基于大数据技术的气象业务监视数据采集处理
2021-11-17张来恩陈文琴
曾 乐,孙 超,张来恩,陈文琴
(国家气象信息中心,北京100081)
1 引言
气象综合业务监视数据是能反映全国气象业务实时运行状态的各种数据的集合[1-2]。为实现“全流程、全业务、一体化”的综合业务监视目标,与一般的信息系统监视数据相比,气象综合业务监视数据涵盖的内容更广泛,包含很多业务运行的细节数据,数据量非常大,处理逻辑较为复杂,时效性要求高。
气象综合业务监视数据可分为资源类监视数据和业务类监视数据。其中资源类监视数据是从信息系统层面体现气象业务软硬件资源可用性,包括主机、存储、网络、安全、动力环境等基础设施以及数据库、消息中间件等通用系统软件、气象业务应用进程运行状态数据;而业务类监视数据是从业务层面体现气象业务运行状态的监视数据,在这类监视数据中,一般包含具有气象业务涵义的数据内容,如收集的观测资料到报率、可用率等[3],与气象业务流程和业务逻辑息息相关,能反映业务可用性等情况。
根据监视数据的形态,气象综合业务监视数据可细分为资源性能指标类数据、原始业务日志数据、业务指标类数据、告警事件类数据等。
1)资源性能指标类数据是以指标数值来反映资源的运行能力状态的数据,如存储可用率、网络流量等。
2)原始业务日志数据是业务各环节产生的日志数据,是主要的业务监视数据来源,其中最核心的是气象行业内各种观探测资料从采集、传输、预处理、存储到产品加工、服务应用的气象资料全生命周期各环节的运行状态日志数据。除此之外,还包括各个气象业务系统生成的业务日志数据,如定时任务的执行情况、用户对具体业务服务的访问日志等。目前行业内对关键的原始业务日志数据的内容和格式提出了规范性要求,以便于数据的处理和管理。
3)业务指标类数据是原始业务日志经处理、统计等计算逻辑生成的能精细化反映业务运行的状态和可用性的指标数据,如地面逐小时观测资料的到报完整率、及时率、可用率等。这些业务指标数据,不仅能监视保障业务的正常稳定运行,还能提供业务管理决策支持。
4)告警事件类数据是基于前三者数据,经过阈值和状态判断等计算分析发现的异常告警事件数据,包括告警事件的来源、种类、异常详细情况等内容,生成的告警类数据还需要进行进一步的告警规则处理及业务关联分析。
目前,每小时采集和处理的气象综合业务监视数据已达到1亿条以上,要实现对海量监视数据的高效采集和处理分析,本文提出了基于大数据技术的监视数据采集和处理框架,能实现对海量原始监视数据的高效采集、实时处理分析,系统框架同时具备稳定性、容错性和可扩展性等特征。
2 系统框架设计
系统框架分为三层,包括原始监视数据采集层、缓冲层、处理层。处理后的资源性能指标类数据、原始业务日志数据、业务指标类数据、告警事件类数据等将存储在不同的数据库中,如图1。

图1 系统框架
1)采集层。实现气象综合业务监视原始日志的高效接入,并对接入数据进行清洗,保证后端指标计算环节数据的准确性。采用REST接口及Flume日志收集系统两种方式实现监视数据采集。
2)缓冲层。对采集的监视数据进行缓存,实现监视数据采集与处理环节的松耦合,为处理环节提供有效数据源。采用Kafka消息队列实现对监视日志数据和指标数据的缓存。
3)处理层。根据气象综合业务监视需求,对原始监视数据进行预处理、指标计算并生成告警事件。采用Spark Streaming实时流数据处理框架实现高并发的监视数据处理。
对监视信息采集和处理之后,根据不同特点的监视数据类型,针对日志类、指标类、告警类监视数据分别设计了不同的存储模型:业务日志数据存储在基于索引技术的Elasticsearch数据库[4],方便日志详情查询;资源性能指标和业务指标类数据采用时序值方式存储在Cassandra数据库[5];告警事件类数据存储在MongoDB数据库,热点数据存储在Redis内存数据库。由于存储的设计不是本文重点,故存储模型设计不在此详述。
3 监视信息采集设计
气象综合业务监视数据的采集主要通过“拉取”和“推送”两种方式,拉取方式主要通过Flume技术,部署采集Agent到客户端,采集监视数据;推送方式主要由业务系统在运行过程中,主动调用REST接口实时推送监视数据。不同类型监视数据的采集方式和技术见表1。

表1 监视信息采集方式
3.1 REST接口采集
REST接口采集通过调用REST(Representational StateTransfer,表述性状态转移)接口[6]实现客户端通过HTTP层向服务器端推送监视数据。在气象业务系统中,实时收集、解析、处理生成监视所需的运行状态信息,并通过调用REST接口,实时发送监视数据,其发送的RESTful接口,以国家级地面自动站收集日志采集为例,数据格式如下:
{
"type":"RT.CTS.STATION.DI",
"system":"CTS",
"message":"国内气象通信系统",
"occur_time":1518256800000,
"receive_time":1518256922000,
"fields":{
"FILE_NAME_N":"Z_SURF_C_BESZ_20180210100000_O_AWS_FTM_PQC.BIN",
"LENGTH":1286,
"IIiii":"54511",
"STATION_NAME":"北京南郊站",
"DATA_TYPE":"A.0001.0044.R001",
"PROCESS_LINK":"2",
"DATA_TIME":"2018-02-10 10:00"
"PROCESS_TIME":"2018-02-10 10:01:10.000",
"TRAN_TIME":"2018-02-10 10:01:15.000"
}
}
收集日志包含“台站编号”、“资料类型”、“资料时次”、“业务环节”等内容,其中台站编号、资料类型、资料时次用于计算数据到报情况,其它信息用于日志详情查询。
3.2 Flume采集
Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,本系统采用Flume-ng,其核心是Agent,主要由source、channel、sink三个组件组成[7-8]。
Flume采集框架,包括采集层和汇聚层。采集层Agent负责采集气象业务系统的运行日志,并进行格式转换及封装,汇聚层Agent负责汇聚所有业务系统的监视数据。汇聚层相当于业务总线的作用,起到隔离、缓冲的作用,如图2。

图2 Flume采集框架
1)隔离。屏蔽采集层单个Agent调整,而不影响其它监视数据采集。Agent调整包括客户端IP变动,业务日志格式变化等。
2)缓冲。缓存采集层传输过来的数据到File Channel,一方面可以保证采集层采集Agent的不间断执行,另一方面可减缓大量监视数据传输的峰值压力,并保证服务端监视数据收集处理程序异常时,不丢失采集到的业务监视数据。
另外,在Agent设计中,主要有以下关键点:
1)双Channel设计。当堆积在Channel中的Events数小于阈值时,所有的Events被保存在MemoryChannel中,Sink从MemoryChannel中读取数据;当堆积在Channel中的Events数大于阈值时,多余的部分自动存放在FileChannel中,Sink从FileChannel中读取数据。双Channel可以充分使用MemoryChannel的高吞吐特性保证数据处理时效性,同时,利用FileChannel的缓存特性保证数据完整性。
2)故障切换设计。在采集层Agent,Failover Sink Processor维护一个由3个Sink组成的优先级Sink组件列表,只要有一个Sink组件接收或发送Event不可用,Event就被自动切换到下一个组件。
3)负载均衡设计。在汇聚层Agent,使用负载均衡机制LoadBalance。部署2个Agent,均衡处理采集层Agent发送的监控数据,在每个Agent中,设计4个Sink,可以实现处理的高并发。采集数据转换复杂的环节通过增加Sink组件提高Agent的吞吐量。
4 监视信息处理设计
4.1 监视数据预处理
监视数据预处理主要针对气象原始业务日志数据,资源性能指标类监视数据比较规整,不需要进行预处理。气象原始业务日志数据包括14大类498个子类的气象观测资料及产品从台站到省级、国家级的收集、分发、处理、存储、归档、服务的全业务流程运行信息[9]。原始业务日志数据存在信息不完整、数据重复等问题,需要在监视指标计算前对数据进行标准化构建和数据清洗。
4.1.1 数据标准化构建
数据标准化构建包括数据合法性检查、时间标准化处理、业务信息关联和日志信息丰富等,处理流程如图3。
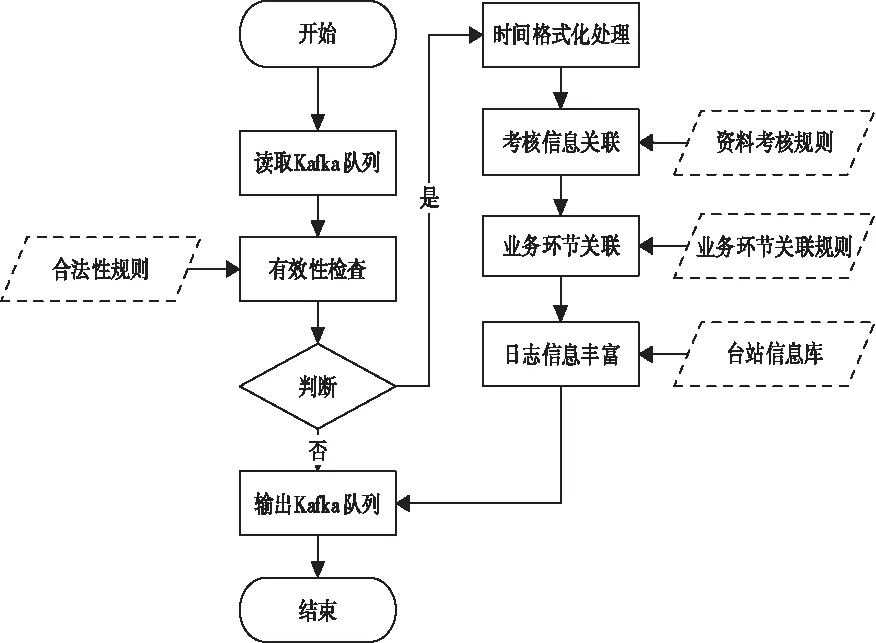
图3 数据标准化构建处理流程
1)数据合法性检查。根据业务特征和资料特征等合法性规则检查监视数据是否有效,无效数据存入Kafka错误数据队列,入库备查。
2)时间格式化处理。统一各业务环节监视数据的时间格式,所有时间统一为世界时,并精确到毫秒。
3)业务信息关联。关联业务配置信息,例如,某一种气象资料是否业务考核、具体考核的比例、阈值、及时时间等是该资料的业务配置信息,则在此步骤中将通过关联业务配置信息来判断该气象观测资料是否业务考核资料,如果是业务考核,则获取相关的考核信息。
4)日志信息丰富。根据原始业务日志中的台站编号,从台站信息库中补充台站所在的国家、区域/省、市、地县等信息。
4.1.2 数据去重
为保证业务质量,气象资料在各业务环节存在数据订正、数据传输续传等现象,导致原始业务日志数据也存在重复问题。为保证后续监视指标计算的准确性,预处理过程需要对数据进行清洗去重操作,避免因重复计算造成误差。
去重过程针对每一条原始业务日志,提取“资料类型”、“资料时次”、“业务环节”、“台站号/文件”等要素作为唯一标识,根据唯一标识中的信息,计算其MD5值存入Redis缓存,后接入数据时检查MD5值是否出现,若是则打上重复标记。根据气象资料业务时次周期处理的特点,在Redis中缓存4个数据周期,能够覆盖大部分数据,对于少数超过4个周期的延迟数据,系统采用离线计算方法纠正。
首先对资料类型、资料时次、资料台站和业务环节全排列编码,计算方法如式(1)。
编码值i=MD5(typei×timei×stationi×processi)
(1)
其中:type为资料小类编号;time为业务时次编号;station为台站号;process为业务环节编号。
以500种资料小类,20种不同业务时次,10万个台站,10个处理环节为平均数估算最大占位数,如式(2)。
500×20×105×10=1010
(2)
在Redis中设置1010的Bitmap,占用内存1010÷8=1.25×109字节,约为1.16GB。将每条资料日志记录的编码值i存入Redis中缓存,后续的日志记录均与Redis缓存的编码值进行比较,如果相同,则打上重复标记。
4.2 监视指标计算
原始业务日志数据预处理后经过指标计算处理,生成能精细化反映业务运行的状态和可用性的指标数据,如完整率、到报率、及时率等。监视指标计算环节采用Spark Streaming实时处理框架,对实时数据流进行统计计算。
为实现监视指标的实时更新,指标计算以15秒为窗口从上游获取日志数据,统计分钟、小时、日尺度的业务监视指标,以及全国和分省指标,并存入指标库。
4.2.1 业务指标计算
气象业务系统对于考核数据每天会生成应收数据清单(节目表),包含数据类型、应收站号、应到时次、环节标识等信息,当有数据到达某个环节时该环节会形成数据达到日志提交综合业务监视,通过与节目表的算法匹配计算出业务指标,具体流程如下,以区域站数据小时到报率计算为例:
1)通过采集层获取每日节目表,解析后将类型、站号、时次等信息写入存储层中。
2)从实时数据队列中每15秒获取一次日志数据,通过数据类型和环节标识区分出区域站数据,并从存储层中获取区域站数据的节目表信息。
3)将收集环节的区域站日志中的站号、时次信息与进行匹配节目表,计算15秒内日志中区域站数据的收集情况。
4)从存储层中获取区域站到报指标,根据步骤3)中的计算结果进行累积汇总,计算出实时指标回写至存储层,供综合业务监视前端展示调用。如图4所示。
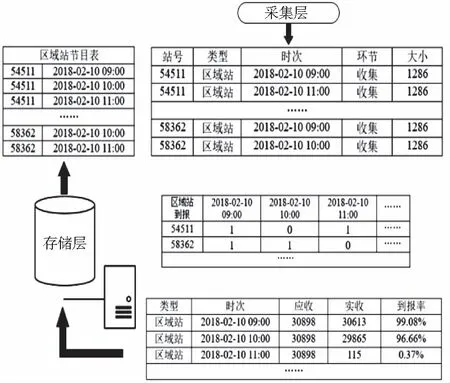
图4 业务指标计算流程
每次计算当前时次、前两个时次和后一个时次的到报情况,既能保证数据计算时效性,前端能取到实时的到报情况,又能保证计算资源的合理利用。由于气象业务数据存在延迟到达的现象,指标计算每天定时从存储层中将近三天的数据取出进行一次指标重算,保证指标库中非实时数据的正确性。
4.2.2 计算任务容错处理
由于指标计算时偶尔会出现计算失败导致最终指标计算结果存在误差,系统设计了数据处理容错机制。采用批序号的增量计算方式,通过Redis缓存记录当前处理的批号,在指标累计过程中比较最近的有效计算结果实现增量累计,只有在所有数据执行计算完成之后才提交Kafka进行消费量偏移,若是计算失败则纳入下一批次重新计算。数据处理容错流程如图5。

图5 指标计算容错处理流程
4.3 告警事件生成
根据业务规则,对监视指标进行判断和分析将生成告警事件,告警事件包括来源、种类、异常详细情况等内容。由于气象综合业务监视数据包括业务全流程环节监视指标、以及支撑每个业务环节的基础设施资源运行状态信息,一个环节出现告警,将导致后续业务流程均产生告警,而大批量的告警将影响运维人员对关键告警的判断。
减少告警数量、分析告警源头,生成面向运维人员的告警事件,将提高故障处理效率。告警归因分析需要比较复杂的分析处理过程,还需关联业务配置信息进行综合判断。本系统主要实现了以下基础的告警处理:
1)告警归并。对同一种资料、同一个业务时次、不同业务环节的告警事件进行归并,只保留最前业务环节的告警事件。告警归并方式包括有根据同一告警源头进行归并处理,根据同一时间窗口内的相似告警的归并处理等,根据不同的业务需求采用不同的归并处理算法,并对算法进行优化处理。
2)告警压缩。设置压缩规则,将同一种告警源头、同一个业务时次、同一业务环节超时未处理的重复告警事件设置压缩标识,对重复事件进行压缩,并标识该告警事件对应的第一次和最后一次发生时间,压缩所采用的算法包括有:基于滑动窗口的压缩方法,基于告警事件文本相似度的压缩法,基于告警发生事件关联关系的压缩法等。对于某个具体业务应用,可以配置压缩时间窗口的大小,压缩文本相似度大小,压缩所需要的特定字段等
为了计算告警事件之间的关联关系,首先需要对同一个时间窗口T内的告警进行去重处理,得到唯一个告警事件ID,这一个时间窗口T内的所有独立告警可以被认为是一个独立的数据集,即
AT={a0,a1,a2, …an}
其中AT表示时间窗口T内所有告警的集合,而a0表示某一条独立的告警事件。
计算告警事件之间的关联规则就是形成如X→Y的映射关系,其中X和Y是不相交的项集,在关联关系挖掘中,有两个非常重要的概念:支持度(s)和置信度(c),对于告警事件的支持度和置信度的计算公式分别为
其中:N是所有AT的总数。σ(X)表示X项集的个数。
3)告警升级。定义告警级别升级策略,对告警事件持续时间较长而未处理关闭的告警进行级别自动升级处理,如从一般告警升级为严重告警;也可以依据告警事件发生频次做升级处理,如对于发生频次较高的告警做升级处理;或对指定告警类型进行升级处理,如对硬件类资源监控指标得到的告警事件进行升级处理等。这些升级处理的触发时间和触发条件等可以通过配置来实现。
4.4 基于spark streaming的处理框架
为提高对海量气象业务监视数据的处理时效,系统采用Spark Streaming处理框架实现对监视数据预处理、指标计算。
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照时间窗口分成一段一段的数据DStream(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备。Spark Streaming处理流程如图6[10]。
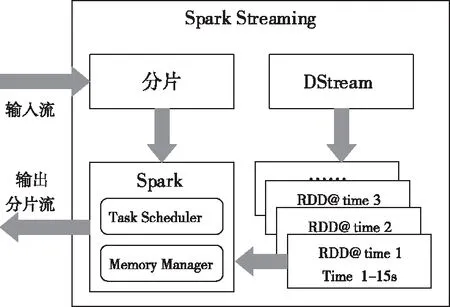
图6 Spark Streaming处理流程
对于一个Spark集群来说,执行器(Executor)数量和执行器的并行度固定后,分区数量决定了任务执行的数量,也决定了任务执行的效率。
针对执行器数量,分区过多会导致任务的排队,分区过少会降低集群的利用率;分区数据的倾斜,会导致各个任务的执行时间不一致,快的任务需要等待慢的任务,形成木桶效应,降低利用率。另一方面时间窗口大,每一批的数据量过大,会导致数据溢写,降低效率,处理时间变长;窗口小,批次数据过少,又会导致调度时间相对过长。所以,分区和时间窗口的设置需要充分考虑系统资源情况和处理数据量。
气象综合业务监视数据平均每秒处理记录数约为3万条,设置时间窗口为15s,每批数据量为45万条;执行器数量为12,故选择把数据分成10个分区,对应10个执行器,另外2个执行器进行调度处理。一方面为了提高系统资源利用率,另一方面避免在计算过程中分区之间过多的数据交换。
由于计算中经常会对同一种资料、同一个时次进行指标累加计算,如果将数据随机分配到分区中执行计算,同一种资料会在多个执行器上计算,汇聚时需要从各个执行器上进行结果汇总,根据实验结果,影响了整体运行效率。为了减少任务执行后产生的汇聚开销,在数据进入分区前增加一次排序操作,按照资料类型和业务时次进行排序,尽可能把同一种资料同一个时次的日志数据放在同一个执行器上执行。
把45万条数据根据资料类型和时次均匀分成10个分区,数据分区的伪代码如图7。

图7 数据分区伪代码
为提高分区效率,本文采用水塘采样算法,对每一个时间窗口的m条数据,随机抽取n条样本数据,针对样本数据,按照分区逻辑计算每个分区的索引范围,再将m条数据根据索引范围加入到每个分区中。引入该方法后,数据分区效率得到大幅度提升。
根据复杂度[11]式(3)估算45万条数据的排序性能。
计算复杂度=O(m)+n×log(n)+O(n)
(3)
分区优化前,计算复杂度为
O(450000)+450000×log(450000)+
O(450000)≈3443946
(4)
分区优化后,计算复杂度为
O(450000)+2000×log(2000)+O(2000)≈458602
(5)
可见,利用采样数据进行分区优化,根据复杂度计算结果,分区性能可提升7倍以上。
4.5 基于全链路压测体系的故障仿真与定位
基于全链路压测体系的故障仿真建立了一套标准的模拟流程(图8),包含准备阶段、执行阶段、检查阶段和恢复阶段。覆盖从计划到还原的完整过程,并通过可视化的方式清晰的呈现给使用者。故障模型训练的目的是有针对性的制造一些故障,给故障定位系统制造数据。其流程图如图9所示。

图8 全链路压测体系故障仿真流程图

图9 故障模型给故障定位系统制造数据流程图
故障注入的对象包括1)应用:外部超时/响应变慢等。接口,DB延迟/连接满/热点,redis缓存热点,kafka,中间件的负载均衡/限流等。2)资源:cpu,内存,磁盘,io,网络延时等。以及3)程序:cpu,mem,iptable,流量劫持,解析,过滤,模拟丢弃和延时等。
通过故障模拟,可以实现以下目标:1)检验降级预案的有效性:下游依赖出现故障时,预案能及时应对,将系统的 SLA(service-level agreement,服务等级协议)维持在相对较高的水平,不因下游故障引起当前服务可用性的故障。2)监控报警:校验报警是否符合预期:是否报警、消息提示是否正确、报警的实效、收到报警的人是否预期。3)故障复现:故障复盘的后续todo项落地效果如何,通过一定时间后对故障的重现和验证,完成闭环。4)架构容灾测试:主备切换、负载均衡、流量调度等容灾手段健壮性如何,提前发现并修复可避免的重大问题。5)参数调优:限流策略、报警阈值、超时设置的调优。
5 实验结果与分析
5.1 实验运行环境
气象综合业务监视数据采集与处理框架的实验运行环境由11台虚拟机组成,硬件配置如表2。
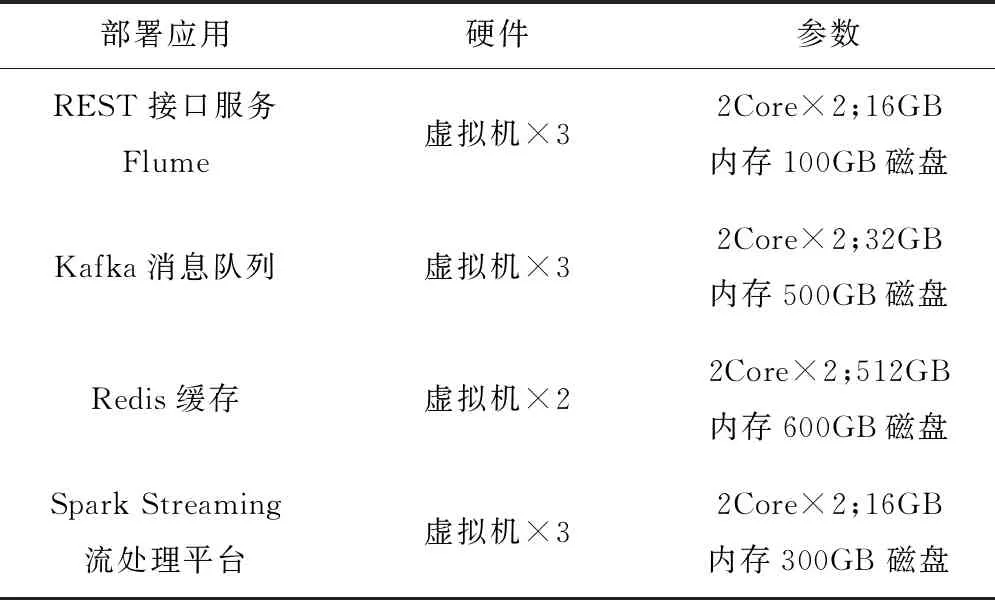
表2 硬件配置
5.2 性能分析
为测试监视数据采集性能,选取了5个业务日志文件,计算Flume从读取文件到写入Kafka消息队列之间的时效和吞吐量,测试结果表明,5个日志文件的平均处理吞吐量为18MB/s,每秒采集的日志记录条数峰值达30万以上,如图10。

图10 Flume采集性能
另外,基于Spark Streaming流处理平台,接入所有气象综合业务监视数据,测试24小时内,预处理、去重、指标计算环节的处理记录条数,如图11。

图11 Spark Streaming处理性能
测试结果表明,Spark Streaming流处理平台能实现平均每分钟处理200万条,每秒处理峰值达6万条以上,日累计处理记录数超过30亿条。
5.3 告警压缩结果
本文选取了2019年6月15日到6月20日共5天内的告警事件数据,并采用上述告警压缩方法,选定时间窗口为10分钟,得到了压缩前后的告警数量,如图12所示。
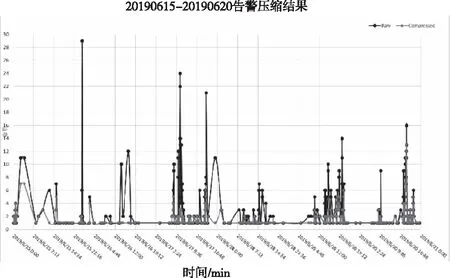
图12 对5天内的告警数据做压缩得到的结果。
图12中展示了一部分时间内的告警压缩结果,其中红色线表示压缩之前的原始告警数量,而绿色线表示经过告警压缩之后的告警数量,从图中可以对比发现,压缩之后告警的数量得到了极大减少,且通过计算发现,该时间段内的告警压缩率结果为71.2%,表明经过压缩算法处理后,呈现出来的告警数量降低到原来的30%左右,显示出压缩算法的效果非常显著。
5.4 故障仿真结果
为了验证系统的稳定性和及时发现故障,解决故障的能力。从资源、应用和程序三个方面进行了故障注入的模拟测试。下面给出了其中两个测试的实验结果。
1)进程挂起故障模拟
图13显示了编号为1841的进程挂起的故障模拟结果,故障注入之前状态为S,故障注入之后的状态变为T。

图13 进程挂起的故障模拟结果
该结果显示故障注入系统可以成功的模拟和监测进程故障。
2)系统使用故障模拟注入
在该实验中,人为模拟了通过对系统进行冒烟压力测试的方式,加大系统的CPU使用率,图14显示了从12月29日到1月6日这一周之内测试的结果。

图14 测试结果
结果显示,系统可以有效捕捉到CPU使用率超标的系统缓慢故障并及时发出有效预警,给系统维护人员准确判断故障原因与及时排出故障提供了有效依据。
6 结束语
本文建立了针对气象综合业务监视数据的采集与处理框架,采用REST、Flume、Kafka、Spark Streaming等一系列大数据技术与算法,实现对监视数据的高效采集、缓冲和处理。同时采用先进的故障模拟仿真技术对系统进行了故障排查压力测试。该框架已经业务应用于中国气象局气象综合业务实时监控系统中,目前,每日采集和处理数据超过30亿条,每秒处理峰值达6万条以上,支撑监视数据30s内完成采集、处理到告警的快速发布,提高了气象综合业务故障的快速发现能力。未来,基于该处理框架的监视数据挖掘、告警关联分析、故障智能预测和故障自愈将是研究的重点,以推动气象监控运维系统的自动化、智能化水平。
