基于半监督深度学习法的网络大数据集成挖掘
2021-11-17纪冲,刘岩
纪 冲,刘 岩
(内蒙古农业大学计算机与信息工程学院,内蒙古 呼和浩特 010018)
1 引言
大数据挖掘是将数据作为组成知识的主体,从大量随机的数据里,挖掘出潜藏在数据库内人们不知道的有用知识[1]。互联网技术的高速发展、网络资源使用率的不断提升使得各行各业对大数据挖掘的重视程度也越来越大,特别是在一些特殊网络环境下,由于大数据各类特征参数较多,则数据挖掘前需要对各类数据进行集成处理[2-3]。
数据挖掘是一种比较广义的交叉学科,数据集成最为常见的方法是模式集成方法,这种方法是一种非常经典的集成算法,中间件算法是模式集成算法里比较经典的,该算法会将所有独立的数据源,根据Wrapper进行转换同时封装,这些数据的存储位置不会出现变动,利用Mediator对所有封装之后的数据源进行视图统一,Mediator会把浏览的历史请求变换成局部数据源模式的搜索,利用Wrapper进行结果提取,同时使用Mediator对数据集成,之后撤回至其它中间件或用户中。Mediator主要提供全局优化查询处理,不会提供实际的数据储存[4]。由此可见传统的数据集成挖掘方法,都存在较为一致的缺陷,即数据集成与数据挖掘之间存在检测或分类的误差,这种误差严重的会致使在结束挖掘之后,出现乱码,数据显示不全的问题。
针对上述问题,提出基于半监督深度学习法的网络大数据集成挖掘。该方法会通过半监督深度学习算法来检测并分类大数据种类和特性,为后续挖掘提供较好的网络环境,通过网格服务对大数据集成,使各不相同的数据能够处于同一坐标处,使用关联度挖掘算法对数据高精度集成挖掘。
2 大数据集成挖掘
2.1 网络大数据的集成挖掘条件
在网络环境下,为减少数据库的运行内存,提升挖掘方法的稳定性,利用大数据集成挖掘方法组建应对不同网络环境下大数据的矩阵转换[5-6]。
拟定Dj代表网络环境下数据库内大数据中第j行的单排矩阵,dji代表第i列、第j行的大数据,同时i=1,2,3,…,m。假如矩阵内所有行中一共包含m种大数据,那么Dj为
Dj=(dj1,dj2,dj3,…,djm)
(1)
假如大数据总量中存在n种,通过T来描述矩阵的转置转换[7-8],那么网络环境下,数据库内大数据的总矩阵D为
D=(D1,D2,D3,…,Dn)T
(2)
对总矩阵D里集合X的大数据x进行挖掘,拟定其单属性的关联度是sim(X,Y),其中,Y代表和X对应的集合,通过y来描述Y内的大数据,挖掘出的样本通过s来进行描述,那么s就需要符合如下条件的所有需求
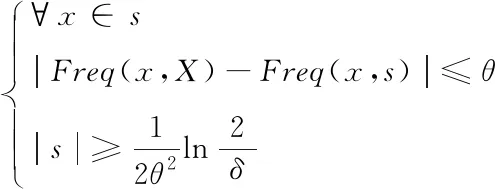
(3)
其中,Freq代表条件出现的次数,θ表示所允许的最大误差挖掘,δ代表该误差出现的概率。
2.2 基于半监督深度学习的大数据集成
典型的机器深度学习通常会分成无监督学习与有监督学习。有监督学习是利用训练标记的样本,对没有标记的样本预测,而无监督学习是根据训练无标记样本,查找无标记样本之间存在的内部特征来进行预测。半监督深度学习是对上述两种深度学习之间的机器深度学习进行融合,能够同时对标记样本和无标记样本进行训练[9]。
在实际使用中,有标记的样本总量较为稀少,因其需要通过手动来进行标记所以耗费较大,因此少量存在标记的样本尤其珍贵,而样本里未标记的样本总量有很多。本文的数据挖掘首先会通过构建数据检测模型来识别网络中大数据属性,但由于正常样本多于有标记样本总量,因此首先把未标记样本都设定为正常样本,根据无监督学习[10]训练单分类数据检测模型,之后按照有标记的样本,校正单分类数据检测模型,从而达到增量学习的目的。
本文充分利用现存的少量有标记样本与大量无标记的样本数据,采用半监督学习,利用先验单分类检测数据模型信息和新的标记样本更新模型对样本数据进行处理,一方面能够使训练之后的样本继承先前学习到的知识,还可以让整体学习存在可积累性,另外一方面也可以实现在线学习,不断的让数据检测模型获得更新。典型的数据检测模型是[11]无监督深度学习,其将数据对象拟定成一种整体,组建一种封闭且紧凑的超球体,使需要描述的数据对象尽可能或全部地处于这种球体里。
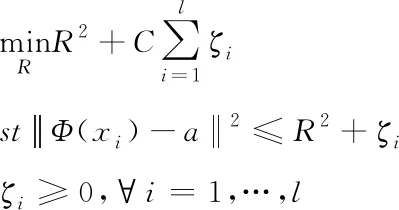
(4)
式中,R代表待求解的球的最小半径,C为惩罚系数,ζi为惩罚项,a为超球体的中心。
在训练结束之后,需要对新的数据点Z评定是否属于这个类,就是
(z-a)T(z-a)≤R2
(5)
至此利用单分类数据检测模型训练了未标记样本,针对数据样本可以使用该模型进行评定。但是未标记样本里存在少量的[12]冗余数据样本,直接根据单分类数据检测模型有可能会产生一些微小的误差,因此本文结合了少量的标记样本组成了半监督深度学习数据检测模型。
1)对含有标记的样本分词处理,根据数据检测模型对样本标记之间存在的关联性与特征词进行分析,条件前K种关键特征词当作筛选特征词;
2)针对未标记样本,利用(1)得到筛选特征词对应的未标记样本特征;
3)针对(2)获得的未标记样本特征,根据深度学习的网络训练取得未标记样本的文本向量。
4)利用文本向量,利用半监督深度学习方法对单分类SVDD模型进行训练,将超球体的半径缩短到最小化;
5)对于新的标记样本,利用在线学习的方式训练向量学习SVDD模型,同时对单分类模型进行校正,提高模型的识别效果。通过该模型来检测大数据内的信息资源。
2.3 大数据集成挖掘的实现
为提升所提挖掘算法的精准性与实用性,需要实现约束大数据特征关联度,约束的内容需要根据网络数据库确认挖掘条件,约束内容需要包含确保挖掘工作计算量小、挖掘质量高的作用。
通过confidence(X⟹Y)来描述特征集合X内涵盖特征集合Y的概率,confidence(Y⟹X)和上述相反,大数据特征关联度sim(X,Y)的挖掘结果为
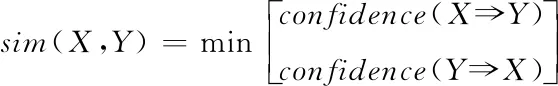
(6)
由于confidence(X⟹Y)与confidence(Y⟹X)的取值范围是[0,1],所以,大数据特征关联度sim(X,Y)的取值范围也应该是[0,1]。在sim(X,Y)=0时,即网络大数据间的特征是互相独立的,此时不需要进行大数据集成挖掘聚类。
网络数据位置的关联度挖掘结果,能够利用计算大数据传输信道的质心得到,把大数据集合X与Y传输信道的质心拟定成c1与c2,两种质心之间的距离是|c1c2|,下面通过图1来对大数据位置关联度的挖掘原理进行描述。

图1 大数据位置关联度挖掘原理
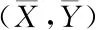
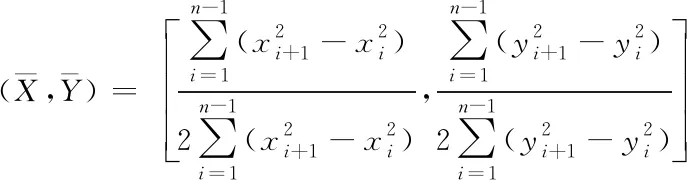
(7)
网络大数据方向关联度即指大数据集合X与Y传输方向之间的角度(s1,s2),其余弦值能够通过公式描述成

(8)
通过上式能够看出,大数据集合X与Y传输方向之间存在的角度(s1,s2),如果角度cos(s1,s2)越大,(s1,s2)值就会越小。在(s1,s2)超过180度之后,cos(s1,s2)值就会变成负数。为了免除大数据位置关联度挖掘结果,对大数据方向关联度挖掘结果造成的干扰,所提网络大数据集成挖掘方法利用[1-cos(s1,s2)]的正弦值来描述方法,取代传统[1-cos2(s1,s2)]的正弦值描述方法,使大数据方向关联度被精确的挖掘出来。
基于上述方法,把大数据方向关联度的挖掘结果拟定成sim(dist),对大数据结合X与Y传输方向的平均值avg(|s1|,|s2|),进行加成计算,就会出现:
sim(dist)=avg(|s1|,|s2|)[1-cos(s1,s2)]
(9)
把上述式(6)、(7)与(8)根据式(4)给出的挖掘样本s条件进行聚类,确保最后的网络大数据集成挖掘结果。通过F来表述挖掘样本s的挖掘效率,那么,Fs就能够表示成大数据挖掘聚类,即本文方法的集成挖掘结果为
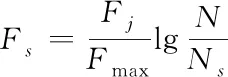
(10)
式中,Fj为大数据的特征、位置与方向同时出现的概率,Fmax为大数据特征、位置与方向关联度内的最大值,N为未进行挖掘工作前的大数据样本总量,Ns为挖掘出的数据特征、位置与方向的总量。
根据以上步骤,利用有监督与无监督深度学习间的机器学习,组成半监督深度学习训练标记样本,利用支持向量数据组建超球体。利用超球体结合标记样本,组建半监督深度学习数据检测模型,采用深度学习检测大数据,以此为基础筛选样本特征词,利用半监督深度学习方法训练单分类SVDD模型,实现检测大数据内的信息资源,获取网络大数据集成挖掘结果。
3 实验结果与分析
为验证所提方法的应用有效性,设计一次仿真。仿真环境为Intel Celeron Tulatin1GHz CPU和384MB SD内存的硬件环境和MATLAB6.1的软件环境。
3.1 不同方法的大数据集成挖掘精度对比
为进一步验证所提方法的实用性,将文献[1]提出的基于事务映射区间求交的网络大数据集成挖掘方法、文献[2]提出的基于数值信息抽取的网络大数据集成挖掘方法以及文献[3]提出的基于差分隐私的网络大数据集成挖掘方法作为本次实验的对照组,不同方法的集成精度对比见表1。
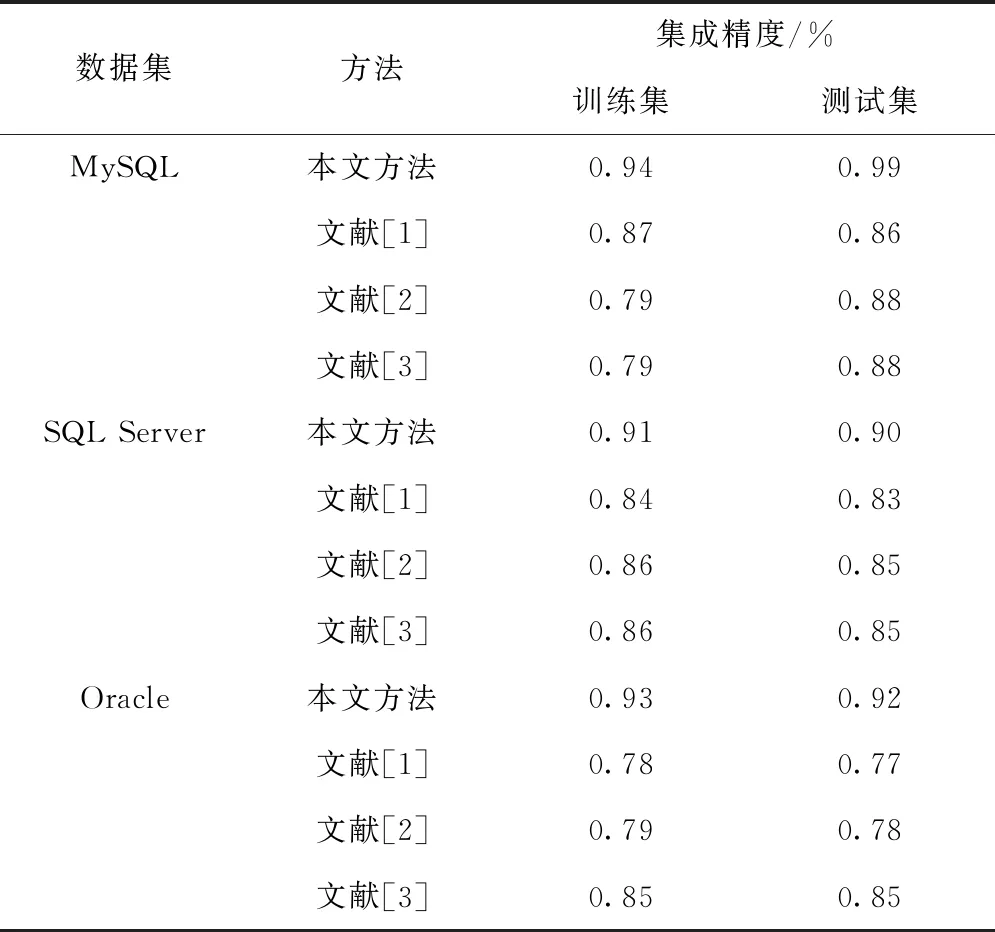
表1 不同数据集中三种方法的大数据集成精度对比
从表1所统计出的数据可知,本文方法与文献方法相比集成挖掘结果精度更高,且所提方法在大数据集成挖掘过程中应用的稳定性较高。
3.2 不同方法的大数据集成挖掘耗时对比
为进一步验证所提方法的性能优势,设计本节实验。以大数据集成挖掘耗时为指标,不同方法的大数据的集成挖掘耗时对比测试结果如图2。

图2 不同方法的耗时对比测试
从图2实验结果中可以看出,三种传统方法随着待挖掘大数据量的增多,其耗时不断增加,当大数据量达到60TB时,其耗时最高为6.5ms。相比之下,所提方法的耗时明显低于三种传统方法,在大数据量为10TB时,耗时为2.3ms。当大数据不断增多时,该方法的集成挖掘时间明显降低,且耗时水平较为稳定。大数据达到最大值60TB时,其耗时仍然在2ms上下。本次实验数据表明所提方法具有较为理想的应用性能,符合目前该领域的实际应用要求。
4 结束语
为集成挖掘不同格式、来源、特点性质的大数据,本文提出一种基于半监督深度学习法的网络大数据的集成挖掘方法。通过半监督深度学习算法对大数据实现集成挖掘。通过仿真验证了所提方法具有较高的大数据集成挖掘精度与效率。但随着网络数据规模不断扩大、计算量高速增加,易出现数据查询工作超负荷运转问题,因此在现有方法的基础上,对负载优化模型为日后进一步需要研究的课题。
