基于Mapreduce的多源多模态大数据检索方法研究
2021-11-17魏秀卓赵慧南
魏秀卓,赵慧南
(东北师范大学人文学院,吉林 长春 130000)
1 引言
随着数据结构与应用环境的混杂,不同体系结构、不同操作系统、不同数据格式、不同存储方式等,使网络数据呈现出异构多源多模态特征。对于某事物通常可以有多种异构表现模态,比如采用文本、标签、图像,或者音视频的形式描述。因此,在数据检索的过程中,要想准确全面的检索出所有结果,需要充分考虑跨源跨模态[1]。多源多模态数据通常表现出较为显著的语义区别[2],即高层与低层语义的不一致性。这种特征使得即便在高层语义相近时,也无法保证低层语义的完全吻合。此外,网络数据量的膨胀使得检索方法需要具有大数据处理能力,而大数据的应用也必然会促进多源多模态数据的转换。所以对于多源多模态大数据的检索研究势在必行。
当前关于多源多模态数据检索主要是基于单模态扩展与哈希算法。文献[3]提出了KLSSH方法,能够根据潜在语义得到较为简单的哈希码;文献[4]提出了CCA-SCH方法,先构建不同模态的语义模型,再利用CCA采取模态间的语义融合,得到其关联;文献[5]提出了一种SDCH方法,在模态近似度的基础上,通过学习获取包含鉴别性能哈希码。此外,还有文献[6]和文献[7]等一些研究,都是围绕单模态扩展或者哈希优化,改善了多源多模态数据检索的性能,但是对于海量数据处理场景,并没有深入研究。本文在基于哈希算法与字典学习的基础上构建目标评价,并根据模态近似度计算得出多模态检索结果,考虑到Mapreduce是Hadoop处理大数据的核心[8],能够对大数据任务采取分布式并行计算,本文设计了基于Mapreduce的多源多模态大数据检索模型,从而有效提高对多源多模态大数据的检索性能。
2 多源多模态数据检索算法设计

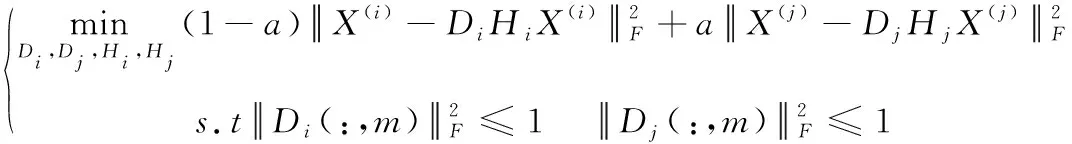
(1)
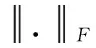

(2)
式中,c和d是加权系数。重写后的目标评价降低了特征对之间的约束性,避免检索范围过窄,此时该目标评价的求解可以转化为非凸问题。采取迭代计算的方式,过程中控制函数为单一参数变化,首先计算出中间变量Ii和Ij。根据目标评价整理可得
(Ii)=(1-a)+
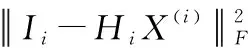
(3)
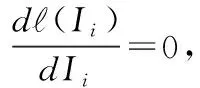
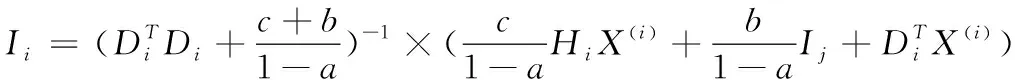
(4)
中间变量Ij的处理方式等同于Ii。然后计算哈希函数Hi和Hj,在求解Hi时,保持Hi以外的变量不变,此时将目标评价整理可得

(5)
将式(5)求Hi的导数,并令其等于零,从而解出Hi如下
Hi=IiX(i)(X(i)X(i)T+d/c)-1
(6)
Hj的处理方式等同于Hi。最后计算学习字典Di和Dj,在求解Di时,保持Di以外的所有变量不变,此时的目标评价整理可得
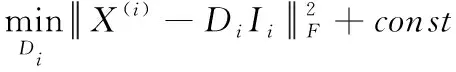
(7)
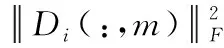
在学习网络的设计中,利用多层处理来代表多源多模态间存在的彼此联系。为了准确表述这种联系,这里将每层的结构设计为节点邻接矩阵形式G=(N,M)。N是网络中的节点集,N内所有节点都具有一个学习字典,在多模态分组情况下,节点集N可以表示为

(8)
式中,c(k)(l)表示多模态网络分组。当不同分组c(k)(l)与c(m)(l′)内同时包含某源的概率大于限定值时,则说明在c(k)(l)与c(m)(l′)中间具有连接,于是邻接矩阵M描述如下
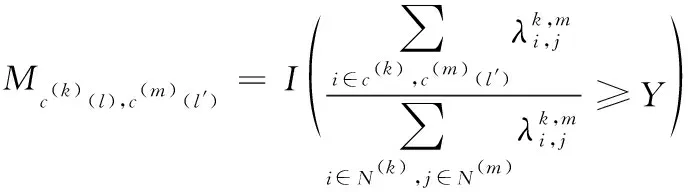
(9)
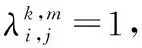
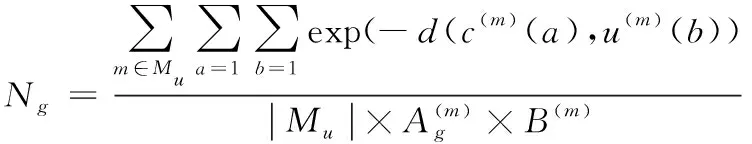
(10)
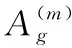
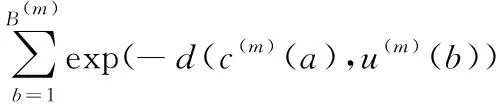
(11)
利用式(11)求解出所有符合要求的单一模态分组,并由它们构成最终的多模态检索结果。
3 基于Mapreduce的大数据检索模型
Mapreduce是Hadoop的一部分,主要用于大数据处理,可以部署在分布式集群网络中,完成数据的计算分析。其主要特点是计算效率高,负载均衡易于控制。Mapreduce的工作过程分为MapTask与ReduceTask两个阶段[9],Mapreduce会将大数据处理任务切割为若干子任务,缩小单次任务执行的复杂度,再把切割后的任务调度给MapTask,MapTask执行输出的结果由ReduceTask完成汇总。根据Mapreduce的工作原理,本文设计的多源多模态大数据检索模型如图1所示。
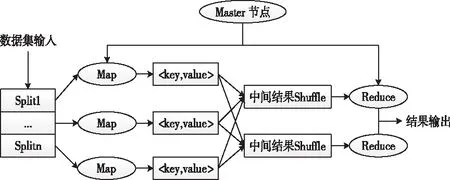
图1 Mapreduce多源多模态大数据检索模型
在接收到检索任务后,集群中的Master节点会按照HDFS配置对检索数据进行划分,划分后的数据子集调度至各Map,此阶段不需要在Mapreduce中部署算法。Map收到Split输入数据后,将数据映射成形式
4 多源多模态大数据检索质量分析
这里从检索的准确程度与完整程度两个方面进行分析。假定某时间段的数据源数量为m,各自权重表示是W=(w1,w2,…,wm),对应的多源多模态数据表示为R=(R1,R2,…,Rn),检索得到的单一源单一模态结果表示为Ri=(ri1,ri2,…,rin),则在检索结果与检索数据的实际值完全吻合时,才表明检索准确。因此,将单一源的多模态检索输出采取如下映射处理

(12)
根据多模态映射结果的累加和与模态数量的比值,计算得到第个数据源检索准确度公式如下

(13)
对应多源情况下检索准确度公式如下
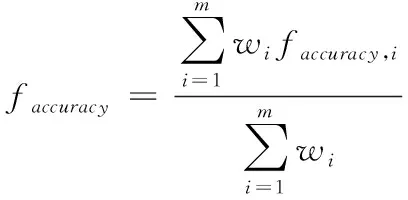
(14)
完整度描述的是数据集中未知结果部分与所有数据间的比值。同样将单一源多模态的检索输出采取如下映射处理
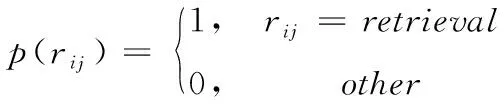
(15)
式中,rij=retrieval表示第i个数据源的第j个模态数据被检索。根据该映射结果计算第i个数据源检索完整度公式如下
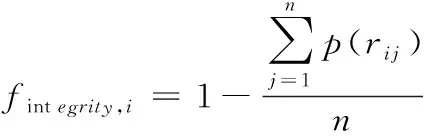
(16)
进一步得到多源情况下检索完整度公式如下
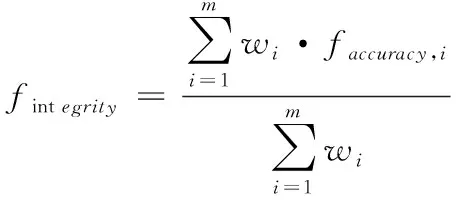
(17)
5 仿真与结果分析
仿真采用Wiki与NUS-WIDE数据集来产生原始多源多模态大数据。Wiki中含有2866组由文本与图像构成的特征对,NUS-WIDE中含有269648组由标签与图像构成的特征对。仿真中数据集设置如表1所示。

表1 数据集设置
实验过程中,目标评价涉及的哈希码位数依次取值16、32、64、128,通过50次模拟求均值,得到Wiki与NUS-WIDE数据集中检索的准确度。同时,本文引入文献[4](CCA-SCH)方法和文献[5](SDCH)方法进行性能比较。最终的准确度结果如图2所示。
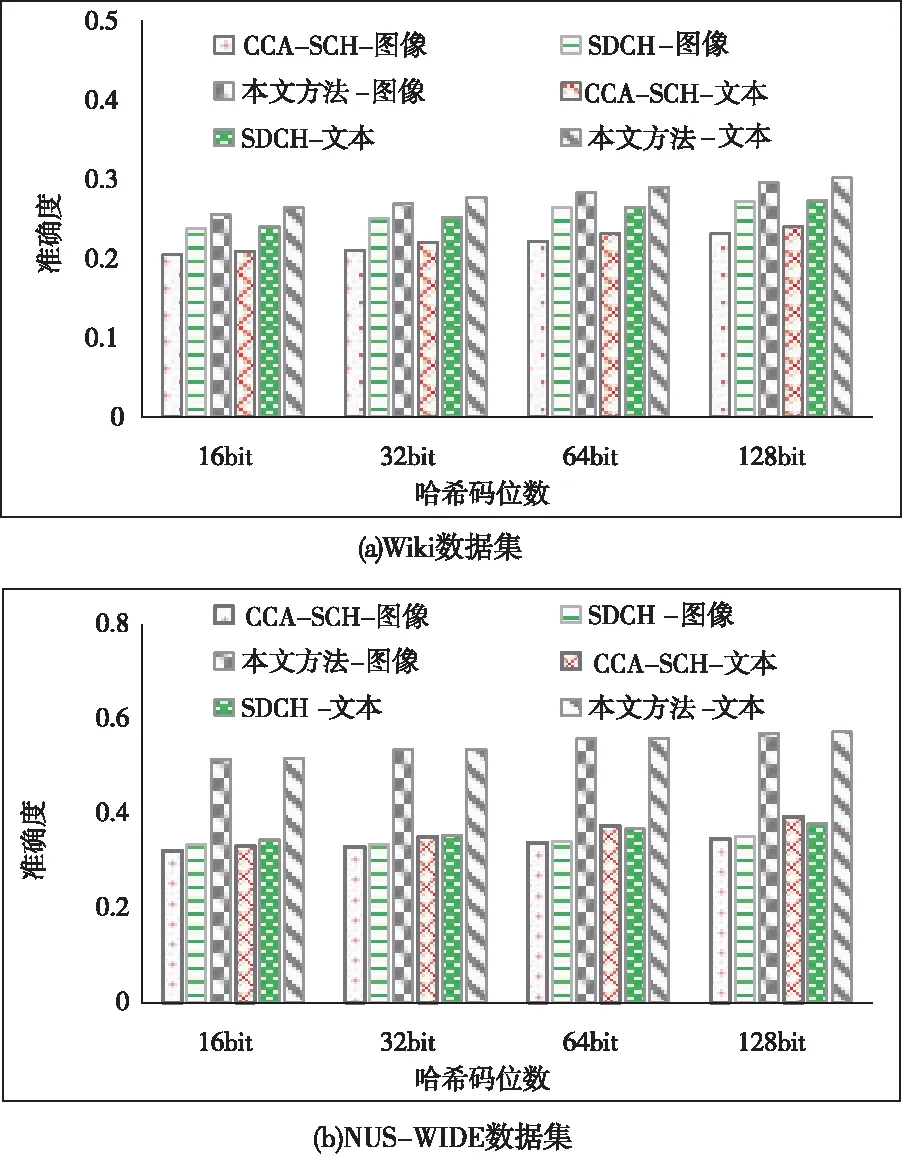
图2 检索准确度结果对比
根据Wiki数据集上的结果对比可知,各方法对于图像和文本两种不同模态的检索差别不大,在哈希码位数增加时,各方法的检索准确度都有所增加,但是在相同位数时,本文方法的检索准确度更高。根据NUS-WIDE数据集上的结果对比可知,各方法对于图像和标签两种不同模态的检索存在差异,CCA-SCH和SDCH方法在标签检索时较图像检索具有一定的准确度提升。而本文方法则在不同模态间呈现出较为平衡的检索性能,不管是哪种模态哪种哈希长度情况下,都具有更高的检索准确度。这是由于文献方法在多源多模态数据的低维子空间转换过程中,缺乏模态内部与外部的近似性处理,而本文则通过哈希与网络学习,对各种模态特征描述更为准确,从而得到更加合理的近似解。
仿真得到各方法在Wiki与NUS-WIDE数据集中的P-R曲线。根据准确度结果,由于在哈希码位数为64时,各方法都能获得较好的检索性能,所以这里针对64位哈希码情况得到如图3所示P-R曲线结果。
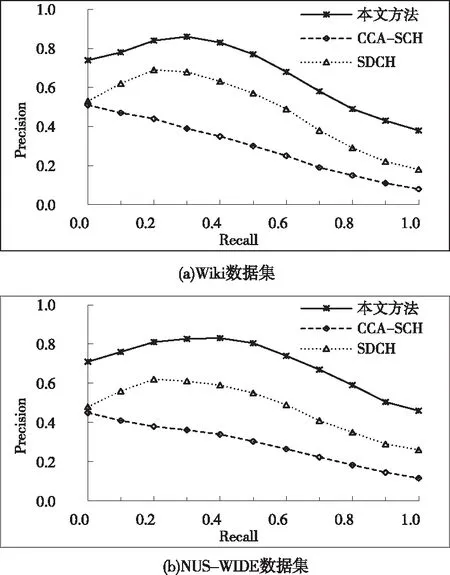
图3 64位哈希码曲线对比
根据Wiki与NUS-WIDE数据集的P-R曲线对比可知,在小于某召回率的范围内,当检索的完整度增加时,本文方法的准确度也随之上升;在超过某召回率的范围后,当检索的完整度增加时,本文方法的准确度将随之下降。在整个过程中,数据检索的完整度与准确度指标都优于文献方法。这是因为两种文献方法对于多源多模态数据的语义特征考虑的不够全面,而本文方法则考虑了多源多模态数据间的彼此联系,通过网络学习,完成检索的同时,也很好的保证了源内外、模态内外数据的近似度。
此外,为了进一步评价本文方法对于大数据的检索效率,考虑到NUS-WIDE数据集包含的数据量更大,针对NUS-WIDE数据集统计得到各方法的平均检索时间,结果如表2所示。根据结果可以看出,本文方法的平均检索时间仅为0.882s,显著低于对比方法,更适合于大数据应用场景。这是由于本文方法引入了Mapreduce,在横向上将多源多模态大数据的检索分割成若干子任务并行处理,在纵向上将检索分割为算法处理、中间结果Shuffle,以及最终汇总等独立阶段,使单次任务更加轻量化,充分发挥并行计算优势。

表2 平均检索时间对比
6 结束语
本文针对多源多模态大数据检索,提出并设计了基于Mapreduce的近似度学习检索方法。为了提高语义鸿沟,引入哈希与字典学习构建算法的目标评价,并设计了迭代求解算法;同时设计了网络学习来获取多源多模态数据间存在的彼此联系,根据近似度计算得出多模态检索结果。为了提高海量数据处理性能,引入Mapreduce并行处理框架,将检索任务分割成轻量化的子任务,并将算法部署于MapTask与ReduceTask。通过在Wiki与NUS-WIDE数据集上的仿真,验证了本文方法对于多源多模态数据特征的描述更为准确,能够很好的保证源内外、模态内外数据的近似度,且Mapreduce框架显著提升了大数据检索的效率。
