软件异类入侵数据自我识别强度云检测方法
2021-11-17黄振华李春华刘翠焕
黄振华,李春华,张 波,刘翠焕
(1.河北工程技术学院软件学院,河北石家庄 050091;2.河北科技大学信息科学与工程学院,河北石家庄050018)
1 引言
在互联网飞速发展的同时,越来越多的网络安全问题接踵而来,计算机系统中防火墙无法全方面做到隔离软件异类数据[1-2]。目前针对软件异类入侵数据相关领域学者做了大量的研究,并取得了一定的成就,但是在检测率和误报率上仍然存在问题[3-4]。神经网络存在着一些不足,神经网络拓扑在一定程度上受到限制,神经网络比较复杂,计算负荷较重。
云检测本质上是一个随机的过程,在软件内部组网端序列数据传输过程中,数据相对稳定,异类数据难以入侵,数据难以产生巨大的波动,因此可行性更高[5]。云检测是一种主动的网络安全防御措施,能有效弥补防火墙的不足,对网络采取实时性、全方位保护,对系统外部试图入侵的异类数据进行检测防护。
综上所述,传统的检测方法已不能满足现在网络安全的需要,为了解决软件异类入侵数据在传送过程中精确度不足的问题,本文建立了一种基于异类入侵数据自我识别强度的云检测方法,混合采用神经网络模型,实现了一种实时模拟分光器,采用ROC曲线对收集的数据与测试的数据进行对比评估。经实验证明,云检测方法可以有效地提高数据的精确度。
2 软件异类入侵数据识别
为更好地实现入侵数据的检测,前提是需要识别异类入侵数据。入侵数据识别分为三部分,分别是:数据收集、入侵分析和响应处理。软件异常入侵数据识别结构图如图1所示。

图1 软件异常入侵数据识别结构图
观察图1可知,数据收集是采集软件数据,是入侵检测中的基础。入侵分析是云检测方法的核心步骤,对采集到的数据进行加工处理并分析与原始数据进行对比,判断数据是否为异类数据,是否影响整体的运行状态[6]。若数据属于异类数据且存在异常入侵的情况,则通过响应处理进行报警,值班人员通过原始数据流提取异类数据并与储存的数据进行对比更正。云检测是通过整合主机网络信息和若干分集机网络信息方式进行发掘与分析。根据异类数据的轨迹发现其入侵行为,将主机的正常样本与检测的采集数据样本进行对比,对异类数据进行纠正,确保系统资源的精确性。
因此在进行数据识别时,可按照检测对象和入侵方式进行分类,按检测对象的不同可以分为两类,主机数据和网络数据,按入侵的方式不同,分为数据异常和输入错误两种入侵方式。分类如表1所示。

表1 入侵数据分类
为尽量减少数据入侵,在输入电脑程序时尽量避免错误,减小系统误差,提高系统精确度。及时发现数据异常的入侵方式,避免对后期数据的影响。再根据日志与显示数据,将已知的异常数据变成攻击编码模式[7],数据编码如图2所示。
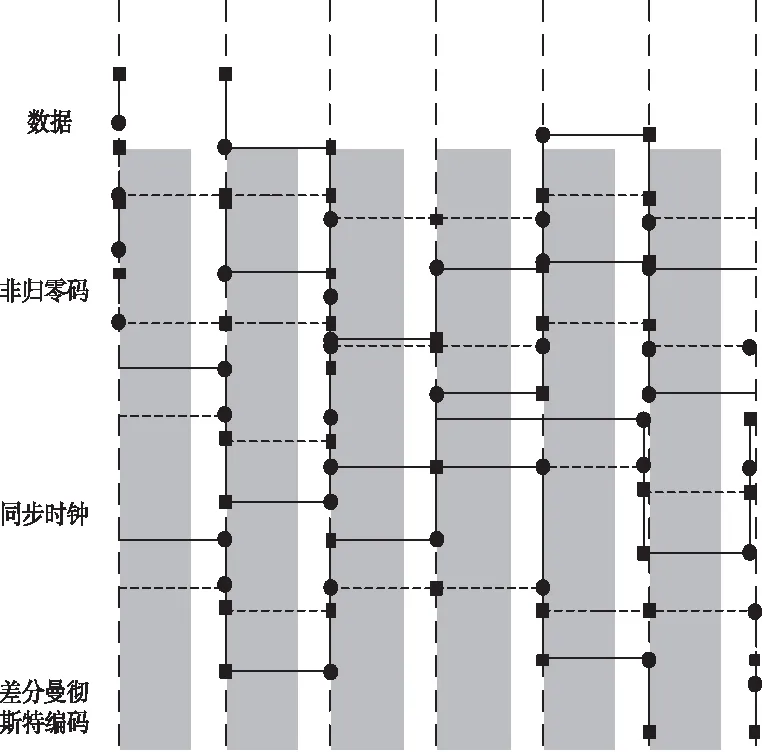
图2 数据编码模式
存储在入侵模拟数据库中,将实施的正确数据与入侵模式中异常数据进行匹配,识别出入侵数据。
3 异类入侵数据自我识别强度云检测
3.1 源程序数据传输的路径优化模型
由于在直角坐标系中,异常数据样本和正常数据的样本是不一致的,因此本文通过建立直角坐标系完成数据处理工作。随机抽取n个数据作为基础样本,通过Matlab软件画出ROC曲线,判断出数据的精确值,再重复此操作。对其它样本进行取样计算标准数据与测出数据的偏移量,对重合的数据进行储存,有差别的数据进行重新整合,直至ROC曲线是一条重合的线[8]。
若ROC不是一条光滑的曲线,则需将ROC曲线分为若干段,形成若干小梯形,计算出每个梯形的面积为数据的精确值,通过若干梯形面积相加得出数据的个数与正常数据数相减,得出异常数据的误报率。在ROC曲线中寻找出检测的最佳工作点。
由于操作错误系统软件会产生一些不正常的样本点,一般情况下,与做出的ROC曲线不重合的孤立点是由于操作失误而得到的,因此要保证数据的准确性,首先要确保主机系统内数据的准确性,对不规律的数据进行纠正,标记异类数据。软件内部组网具有周期性,每一个程序都以异常数据攻击的先后顺序排列,根据程序的不同,所处环境不同。因此对程序进行调用,在软件网络中,每个节点都对应不同的程序,程序内部每条路径代表着每个数据传送的过程,建立不同的数据传输通道形成数据网,植入云检测系统和报警系统,在一定安全策略下,进行入侵云检测。由于软件网络中每条路径都有起点和终点,在节点上具有储存数据的功能,异常数据常常通过程序的漏洞对每个节点进行攻击,通过改变源程序数据传输的路径,使整体的序列与正常执行的序列有一定的差异。因此本文在数据处理过程中,构建了源程序数据传输的路径优化模型

(1)
式(1)中,E(n)为获得的数据处理模型,e为常数值,n为监测到的异常数据数量。
3.2 入侵数据自我识别强度云检测
在上述路径优化模型的基础上,进行云检测,云检测方法主要分为数据库清洗和集成、数据库储存、选择与转换特定数据集、数据挖掘形成模式、评估与表示五个阶段。入侵数据自我识别强度云检测流程如图3所示。
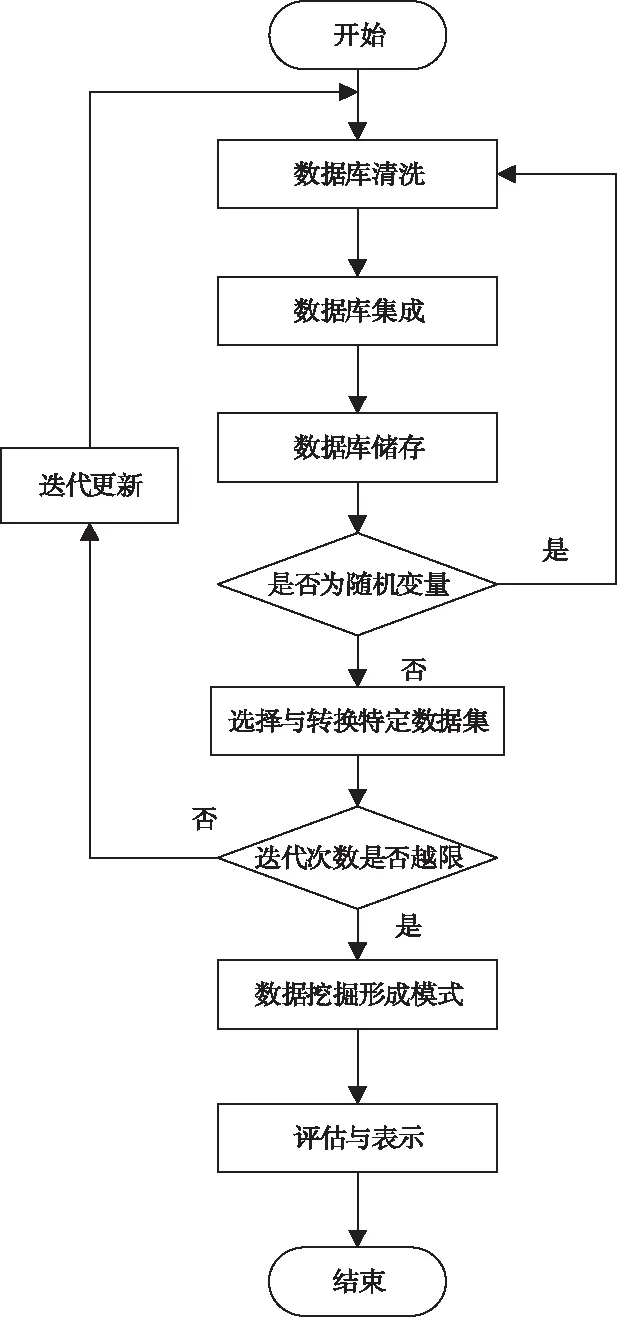
图3 入侵数据自我识别强度云检测流程
观察图3可知,数据库清洗和集成的作用是找出异样数据,对异样数据进行整合清洗;数据库储存的作用是将清洗过的数据进行储存,将数据源中的数据组合到一起;选择与转换特定数据集作用是将整合后的数据进行筛选整合成数据包的形式进行特定的存储;数据挖掘形成模式是对特定存储的数据进行分解,智能的将数据进行有规律的分解;评估与表示知识作用是根据分解出的数据筛选出有意义的模式知识,利用数据的可视化向用户展现出来。
数据通过传输网传送,在节点的末端小型中央处理器对数据进行读取、审计并记录,用exevce/inetd系统检测,产生新的数据,主机系统对数据进行自我识别[9]。若数据发生异常,则重新返回开始,进行纠察并重新传输数据,若数据与原数据一直继续向下传输,得到path的数据值,判断是否为正确的程序。如果数据经过加权后,得到了相应的服务权限矢量,判断 PID是否存在矢量中,如果没有,系统就需要重新编程,如果存在矢量继续向下传输判断是否 fork如果继续向下传输,输出的数据存储在相应的数据资源库中,如果不是,就需要检查数据并纠正重新传输。
通过构建线性函数将原有的数据映射到三维空间内,将空间进行划分,利用矩阵寻找异类数据的过程从而获得最优解,采用最小误差平均准则E=1,将整体数据集划分成互不重合的数据块,使整体数据形成紧凑的独立体[10]。分割过程如图4所示:
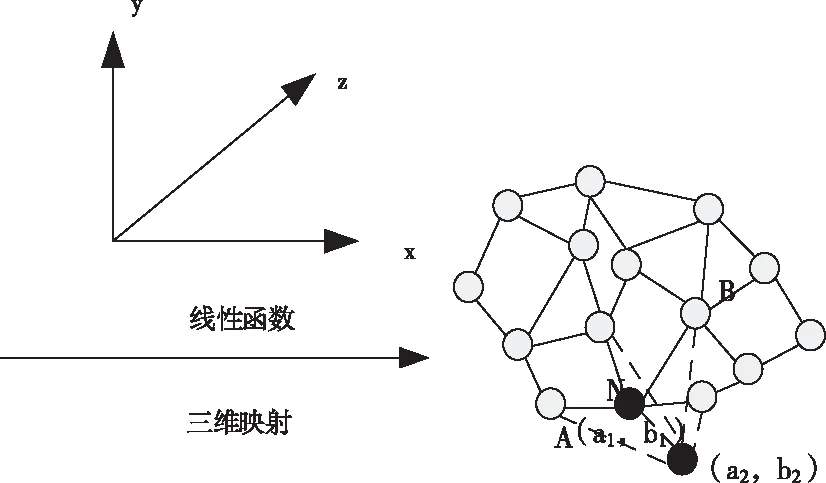
图4 数据分割原理
根据图4的分割原理得到数据独立体,在获得离散型属性数据后,通过构建新线型函数将原有的数据映射到三维空间内,将空间进行划分,利用矩阵寻找异类数据的过程从而获得最优解[11]。云检测的方法主要依赖于模拟数据库,若模拟数据库中无正常数据,则不能检测出攻击数据,若异常数据的实时编码与正常数据超过一定的阈值,正常数据也会受到攻击。对整体数据进行分析处理,展现出正常数据与异常数据之间的非线性关系,通过随机取样的方式来进行数据对比。利用HMM(Hidden Markov Model)模型的检测功能[12],通过云测试识别出异样数据,实现信息分布化处理,增加处理过程的自适应性。HMM模型如图5所示。

图5 检测模型
观察图5可知,每条通道上传输的数据可以简称为数据流,具有连续性,大容量,快速响应的特点,当异类数据入侵时,在数据流中执行云检测,若数据为事件数据的一部分,则其为入侵数据。数据主要有三种数据类型:点异常、样本异常、顺序异常。感应数据流的传输数据,增强了数据流算法的稳定性,提高了检测性能,增加检测过程稳定性。
4 仿真与分析
为了检测本文提出的软件异类入侵数据自我识别强度云检测方法的有效性,与现有方法进行对比实验研究,选用的对比方法为基于SDN的智能入侵检测系统模型与算法(文献[3]方法)、基于云模型与决策树的入侵检测方法(文献[4]方法)。
入侵检测性能指标主要包括三方面:检测率、误检率和漏报率。
1)检测率是云检测系统受到异类数据入侵时能够准确报警的概率,检测率越高,说明方法的性能越好,计算公式为

(2)
式中,C1为正确检测异类数据入侵的次数,C为异类数据入侵的总次数。
2)误检率是云检测系统错误判断异类数据入侵的概率,误检率越低,说明方法的检测性能越好,其计算公式为

(3)
式中,C2为错误判断异类数据入侵的总次数。
3)漏报率是系统对未检测到的异常数据大致估算概率,漏报率越低,说明检测结果更可靠。其计算公式为
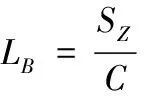
(4)
式中,SZ为漏报为正常的入侵次数,为异类数据入侵的总次数。
设定实验参数如表2所示。

表2 实验参数
设定实验环境:实验所用系统为Windows 2010 64位,内存4GB,CPU 3.30 Hz,仿真平台为MATLAB R2018 b。具体实验结果与分析如下内容所示。
4.1 检测率实验
根据上述实验参数和实验环境,利用三种检测方法检测软件异类入侵数据,得到的检测率实验结果如图6所示。
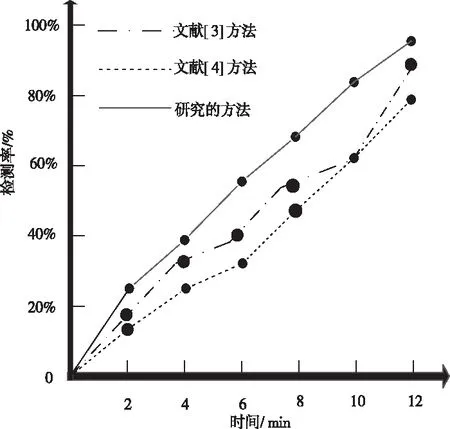
图6 检测率实验结果
根据图6可知,当检测时间为4min时,文献[3]方法检测率为22%,文献[4]方法检测率为29%,研究的检测方法检测率为38%;当检测时间为8min时,文献[3]方法检测率为44%,文献[4]方法检测率为48%,本文提出的检测方法检测率为65%;当检测时间为12min时,文献[3]方法检测率为60%,文献[4]方法检测率为80%,本文提出的检测方法检测率为82%。由此可知,研究的检测方法检测率要始终高于传统的检测方法,随着检测时间的增加,三种检测方法的检测率也在逐渐提高。
4.2 误检率实验
依据上述实验环境,对比三种方法的误检率,将测试数据随机划分为10组,每组数据为1550个,检测每组数据时随机加入入侵数据30个。基于此,误检率实验结果如图7所示。

图7 误检率实验结果
由图7可知,研究的检测方法误检测率明显低于对比检测方法的误检测率,由于研究的方法采用云检测,所以更好地对数据进行分析,探究数据的内部强度,提高了异类数据检测精度。综上所述,此次研究提出的检测方法更适合应用到软件异类入侵数据检测中,适用性更广,应用效果更强。
4.3 漏报率实验
同样依据上述实验环境,以3.2节实验的数据分组为基础进行漏报率实验,具体实验结果如图8所示。

图8 漏报率实验结果
由图8可知,对比的两种方法漏报率介于10%~16%之间,而研究的方法的漏报率介于2%~6%之间,低于对比方法。因为研究的方法考虑到软件内部组网的攻击顺序排列问题,优化了数据传输路径,并在数据网中植入了云检测系统,形成了较稳定的检测环境,同时也实现了降低漏报率的目的。
5 结束语
本文利用软件异类入侵数据研究了一种新的自我识别强度云检测模型,该模型具有强大的自我识别能力和传送数据能力,可以快速的识别到异常数据,对入侵异常数据进行性能的检测,有效地提高入侵系统的误报率和漏报率。运用ROC曲线进行云检测,将正常数据与异常数据进行对比,找出异常区域加以纠正,提高了检测的精确度。
