深度学习在视网膜血管分割上的研究进展
2021-11-17李兰兰张孝辉牛得草胡益煌赵铁松王大彪
李兰兰,张孝辉,牛得草,胡益煌,赵铁松,王大彪
1.福州大学 物理与信息工程学院 福建省媒体信息智能处理与无线传输重点实验室,福州350116
2.福州大学 机械工程及自动化学院,福州350116
3.广东省第二人民医院,广州510317
在2019 年10 月,根据世界卫生组织发布的一份世界宣明会报告,世界范围内超过4.18 亿人患有青光眼、糖尿病视网膜病变(diabetic retinopathy,DR)、老年性黄斑变性(age-related macular degeneration,AMD)或其他可导致失明的眼部疾病[1]。许多眼底病变都会发生在血管的周围,视网膜眼底图像中包含丰富的视网膜血管特征[2-3]。分析视网膜血管长、宽、弯曲度、分叉模式等结构特性可以得到眼底疾病的临床病理特征,对这些疾病的预防和治疗具有重要意义[4-5]。如用于微动脉瘤检测的薄血管和厚血管的直径都是糖尿病视网膜病变诊断的重要生物标志物[6-7]。视网膜血管分割是获取这些结构特性的必要的步骤,良好的分割结果将使后续特征提取和异常检测分析更加高效、准确[8-9]。由于视网膜血管复杂的树状结构,人工视网膜血管分割存在易出错、费时、乏味等问题[10-11]。自动分割算法能够帮助医生分析复杂的眼底图像,且精度在逐步提升,近年来引起了较多的关注[3]。
视网膜血管准确自动分割难度较大,原因在于:(1)视网膜血管的尺度变换大,其中有非常微小的毛细血管,最小直径仅有1~2个像素宽,对比度也比视网膜血管的主要动脉和静脉低[12];(2)视网膜血管具有和树相似的复杂结构,比如分叉、交叉结构[13];(3)部分的视网膜血管存在微动脉瘤、渗出物等病变,增加了分割的难度[13]。
在传统算法中,通常将人工设计的纹理、颜色、形状这些底层特征作为血管分割的依据[14-15]。如Vlachos 等人[16]提出了多尺度的线性跟踪程序应用于视网膜血管的分割和血管的提取,在DRIVE 数据集上得到分割的准确性达到92.9%。Zhao 等人[17]提出了基于Retinex 理论的图像不均匀性校准,基于局部相位的血管增强和基于图分割的主动轮廓分割三者结合的算法用于血管的分割,在DRIVE 数据集上的准确性为95.3%。尽管这些方法在特定的环境下取得了好的分割结果,但是人工设计的特征不能够充分地表达视网膜血管复杂的特征,在相对大的数据集中,算法就不能适应复杂的环境[14]。而且传统自动分割方法用时不能达到实时检测的效果,比如Fraz等人[18]的研究每分割一张图片需要100 s。
近年来很多研究者尝试将深度学习引入到医学图像处理领域,相较于传统自动分割算法,深度学习有很大的优势:首先,深度学习是一种端到端的学习方式,不需要手动设计统计特征,可以自动提取图像的底层、中层和高层特征,避免了传统算法人工设计特征不能完全表征图像的特征的缺陷。其次,深度学习应用到医学图像处理领域表现出优秀的学习能力和潜力,性能接近或超过传统方法,比如,Li等人[19]将分割任务重新塑造为从视网膜图像到血管图的跨模态数据转换问题,在DRIVE 数据集上准确性为95.27%。Gu 等人[20]基于编码解码结构提出了语义编码网络(context encoder network,CE-Net)分割算法,在DRIVE 数据集上准确性为95.45%。Zhou 等人[21]基于生成对抗网络(generative adversarial network,GAN)[22]提出的对称均衡生成对抗网络(symmetric equilibrium generative adversarial network,SEGAN),在DRIVE 数据集上准确性为95.63%。
正因为深度学习在视网膜血管分割任务上巨大潜力,表现出较好的临床应用上前景,近年来吸引了大量的国内外研究。本文对近年来基于深度学习的视网膜分割研究进行总结回顾,主要包括视网膜图像数据库建立、图像预处理方法及血管分割算法三方面。在此基础上探讨当前研究仍存在的不足,分析可以改进的措施,并展望未来较有潜力的研究方向。

Table 1 Fundus image databases表1 眼底图像数据库
1 数据处理
1.1 数据库
深度学习本质上是基于数据驱动的算法,高质量的图片数据库对深度学习算法的性能极为重要。世界上许多研究机构建立并公开了其眼底图像数据库,以期推进深度学习技术在视网膜血管分割上的发展。其中影响较大的有荷兰的DRIVE 数据库、美国的STARE 数据库,此外还有英国的CHASE_DB1数据库、捷克的HRF 数据库等。表1 是眼底图像开源数据库的综合信息。
这些开源数据库对分割算法的进步起到了很好的推动作用,然而目前数据集建立的工作仍存在一些不足:首先,目前的不同数据库图片差异性较大,拍摄图片使用的设备、数据的维度等方面各不相同,这对深度学习模型的泛化性能影响较大。其次,数据库里面的数据较少,比如常用的DRIVE 和STARE数据库只有几十张图片,而深度学习在自然图片中一般要求数万量级的图片量。相对而言,眼底视网膜数据库的数据量很少,这也是医学图像处理领域目前存在的普遍性问题。因此加快建立标准统一和具有一定规模的数据库是推进深度学习今后在视网膜血管分割中应用的一项重要工作。此外,目前眼底图像数据库建立工作主要是在欧美等发达国家进行,我国在这方面的研究还较少。
1.2 数据预处理
由于数据集的缺乏,采用数据增强技术对图像数量进行提高是一项必备的工作。使用数据增强技术可以降低模型过拟合的概率,有利于模型的收敛,可以提升模型的泛化性能[23]。目前在视网膜血管分割研究中被使用的数据增强技术主要有水平和垂直翻转[2,6,24-28]、调整大小[6,25-26,28]、添加随机噪声[25]、随机旋转[6,24,26,28]、调整对比度[6]等。不同的研究会根据实际需要选择一种或者多种图像增强技术,图像增强技术在部分研究中的使用情况见表2。总体上看,水平或竖直翻转是最广泛使用的增强操作,而增强对比度则较少使用。

Table 2 Data enhancement of fundus images表2 眼底图像的数据增强操作
图像预处理操作可以让图像的特征完全地表征出来,神经网络更容易提取图像不同的特征,有助于提高模型性能。目前在视网膜血管分割任务中常用的图像预处理方法主要有图像灰度化[2,6,13,24-25,27,29-31]、图像标准化[2,10,24,27-28,30,32]、对比度受限的自适应直方图均衡化(contrast limited adaptive histogram equalization,CLAHE)算法[2,10,13,27,29,32]、提取图像的绿色通道图片[6,25,30-31,33-34]、伽马校准[2,10,28-30,32]。不同研究根据模型需要选取一种或多种预处理方法,近年研究使用的预处理方法统计见表3,总体上看图像灰度化和标准化是使用较多的预处理技术。

Table 3 Data preprocessing of fundus image表3 眼底图像的图像预处理
为了减轻模型的计算负荷并获取更多的图像的细节特征,许多研究还会对眼底图像进行切片处理。图像切片是将一张完整的眼底图像分割成小尺寸的图像补丁。不同的尺寸对模型带来的计算负担不同,同时对于图像的细节和全局特征把握也不同。分割尺寸的大小没有客观标准,定性来看,尺寸越小对模型提取细节特征越有利,而尺寸越大对模型提取全局特征越有利。目前常用的图像切片的尺寸有9×9[31]、48×48[2,29,30,32]、64×64[27-28,35]、128×128[6,25,29,33]。图像切片尺寸的汇总如表4。
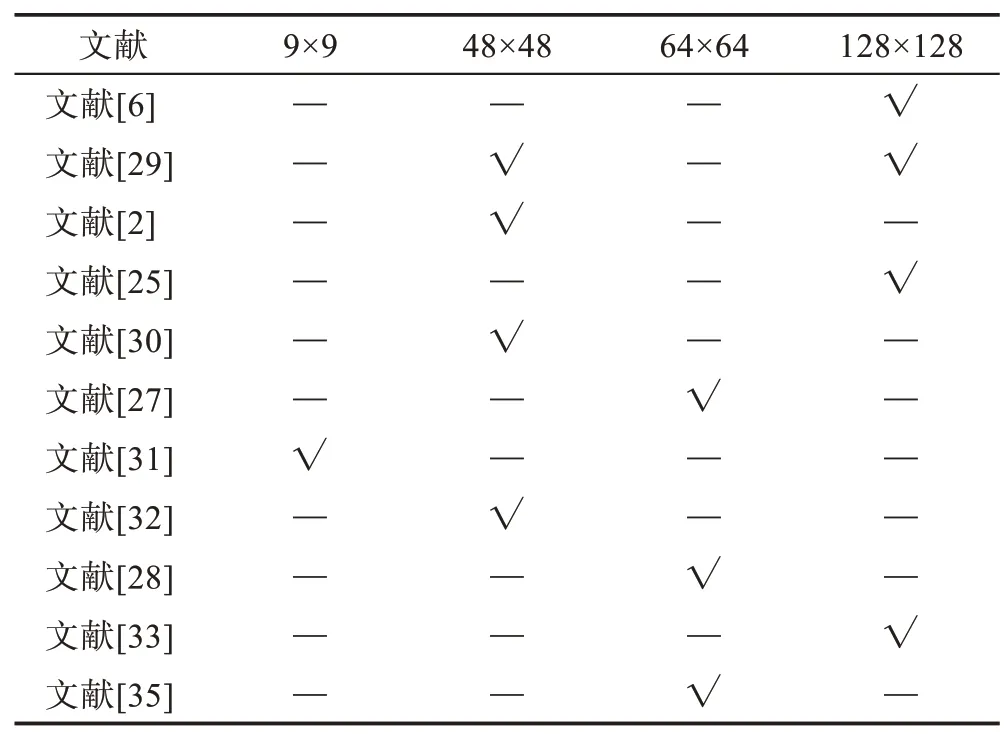
Table 4 Image slice size for retinal vessel segmentation表4 视网膜血管分割的图像切片尺寸
2 图像分割算法
在数据相关操作完成后,需要通过分割算法将视网膜血管从背景中分割出来。早期使用的医学图像分割神经网络主要为全卷积神经网络和编码解码网络,在这些网络基础上发展了很多不同结构的神经网络。本文从网络架构的角度对近年来用于视网膜血管分割的神经网络进行归类总结,主要分为级联结构、多路径、多尺度类型的神经网络,介绍了各类神经网络的特点,并对比各种分割模型在现有研究中达到的性能,同时对比了算法的复杂度。从算法现实部署的角度介绍了部分研究。目前分割算法中常见的性能指标见表5。

Table 5 Performance metrics of retinal vessel segmentation表5 视网膜血管分割性能指标
2.1 早期医学图像分割神经网络
Long 等人[36]提出全卷积神经网络(fully convolutional networks,FCN)用于图像的语义分割,如图1[36]。作者通过修改经典的CNN(convolutional neural networks)网络结构,将全连接层都转换为卷积层,来管理非固定尺寸的输入和输出。模型前几层的特征图通过上采样和最后一层的特征图进行融合产生一个精确细致的分割图。该模型在PASCAL VOC、NYUDv2和SIFT Flow 上进行了测试,取得了较好的分割效果。在图像分割领域,FCN 被认为是里程碑式的进步,证明了深度神经网络可以在变化的图像上以端到端的形式训练进行图像分割。
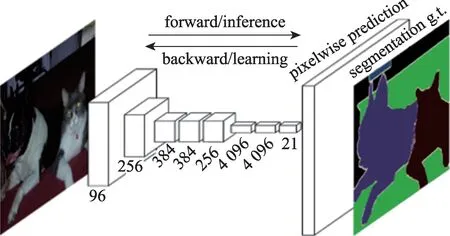
Fig.1 Fully convolutional networks图1 全卷积神经网络
编码解码模型也可以用于图像的分割,大部分的深度学习的分割网络都是用的编码解码网络。有一些专门为医学图像分割而开发的模型,比如受到FCN启发的U-Net网络[37]和V-Net网络[38]。Ronneberger 等人[37]提出的U-Net 如图2[37]所示,该网络包含两个路径,压缩路径主要用来捕获上下文的语义,对称的扩张路径主要关注像素位置信息。下采样和收缩路径和FCN 网络具有类似的结构,都是使用3×3的卷积核来提取数据的特征。对于上采样和扩张路径部分使用转置卷积,在减少它们特征图数量的同时增加特征图的维度。通过将网络下采样部分的特征图复制到上采样部分避免模式信息的丢失。在UNet基础上,Milletari等人设计了V-Net[38]用于3D 医学图像的分割,同时引入了一个基于Dice 系数的目标函数,通过这种目标函数能够使模型处理前景和背景中像素严重不匹配的情况。
2.2 视网膜血管分割算法
近期提出的视网膜血管分割算法主要是基于全卷积神经网络。从网络架构上,全卷积神经网络可划分为编码解码结构和多尺度神经网络。编码解码结构是级联结构和多路径网络的基础架构,网络之间的关系如图3 所示。下面将详细介绍每种网络的特点、最近研究,并且对算法的性能、复杂度、缺点进行对比、分析。
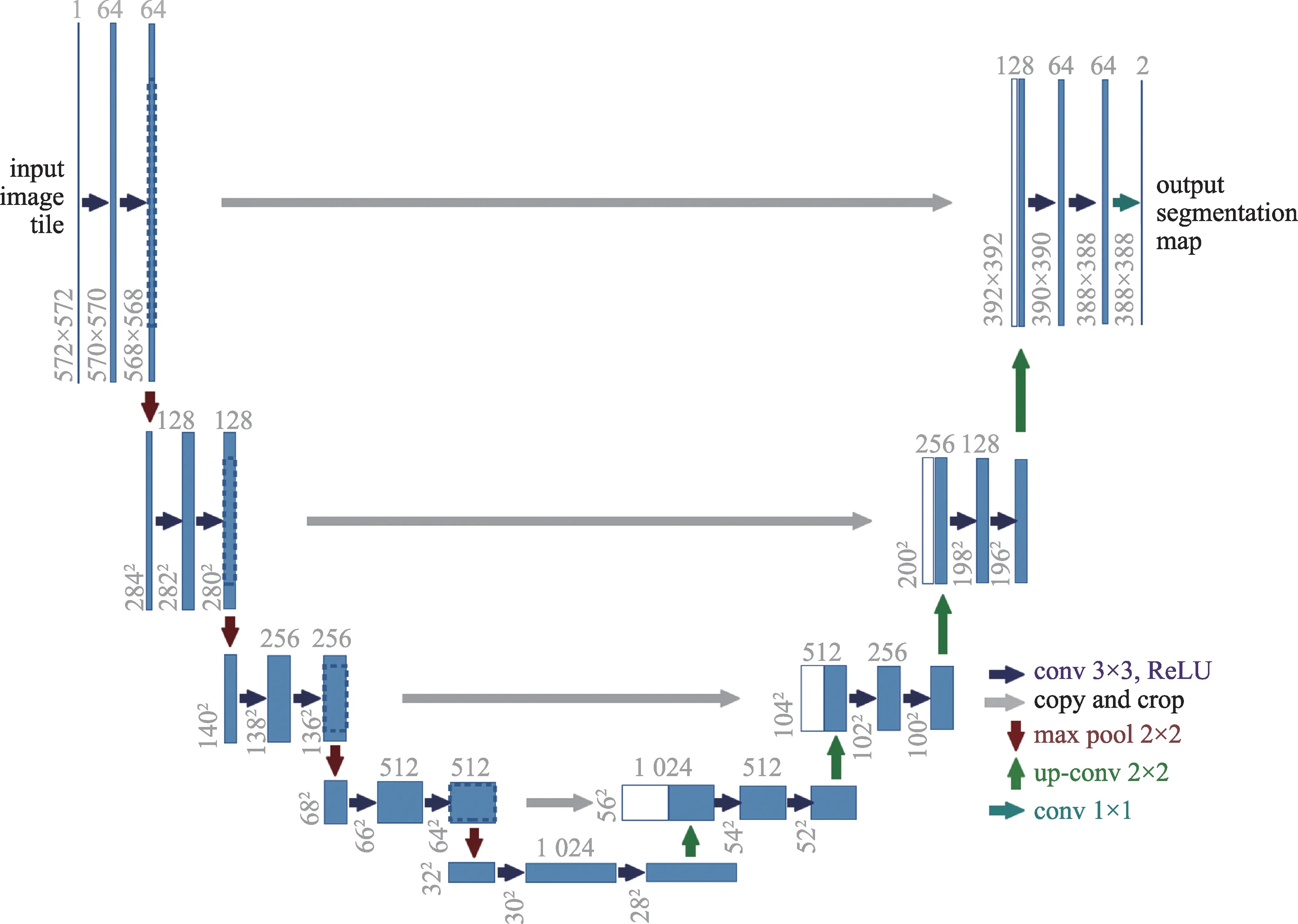
Fig.2 U-Net used for biomedical image segmentation图2 U-Net:用于生物医学图像分割

Fig.3 Relationship between algorithms图3 算法之间的关系
2.2.1 级联结构神经网络
级联结构神经网络由两个相似网络间串联而成。前一级网络产生了血管分割图,后一级网络可以在前一级网络的输出血管分割图基础上对血管分割结果的结构进行细化,对血管像素的预测结果进行优化,典型结构见图4[2]。这种网络对于视网膜血管的空间结构的预测能力优势明显。如Wu 等人[2]设计了名为NFN+w/o Ics级联结构的神经网络,前向网络将输入转换为粗血管分割图,后一级网络调整粗血管分割图分类错误的像素,重新优化了血管的空间结构。基础模型和NFN+w/o Ics 模型(级联结构,无跳跃连接结构)在DRIVE 数据集上设计对比实验,NFN+w/o Ics 模型在AUC、AUPR、ACC 等指标上分别上升了0.3%、0.79%、0.12%,体现了级联结构在模型中改善了分割血管的连通性,提升了结构预测的能力,提升了模型的性能。Wu等人[12]提出的多尺度跟踪网络(multiscale network followed network,MS-NFN)包含NFN 模块。每个NFN 模块由两个子网络(uppool 网络或者pool-up 网络)形成了级联结构。对两个不同路径的NFN 模块网路生成的血管分割图进行平均得到最后的血管分割结果。Lian 等人[13]提出了基于全局和局部增强图片的残差U-net 网络,其中用于粗分割的WUN(weighted U-net)模块和用于细化的WRUN(weighted Res-Unet)模块组成了级联结构。全局增强眼底图的图像切片作为WUN 的输入生成粗分割血管图,局部增强的图像切片、相应金标准的图像切片以及前一级网络的粗分割血管图作为WRUN 的联合输入来训练网络。这个模型能够很好地处理光照、硬性区域视盘、病变区、边缘区、视盘区等异常噪声区域。同时该模型能够很好地分割细小血管,又能保持视网膜血管的几何连接。
2.2.2 多路径神经网络

Fig.4 NFN+neural network structure图4 NFN+神经网络的结构图
多路径神经网络是两个及以上不同路径的神经网络并行组成的网络架构(图5[39]),每条路径关注图像不同特征的信息,比如一个路径关注全局特征,另一个路径就关注局部特征,最后将两个路径的产生的特征图进行整合得到最后的结果。这种神经网络可以整合更多的语义信息,同时对于感兴趣的区域有更好的针对性,有利于毛细血管和薄血管的分割,多路径神经网络对于图像分割领域来说是一个新的尝试。如Tian 等人[39]模拟了初级视觉皮层对多路径信息处理的神经编码机制,提出了多路径卷积神经网络[39]分割方法,两个路径分别为高频特征提取路径和低频特征提取路径,其中高频提取路径关注图像的局部信息,低频特征提取路径关注图像的全局信息。Yan 等人[6]提出的深度学习模型分为厚血管分割、细血管分割和血管特征融合三个阶段。对粗血管和细血管进行分离分割可以获得更好的鉴别特征,因此最大限度地减少了粗细血管比例不平衡所带来的负面影响,血管融合阶段通过进一步识别非血管像素来改善血管整体厚度一致性细化了结果。Wang 等人[30]提出的DEU-Net 网络有两种编码路径:一种是带有大核的空间路径以保留空间信息;另一种是带有多尺度卷积块的上下文路径以捕获更多语义信息。Wu 等人[32]提出的Vessel-Net网络,在模型优化过程中引入了传统的监管路径、丰富特征的监管路径和两种多尺度的监管路径。Khan 等人[40]提出的网络其中一条路径提取目标清晰的边缘,另一条通过空间金字塔池化模块将几种不同的分辨率的特征进行汇集去提取显著的语义信息。
2.2.3 多尺度神经网络

Fig.5 Multi-path convolutional neural network designed by Tian et al图5 Tian 等人设计的多路径卷积神经网络

Fig.6 Neural network integrating multiple layers of semantics designed by Song et al图6 Song 等人设计的整合多层语义的神经网络
多尺度神经网络是对不同尺度大小的特征图进行整合,典型结构见图6[35],考虑到高层特征和底层特征不同的优势,高层特征有助于像素的分类,底层特征可以帮助像素的定位[35]。将不同层级的语义相互整合可以获得更加全面的信息。如Song 等人[35]提出的神经网络,该网络以图像切片作为输入,每个模块创建固定大小的特征图,然后将这些不同尺度的特征图组合成一个单独的特征图。Feng 等人[35]提出一种交叉连接卷积神经网络(cross-connected convolutional network,CcNet),主路径和次路径之间的交叉连接融合了多层次的特征,根据学习到的特征预测像素的类别。Hu 等人[41]提出基于改进的交叉损失函数的卷积神经网络进行多尺度特征图的整合,并且引入了全连通条件随机场(fully connected conditional random fields,Fully CRFs)来消除特征图噪声和边缘模糊的问题来细化特征图,从而得到最后的分割结果。Guo 等人[26]提出的BTS-DSN 网路引入了bottomtop short connections 和top-bottom short connections的连接方式,bottom-top short connections 将底层的语义信息传递给高层,细化了高层侧输出的结果,缓解了由于降采样操作高层侧输出糊化的问题,topbottom short connections 将高层的结构信息传递给底层,优化了底层侧输出的结构信息,减少了底层侧输出的噪声。Zhang 等人[28]提出了基于全卷积神经网络的架构,将相邻的卷积层提取的特征融合在一起,可以将底层的信息尽可能地传输到顶层。同时引入文献[27]中的Atrous Convolution 来取代常规的卷积操作。Xu 等人[29]采用不同膨胀率的并行放大卷积滤波器设计多尺度聚合块,并嵌入网络中,充分探索利用多尺度信息。在CHASE-DB1 和HRF 中的性能体现了文中提出方法的有效性,解决了毛细血管尺度变化大,不利于分割的问题。
2.2.4 算法的性能对比
表6 是关于近期视网膜血管分割算法的性能对比表格,其中标黑的部分是在相应的指标排名前三的性能分数。通过性能的对比发现,Lian 等人[13]提出的级联结构+跳跃连接+加权注意机制和Wang 等人[14]提出的特征金字塔级联模块在SP、ACC 上取得了较好的性能。Wu 等人[2]提出的级联结构+跳跃连接在AUC 上性能突出。级联结构的第一级可以确定视网膜血管的形状和大概位置,级联网络的第二级对分类错误的像素重新进行预测,以及对血管结构进行优化。在单独SE 上,Tian 等人[39]提出的多路径网络的SE=86.39%取得了最高的性能。在单独SP 上,Lian等人[13]提出的级联结构+跳跃连接+加权注意机制网络达到了最优的性能SP=98.61%。在单独ACC 上,Lian 等人[13]的工作也是最优的,ACC=96.92%。在单独AUC 上,Wu 等人[12]提出的多路径+级联结构和Gridach[46]提出的ResNet 预训练网络+金字塔扩张模块达到了最优AUC 分别为98.70%、98.74%。多路径神经网络通过不同的路径关注视网膜血管的不同的信息,可以获得更加有利于细小血管分割的特征,也较利于血管的分割。
2.2.5 算法的复杂度分析
如表7 中所示,在上述算法实施的平台主要是英伟达的显卡,可以满足现实部署的实施。Feng 等人[34]、Wei 等人[48]设计的算法推断时间都是处于毫秒级的,可以满足现实中的算法需要的推断时间。Laibacher等人[47]、Jin等人[10]、Wei等人[48]的计算参数数量分别为0.55×106、0.88×106、0.27×106,计算的代价也比较小。Laibacher 等人[47]、Wei 等人[48]中模型的大小分别只有2.2 MB 和1.2 MB,具备了嵌入在设备上的潜力。因此近些年提出的基于深度学习的视网膜血管分割算法具有实际应用的潜力。
2.2.6 算法的缺点分析
虽然目前的视网膜血管分割算法取得了很好的结果,但在SE 这一指标上始终没有突破90.00%,因此分割算法还是有待提升。列举了目前最优的视网膜血管分割算法解决的问题,并总结出最优算法存在的不足。
在文献[13]中设计了级联结构的神经网络,在网络第二级采用了对图像切片进行增强的方法,通过对局部图像的增强,获得了丰富的局部信息,有利于薄血管的分割。级联结构的神经网络在网络的第二级优化了第一级网络的分割结果,对于血管的结构又进行了优化。在文献[2]中级联结构的神经网络后一级网络可以优化血管的结构,前一级网络预测错误的像素,可以通过后一级网络重新预测。同时作者利用两级网络间的跳跃连接以及网络内的跳跃连接将底层的特征传输到高层,有利于薄血管的分割。在文献[39]中设计了多路径卷积神经网络,能够有效抑制噪声,保证血管分割后的连续性。同时作者利用高斯低通滤波器和高斯高通滤波器对图像进行处理分别得到包含全局特征信息的低频图像和包含局部特征信息的高频图像,通过多路径整合了更加全面的信息,其中关于局部特征的信息更加有利于薄血管的分割。在文献[12]中提出的多尺度的跟随网络用于视网膜血管分割,其中提出的NFN 模块,在一定程度上遏制了预测血管断裂的问题。但是没有考虑细小血管的分割,以及有病变区域图像的分割。在文献[14]中提出的RVSeg-Net网络中包含了特征金字塔级联模块(feature pyramid cascade module,FPC),这个模块能够捕获多尺度的特征,解决视网膜血管尺寸变化大的问题,同时聚合了局部和全局语义信息解决了不连续的问题。在文献[32]中作者提出了Vessel-Net 网络用于视网膜血管分割。其中整合了Inception 和residual模块改善了特征表示。提出的多路径监督方法保留了多尺度特征,对于血管的结构预测起到了很大的作用。
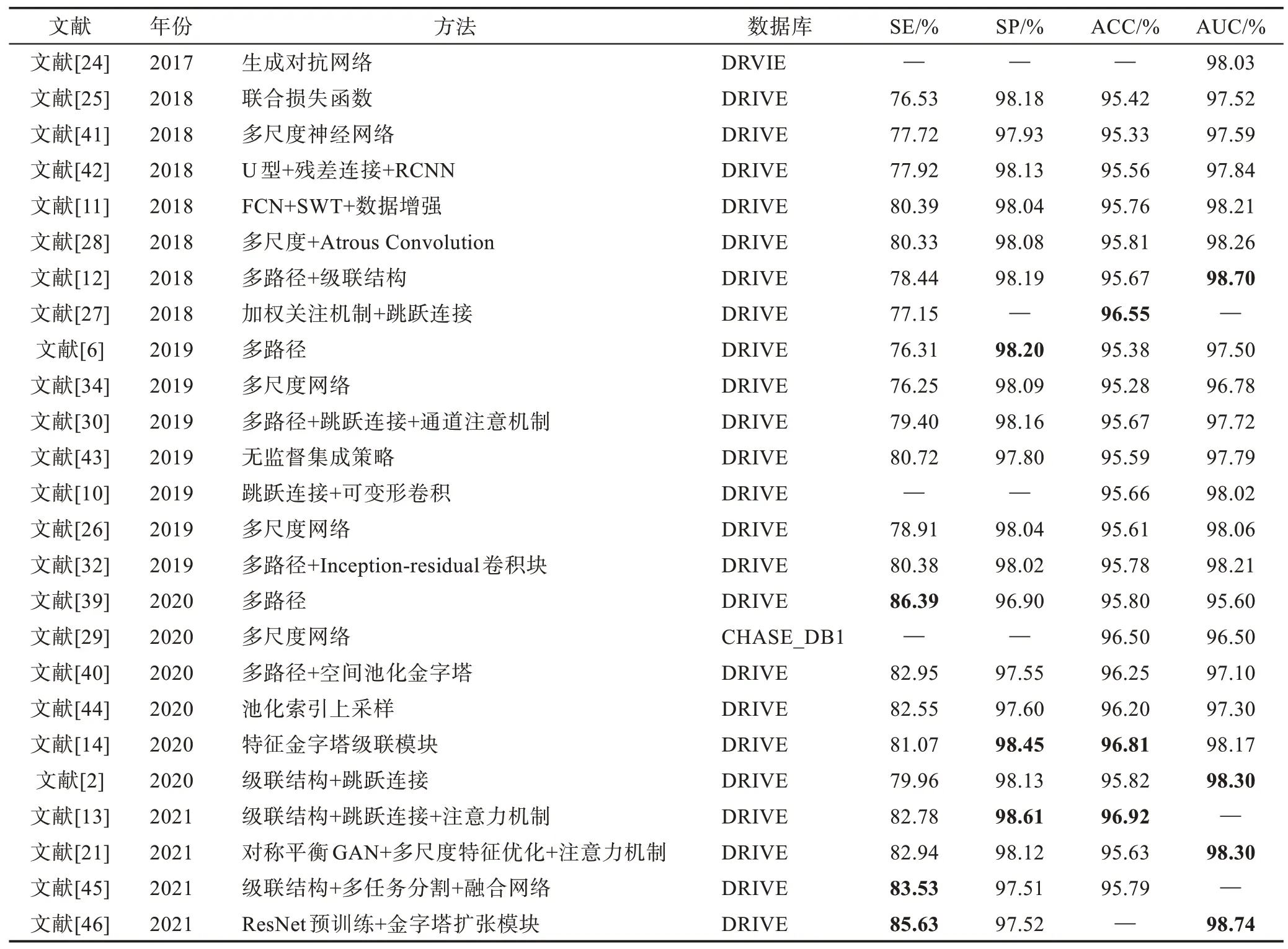
Table 6 Performance comparison of retinal vessel segmentation methods表6 视网膜血管分割方法的性能对比

Table 7 Analysis of algorithm complexity表7 算法复杂度的分析
在文献[2,13,39]中都考虑了对于薄血管分割的问题,在文献[2,13,32]中都考虑了血管结构预测的问题,在文献[12,14,39]中都考虑了血管分割结果中血管不连续的问题,在文献[14]中考虑了血管尺度变化大的问题。对于这些最新的相关研究关注的问题都只是解决了某一个或者两方面的问题,而没有解决所有的问题。
总的来说,目前视网膜血管分割算法对于一些模糊小血管的分割存在着困难,虽然目前有一些针对这个问题的算法,但是敏感性始终维持在83%左右,还存在着很大的提升空间,同时这些模糊小血管还是造成分割结果中血管断裂的主要因素;对于分叉交叉这些血管的连接处,算法的分割可能会出现断裂的问题;对于视网膜中存在病变区域的血管分割还是存在着问题,且相关研究较少。
2.3 现实部署的尝试
在移动设备硬件资源不足的情况下,包含大量参数的神经网络的现实部署就会存在一些限制。一方面神经网络不能超过设备的存储和计算大小的极限,另一方面还要满足一定的性能要求。在视网膜血管分割任务中,相关人员探索了轻量级的卷积神经网络。如Hajabdollahi 等人[31]提出了一种基于量化和剪枝相结合的神经网络。其中全连接层被量化,卷积层被修剪,网络的参数减少了60%。在STARE数据集上SE=75.99%,SP=97.57%,ACC=95.81%,算法在SE和SP 的指标上获得了当前接近最优的性能,证明了简化CNN 有作为便携式视网膜诊断设备中血管自动分割方法的潜力。随后,Laibacher等人[47]提出了M2UNet网络的参数只有0.55×106,相较于U-Net网络31.03×106的参数来说明显降低。在Rockchip RK3399平台上进行测试时,M2U-Net的推断时间只需要5 870.0 ms,而U-Net的推断时间则需要8 460 000.0 ms,证明了网络实时分割的潜力。Li 等人[3]沿用U 型网络的结构并整合了注意力机制模块,模块提升了中间层的利用率,适当地减少模型的深度,最深的特征图仅仅只有128 通道,模型总共只有0.4×106的参数。Wei 等人[48]考虑到人工设计神经网络是非常费时的,因此基于遗传算法自动设计一个轻量级的U 型网络,网络对于每张图片的推断时间只有27.5 ms,网络参数仅有0.27×106。Atli 等人[49]提出了一种新颖的全卷积神经网络,利用上采样和下采样的方式构建了形状类似正弦波的网络,网络的每张图片的推断时间为350.0 ms。表8是近些年关于轻量化网络的总结。
通过以上总结可以看到神经网络具有落地应用的潜力。在移动设备硬件资源局限的情况下,设计一个性能达标并且参数尽可能小的神经网络是一个值得探索的方向。
2.4 其他值得关注的研究
生成对抗网络一般用于生成图像数据[51],由鉴别器和生成器两个网络组成。当鉴别器试图区分生成器的生成图像和金标准图像时,生成器试图生成鉴别器无法区分的图像。近些年来也有人将生成对抗网络(GAN)用于图像的分割,比如Son 等人[24]将GAN 用于视网膜血管的分割,并且在DRIVE 数据库上AUC=98.03%,接近当前Gridach[46]AUC=98.74%的最优性能。虽然直接使用GAN 网络可以获得较好的分割结果,但GAN 的鉴别器较少有相关结构的研究,尽管鉴别器不直接生成图像,但是它也需要足够的能力去识别生成图像和真实标签之间细节的差别。为了保证鉴别器能够提取高分辨率的细节信息,Zhou 等人[21]在GAN[22]网络的生成器和鉴别器上都使用U-Net 作为基础网络,构建出对称平衡体系,保证了鉴别器有能力提取高分辨率的信息。同时在生成器中嵌入了多尺度特征细化块(multi-scale features refine block,MSFRB),MSFRB 优化了高分辨率的浅层特征和高层语义特征,并且促进了它们的融合。在MSFRB 分支中加入了注意力机制(attention mechanism,AM)抑制了不重要的特征。提出的对称均衡生成对抗网络(symmetric equilibrium generative adversarial network,SEGAN)在DRIVE数据集上AUC=98.30%。GAN 网络的鉴别器可以鉴别生成分割图和真实标签之间的差异,相对于全卷积和编码解码类型的网络多了一个校正错误的老师,不断促使生成器去生成接近真实标签的血管分割图,并且相关研究结果表现出较好的性能。因此将GAN 系列网络用于视网膜血管的分割是一个有潜力的研究方向。

Table 8 Performance and parameter comparison of light-weight networks表8 轻量级网络的性能以及参数对比
在深度学习中损失函数决定模型最后收敛的区域。设计一个针对特定任务的损失函数有助于模型的收敛。Yan 等人[25]设计了一个针对视网膜血管分割任务的联合损失函数,它是由分段级损失和像素级损失组成的,这种损失让厚薄血管在损失计算中的重要性更加均衡,在一定程度上解决了厚血管和薄血管分布不均匀的问题,在DRIVE 上SP=98.18%,接近当前Lian 等人[13]SP=98.61%的最优性能。因此设计一个针对视网膜血管分割任务的损失函数是值得探索的研究方向。
3 总结和展望
视网膜眼底图像提供了丰富的病理变化信息,可用于黄斑变性、糖尿病视网膜病变、青光眼等眼病的诊断。在眼底图像的各种特征中,视网膜血管特征起着至关重要的作用。为了提取视网膜血管的特征,生成一个精确的视网膜血管分割是必要的。本文对近年来基于深度学习的视网膜血管分割方法的研究进行回顾总结,得到的结论及下一步的研究方向如下:
(1)总结了5 个常见的眼底图像数据库,其中在研究中使用最多的是DRIVE 数据库。这些开源数据库有效推进了深度学习在眼底视网膜血管分割方面的应用,然而现有眼底图像数据库建立工作仍存在一些不足,主要表现在数据库的标准并不统一和数据库的数据较少等方面。建立有一定数据规模的高质量眼底图像数据库,是下一步研究的重要工作内容。
(2)数据增强、图像预处理及图像切片处理,常用在视网膜血管分割任务中,在现有研究中使用较多的数据增强技术为水平或竖直翻转,使用较多的图像预处理方法为图像灰度化和标准化。
(3)从网络架构的角度可将视网膜血管分割网络分为级联结构、多路径和多尺度神经网络。级联结构网络的第一级可以确定视网膜血管形状和大概位置,第二级对第一级网络的分割结果进行优化,这种结构适用于结构复杂的视网膜血管的分割。多路径神经网络通过整合不同路径的信息就可以得到更加全面的信息,避免了神经网络在训练过程中过度关注某一方面的信息,而忽略了其他重要的信息,多路径神经网络在视网膜血管分割任务中就可以一定程度上避免神经网络训练时对粗血管的依赖程度过高,而忽略细血管的问题。
(4)部分先进网络推断时间可以达到毫秒级,计算消耗在兆以下,网络的大小在10 MB 以下。这些性能良好的网络具有实际应用的潜力。
(5)对于薄血管,病变区域的分割以及对于血管结构的预测,还是存在困难,而且分割中可能会出现血管断裂的情况。目前的算法只是针对单一问题做出了相关研究,并没有同时解决所有的问题。
(6)目前用于视网膜血管分割任务综合最优的神经网络是级联结构的神经网络,网络达到的敏感性、特异性、准确性分别为82.78%、98.61%和96.92%。
(7)在移动设备硬件资源限制的情况下,网络轻量化是值得探索的方向。GAN 系列网络用于视网膜血管分割及设计针对视网膜血管任务的损失函数是未来有潜力的研究方向。
