基于迭代加权图像的藏文古籍逐级分类仿真
2021-11-17沈淑涛高飞梁家瑞
沈淑涛,高飞,梁家瑞
(1. 西藏大学,信息科学技术学院,西藏 拉萨 850000;2.太原理工大学,软件学院,山西 榆次 030600 )
1 引言
我国的藏文古籍数量多,且内容丰富,是中华民族文化遗产的主要组成部分。但是藏文古籍涉及的种类复杂,在研究藏文古籍时,想要从中挑选出所需的古籍十分困难,国内学者一直在研究有效的解决方法。
文献[1]提出了通过学习向量量化算法对藏文古籍进行分类的方法。首先根据需要筛选出古籍因子,采用学习向量量化算法对因子进行分类,再使用列文夸特算法建造古籍模型对其分类。但该方法并没有将两种方法融合,导致出现分类不精准的问题。文献[2]提出了通过表示法对迭代加权图像的藏文古籍进行分类的方法,首先研究藏文古籍图像的信息分类方法,然后提取藏文古籍中有明显特点的图像信息,最后使用表示法表示出不同的藏文古籍迭代加权图像信息。但是该方法在提取明显特点的图像时,因没有筛选过程,导致提取出冗余图像,浪费了大量筛选时间。文献[3]提出先通过对藏文古籍进行调整,并进行归属判定,再通过统计操作对其判定结果进行统计。但该方法因藏文古籍的种类复杂,该方法只能针对其实验目进行判定,该方法不具有普适性。
针对上述问题本文提出了一种基于迭代加权图像的藏文古籍逐级分类方法,该方法能更精准的分类藏文古籍,且分类效率较高。
2 迭代加权算法
2.1 迭代模型
针对藏文古籍逐级分类问题,传统方法通常使用广义内积值的样本选取方法对藏文古籍进行逐级分类。但此类方法依赖协方差矩阵的分类准度。如果初始分类存在较大误差,便很难分类出有用的样本。且需要长时间对样本进行大量的协方差矩阵训练,但只能粗略地去除训练样本的合数,导致分类性能下降。
为了解决上述问题,本文采用基于迭代加权图像的藏文古籍逐级分类方法。为便于分析,假设环境由两种区域组成。
(1-α0)00+α001
(1)

在最少均方误差要求下计算式(2)最优权问题。

(2)
由传统方法知式(2)的最优质权为

(3)

通过式(3)能看出,最优权的分子只能与均匀样本相关,当样本总数到达一定数量时,最优权与不均衡出现反比。可能使不均匀程度达到最大化,不均匀程度的样本因不均匀程度达到最大化,导致其所加的权值出现最少量。
广义内积值与其本身的均值差距越大,则不均衡的效果越强,同时在样本总数目有限的状态中,其广义内积的均值即不是理论均值。
通过以上分析可知,本文所使用迭代加权方法中的统计均值与广义内积值中的方差对所有样本进行加权处理,消除相对不均衡样本在协方差矩阵里的比重,导致更改样本升高产生的逐级分类精准度下降,为了调整不均衡坏点对与广义内积的影响,应先利用构建的广义内积直方图对广义内积值进行评估。再考虑样本在总数量有限的情况下利用协方差矩阵会出现的差度。本文使用迭代模式对协方差矩阵的分类进行准度提高。方法的流程如图1所示。
下列为本文方法的操作流程:
1)设定起始协方差矩阵:利用传统方法的样本协方差矩阵计算起始协方差矩阵
(4)
式中M代表总数训练样本。
2)对广义内积值进行计算,再统计其几率分布情况:先使用获取的协方差矩阵算出全部样本单元的广义内积值zi

(5)
接着利用直方图来计算出广义内积值的几率分布状况P(zi),i=1,2,…,M。
3)权值计算:每一种样本的权重经过计算其广义内积值的误差以及广义内积值所得到的数据,其合理权值的重要点是获得的反应均衡数据广义内积值。
正常情况下,可理解训练样本内的均衡数据占据大部分位置,不均匀数据占比略小。因为均匀数据的广义内均值与不均衡数据之间的广义内积值相似度较高,包含较大差异,所以在对广义内积值的计算几率分布内,其均衡数据的几率要大于不均匀数据。
为了能够获取较为适当的广义内积值,避免受到不均衡样本的广义内积值对均值的影响,只使用样本几率较大的均值进行计算。

(6)
式中θ={i|P(zi)≥p},m代表集合θ中古籍的数量,p=μP(zi)代表设置的几率值,μP(zi)代表(zi)的均值。
每一种样本的权值为
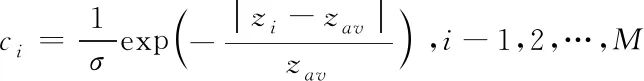
(7)

4)改进协方差矩阵:利用获取的权值对样本进行加权处理,即可得到分类的协方差j。
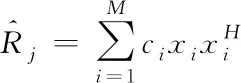
(8)
综上,本文使用迭代加权算法建立样本并对其进行迭代加权自适应,使后续的逐级分类更简单,提高了后续逐级分类的精准度和分类性能。
2.2 藏文古籍迭代加权图像信息特征提取
藏文古籍的章篇较短,所有藏文古籍会累积出大量的图像信息,图像信息会导致获得的向量空间维度较高。藏文古籍迭代加权信息特征提取的难度在于特征图像的选择和权值计算。藏文古籍的特征空间维度过大,会干扰逐级分类的精准度与效率,所以在进行分类时,需调低藏文古籍迭代加权图像信息的空间维度,挑选出可以为分类提供较大贡献的图像信息,从而进行特征提取。
对藏文古籍迭代加权图像进行特征提取时,需计算出藏文古籍图像的频率,计算公式如下所示
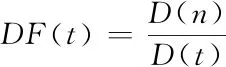
(9)
其中,D(n)表示藏文古籍迭代加权图像特征的问本数,D(t)代表藏文古籍的数量,DF代表藏文古籍迭代加权图像频率。DF代表经过计算藏文古籍的复杂度来测出藏文古籍文本信息特征,复杂程度越低,适用性越广泛。当复杂程度和藏文古籍总数呈线性关系时,集成速度快,有用信息少。当DF值升高时,有用信息越多。计算出藏文古籍迭代加权频率后,需对迭代加权图像信息与藏文古籍种类的相关性进行判断,判断公式如下所示。
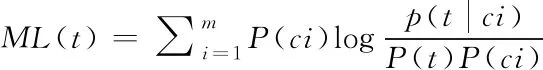
(10)
其中,ML代表藏文古籍类别和迭代加权图像信息的关联性,在特征选择时拟定计算特征词t与估计类比ci,从而判断特征和类别的相关联度。藏文古籍的某种类别ci出现的几率较高,相关性就越高,P(ci)代表第i类出现的几率,p(t|ci)代表特征词t与估计类别ci同时出现的几率。这种过程受边缘几率影响较大,可能会出现评估函数不选择高频而使用稀有,对后面的计算过程产生干扰。使用IG融入分类信息,融入的分类信息越多,该特征就越重要,IG融入分类用下列公式表示

(11)
式中,P(ki)代表包括特征信息的藏文古籍,P(ti)代表不包含特征信息的藏文古籍。IG相对高频特征图像信息的提取所含利成分越多,迭代加权特征图像的IG值越高,对逐级分类提供的贡献就越高。所以在对迭代图像信息进行特征选择时,通常提取IG值较高的特征图像提取特征信息,定制特征向量。反之对于没有特征信息的迭代加权图像无法计算IG值,提取信息的精准度较低。
2.3 藏文古籍迭代加权图像文本表示
藏文古籍迭代图像代表对图像文本进行形式化处理,使用计算机理解迭代加权图像信息文本,制造索引模型。当前使用较为广泛的模型有空间向量模型、自然图像模型与概率模型。通过大量实验证明,空间向量模型在表示迭代加权图像时更有效。空间向量模型可以把大量迭代加权图像表达为特征信息矩阵,把类似图像变换为特征向量相似度比较,逐级分类过程将更清晰。特征信息矩阵如表1所示
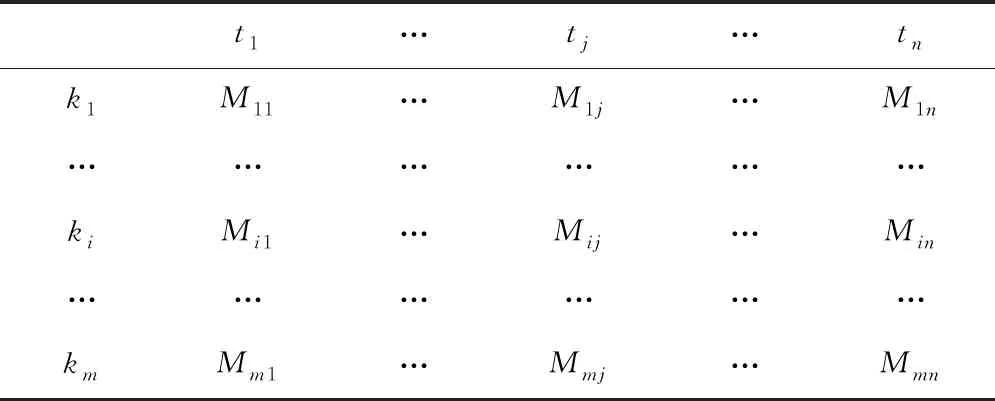
表1 特征信息矩阵
在特征矩阵中,t代表特征图像,k代表藏文古籍,n代表藏文古籍迭代加权图像的数量,m代表有待分类的藏文古籍,将所有古籍中的迭代加权图像表示为三维空间中的某个点,示例k(d)=((t1,k1),(tj,k1),(tm,k1)…(tn,km)),M代表向量的特征值,经过矩阵判断特征信息在藏文古籍内的重要性,计算出迭代加权图像和藏文古籍的相关性。经过对迭代加权图像赋予的概率值计算出其在藏文古籍中的贡献程度,从而对藏文古籍进行逐级分类。
3 实验结果分析
实验环境为Intel Celeron Tulatin1GHz CPU和384MBSD内存的硬件环境和MATLAB6.1的软件环境。本文实验中,为了评测本文方法的性能,使用文献[2]方法与本文方法进行较比。书籍样本总数是651,共分为4类,其中每种分类区域的藏文所占比列分别是60%,40%,30%,20%。
3.1 收敛性验证
为了更为简单的观察本文方法的收敛性能,给出输出收敛性的计算公式:
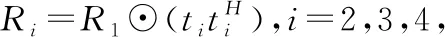
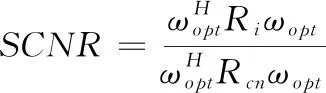
(12)
其中Rs代表目标古籍的协方差矩阵,Rcn代表迭代加权图像的协方差矩阵。设定输出SCNR权对SCNR最大值的差进行处理。

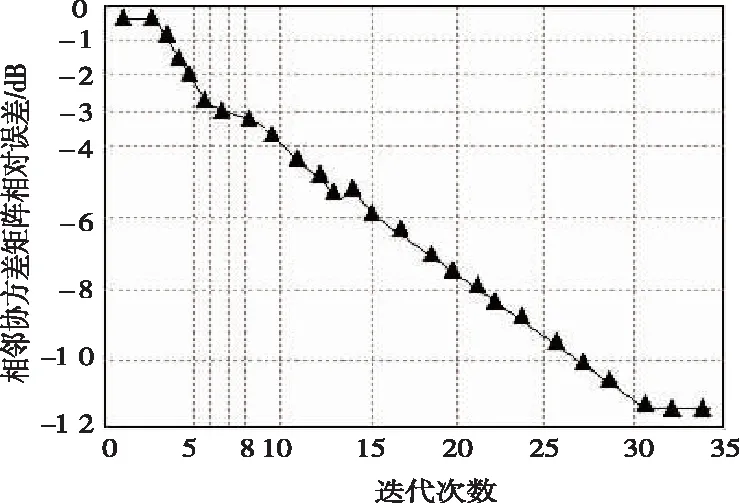
图2 迭代加权方法收敛曲线图
3.2 分类效果验证
图3是研究方法和传统方法的逐级分类结果对比图。分别对藏文古籍进行编码,1-353是第一区域,354-417是第二区域,418-545是第三区域,546-641是第四区域。图3(a)中显示的是传统方法的分类结果,虽然分类了所有古籍,但是第2区域与第3区域的权值显然大于第1区域。所以,传统方法并不会有效的对藏文古籍进行逐级分类,而图3(b)为研究方法的分类结果图,图中第2区域的权值显然要小于第1权值,第4区域和第3区域的权值则明显小于第1区域,就是不均匀程度越高加权值就越小,这证明本文方法可以有效的逐级分类藏文古籍。
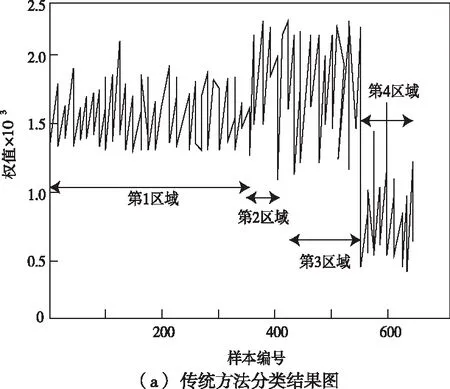
图3 不同方法分类藏文古籍结果图
通过上述实验能够看出,通过本文方法逐级分类的迭代加权图像藏文古籍,能够清楚看的到各阶级的分类阶梯,而使用传统方法分类出的藏文古籍,区域较为杂乱并且分类并不完整。
3.3 检索效果验证
为进一步验证研究方法的应用有效性,将该方法运用到实际藏文古籍检索中。该方法可对古籍题名、作者、语种、类别及收藏情况进行筛选检索,检索界面如图4所示。
图4 藏文古籍检索界面
以检索藏文著作《藏历时论学智者生悦论》为例,运用迭代加权图像的藏文古籍逐级分类方法进行检索。结果表明该方法能快速有效地进行分类检索,且分类层级明晰,说明对藏文古籍检索是有帮助的。检索结果如图5所示。

图5 检索结果
3.4 分类时间对比
为了进一步验证研究方法分类藏文古籍的有效性,利用传统方法与研究方法对逐渐增加的1600份藏文古籍样本进行分类,对比两种方法的分类时长。具体实验结果如图6所示。
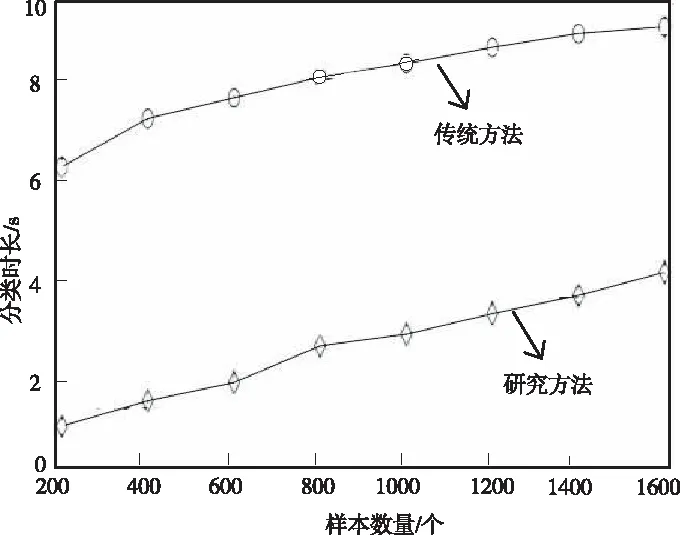
图6 不同方法分类藏文古籍时长结果图
通过上述实验能够看出,两种方法的分类时长随着藏文古籍样本增多而增加。在样本数量个数为200个~1600个区间内,传统方法的分类时长约为6~10s,而研究方法的分类时长约为1~4s,远远小于传统方法的分类时间。说明本文基于迭代加权图像的藏文古籍逐级分类方法能对藏文古籍进行高效分类,具有一定的科研意义。
4 结论
针对藏文古籍分类中存在的分类不完整和分类效率低的问题,本文提出了一种基于迭代加权图像的藏文古籍逐级分类方法。该方法首先使用迭代加权算法,基于藏文古籍构建出迭代加权模型,从而使其自适应处理需要大量训练样协方差矩阵,然后通过训练出协方差矩阵和广义内积进行融合,之后对迭代加权图像进行计算,从而改进后续分类时出现的分类准度下降问题,最后通过对藏文古籍迭代加权图像进行信息特征提取,来达到逐级分类的目的,实验证明本文方法,能够完整的对藏文古籍进行逐级分类,并且分类的速度较为迅速。
