差较大,则说明该特征在所有样本上的值离散程度高,该特征的识别能力较强。
本文利用方差选择法,将242个特征值数量降低至139个。
3.3.2 单变量特征选择
利用相关系数,计算各个特征与目标值的相关系数,结合显著性水平p,对特征值进行进一步的选择。本文采取的方法为综合SelectKBest与卡方检验方法,即检验定性自变量对定性因变量的相关性,并将计算得到的卡方值从大到小排序,选择排名前k名的所有特征。
本文选取了排名前20名的特征变量作为模型的输入变量。
3.4 模型构建
医疗大数据领域多应用有监督的机器学习方法,即预先知道患者的患病标签,结合患者的各项指标,比如生理指标、病史、基因等,对患者患病的可能性进行预测。以下是对医疗大数据领域常用的机器学习算法的简单总结。
本文利用医疗大数据领域的常用的几种有监督的机器学习算法,包括逻辑回归、决策树、随机森林、GBDT等,分别构建分类模型。70%的数据设为训练集,其余的30%设为测试集,并分别计算模型在训练集和测试集的预测准确性,对比不同模型的预测准确性及模型的泛化能力。
4 结果
若模型在训练集的准确性高而在测试集的准确性不高,说明模型可能存在过拟合问题,即泛化能力不强;若在测试集的准确性高而在训练集的准确性不高,则说明模型可能存在欠拟合的问题,模型的训练程度不足。表3为选取的几个模型的训练集和测试集预测准确性的对比。可见,决策树模型和随机森林模型的预测准确性较高,且泛化能力较强,GBDT模型次之,随机森林最弱。图4是对主要特征值对模型的影响程度的测试,数值越高,则说明特征值对模型的影响程度越大。

表2 医疗大数据领域机器学习方法简介

表3 算法及其准确性
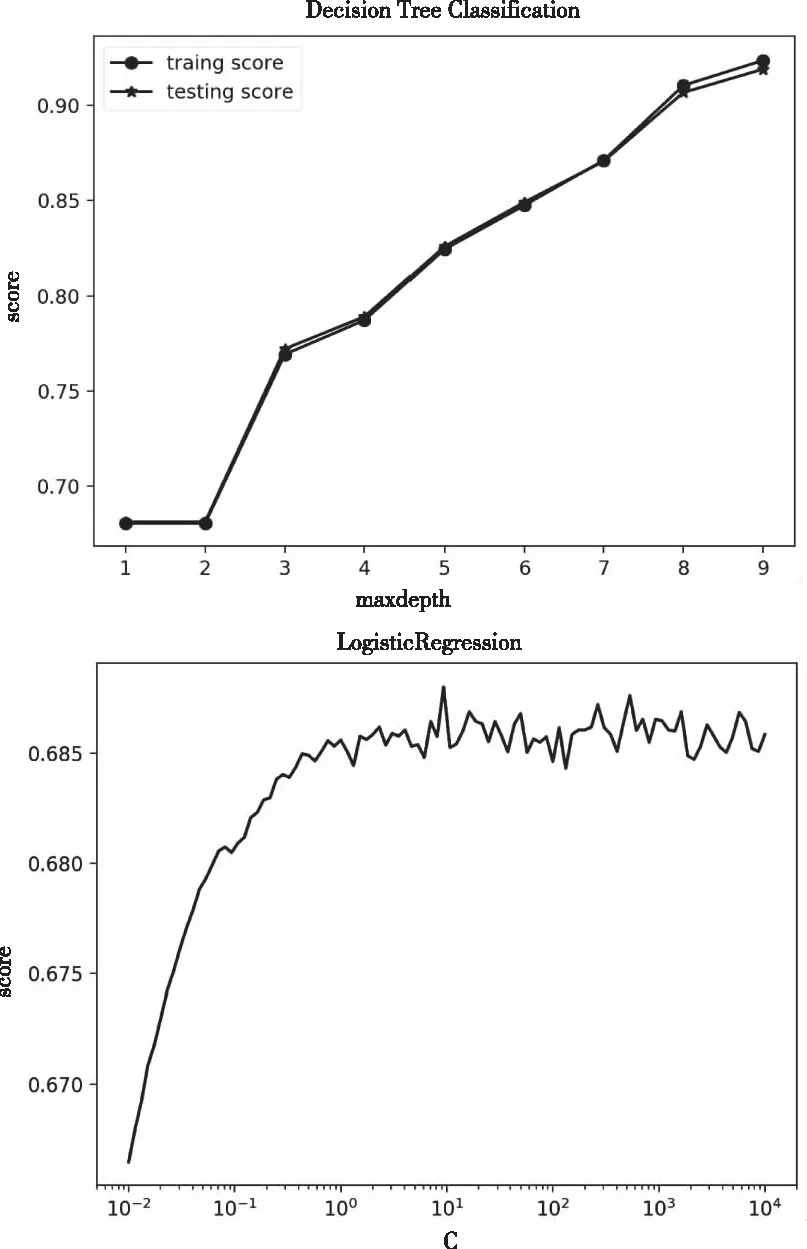

图4 参数对模型的影响程度对比
5 讨论
模型模拟结果表明,可利用患者一段时间的行为(本文采取时间段为1年)行为,预测患者未来一个时间段(本文预测未来一个季度)内是否会患AMI。并对比了不同模型预测准确性的高低及泛化能力的强弱,证明基于本文采用的数据集,利用决策树和随机森林模型,可以得到更高的预测准确性。
本文对于结合患者生理指标与短期行为进行未来患病可能性的预测有一定的借鉴意义,大多相关研究是基于患者的生理指标进行患病风险预测,且大多无法预测未来较短时间段内患病的风险。另外,本文的研究思想对于保险行业有一定的参考价值,通过预测潜在投保人未来短期内患急性病的可能性,可更好的设置保险赔付额度、保费等条款。
未来的研究可进一步深入,不局限于二分类问题,预测患者患AMI的类型;另外,算法的准确性与泛化能力存在提升的空间。
