PEST:由PYNQ 集群实现的高能效NEST 类脑仿真器
2021-11-17李佩琦郁龚健刘家航柴志雷
李佩琦,郁龚健,华 夏,刘家航,柴志雷,3+
1.江南大学 物联网工程学院,江苏 无锡214122
2.江南大学 人工智能与计算机学院,江苏 无锡214122
3.江苏省模式识别与计算智能工程实验室,江苏 无锡214122
当前,以深度学习为代表的智能计算系统仍存在系统能耗高、通用智能水平弱两个主要瓶颈,难以成为解决人工智能问题的终极手段[1]。而人类的大脑是由约1011个神经元、1015个突触构成的复杂生物体,不但具有很高的智能水平而且功耗只有20 W 左右[2],其计算模式非常值得研究借鉴。目前的类脑计算主要基于工作机理更接近生物大脑的脉冲神经网络(spiking neural networks,SNN)来实现[3]。由于达到一定规模的SNN 才能展现出较强的智能水平,类脑计算最具挑战性的难题之一,就是对大规模SNN进行仿真时保持系统的高性能及低功耗。
针对类脑计算的高能效需求,工业界和学术界尝试采用专用类脑芯片和系统来实现脉冲神经网络。2018 年曼彻斯特大学推出了SpiNNaker2 神经芯片,该芯片相比第一代专门构建了用于指数和对数运算的硬件加速器,通过定点化设计,在有一定精度损失的情况下提高了芯片能效比[4-5]。2020 年,英特尔推出神经拟态系统Pohoiki Springs,其内部由768颗Loihi 神经拟态芯片组成,该系统在低于500 W 功耗的情况下可使用多达1 亿个神经元来执行任务[6]。“天机芯”是清华大学类脑计算研究中心施路平团队研发的一款新型人工智能芯片,整个芯片由156 个计算单元(Fcore)组成,包含约4 万个神经元和1 000 万个突触,支持机器学习算法和现有类脑计算算法[7]。2020 年浙江大学推出了类脑芯片“达尔文2”,该芯片由576 个内核组成,每个内核支持256 个神经元,神经突触超过1 000 万,通过系统级扩展可构建千万级神经元类脑计算系统[8]。
专用的类脑芯片与系统可以达到更佳的性能和功耗指标,但存在面向不同应用时适应性差的缺陷。当其与应用负载不匹配时,能效表现会大打折扣。例如,在SpiNNaker 上运行一个全尺寸皮质微电路模型时[9],由于该模型中神经元连接的突触数量超过了SpiNNaker 设定的最优值,平台无法运行在最优状态,计算能效还不如基于高性能集群的NEST 软件模拟方式[10]或单块GPU(graphics processing unit)方式[11]。
类脑计算的另一种实现方式是以软件方式构建类脑仿真器,目前比较成熟的类脑仿真器如Brain[12]、NEST[13]、BindsNET[14]等已得到了大量的应用,并且形成了各自的生态。采用软件方式实现具有灵活性强、精度高等优点,但存在计算复杂度高、仿真速度慢、运行功耗高等问题。
软件实现的类脑仿真器中,NEST 仿真器生态完整、用户众多,相比其他类脑仿真器,NEST 交互接口完备,可以在Arm、X86 等不同计算平台上运行,并且支持并行与分布式计算。本文首要解决的工程问题是如何在保持良好应用生态的前提下追求计算能效最高,因此本文的工作选择通过PYNQ 集群加速NEST,而不是直接做类脑芯片或系统。
在基于PYNQ 集群加速NEST 时,需要解决的关键问题是如何通过硬件定制、软硬件协同,使得SNN的应用负载和硬件平台相互最佳适配,达到最佳能效。本文提出一种基于PYNQ 集群的高能效NEST类脑仿真器PEST,希望以此为类脑仿真提供一个合适的计算平台,本文的主要工作如下:
(1)构建大规模PYNQ 集群,实现基于NEST 仿真器的规模可伸缩类脑计算系统;
(2)针对单节点进行优化,设计软硬件数据交互接口,通过FPGA(field programmable gate array)并行与流水化设计、计算定点化等实现IAF 神经元FPGA硬件加速;
(3)针对集群整体进行优化和分析,设计集群的网络文件系统,分析集群性能功耗平衡点,通过消息传递接口(message passing interface,MPI)分布式计算实现PEST 高能效计算。
1 NEST 仿真器
NEST 是一个可以构建大规模神经网络模型的脉冲神经网络仿真器。它包含了50 多种神经元模型和10 余种突触模型[15]。在NEST 中,不同的神经元和突触模型可以共存,任何两个神经元都可以有不同性质的多重连接。NEST的另一个特点是可以进行扩展,用户可以添加自定义神经元、突触和设备模型[16]。目前NEST 作为主流的脉冲神经网络模拟器被广泛使用。NEST 的应用从基础的单个神经元实现[17]到复杂的人类小脑网络模型仿真[18]都有涉及,并且运行在NEST 上的应用都可通过Python 语言进行开发。
如图1 所示,NEST 仿真器在运行时主要包含创建、连接、仿真3 个阶段。在仿真阶段中一般又分为发送、更新和收集3 个部分。针对不同的应用场景,每部分的仿真时间所占的比例有一定的差异。
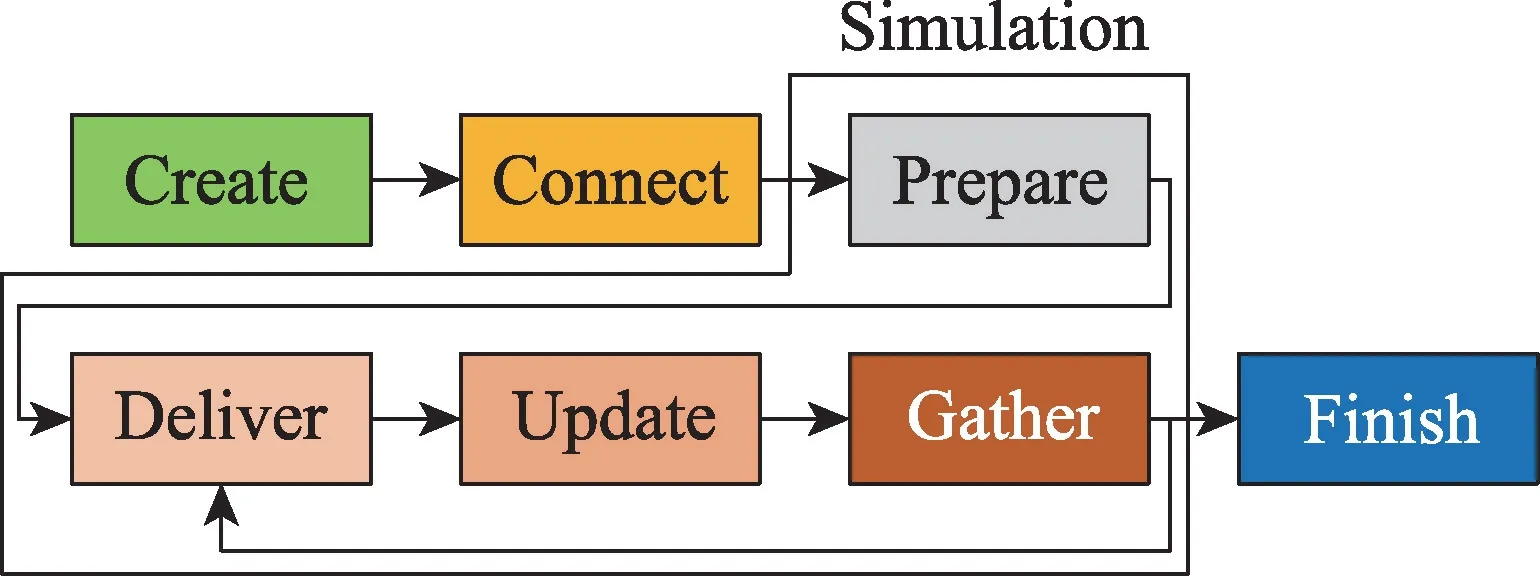
Fig.1 NEST simulator running mechanism图1 NEST 仿真器运行机制
NEST 仿真器通过C++进行开发,在NEST 中包含一个独立的PyNN 后端接口,允许与PyNN 配合使用。PyNN 是一款开源的神经网络仿真器的通用接口,用户可以通过PyNN 将Python 脚本直接运行在NEST 仿真器上,实现通过Python 对NEST 的编程和调试。
NEST 可支持并行与分布式计算,它通过自身包含的MPI 通信协议与多台计算机进行数据通信。通过MPI 的并行编程模式可以建立一个由多台计算机构成的计算集群,图2 展示了NEST 运行小型分布式网络时的运行机制。

Fig.2 NEST parallel distributed computing diagram图2 NEST 并行分布式计算图
图2 中,NEST 运行在由2 台计算机(节点)构成的分布式计算平台上,NEST 进行分布式计算时会将要计算的神经元平均分配给每个节点,图中设定4 个IAF 神经元,因此每个节点分配2 个,Proxy 用来表示存在于其他节点上的神经元id。Sg 和Sd 分别代表脉冲生成器和脉冲探测器,这两部分需要在每个节点上进行构建。
2 基于PYNQ 的计算集群设计与搭建
2.1 PYNQ-Z2 计算节点
计算集群采用Xilinx PYNQ-Z2 开发板构建。其主芯片为Zynq 7020,该芯片是Xilinx 公司推出的全可编程SoC 芯片(all programmable system on chips,APSOC)。如图3,它主要由ARM 处理器(processing system,PS)和可编程逻辑FPGA(programmable logic,PL)两大部分组成[19],两部分的数据主要通过AXI 总线进行传输。
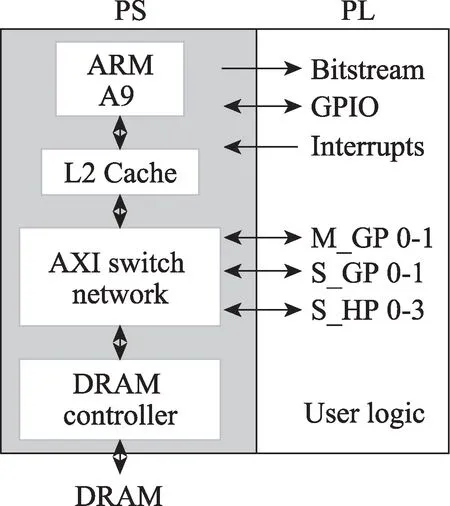
Fig.3 Hardware architecture of PYNQ-Z2图3 PYNQ-Z2 硬件架构
2.2 PYNQ 框架
PYNQ 框架是在FPGA+CPU 异构系统的基础上引入了Python,其提供了一种更友好、更易用的开发方式,降低了FPGA 开发门槛。PYNQ 开源框架主要包含PYNQ 硬件库和Overlay 设计两部分[20]。PYNQ硬件库可用于加速软件应用程序,或为特定应用程序定制专用硬件平台。Overlay 设计由两个主要部分组成,一个是PL 设计(生成bitstream),另一个是Tcl项目框图文件。PL 设计通常是高度优化的特定任务,Overlay 通常设计为可配置的,可用于不同的应用程序中。
图4 为PYNQ 框架硬件结构图,用户通过PC 访问ARM 端的Jupyter,在Jupyter 中可以调用PYNQ 硬件库控制FPGA 以实现各种功能。
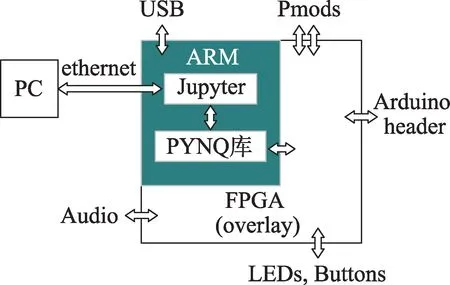
Fig.4 Hardware structure diagram of PYNQ framework图4 PYNQ 框架硬件结构图
2.3 PYNQ-Z2 计算节点
2.3.1 整体设计

Fig.5 Cluster hardware structure diagram图5 集群硬件结构图
PYNQ 集群的结构设计如图5 所示,整体可以分为三层:第一层为计算节点层;第二层为网络交互层;第三层为系统控制层。计算节点层在PYNQ 集群中负责数据的处理,该层每个节点间没有连接关系,各节点都通过以太网连接到网络交互层。网络交互层主要是由网络交换机组成的,在运行时计算节点间会相互发送脉冲信息,该层的主要任务是负责节点间信息传输,另外系统控制层的各种指令会通过该层发送到每一个节点上,该层还起到连接系统控制层和计算节点层的作用。系统控制层由计算节点中的主节点构成,任意节点都可充当主节点,用户可自行定义,它相比其他节点最大的不同是要负责计算任务的分发和接收其他节点处理完的计算结果,主节点在系统运行时也要执行相应的计算任务,整体上与其他节点的差异很小。
该集群可扩展性强,由于在本集群中不涉及到任何的专用电路,可以根据需要对集群规模进行相应的调整。如果要对计算节点进行扩充只需要将新的计算节点与网络交互层相连并且保证主节点能够访问到该节点即可。PYNQ集群计算平台如图6所示。

Fig.6 PYNQ cluster computing platform图6 PYNQ 集群计算平台
2.3.2 集群计算规模
单块PYNQ 开发板的内存大小为512 MB[21],通过实际测试,在排除用于运行系统和NEST 仿真器初始化所需要的内存后,可用的内存大小约为200 MB左右。NEST 仿真器运行时每个神经元和突触所占用的内存大小分别约为1 500 B 和50 B[22]。如果NEST 运行在单节点上,每个节点上最多可以支持14万个神经元或者410 万个突触的计算规模。如果多个节点同时工作,由于NEST 在进行分布式计算时会将神经元和突触平分给全部节点进行计算,在单节点的计算规模不变的情况下,增加节点数量,相当于成倍扩大了计算规模,理论上N节点的集群最大支持14×N万个神经元计算或者410×N万个突触计算。
2.3.3 网络设计
集群在运行时,位于各节点上的神经元在达到阈值时会发射脉冲给目标神经元,如果目标神经元位于其他节点上则会通过网络交互层将脉冲信息发送到对应节点,在PYNQ 集群中使用了2 个千兆交换机通过桥接的方式构建网络交互层。NEST 中单个神经元发送脉冲时通信数据量为4 B,并且单个神经元脉冲发射频率通常低于100 次/s[16]。假设每个节点都工作在理论最大神经元数量下,并且全部神经元的所有脉冲都发射到其他节点,那么每个节点的通信量为53 MB/s,千兆交换机的传输速度高于该值,可以保证集群物理层的数据传输需求。
3 基于PYNQ 集群的NEST 软硬件协同设计
3.1 单节点的实现与优化
3.1.1 单节点实现
单节点设计如图7 所示,用户可以通过Python 设计SNN 计算模型并运行在Jupyter Notebook 上,在Jupyter Notebook 中调用PyNN 库,PyNN 通过PyNEST界面或者SLI 解释器运行NEST 来实现相应的功能,ARM 端的NEST 仿真器包含有AXI 接口可以实现与FPGA 部分的数据传输。由于FPGA 设计灵活、可以并行计算的特点,可以将NEST 仿真器上适合并行计算的步骤(神经元更新、突触更新等)根据使用需求移植到FPGA 上进行计算,提升NEST 仿真器的整体计算速度。

Fig.7 Single-node PEST structure framework图7 单节点PEST 结构框架
3.1.2 PYNQ-Z2 内存分配
在PYNQ 中通常会通过CMA 函数申请一段连续内存来实现ARM 与FPGA 之间的信息交互。CMA 函数申请到内存后会将内存的起始地址发送给ARM 与FPGA,ARM 与FPGA 再将所要相互传输的数据写入到这块内存中以供对方通过内存地址直接读取。通过CMA 函数申请内存可以根据实际需求申请内存大小,但是采用此种方法申请的内存起始地址随机,并且每次使用时都需要重新申请。
为了方便ARM 与FPGA 之间进行数据的交互,将PYNQ-Z2 的内存空间专门划分出一部分用于数据交互,避免每次使用时都要重新申请内存,内存优化如图8 所示。在PYNQ 中DDR 大小为512 MB,内存地址为0x0-0x20000000,划分的共享内存大小由所传输的数据量决定,计算公式为:
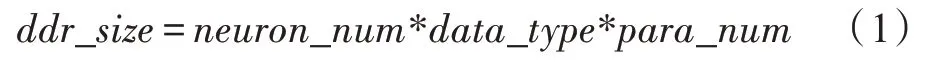
其中,ddr_size为内存的整体大小;neuron_num为神经元的数量;data_type为数据类型;para_num为神经元的参数数量。
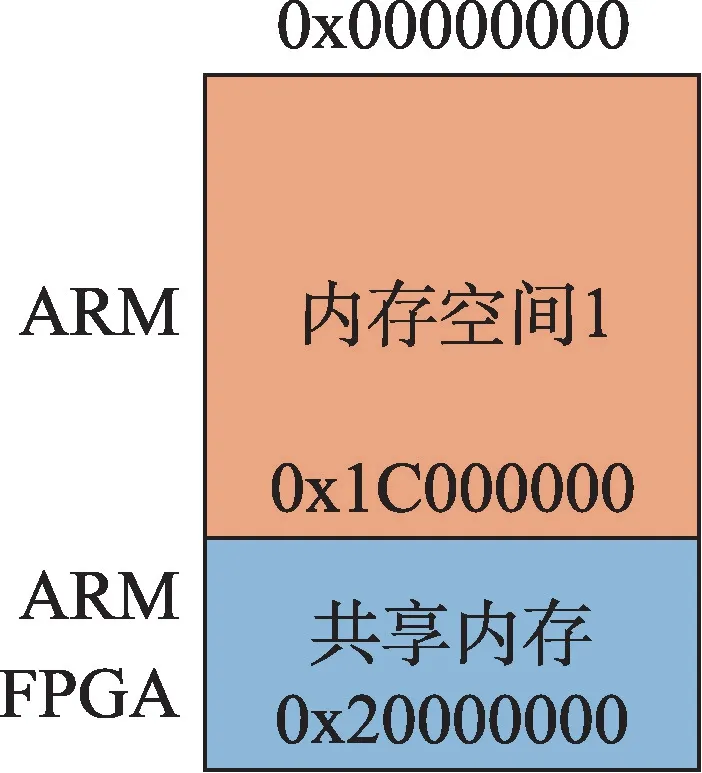
Fig.8 PYNQ-Z2 shared memory allocation diagram图8 PYNQ-Z2 共享内存分配图
根据公式,本设计将每个节点的共享内存大小设定为64 MB,起始地址为0x1C000000,该共享内存大小可以保证单节点在最大神经元数量时每个神经元存储119 个4 B 参数,满足NEST 计算时的使用需求。内存重新分配后,ARM 与FPGA 进行数据交互可以直接将数据写入共享内存中而不需要每次重新申请内存。
3.1.3 通用数据传输接口设计
NEST 运行时神经元与突触的类型和数量与计算模型的需求相关,在运行不同的计算模型时NEST计算瓶颈会有很大的不同,用户可以根据不同的计算需求将需要被加速的计算模块放到FPGA 上进行并行和流水化设计,因此设计通用的数据传输接口非常必要。
ARM 端与FPGA 两部分数据传输的接口设计如图9 所示,被加速部分为计算瓶颈,将该部分在ARM端移除,放到FPGA 部分重新设计。当ARM 端的NEST 仿真器开始运行时,首先映射一段共享内存用来存放需要FPGA 计算的数据,当开始仿真时,将计算所需数据存入共享内存中。

Fig.9 Software and hardware general data interface structure diagram图9 软硬件通用数据接口结构图
当数据准备完成后,通过软件驱动程序将内存映射的地址data_address 通过AXI 控制总线发送给FPGA,FPGA 根据data_address 读取共享内存中对应数据进行计算。该部分的伪代码如下所示,其中mem_size为每段数据所需要的内存大小,fpga_address为FPGA 控制总线的基地址,offset 为控制总线的地址偏移量。

计算完成后FPGA 会通过AXI 控制总线发送完成信号到ARM 端,ARM 端接收到完成信号从共享内存的指定位置读出所需数据继续运行并解除映射,该部分伪代码如下所示:

3.1.4 IAF 神经元的硬件设计
在NEST 仿真器中,每个神经元的计算相对独立,各个神经元在进行更新的时候不会用到其他神经元的数据和参数,该种计算方式非常适合通过FPGA 进行并行计算。IAF 神经元是指数泄漏积分-触发神经元模型,其在SNN 中应用广泛,计算相对复杂,很可能会成为影响计算速度的瓶颈,对其进行硬件加速十分必要。在不应期之前IAF 神经元只更新部分参数,只有当不应期到来之后,IAF 神经元才更新膜电位的值,膜电位的计算公式如下所示:
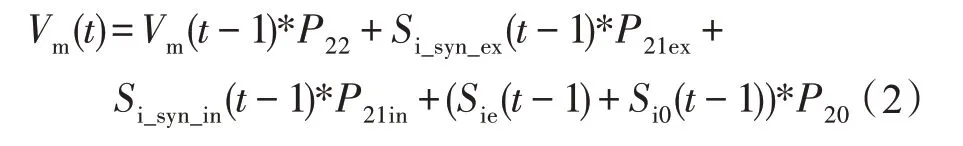
式中,Vm(t)为更新后的神经元膜电位,Vm(t-1)为更新之前的神经元膜电位,P22、P21ex、P21in、P20分别对应膜电位衰减因子、兴奋型电流衰减因子、抑制型电流衰减因子和初始化与外部电流的衰减因子,Si_syn_ex和Si_syn_in分别为兴奋型电流和衰减型电流,Sie为外部输入电流,Si0为初始化电流。
针对上述的计算方法,IAF 神经元的硬件电路设计如图10 所示,整个硬件电路分为三个阶段:第一阶段的主要工作是将单个神经元计算所需要的衰减值、电流值和更新前的膜电位Vm(t-1)送入计算单元中进行计算,得到最新的膜电位Vm(t);第二阶段的工作是将Vm(t)与门限值进行比较,如果Vm(t)大于门限值则进入第三阶段,否则将Vm(t)值暂存用于下一次的计算;第三阶段Vm(t)会进行复位并将该神经元ID存入IDBuffer用于后续的计算。
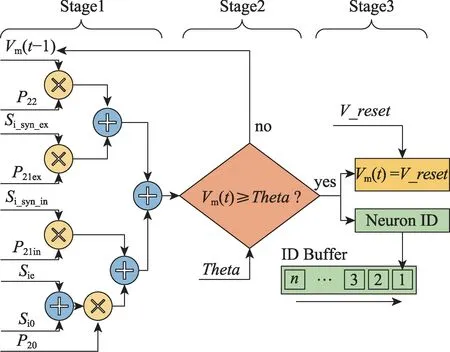
Fig.10 Hardware implementation of IAF neuron图10 IAF 神经元硬件实现
在NEST 仿真器中神经元计算为串行计算,正常情况下神经元读写数据各需要一个时钟周期,假设单个神经元的计算时间(latency)为N+2 个时钟周期,当串行计算时整体的计算时间为神经元数量与单个神经元计算时间的乘积。
由于每个神经元的计算参数各自独立,神经元间的数据没有相互依赖性,可以对神经元计算部分进行并行化处理,但由于数据吞吐量和FPGA 逻辑资源的限制,计算并行度有一定的局限性,通过设计流水化的计算结构可以在资源受限的情况下大幅提高资源利用率,提高整体的计算性能。
针对IAF 神经元的流水化设计如图11 所示,IAF神经元的计算过程在图中简化为读取数据(Rd)、计算(Ex)、写回数据(Wr)三部分,其中num代表并行计算的神经元数量,每个神经元的计算时间同样为N+2 个时钟周期,当同时使用并行处理和流水化操作后,其总体计算时间公式如下所示:

式中,all_latancy代表计算所需要的整体时间,latency代表单个神经元的计算时间,neuron_num为整体的神经元数量,num为神经元计算时的并行度。

Fig.11 IAF neuron pipelining data processing图11 IAF 神经元流水化数据处理
3.1.5 IAF 神经元数据传输优化
IAF 神经元的膜电位大于门限值时会对外发射脉冲,同时更新计算参数和权重,当通过FPGA 进行神经元计算时,每次需要传输的数据量如下所示:

其中,spike_num代表发射脉冲的神经元数量,data_type为数据类型,para_num为每个神经元需要更新的参数数量。IAF 神经元计算参数较多,并且NEST 仿真器中数据大多采用双精度浮点数,如果每次计算后对所有参数进行更新则每个神经元单次更新的数据有80 B。通过对IAF 神经元的参数和计算结果进行分析,神经元的计算参数并不是每次计算后都需要更新,对全部计算参数根据不同的更新需求进行分类,每次计算时只更新必要的数据以减少数据传输量,减少数据传输时间,输入数据的设计如图12所示。

Fig.12 Data input interface diagram图12 数据输入接口图
IAF 神经元的衰减因子在模型运行后初始化,整体的数据量不超过56 B,并且在运行阶段不会改变,通过AXI_LITE 接口传输衰减因子可以减少高速接口的使用,节省资源。
IAF 神经元的电流值与电压值同样只在模型运行的初始化阶段进行赋值,但由于神经元数量巨大,使用性能更好的AXI_Master 接口进行数据传输,可以减少数据传输时间,计算传输时间的公式如下所示:
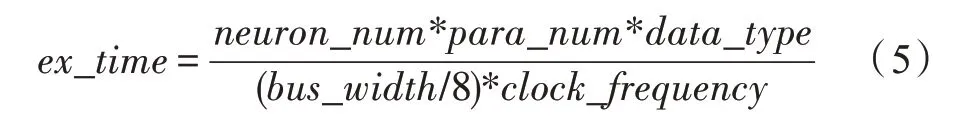
式中,ex_time为传输时间,bus_width为总线位宽,clock_frequency为时钟频率,由于AXI_Master 总线最大数据位宽为64 bit,在时钟频率为100 MHz 的情况下,总线带宽高达763 MB/s,足够满足大量神经元的数据传输要求。
IAF 神经元的门限值和复位电压等参数会在更新训练图片时进行更新,更新频率较低,但每次更新时的数据量很大,对这些参数通过同一组AXI_Master接口进行数据传输。
最后单独设计一个AXI_Master 接口用于发出IAF 神经元ID 并更新权重值,神经元发射脉冲时会将该神经元的ID 发送到ARM 端,并接收ARM 端发送过来的新权重值,因此每次FPGA 发送的神经元ID个数与接收到的权重值数量保持一致,将这两个相关的参数放到同一个高速接口上可以节省接口资源,还可以在每次数据传输时检查数据数量是否一样,保证数据传输的准确性。
3.1.6 IAF 神经元计算定点化
NEST 仿真器中默认的数据类型为双精度浮点型,如果在FPGA 中使用双精度浮点型数据进行乘法或加法运算会大量消耗FPGA 上的DSP 资源,严重影响神经元计算并行度。
IAF 神经元计算时包含兴奋和抑制两种类型的衰减因子,它们在模型初始化时生成且都为固定值,其计算公式为:

其中,P为衰减因子,h为模型分辨率,tau为时间常数。由公式可知,衰减因子的数值主要分布在0~1之间。
NEST中,IAF神经元默认的阈值电压为15 mV[23],当神经元的膜电位超过阈值电压时神经元发射脉冲,膜电位清零,因此,膜电位数值主要分布在0~15范围内。
IAF 神经元的权重值分为兴奋权重和抑制权重,它们主要受脉冲发射率影响,权重值会随着脉冲发射率的提升而增大。IAF 神经元的脉冲发射率一般低于20 Hz[24],因此权重值同样存在一定数值范围。通过运行不同计算模型,统计IAF 神经元数据分布情况,结果如图13 所示。
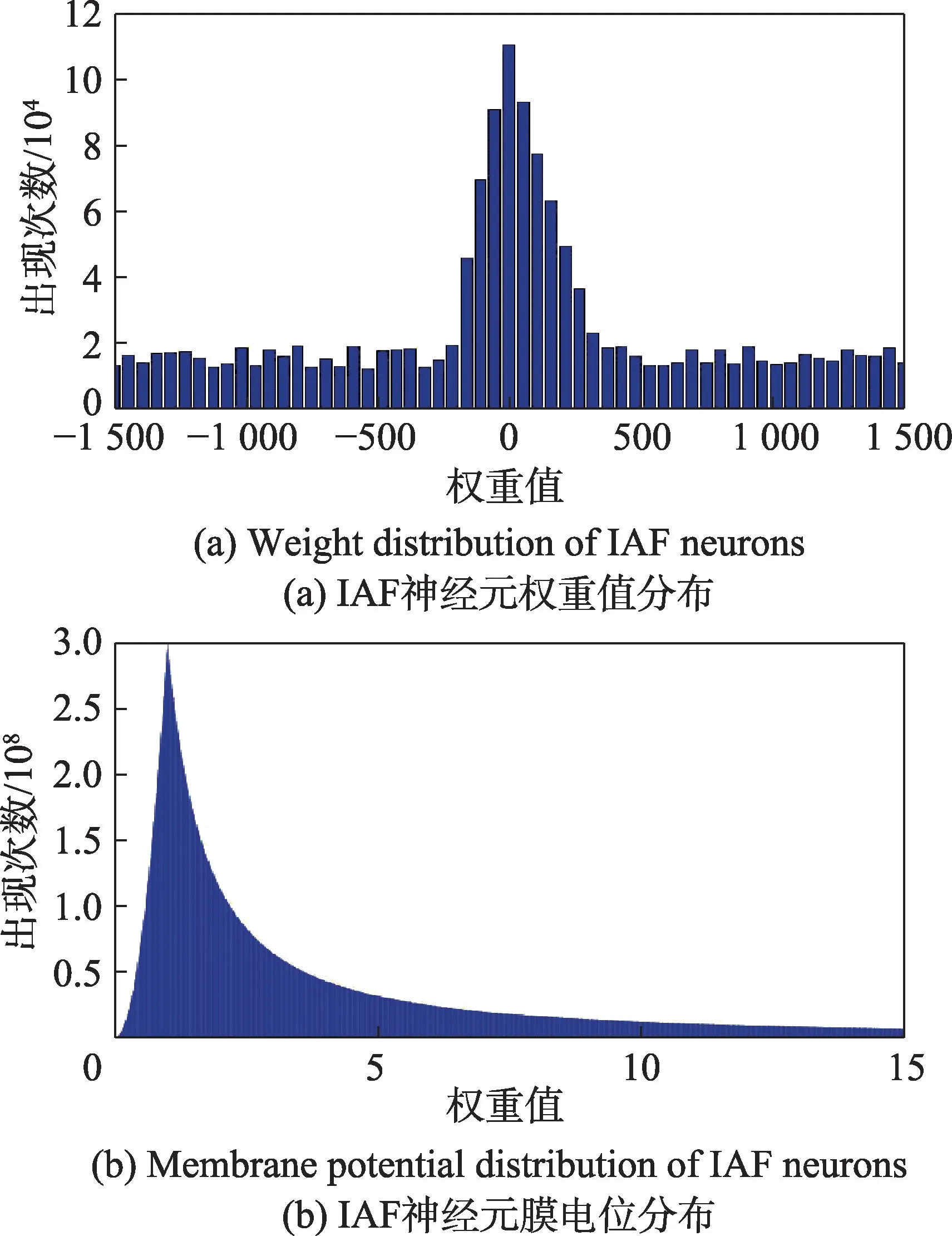
Fig.13 Data distribution of IAF neurons图13 IAF 神经元数据分布
如图13 所示,通过测试,IAF 神经元的权重值主要分布在-1 400~1 400 之间,其数值范围较大并且多为整数,将权重值转化为定点16 bit 数据,可以在保证计算精度的情况下减少数据位宽,降低资源消耗,定点与浮点数转化的计算公式如下所示。式中x为双精度浮点数,y为定点16 bit整数,Q为定标值。

对于权重值,当定点数的数据精度为Q4(-2 048 ≤x≤2 047.937 5)时即可满足使用需求。
衰减因子和膜电位大多位于0~1 之间,进行计算时需要较高的精度。由于膜电位整数部分最少需要5 bit数据,如果使用定点16 bit进行计算,数据精度最多为Q11,会存在很大的精度损失。为保证更好的数据精度,将膜电位和衰减因子转换成半精度浮点数进行计算,使用半精度浮点数可以减少数据位宽,减少硬件资源的开销。在Xilinx 高层次综合语言中包含有半精度浮点数(half)的功能,在硬件设计时可以直接使用half 进行硬件设计。half 由16 bit 数据组成,可以表示6.10×10-5~6.550 4×104范围内的数值,在满足整数范围的同时小数位可以达到定点数Q14的精度。对定点16 bit、half、float 和double 类型的资源消耗进行对比,如图14 所示,相比之下使用定点16 bit和half类型的数据可以极大节省硬件资源。
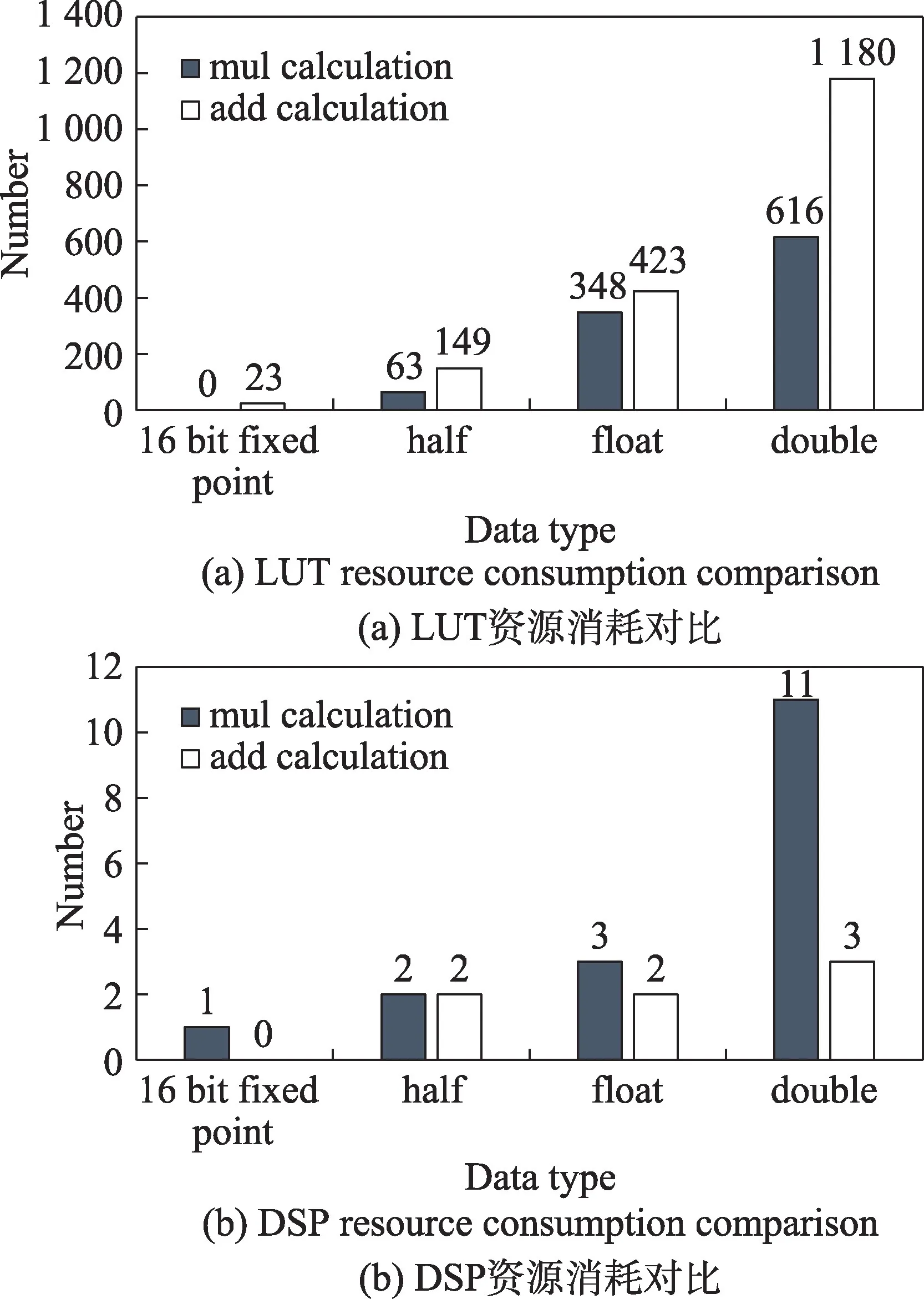
Fig.14 Resource consumption comparison of different data types图14 不同数据类型资源消耗对比
3.2 基于集群的实现与优化
3.2.1 基于PYNQ 集群的实现
如图15 所示,整个集群通过以太网进行连接,集群中的每个节点除了包含PYNQ 异构计算单元外,还包含一组receive buffer 和send buffer,其中receive buffer 的作用是接收其他节点发送过来的脉冲信息供本节点进行计算;send buffer 作用与receive buffer相反,用于将本节点内产生的脉冲发送给其他节点。

Fig.15 Operation mechanism of PYNQ cluster图15 PYNQ 集群的运行机制
通过MPI 在多节点上运行NEST 仿真器时,仿真器首先会将神经元与突触的整体连接关系记录下来,再根据节点分布情况将神经元和突触平均分配给每一个节点进行计算。当其中一个节点上的某个神经元需要发送脉冲时,该节点会将神经元信息放到send buffer 中并通过以太网发送给目标节点,目标节点通过receive buffer 接收脉冲信息,进行后续的计算。计算结束后再通过MPI 将各节点的神经元计算结果收集起来。
3.2.2 PYNQ 集群计算平衡点分析
在理想情况下,如果运行相同的计算模型,集群每个节点分配的计算量与节点数成反比,节点越多单个节点的计算量越小,整体计算速度越快。但是随着节点增加,集群内节点间通信愈加复杂,节点间的通信量增加,通信时间会随着节点数增多而逐渐增加,集群整体计算性能甚至会在节点数过多时出现下降。
在集群运行时计算时间主要分为数据更新时间、通信时间和其他时间(运行准备时间、数据收集时间)这三部分。数据更新时间是集群用于计算的时间,它与计算量高度相关,当计算量一定时,随着节点增多该时间线性减少;其他时间根据不同的计算模型会有所不同,节点数量对该部分时间影响相对较小。影响集群通信时间的因素有很多,影响最大的分别为通信信息量、通信进程数和网络带宽,MPI通信时间的计算公式如下所示:

其中,tmpi(sendbuffer,P)为P规模下每次发送sendbuffer内数据所需要的时间,Td为整个计算的运行次数,tbandwidth为带宽限制所造成的时间影响。由于设计集群时对网络带宽需求进行过分析(2.3.3小节),网络带宽满足使用需求,tbandwidth可以忽略不计;tmpi(sendbuffer,P)可以通过时间统计函数进行实际测量,当计算节点增多或者计算规模增大时,tmpi(sendbuffer,P)所需要的时间会相应增多。
3.2.3 PYNQ 集群文件系统优化
如果对集群中某一节点的文件或配置进行修改,为保证集群能够正常运行,需要对所有节点都执行相同的操作。随着集群节点数量的增多,如果对每个节点的文件逐个修改会相当耗时,将网络文件系统(network file system,NFS)引入PYNQ 集群可以方便对各节点文件进行管理,集群中网络文件系统整体设计如图16 所示。
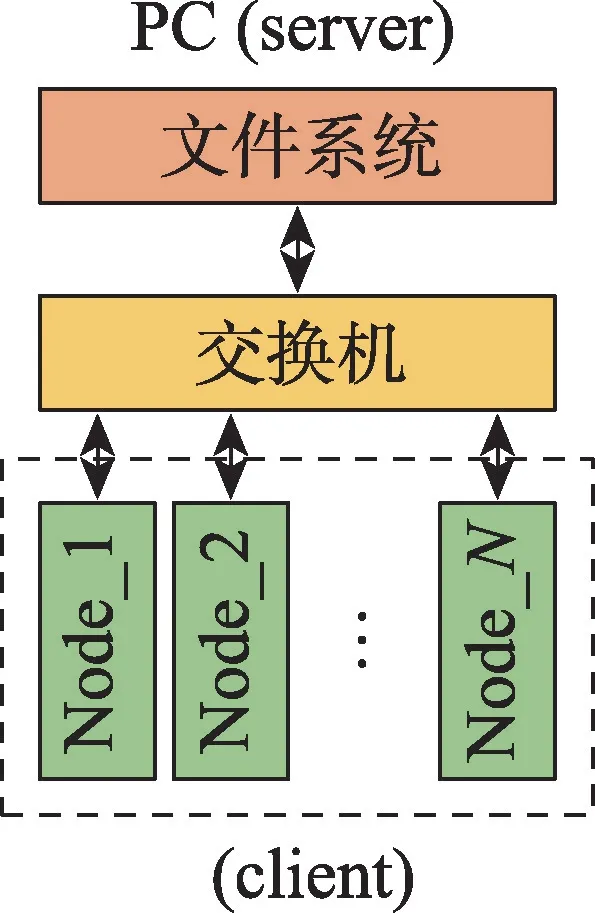
Fig.16 PYNQ cluster network file system structure图16 PYNQ 集群网络文件系统结构
图16 中,PC 作为服务器端存储集群的文件系统,不起到对集群的控制作用,PYNQ 集群的文件系统放在PC 指定的共享文件夹中,各节点作为客户端通过交换机将文件系统加载到本地。如果对各个节点添加文件或者进行修改,只需在PC 端的文件系统上进行修改即可,以此可以提高集群的使用效率。
4 实验结果
4.1 实验环境介绍
4.1.1 软硬件实验平台
软件环境:NEST 仿真器2.14 版本,PyNN API,XilinxVivado 2018.2,XilinxVivadoHLS 2018.2,PYNQ镜像2.4 版本。
硬件环境:集群每个节点为XilinxPYNQ-Z2 开发板(FPGA 部分BlockRAMs 资源140,DSP48E资源220,LUT 资源53 200,FF 资源106 400)。目前集群使用48 块PYNQ-Z2 开发板构建计算节点层,48 块开发板分成两组连接在2 台交换机上,位于网络交互层的交换机相互桥接将48 块开发板构建成一个完整的集群。
FPGA 加速部分通过Vivado HLS 进行设计,通过Vivado 工具综合实现整体硬件电路并生成bitstream,计算模型运行在Jupyter 上并通过PYNQ 框架进行调用。
对照组硬件环境:IntelXeonE5-2620(8 cores,主频2.1 GHz,128 GB 内存)和AMDRyzen5 3600X(6 cores,主频3.8 GHz,6 GB 内存,虚拟机)。
4.1.2 计算模型介绍
神经网络模型1:皮质层视觉模型
皮质层视觉模型是一个无监督的图像识别方案,该网络架构属于麻省理工学院提出的HMAX 模型中的一种,它可以模仿生物学的机制对图像进行分类[25]。如图17 所示,该网络为5 层网络,每层都由IAF 神经元组成,前4 层网络为模型的训练部分,由简单和复杂网络层(S1,C1,S2,C2)交替组成;第5层的模型推理部分主要由分类器构成。

Fig.17 Cortical visual model network structure图17 皮质层视觉模型网络结构
皮质层视觉模型使用Caltech 101 数据集进行模型训练与结果验证。实际使用时,数据集中的图片按照图片尺寸分成128×128、200×200 和300×300 3 个数据集分别进行测试。网络中的神经元数量与图片尺寸成正比,并且逐层递减(128×128 像素图像会生成约13 万IAF 神经元)。模型训练阶段每个神经元平均更新1 700 次,该时间占到了整体运行时间的92%以上,神经元在计算时相互独立,没有相互依赖关系,运行该模型时非常适合通过大规模集群并行计算的方法提升计算速度。
神经网络模型2:皮层微电路模型
该模型模拟1 mm2小鼠大脑皮层的运行机制,模型分为5 层,整体结构如图18 所示,L1 层代表大脑未被建模部分的外部输入,Th神经元群落代表丘脑皮层的输入,L2/3、L4、L5 和L6 层代表4 层皮质,每层皮质都包含一对兴奋性(三角形)和抑制性(圆形)群落[9]。
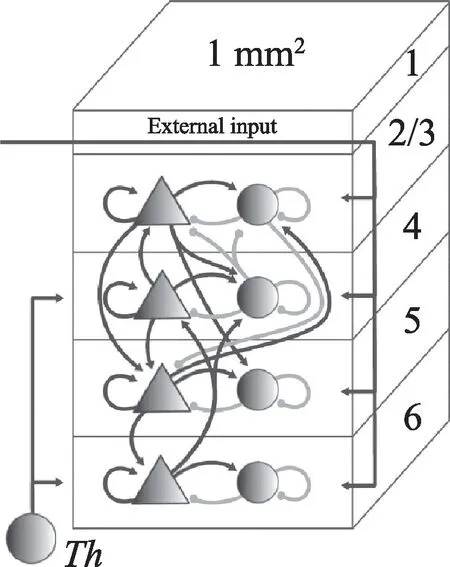
Fig.18 Cortical microcircuit model network structure图18 皮层微电路模型网络结构
该模型主要用于推断局部皮质网络的连通性与活性的关系,完整规模为80 000 神经元,但由于实验对照组AMD 3600X 平台受制于可用内存的限制,最多运行16 000 神经元,因此运行该模型时选择8 000和16 000 个IAF 神经元进行后续测试。该模型神经元数量相比皮质层视觉模型有所减少,但每个神经元平均计算次数为1 万次,因此同样存在整体计算时间过长的问题。
4.2 PEST 运行准确率验证
运行皮质层仿真模型的图片训练部分,对比原版NEST 与单节点PEST 的神经元脉冲发射率和脉冲激发图,验证计算结果正确性,测试图片选择128×128 像素大小,IAF 神经元数量13 万,图片数量10 张,每张图片的仿真时间为170 ms,步进值0.1,图片缩放量分别为1.00、0.71、0.50、0.35。通过观察运行过程中脉冲激发图可以验证计算结果的正确性,运行结果如图19 所示。
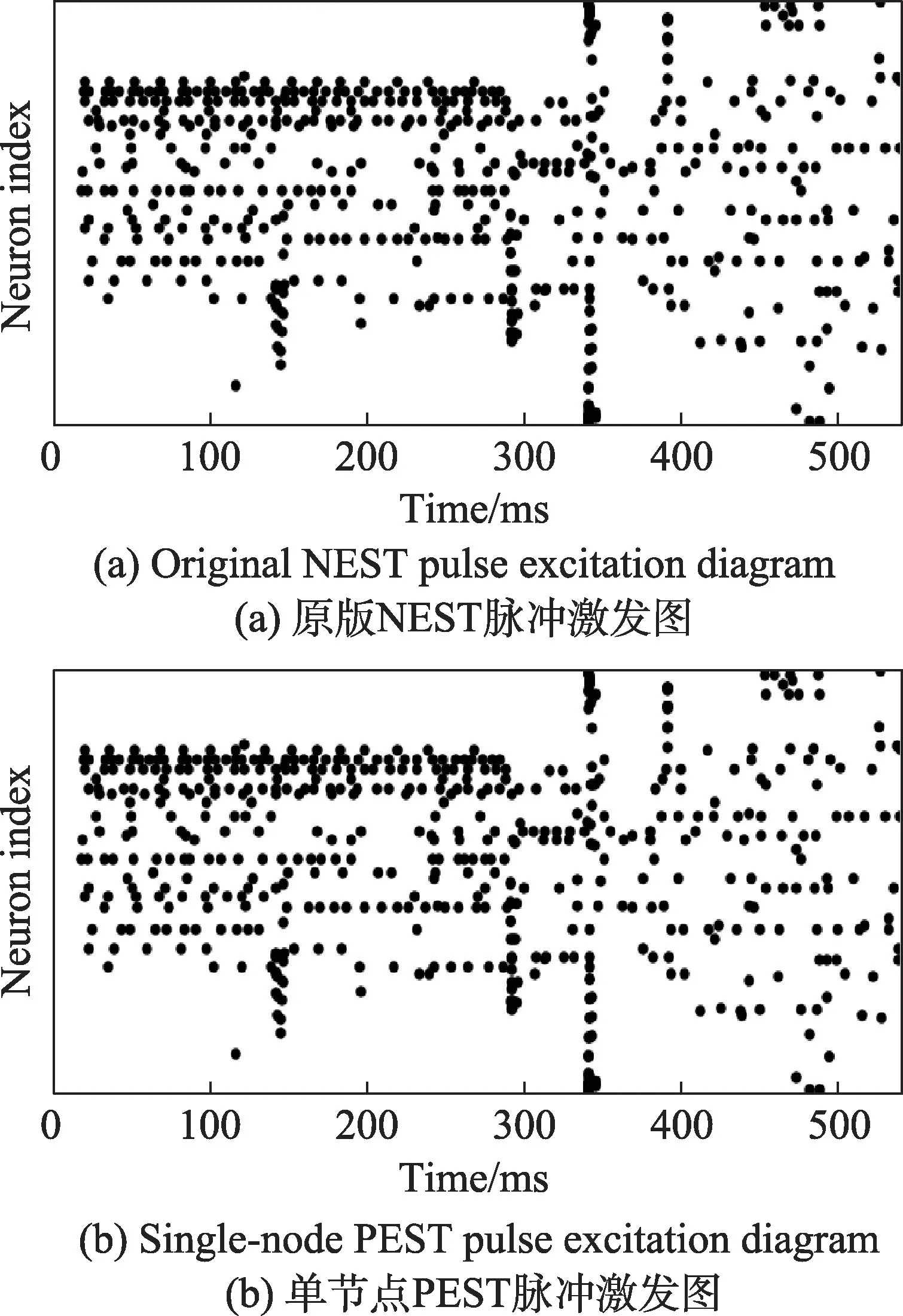
Fig.19 Contrast of cortical visual model results图19 皮质层视觉模型结果对比
图19 中横坐标代表运行时间,纵坐标为神经元序号,随着时间的推移,当某个神经元发射脉冲时会在图中相应位置打点。由于对比时采用完全一致的数据集和计算参数,神经元发射脉冲的时间应大致相同,对比两张脉冲激发图可以发现,单节点PEST与原版NEST 的脉冲激发图基本一致,结果正确。
在各平台运行皮质层视觉模型,使用100 张图片进行图片分类测试,查看最后的图片分类结果是否正确。如表1 所示,通过PC 运行单精度浮点与双精度浮点两个版本的NEST 进行对比,图片分类准确率基本一致。在单节点PEST 上运行半精度浮点和定点数混合的NEST版本图片分类准确率降低4个百分点。
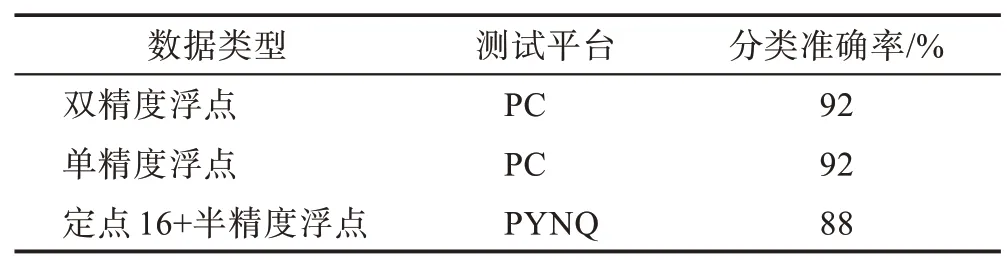
Table 1 Comparison of image classification test accuracy表1 图像分类测试准确率对比
皮层微电路模型测试时使用8 000 个神经元的模型规模进行测试,其运行结果以脉冲激发率的分布情况来表示。

Fig.20 Comparison of cortical microcircuit model results图20 皮层微电路模型结果对比
图20 为8 种不同皮层网络连接时的脉冲发射率分布图,其中深色矩形块为脉冲发射率的主要分布区间,红色竖线为脉冲发射率中位值,红色加号为离群点。对比原版NEST 与单节点PEST 的运行结果发现,脉冲发射率的主要分布区间和中位值结果完全一致,离群点的结果由于计算精度的影响在个别情况下稍有误差。
4.3 资源消耗
设计时,在保证资源开销允许的情况下,最大限度地利用了FPGA 片上资源,资源消耗如表2 所示。

Table 2 FPGA hardware resource utilization表2 FPGA 硬件资源利用率
由于IAF 神经元的计算大量消耗DSP,通过对数据位宽进行优化,如将浮点数转换成16 bit 点或半精度浮点,有效减少了DSP 的使用,在提高计算并行度的同时提高了整体资源的利用率。
4.4 PEST 集群最佳节点数评估
当把某个SNN 工作负载运行到PEST 上时,节点过多或过少都会影响系统的能效,因此需要对该工作负载分配最佳数量的计算节点。在对PEST 进行性能分析时运行皮质层视觉模型,图片选择128×128、200×200 和300×300 像素的不同数据集进行测试。首先对不同节点数的计算时间进行实际测试,实验结果如图21 所示。
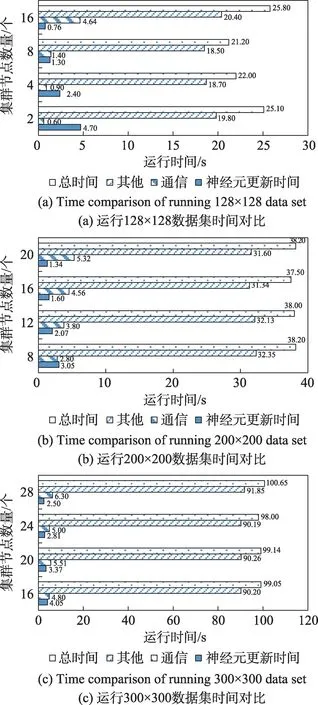
Fig.21 Running time comparison of cortical visual model under different number of nodes图21 皮质视觉模型在不同节点数运行时间对比
以128×128 数据集的运行结果为例进行分析,神经元更新计算时间随着节点数的增加成比例减少,通信时间随着节点数的增多而逐渐增大,其他时间包括仿真的准备和神经元更新后的结果收集,这些工作由于是集群的主节点独自进行处理,花费时间较长。同时由于这些步骤为主节点单独进行,当计算模型一致时,在不同节点规模下的处理时间差异不大。在运行128×128 数据集时,从2 节点开始计算性能依次增加,在8 节点时达到最佳性能,当超过8节点时其计算性能受制于通信时间的增长反而会出现下降。
运行其他两个数据集时由于图片像素增多,所生成的神经元数量也随之增多,计算时间随之增加。由于神经元计算规模增大,通信时间和神经元更新时间都相应增加,其分布特性与运行小数据集时类似,运行200×200 和300×300 数据集时,PEST 仿真器的最佳计算节点数分别为16 节点和24 节点。
在PEST 上运行8 000 和16 000 两种神经元规模的皮层微电路模型进行测试,测试结果如图22 所示。
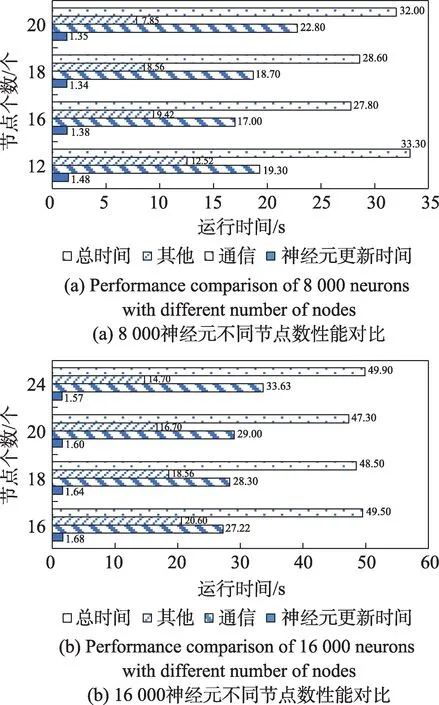
Fig.22 Running time comparison of cortical microcircuit model with different number of nodes图22 皮层微电路模型在不同节点数运行时间对比
皮层微电路模型整体神经元数量相对较少,因此不同节点数下神经元更新所占的计算时间差别较小。但由于整体计算次数很多,节点间的通信时间和其他时间受节点数量的影响很大。8 000 与16 000神经元规模分别在16 节点和20 节点时性能最佳。
目前已有研究自动地为工作负载分配合适的计算节点,限于篇幅在此不再展开介绍。
4.5 PEST 集群性能与能效评估
实验选择PEST 和其他的PC 平台进行对比,测试时使用不同的计算模型和规模进行测试,PEST 的节点数量选取了最佳数。由上文所述,在PEST 上运行计算模型时,数据准备和数据收集是由集群中主节点单独运行,受制于PYNQ-Z2ARM 端的性能,该部分处理时间过长,极大影响整体运行时间。数据准备工作只在模型初始化时运行,并且不受节点数量的影响,因此它可由性能更好的计算平台处理,集群主节点在运行时可将处理好的数据分发给各节点进行计算。数据收集与准备工作类似,主节点可以只负责收集各节点的计算结果,而将数据处理工作交给性能更强的计算平台进行处理。因此在进行性能与能效评估时,本实验只针对集群与其他平台神经元更新部分进行对比。表中PEST 括号中的数字为测试时的节点数量,各平台之间的性能对比如表3~表5所示。

Table 3 Performance comparison of cortical visual models of different platforms(128×128 data set)表3 不同平台皮质视觉模型性能对比(128×128数据集)
通过表3~表5 可知,PEST 的运算性能与功率随着计算节点的增多而线性增加,而Xeon 2620 和AMD 3600X 的运算性能和功率在运行皮质层视觉模型时基本维持不变。
在运行皮质层视觉模型128×128 数据集时,PEST 集群在8 节点时计算性能最佳,神经元更新时间相比3600X 提升16 倍,比Xeon 2620 快23.8 倍。在300×300 数据集下24 节点PEST 集群神经元更新时间相比3600X 提升44 倍,是Xeon 2620 的62.9 倍。整体计算量越大,PEST 在计算速度上的优势越明显。
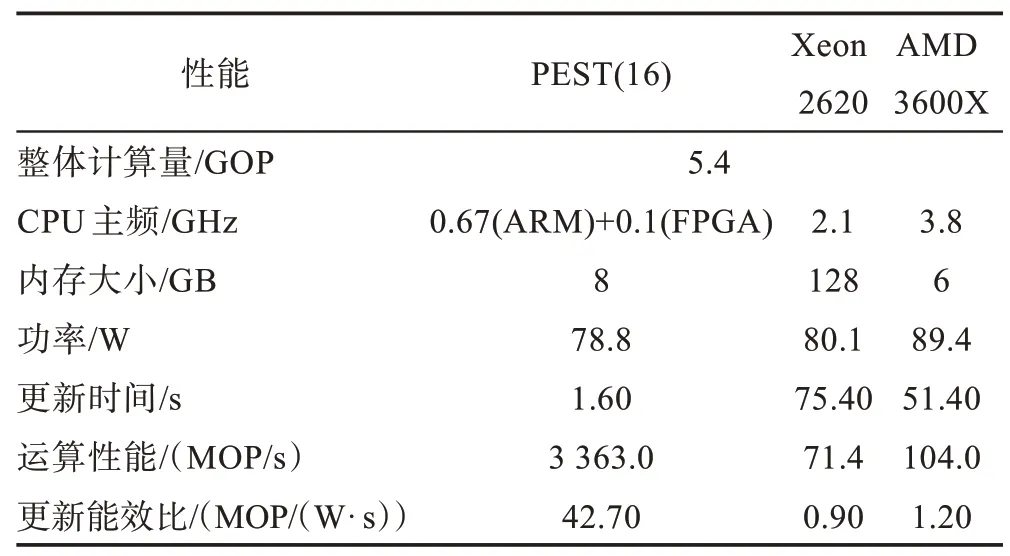
Table 4 Performance comparison of cortical visual models on different platforms(200×200 data set)表4 不同平台皮质视觉模型性能对比(200×200数据集)
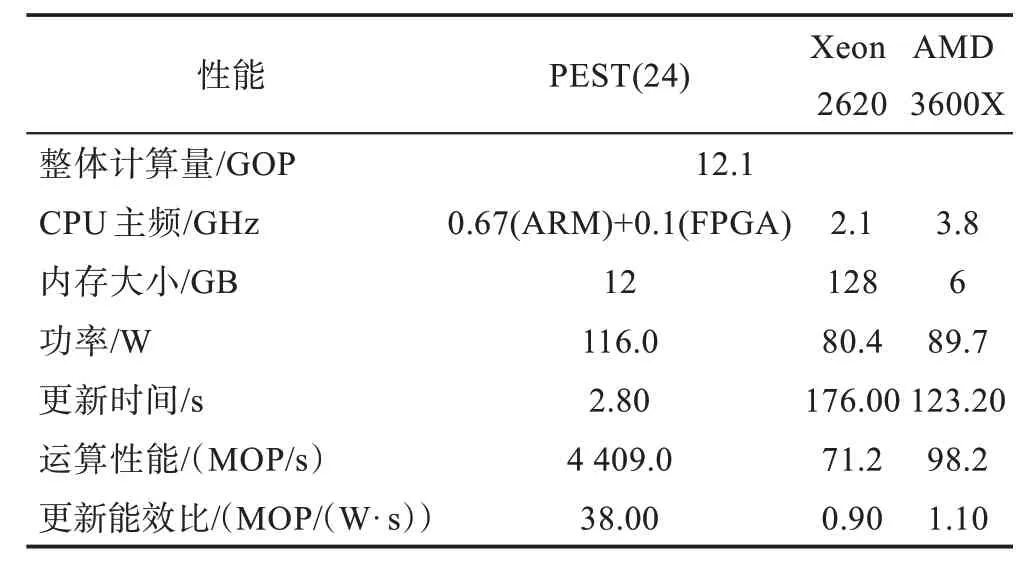
Table 5 Performance comparison of cortical visual models on different platforms(300×300 data set)表5 不同平台皮质视觉模型性能对比(300×300数据集)
PEST 在节点数较少时能效比较高,随着节点增多更新能效比逐渐下降,而Xeon 2620 和3600X 的更新能效比整体变化不大。运行128×128 数据集时,最佳性能的PEST(8)集群相比3600X 更新能效比提升36.9 倍,相比Xeon 2620 提升49 倍。在运行300×300数据集时,性能最优的PEST(24)更新能效比相比3600X 提升34.5 倍,相比Xeon 2620 提升42.2 倍。
如表6、表7 所示,运行皮层微电路模型时,PEST在神经元更新部分相比其他两个平台依然优势明显,在模型规模为8 000 神经元时,PEST 在16 节点时计算性能最佳,神经元更新时间相比3600X 提升4.6倍,比Xeon 2620 快7.5 倍。在16 000 神经元计算规模下20 节点PEST 的神经元更新时间相比3600X 提升14.3 倍,是Xeon 2620 的24.5 倍。神经元数量越大时,PEST 运行皮层微电路模型的性能优势越明显。
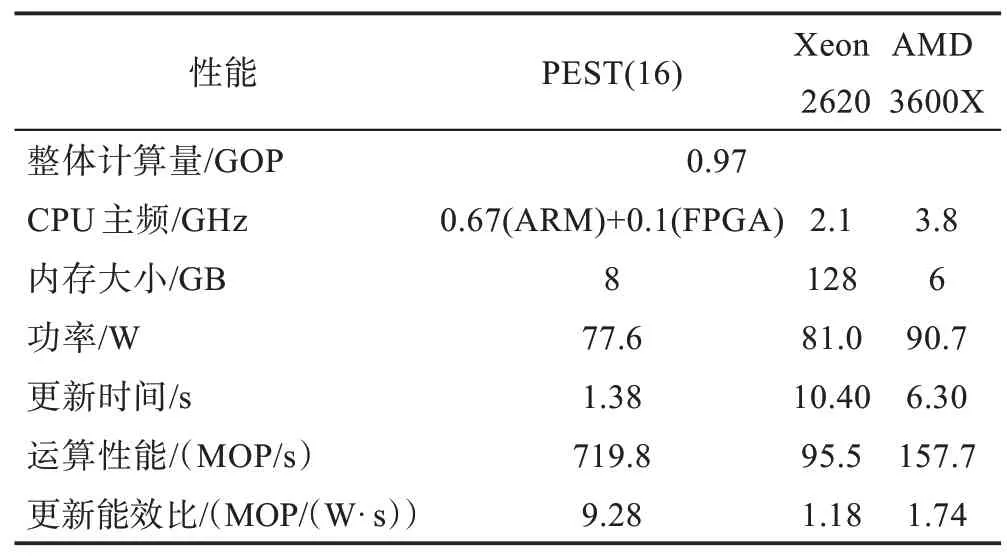
Table 6 Performance comparison of cortical microcircuit models on different platforms(8 000 neurons)表6 不同平台皮质微电路模型性能对比(8 000神经元)
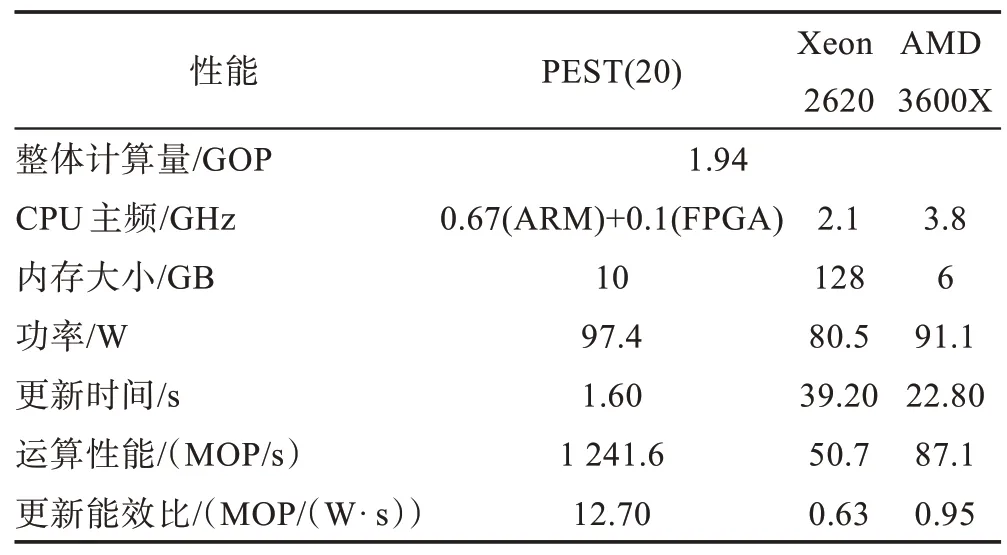
Table 7 Performance comparison of cortical microcircuit models on different platforms(16 000 neurons)表7 不同平台皮质微电路模型性能对比(16 000神经元)
更新能效比方面,PEST 相比其他两个平台依然具有优势,在8 000 神经元规模下,16 节点的PEST 更新 能效比相比3600X 提升5.3 倍,比Xeon 2620提升7.9 倍。在16 000 神经元规模下,PEST 的更新能效比相比3600X 提升13.4 倍,比Xeon 2620 提升20.2 倍。
通过4.4 节可知,PEST 在节点最佳数时的计算性能与运行在其他节点数时性能差距并不明显,用户可以根据需求选择适当的节点数进行模型计算,在损失一定计算速度的情况下使用更少的节点数进行计算可以在能效比方面达到更好的效果。
5 结束语
本文以PYNQ-Z2 开发板为基础,结合PYNQ 框架和NEST 类脑仿真器等软硬件设备,搭建了一套异构类脑计算系统。通过对集群中IAF 神经元更新部分进行优化,增加FPGA 并行计算模块,优化集群文件系统等方式,提升了整体计算性能,简化了操作复杂度,实现了高性能、低功耗、规模可伸缩的PEST 类脑计算集群,为类脑计算提供了一种新的计算平台。
后期工作可以从以下几方面进行研究:(1)继续针对不同神经元或突触类型设计FPGA 并行优化方案;(2)探索计算性能与功耗的最佳平衡点,设计自动确定性能最佳节点的方法;(3)优化仿真过程中的非主要性能瓶颈,进一步提升集群整体的计算性能。
