面向任务型的对话系统研究进展
2021-11-16贺王卜丁紫凡
杨 帆,饶 元,3,丁 毅,贺王卜,丁紫凡
(1.西安交通大学 软件学院 社会智能与复杂数据处理实验室,陕西 西安 710049;2.西安交通大学 陕西省人工智能联合实验室,陕西 西安 710049;3.西安交通大学 深圳研究院,广东 深圳 518057)
0 引言
随着基于深度学习的自然语言处理技术的快速发展,以文本内容特征表示学习与语言模型为核心的深度语义理解与模型构建已逐步替代了传统的基于语法、句法和语义解析的方法,并大幅提升了人机对话系统在人机交互、智能助手、智能客服、情感陪护和问答咨询等多个领域的应用性能与效率。与面向开放领域的对话聊天系统不同(如微软小冰和苹果Siri),面向任务型的对话系统(Task-oriented Dialogue System)是特定场景与环境下,在理解用户多样的表达方式(甚至是口语、俚语以及富情感)的基础上,通过对用户意图的准确识别,并结合外部知识库与知识图谱中的知识语义,尽可能高效率且准确地响应用户任务需求的一种人机对话系统。
早期阶段,构建一个经典的基于流水线模式的任务型对话系统主要包括:自然语言理解(Natural Language Understanding)、对话管理(Dialogue Management)和自然语言生成(Natural Language Generation)等三个方面的任务[1]。其中,利用自然语言处理技术来理解用户的语言并准确获取用户意图,则是核心且基础性的工作。基于规则的槽-值对(即Slot-value对,例如,fromLoc.City_name=Xi’an/depart_time=2020.04.01)的经典方法可较好地抽取出语句中的核心语义和用户意图特征,并在多轮对话中通过利用对话状态管理,将这些用户意图保存起来以保证对话的连贯性。尽管这种基于规则的流水线模式具有较高的准确度,但是,一方面由于依赖大量的专家经验来人工建立规则,无法适应复杂且快速变化场景下的实际应用;另一方面,多个任务模块在串行的流水线机制下,容易产生误差积累问题,极大地影响了对话文本生成的质量。随着深度学习技术的快速发展,Eric等人[2]、Madotto等人[3]提出了采用基于深度神经网络的端到端模式的方法来解决上述问题,并在多个方面取得了较好的性能提升,成为目前研究与应用的主要方向。
本文在对任务型对话系统基本概念进行形式化定义的基础上,重点关注基于深度学习的对话管理模型,围绕着目前对话问题理解、状态管理、对话内容生成等核心问题的研究进展进行梳理与综述。同时,针对所涉及的依赖数据标注与知识库相结合的方法,以及基于个性化条件下的内容多模态生成等关键技术与性能指标进行对比分析,进一步探讨了新一代对话系统的技术发展新趋势。
1 任务型对话系统概念与核心挑战
定义:任务型对话系统:是一种以任务为导向,面向单领域或多领域问题,以最短轮数完成用户查询或对话任务为目标的一种人机对话系统。其优化的目标函数可表示为式(1):
(1)
其中,θ*为通过神经网络需要学习的参数,U表示截至第n轮对话时的用户话语集合:U={U0,…,Un};R*则表示机器自动生成的回复的集合,R*={R0,…,Rn-1},K表示该领域下的知识库或知识图谱中的业务数据或知识集合,N表示对话的总轮数。因此,任务型对话系统可以表示为:针对用户问题Un的意图识别,在前n-1轮的对话状态的管理与知识库K的约束下,机器在最小轮次的情况下自动生成的满足用户需求的回复Rn。
根据上述定义,任务型对话系统需要面对如下三个核心挑战。
(1)如何准确理解和识别在复杂业务场景下基于自然语言的用户意图。由于任务型对话系统的核心优化目标是采用尽可能少的对话轮次来实现用户任务的反馈Rn,一方面,在人机交互时,如何提高对自然语言的理解能力,从用户话语U中精确获取和识别用户意图是任务型对话系统面临的核心挑战;另一方面,当单轮对话无法完成对话任务时,如何通过对话状态管理,从R*中有效选择相同任务主题中的上下文,来优化用户意图的识别,也是目前研究的关键问题之一。
(2)如何解决对训练数据的标注依赖和知识库的结合问题。基于端到端的深度学习算法在建模时往往依赖大量的标注的数据,高质量的标注数据需要花费大量的时间与人力,如何在无标注或少量标注的情况下,提高模型在用户意图、对话状态和对话策略等方面的性能;其次,系统如何结合包含业务数据的知识库K,来对识别出的用户意图进行更好的语义查询与推理匹配,这直接影响系统的应用性能与范围。
(3)如何解决多模态条件下对话内容的个性化生成。目前主流的任务型对话系统主要采用基于语音或文字的人机交互方法,但是人们在实际的对话过程中,往往会同时借助于视觉、语言内容以及语音和语调等多种模态的融合特征来辅助决策。一旦将这些多模态信息引入到对话系统,既能避免传统对话内容生成的单调性,又能充分结合用户的个性化特征,确保了基于多模态对话内容生成的多样性。因此,解决面向复杂场景下的基于多模态的对话内容个性化生成已成为下一代对话系统的重要方向之一。
因此,本文在任务型对话系统基本概念的基础上,针对上述三个核心问题,进一步分析并深入探讨当前的研究与技术进展。
2 基于自然语言处理的用户意图理解
如何准确理解用户问题和意图是面向复杂业务场景下人机对话系统的核心任务与挑战,这主要依赖于系统对自然语言以及口语的理解能力。在流水线模式下,可根据事先定义的规则将用户意图分为不同的类,如天气查询、订餐等,再将时间、地点、人物等不同的命名实体类别定义为槽(Slot),从用户话语中抽取相应的值(Value),并形成Slot-value对(如:时间=12:00pm)来表示用户意图。目前,大量实际的人机对话系统都是以此为基础进行扩展和优化形成的。本节针对近年来在用户意图识别与理解领域的最新研究进展进行梳理与总结。
在任务型对话系统的自然语言理解领域,较为常用的数据集有ATIS (https://github.com/Microsoft/CNTK/tree/master/Examples/LanguageUnderstanding/ATIS)、DSTC4[4]和Snips-NLU[5]三种,其中,ATIS和Snips-NLU两个数据集的一些信息如表1所示。DSTC4数据集由35组真实的对话数据组成数据集,分为导游和游客两种角色,对话中包含31 034条话语,时长达21h。

表1 ATIS和Snips-NLU的数据统计
2.1 联合意图理解与槽填充任务的人机对话理解
在对话语义理解与意图识别任务中,用户意图检测(Intent Detection,ID)可通过文本主题分类方式与基于BIO标注的语义槽填充(Slot Filling,SF)相结合,以利用两者在语义和逻辑上的联系提升模型性能,可解释性也更好,这类模型常被称为联合学习模型。
Zhang等人[6]提出了RNN Joint Model,将命名实体抽取与对话主题分类相结合,通过Bi-RNN进行编码,将其中的隐向量作为意图识别与槽填充两个任务的输入,在ATIS数据集上的实验结果表明,这种方法可有效提高模型的性能,其槽填充F1值达到了95.61%,成为近年来最具竞争力的模型之一。而Liu等人[7]则使用类似于机器翻译的Seq2Seq+Attention注意力机制的联合学习模型来进行意图识别和槽填充任务,使用Encoder对用户话语进行编码,并利用基于Attention的机制分别进行意图与槽填充的判断。该模型在ATIS和Snips-NLU数据集上槽填充的F1值分别达到94.2%和87%。上述这两种模型均采用联合损失函数来模拟意图识别和槽填充的联合学习方式,但均未明确地描述出两者之间的关联,因此也被称为隐式的联合学习方法。
为了更加显式地表示两者之间的关系,Goo等人[8]提出了Slot-Gated Model,利用门机制对用户意图与槽之间的关系进行建模,在提升模型可解释性的同时,其性能比Attention Bi-RNN模型在ATIS和Snips-NLU数据集下的槽填充F1值分别提高了1%和1.3%。为了进一步增强对输入特征的选择与语义的表示能力,Li等人[9]融合了门与自注意力机制,提出了一个GMSAM模型,该模型利用自注意力机制增强了自然语言的编码能力,并利用门控(Gate)机制实现了输入特征的选择控制,且在ATIS数据集下的槽填充F1值以及意图识别准确率分别达到了96.52%和98.77%。
上述两种基于门控机制的联合模型均是根据用户意图来决定槽填充的单向方法。但实际上,槽分类与意图识别之间存在着相互的影响,因此,Wang等人[10]设计了一种利用两个Bi-LSTM Encoder分别对用户语句的意图特征和槽特征进行编码的双向模型(Bi-Model),并在计算过程中同时考虑意图与槽之间的相互影响,该模型在ATIS数据集上的槽填充F1值和意图识别准确率比GMSAM[9]分别提升了0.37%和0.22%。Haihong等人[11]在显式地模拟和计算意图与槽之间相互影响的基础上,进一步提出了一种新的联合学习模型SF-ID network,如图1所示,模型对于学习到的意图和槽表示向量,并不直接进行分类输出,而是利用文中提到的subnet算法先计算出两者之间的融合表示,再利用其表示与槽表示计算出槽的加强向量,并用该向量完成后续的任务。这种方式使得模型可以更加深入地学习意图与槽之间的语义和上下文联系,在Snips-NLU数据集上的槽填充F1值和意图识别准确率分别达到92.23%和97.29%。

图1 SF-ID network的结构[11]
Zhang等人[12]提出了一种基于分级胶囊网络的CAPSULE-NLU动态模型,如图2所示,该模型封装了话语中的词语、槽和意图之间的层次关系,并实现了槽填充和意图识别的联合学习,且在Snips-NLU数据集上,槽填充F1值与意图识别准确率分别达到了90.2%和97.7%。
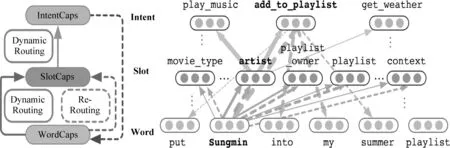
图2 CAPSULE-NLU模型的结构[12]
为了进一步融合槽与意图的语义关系和词级别的关系,Chen等人[13]提出了WAIS模型,该模型在Encoding部分使用了传统的BiLSTM进行特征编码,再利用Attention机制计算意图与槽的表示,但随后利用了词级别的Attention来提取额外特征,并利用门控机制将意图与槽的表示和该特征融合起来输出计算结果。这种做法使得模型在结构简洁、参数较少的情况下,同时融合了词级别特征和槽/意图特征,因此获得了较高的性能。在ATIS数据集上,WAIS比SF-ID network模型在意图识别准确率和槽填充F1值上分别高出1.0%和0.7%。在Snips-NLU数据集上,则比此前性能最好的CAPSULE-NLU高出0.73%和0.89%。
随着BERT[14]预训练模型在自然语言处理的各项任务上表现出的强大性能,Chen等人[15]将BERT模型用于槽填充和意图识别联合学习的任务上,通过将CLS标签对应的输出采用线性分类器输出意图类别,而用户话语对应的输出则利用BERT+CRF的经典方式输出槽填充的标注。该方法在Snips-NLU数据集上与WAIS 模型相比,在意图识别准确率上相当,但在槽填充F1值上则高出5.61%。加入字母Embedding的做法可以为模型加入诸如词根等额外特征,使得模型获得更深入的解析能力。Firdaus等人[16]基于此提出HCNN模型,利用融合单词和字母Embedding的做法大幅提高了模型的性能,并在ATIS数据集上,意图识别与槽填充的性能比BERT+CRF模型分别高出1.19%和1.32%;但在Snips-NLU数据集上则比BERT+CRF模型低了0.16%和1.8%。
2.2 基于上下文状态管理的对话理解
在一些应用场景下,一旦无法用当前对话来确定用户的真实意图,则需要通过多轮对话来确定,此时对话的上下文信息可用来辅助模型进行自然语言理解任务。基于此,Shi等人[17]提出了一个基于对话上下文分析的语言理解模型RNN-based Contextual Model,该模型将上一轮对话的预测结果与当前轮次的对话结果相结合,来确定用户的意图与槽值,在AITS数据集上槽填充F1值达到了96.83%。为了将对话历史信息更好地建模,Chen等人[18]提出了MNN-NLU模型,该模型通过MNN网络将对话的历史上下文内容进行编码,将当前用户话语表示与历史用户话语表示直接求向量积来计算 Attention 权重,用Attention权重与历史对话表示加权求和来生成上下文表示向量,再利用这个上下文表示向量与当前轮的对话表示相结合,协助判断用户意图与槽的填充值。在Cortana数据集上,多轮对话的整体槽填充准确率为67.8%,召回率为66.5%。在此基础上,Bapna等人[19]进一步提出了一种基于序列对话的编码网络(SDEN),该网络在编码历史对话信息的策略上与MNN算法不同,该策略是将当前用户话语表示与历史对话表示拼接起来,使用前馈神经网络来计算上下文矩阵,再求解获得上下文的向量表示。为了将对话中仅包含单领域问题的数据集扩展到支持多领域问题的数据集,SDEN模型采用了一种重组数据集的策略,即随机选取两组对话,并随机将其中一组对话截取为两半,将前一半拼接在第二组对话的前面,构成新的重组数据。测试结果显示,在非重组数据集中,该模型表现略差于MemNN-NLU模型,但是在重组数据集上的领域和槽两个任务指标上分别高出0.7%和1.8%,而意图F1值上则低了0.4%。
由于离当前对话越近的历史上下文对当前的用户意图理解可能会越有用,并且之前研究普遍缺少对话角色对算法的影响(例如,服务端角色说话的方式通常较为固定,回答也比用户更简单易懂)。因此,Chen等人[20]提出了考虑角色的时间-上下文动态感知模型(CTAA),结构如图3所示。

图3 CTAA模型的结构[20]
该模型分别对用户和系统利用了上下文和时序两类Attention协助编码历史对话,在DSTC4数据集上,句子级别和角色级别的F1值分别达到了74.6%和 74.2%。为了更加精确地计算时序特征,Su等人[21]又提出了E2E-CTAA模型,该模型认为这种时间-上下文动态感知模型在计算时序时 Attention 方式过于简单,因此,使用可学习的方式将三种一次函数利用加权平均方式来模拟时间衰减函数,从而获得了比手动配置衰减函数以及使用固定的衰减函数更高的性能,并在DSTC4数据集上,句子级和角色级的F1值分别达到了74.40%和74.33%。考虑到这两种模型的性能基本相当,并且在上述两种时间感知模型中,利用手动调整的时间衰减函数常常无法达到最优的效果,因此Kim等人[22]提出了无须衰减函数的时间感知注意力模型(DFF-CTAA)。该模型一方面引入了一个可训练的距离向量来直接学习时间衰减趋势,另一方面考虑了存在多个用户的情况,将说话人身份的角色特征构造成一个可训练向量来计算。实验结果显示,该模型的性能比之前Su和Chen等人提出的模型有了很明显的提高,在句子级别与角色级别的计算中,F1值在句子级别上比此前最好的CTAA模型高出1.35%,在角色级别上也比E2E-CTAA模型高出1.23%。
2.3 基于自然语言处理的对话理解模型对比
一般地,基于联合学习的研究重点主要在于如何解析深度语义来实现槽与意图的有效关联;而基于对话历史上下文整合的模型则更关注如何综合判断对话历史距离以及内容对于当前对话的影响上,因此一些研究利用历史对话与当前对话的关联性随时间衰减这一特点,来进行模型性能的优化;同时,由于模型在编码对话历史时随着对话轮数的不断增多,耗费的计算资源也将随之增加,如何将这种衰减与对话中的意图与语义结合起来,让对话历史的关联性从单纯的时间维度拓展到语义、意图等多维度,则是一项重要的任务。但由于基于上下文的预测模型和联合学习模型所采用的数据集不同,因此,尚未对这两类模型的性能优劣进行有效对比分析。
表2对比了上文中提到的各类基于自然语言处理的对话理解模型的性能对比,其中,ID表示为意图检测(Intent Detection),SF表示槽填充(Slot Filling)。从性能指标来看,Kim等人[22]提出的DFF-CTAA模型在利用上下文预测的模型中性能最佳,这是因为该模型不仅将角色利用可训练向量进行表示,而非简单地采用Guide/User来表示,使得用户的角色特征可以被模型更好地学习和表示,并且模型在时间衰减函数上采用了完全的端到端算法,增加了时间衰减函数的精确性。而在基于联合学习的模型中,无论是采用基于胶囊网络、CNN或是RNN的模型,在不同数据集上都获得了较好的性能;同时,在HCNN模型中通过利用字母级别的Embedding,以及在WAIS模型中加入了词级别的Attention,这些方式增加了更多有用的特征,并提升了模型对自然语言的理解能力。另外,基于预训练的新语言模型对算法性能提升显著,例如,一个简单的BERT+CRF[15]结构,就能让模型获得较大的性能改善,如果将相关数据集进行预训练,性能也许会有更大的提升。

表2 基于自然语言处理的对话理解模型的性能对比
2.4 基于对话状态追踪的用户意图理解
对话状态通常由一组请求和联合目标共同组成,其中,请求分为目标(information,即表示用户希望实现的目标)和请求(request,表示用户希望获取的信息),例如,用户希望吃中餐(以Slot-value的形式体现:如food=Chinese)是一个目标,而用户希望获得地址(address)则是一个请求。将到当前轮为止的每一对话轮中的目标和请求加在一起,其中的每一轮的目标和请求称为回合目标和回合请求,而所有轮的目标构成联合目标。表3列举了一些在该任务上的常见数据集,这些数据集不仅可以用来进行对话状态追踪任务,也可以作为整个对话系统构建任务的数据集使用。

表3 支持对话状态追踪任务的常见数据集
在传统的流水线模型中,需要对话状态追踪模块记忆用户的每一轮意图来进行系统行为的判断。在当前的研究中,对话状态追踪任务整合了用户意图理解的任务,对话状态直接由对话生成。而使用基于深度学习方式来构建的对话状态追踪器常可以分为两种方式:生成式与检索式,前者直接使用生成方式来生成槽或根据备选的槽生成对应的值;后者则是将所有的备选槽-值对以分类的形式进行计算,从而判断当前的对话状态。
Zhong等人[28]发现:在对话状态追踪任务相关的数据集中,有一些槽的样本很少,传统的模型对于这类稀疏样本无法有效学习,因此提出GLAD模型(Global-local Attentive Encoder),如图4所示,该模型对于不同类型的槽使用单独的基于Bi-LSTM的编码器进行编码(local-encoder)以学习不同槽的特征,并对所有的槽使用了一个相同结构的全局编码器进行编码(global-encoder)来学习这些槽的共同特征。该方式不仅解决了对于稀疏样本的学习问题,并在对话状态追踪性能上取得了突破,且在DSTC2[23]数据集上的联合目标准确率比NBT模型高出1.1%,达到了74.5%,在WoZ2.0[24]数据集上比FS-NBT模型高出3.3%,达到了88.1%。同时,在多领域对话数据集Multi-WoZ[25]数据集上的全部任务联合目标准确率达到了35.57%,并且针对该数据集中的餐厅子数据集达到了43.95%。实验显示,在面对较少的测试样例时,通过global-local策略可有效提升模型的对话状态追踪能力,如图5所示。
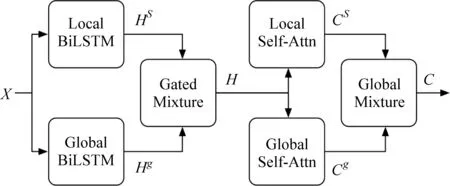
图4 GLAD模型的结构[28]

图5 GLAD模型在面对稀疏数据时显示出较高性能[28]
在GLAD模型的基础上,又衍生出一系列相应的改进模型。其中,具有代表性的改进模型包括:Sharma等人[29]提出的DRC模型以及Nouri等人[30]提出的GCE模型等。DRC模型主要采用GLAD模型分别编码对话历史、系统行为与用户话语来融合不同特征,从而在MultiWoZ-Restaurant[25]数据集上获得的联合目标准确率比单纯的GLAD模型高出2.36%。而GCE模型在大幅降低GLAD模型的复杂性的同时也提升了其性能,在WoZ2.0[24]数据集上的联合目标准确率比GLAD模型高出0.4%。
由于GLAD模型随着槽的类型的增加,模型的参数量也会随之增多,因此在多领域数据集下的训练将非常耗费系统资源,而且无法有效地分类训练未出现过的样本。而Ren等人[31]使用了一个通用的StateNet模型,通过跨槽值来共享参数,并且模型不会随着槽值对的数目增加而变得更复杂。同时,对于给定的槽,即使出现新的对应的值,只要有该值的词向量,模型就可以对新的值进行预测。为了进一步证明模型在共享参数时也可以更好地实现对话状态追踪任务,消融实验的结果显示:通过共享领域间的参数,并使用某一领域的部分数据进行预训练,可有效提高模型的性能。在DSTC2[23]和WoZ2.0[24]两个数据集上的测试结果显示,联合目标准确率比GLAD模型分别提高了1%和0.8%。
此外,随着BERT等预训练语言模型在自然语言处理领域内的成功,Lee等人[32]将BERT模型引入到对话状态追踪任务中,提出了SUMBT模型。该模型利用BERT模型分别预训练学习对话状态的固有特征和自然语言的通用特征,从而充分共享不同领域间的语义和槽值对等信息,并在多个数据集上展现出了很高的性能,其中,在WoZ2.0[24]数据集上,该模型比StateNet模型的联合准确率高出0.3%,达到了89.2%;在MultiWoZ[25]数据集上,该模型的联合准确率则高出GCE模型6.82%,达到了42.4%。
考虑到对话状态追踪模型在利用会话历史以及语言理解两种模式分别进行计算时,都表现出了一定的优势,如果能将这两种模式的优势融合,则可能会大幅提高模型的性能,因此,Goel等人[33]提出了混合两种模式的HyST模型,并将当前话语编码和前一轮的对话编码作为输入,利用前馈神经网络计算每一个槽是否在该轮被提及,并判断每一个槽对应的值在全词表上的分布,使得模型在整合对话历史、加强自然语言处理能力和应对OOV(Out of Vocabulary)问题上都获得了较好的性能。例如,在MultiWoZ[25]数据集上,该模型的联合目标准确率比SUMBT[32]高出1.84%。而Gao等人[34]提供了另一种解决问题的思路,其将对话状态追踪任务作为阅读理解任务来看待,并基于Attention来构建了NRC-DST模型(Neural Reading Comprehension-DST),该模型将用户话语中蕴含的槽分类为:是/否/不关心或范围(span)四种,当槽检测器检测结果为范围时,槽范围检测器则会在对话内容中确定一个存在槽的范围;如果检测结果为“是/否”,则利用二值化检测器输出所有候选槽的概率分布。在MultiWoZ[25]数据集上,该模型的联合目标准确率达到了47.33%,比HyST[33]模型高出3.11%。
为了让模型更好地适应多领域的对话任务,Wu等人[35]在引入指针生成网络[36]的基础上,提出了TRADE模型,通过检索整个词表与候选的槽值对来选择所需要生成的对话状态。该模型在MultiWoZ[25]数据集上联合目标准确率达到了48.62%,比NRC-DST[34]模型高出了1.29%。其结构如图6所示。
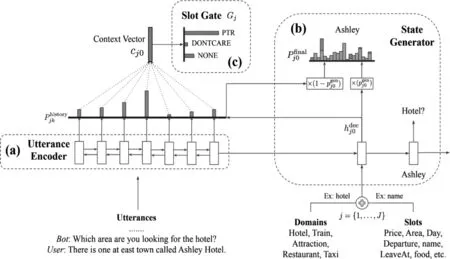
图6 TRADE模型的结构[35]
而利用MultiWoZ[25]中五个领域中的四个子数据集进行训练时,将剩下一个领域子数据集中1%的数据进行fine-tuning,再对该领域进行测试,结果显示模型具有一定的迁移能力(表4)。表中指标为联合目标准确率,第一行数据为除该领域外的数据进行学习时达到的准确率,后三行为根据不同的策略在新领域利用1%的数据进行学习后在新领域数据上的性能。

表4 TRADE模型的领域迁移实验[35]
由于上述模型的时间复杂度普遍较高,例如,前文提到的GLAD[28]模型,其算法的推理时间复杂度[39]为O(m×n),其中,m表示值的数目,n表示槽的数目。这使得本来就耗费计算资源的深度学习模型在面对多领域、大数据量的情况时,计算的速度会变得非常慢。基于此,Ren等人[39]提出了完全生成式的COMER模型,将前轮的对话状态、前轮系统回复和当前轮的用户话语采用BERT进行预训练进行嵌入表示后,再利用经典的BiLSTM进行编码,而后经过三个CMR Encoder(图7)的编码器结构进行特征融合编码,最终输出当前轮的对话状态。这种方式不需要对每一个槽或值进行匹配和计算,而是通过采用不同的生成方式分别生成领域、槽和值的对应信息。这种完全生成的方式在Multi WoZ[25]数据集上显示出了极佳的性能,联合目标准确率高出TRADE模型0.03%,同时将计算的推理时间复杂度降低到O(1)。

图7 CMR Encoder模型的结构[39]
本文进一步将上述模型在不同数据集下的性能进行对比。在该问题下,除了联合目标准确率外,常用的评判指标还有每轮轮请求准确率(Turn Request Accuracy)和槽识别准确率(Slot Accuracy)。从表5 可见,一些具有跨领域处理能力的模型,由于其具有对深度语义的理解能力,使得其在单领域数据集下具有较好的性能,并且在基于全词表检索的生成式模型的基础上,这些算法在降低所需计算资源的同时,面对测试集中存在的未知数据也可以通过迁移学习而具有一定的应对能力。下一步的研究中,如何为算法赋予更深刻的语义解析能力、业务和通用领域语义的融合能力,以及对稀疏样本的学习能力,将成为研究工作的重点。

表5 对话状态追踪领域各模型的性能对比
3 标注数据依赖与知识依赖
3.1 降低标注数据依赖的对话理解算法优化
利用基于流水线的深度学习模型需要用户意图理解、对话状态追踪、对话策略管理、自然语言生成等多个模块协同工作,也因此需要大量的标注数据,这导致训练样本的获取成本变得高昂。例如,WoZ 2.0[24]这种小规模的数据集,仅包括了99个餐厅数据,约1 500轮对话,三种information和六种request类型的数据。而现实场景下的业务数据和客服记录并未进行过大规模的详细标注,如果能对这些原始数据进行妥善利用,将会极大降低数据集的构建成本并提高系统的构建效率。
传统的Seq2Seq[40-41]模型在机器翻译场景下,采用完全端到端的方法而无需额外的数据标注就能取得很好的结果。因此,如果能够将历史对话全部进行编码和存储,并在输入新的对话后,通过改进Seq2Seq模型来实现对话状态管理以及对话历史与上下文的快速查询与语义匹配,则可有效改进任务型对话系统对数据的依赖。例如,MemNN模型[42]通过计算对话历史和当前对话的Attention来计算对话历史记录对当前对话的影响,其结构如图8所示。在此基础上,Madotto等人[3]将Seq2Seq与MemNN模型相结合,提出了Mem2Seq模型,该模型利用不同层的MemNN将对话历史与知识库中的不同特征进行编码,从词表、对话历史以及知识库中挑选出单词作为输出。在KVRT(In-Car)[2]数据集上,该方法比单纯的Seq2Seq模型在EntityF1值与BLEU指标上分别提高了13.5%和4.2%。
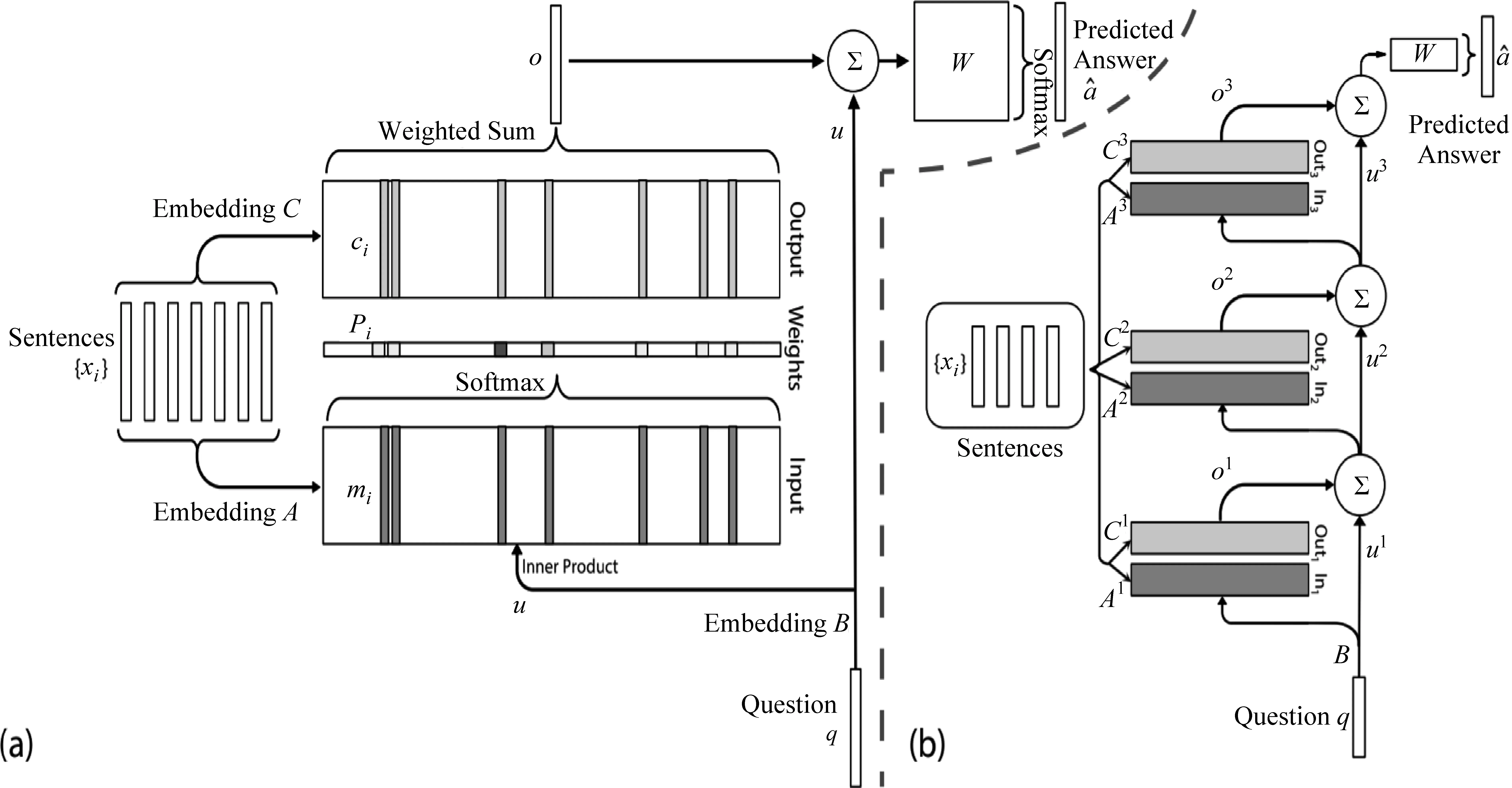
图8 MemNN模型的结构[42]
考虑到人们对情景记忆(对话、文本等)以及语义记忆(书本、知识库等)模式存在着差别,但Mem2Seq将知识库与对话编码混为一谈,因此,Chen等人[43]提出了一个WMM2Seq模型,将对话历史和知识库分别编码后,使用门控机制来过滤并选择所需要生成的单词。该模型在DSTC2[23]数据集上比起Mem2Seq模型在EntityF1值和BLEU两个指标上进一步提高了5.43%和3.27%。除了利用MemNN结构进行端到端的对话系统构建外,Wen等人[44]提出DSR模型,利用对话状态追踪模块与Seq2Seq模型的优势,将对话状态建模为向量表示形式,并使用注意力机制来增强模型对知识库的查询以及对对话历史中有效信息的利用。测试结果显示,该模型在Cam676[45]数据集上,BLEU和Entity Match 的F1值比Mem2Seq模型分别又提升了1.7%和9.2%;而在KVRT[2]数据集中,则在这两个指标上也分别高出Mem2Seq模型0.1%和18.5%。
另外,基于传统端到端的任务型对话系统常将知识库查询作为对整个知识库的Attention,而不是针对特定的单个知识库进行观察,这种情况可能会导致模型生成的实体会出现不一致。针对这一问题,Qin等人[46]提出了一个基于Seq2Seq结构的KBRNet模型,该模型采用远程监督技术[47]和Gumbel-Softmax技术,解决了知识库中检索标签未标注的问题。同时,在解析用户话语时,利用知识库检索组件返回最相关的知识库记录,来过滤生成话语中的无关实体,提高了话语的逻辑性和实体之间的相关性。并在KVRT[2]数据集上,BLEU指标与Entity Match 的F1分别达到了14.1%和到53.7%,并比DSR模型分别高出了1.4%和1.8%;而在Cam676[45]数据集上,两项指标分别达到18.5%和58.6%,比DSR模型分别高出1.1%和0.6%。
同时,为了更好地解析语义并利用知识库中的信息,Banerjee等人[48]提出了GCN-SeA模型,通过图卷积网络[49-50]将对话历史、当前对话及知识库信息进行编码,并结合图卷积网络对知识库三元组的元素进行语义嵌入与关系解析,并达到了与WMM2Seq模型相近的性能效果。而Lei等人[51]利用标注好的对话状态数据与聊天记录一起来进行任务型对话系统的构建,在基于CopyNet[52]的基础上提出了Sequicity模型,该模型先利用上一轮的对话状态和系统回复以及当前用户话语生成对话状态,再进一步考虑到该轮的对话状态,并生成下一轮的系统回复。这种方式既减少了对标注数据的依赖,又可以利用对话状态提高模型的可解释性。在Cam676[45]数据集上的测试结果显示,该模型比LIDM[45]在Entity Match Rate、BLEU以及SuccessF1等指标上分别提升了1.5%、0.7%和1.4%。另外,这种方式在降低模型复杂度的同时提高了对标注数据的利用率,并可以通过基于生成的方式来有效应对OOV(out of vocabulary)问题。但是,这种生成式模型也可能会由于生成错误的对话状态或对话状态序列的顺序而导致对下一轮结果产生影响。
考虑到Sequicity模型存在的不足,Shu等人[53]结合检索式和生成式两种模型的优势提出了FSDM模型,该模型利用CopyNet通过输入槽的编码来生成inform类槽的内容,并使用二分类方式从所有备选内容中判断Request类槽和系统回复中所包含的槽内容,并在Cam676数据集下,比Sequicity模型在BLEU,Entity Match Rate和SuccessF1三个指标上分别提高了2.1%、2.2%和2.1%。但由于所采用的encoder会限制用户话语的编码能力,因此如果采用更好的编码方式(例如更高的维度)将会进一步提升模型的性能。
表6对近两年来通过降低标注数据依赖而实现的任务型对话算法的性能进行了对比。常用的任务型对话系统模型的评判标准如下:
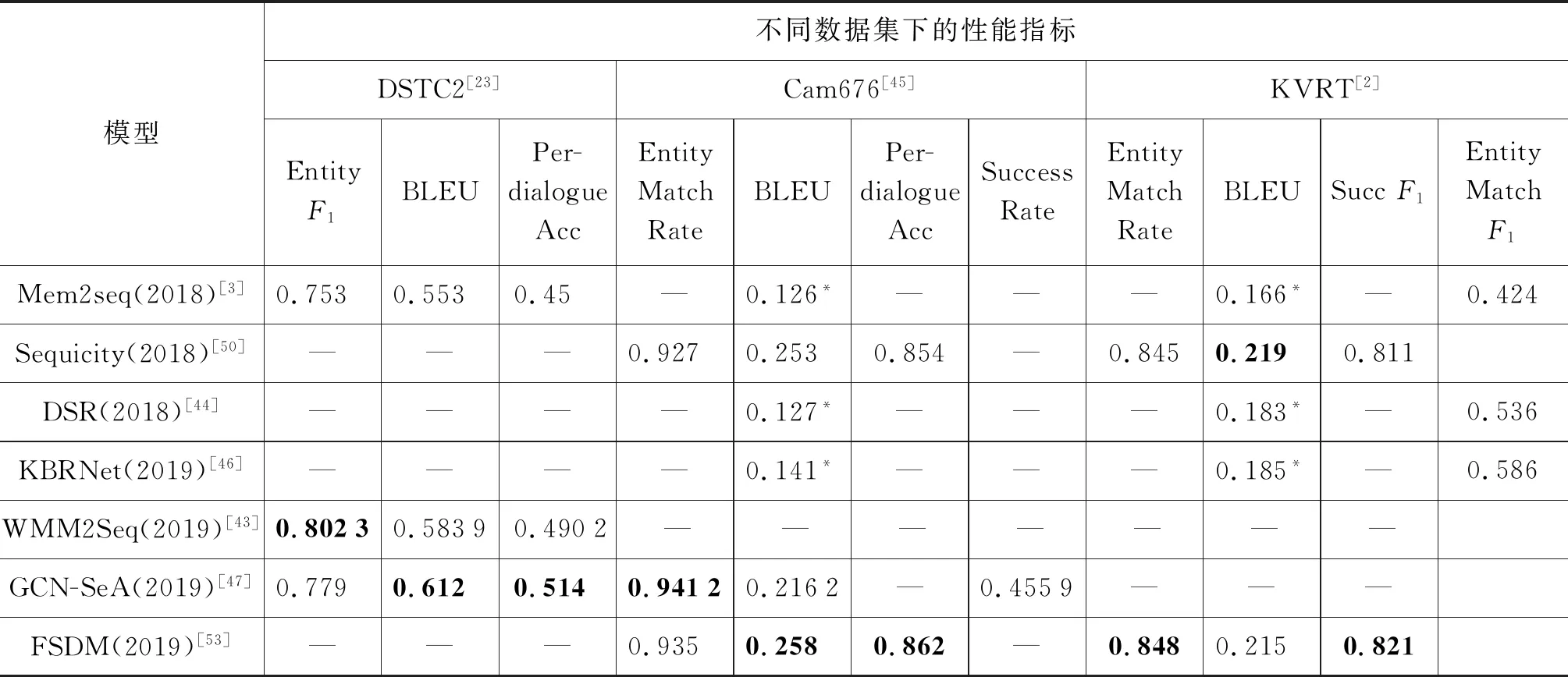
表6 低标注数据依赖的任务型对话系统与性能对比表
(1)Per-Response/Per-dialogAccuracy[54]:分别表示一轮或一组完整对话响应与ground truth匹配的百分比。
(2)BLEU[55]:利用N-gram下的准确率评判生成的回复与ground truth相似程度的指标。
(3)EntityF1[56]:表示每轮生成的实体与groud truth中实体匹配程度的百分比值。
(4)EntityMatchRate(EMR)[24]:表示每组完整的对话完成后算法选择的实体与ground truth的匹配率。
(5)SuccessF1[50]/Rate[47]:表示在对话中对用户请求的槽识别的F1/比例。
从实体识别能力的角度来看,2019年提出的几个模型在不同数据集下均展现出了较高的性能。而在生成回复部分,由于基于图网络和CopyNet模型分别在知识库查询和回复生成方面具有更强的性能,使得模型的BLEU指标相对较高。而KBRNet[46]在使用的数据集和测试方式上和其他几个数据集不同,但考虑到该模型基于Seq2Seq模式,且仅考虑了对知识库的优化检索方式,就已获得了比之前工作更好的性能。可见,目前的任务型对话系统在数据检索问题上还存在不足,需要在以后的研究中继续探索和优化。
3.2 基于知识的对话系统(KBQA)研究
KBQA领域的研究内容是构建以基于知识库帮助用户回答问题为目的的对话系统,与任务型对话系统的区别在于KBQA领域的对话以单轮对话为主,问题也常需要进行逻辑推演来找到答案。在该领域,最为广泛使用的两个数据集是WebQuestions[57]和SimpleQuestions[58],前者训练集/验证集/测试集中的问题数分别为3 000/778和2 032,后者则为75 910/10 845/21 687。
3.2.1 针对多跳关系问答的研究
由于用户意图并非都采用基础的实体/关系查询,在实际场景中,基于知识库或知识图谱的逻辑推理过程,存在着具有递归性质的实体关系间的多跳逻辑,因此,Yu等人[59]提出了一种分层递归神经网络HR-BiLSTM模型来检测知识库中的知识关系,该模型在SimpleQuestions[58]及WebQuestions[57]两个数集上的准确率分别达到93.3%和82.53%。Zhang等人[60]进一步将注意力机制引入KBQA领域,并提出了一个基于注意力的词级别互作用模型ABWIM,该模型比HR-BiLSTM模型在相同数据集上的准确率分别提高了0.2%和2.79%。而Yu等人[61]在知识库自动提取出对象实体类型的基础上,进一步从关系和问题中抽取出多个信息视图,并从多个角度来比较不同视图中存在的问题和关系,使得在相同数据集上的性能比ABWIM模型进一步提升了0.19%和0.63%。
除了常用的SimpleQuestions等数据集外,在如PathQuestion[62](https://github.com/zmtkeke/IRN)/MetaQA[62](https://github.com/yuyuz/MetaQA)/WC2014[64](https://github.com/zmtkeke/IRN)这样的数据集上,有75.6%的问题属于三跳关系的问题,而单跳关系的比例为0。为了解决该问题,Lan等人[65]提出了一种迭代序列匹配模型来进行多跳关系的匹配工作,模型在MetaQA数据集上,一跳/二跳/三跳的%Hits@1性能达到了96.3%,99.1%和99.6%。同时,在MetaQA,PathQuestion和WC2014数据集上的Hits@1和F1性能分别达到了98.6%和98.1%,96.7%和96.0%,及99.9%和99.9%。但是一个依然存在的问题是:所有现有的模型总是有跳数上限,因此对于过度复杂的多跳问题,识别能力依然有限。
3.2.2 针对数据不完整等问题的KBQA研究
由于目前现有的知识库,如FreeBase(已被Wiki Data取代,https://www.wikidata.org/wiki/Wikidata:Main_Page)的子集FB2M,拥有200万个实体和6 700条关系;而SimpleQuestions[58]等数据集由于问题数有限,因此无法覆盖所有的关系。因此,如何让模型识别出这些无法被数据集覆盖到的关系也是一个具有挑战性的问题。针对这一个问题,Wu等人[66]提出了一个从整个知识图谱中学习关系表示的New HR-BiLSTM模型,该模型将学习到的表示合并到关系检测的模型中。在SQB数据集上的测试结果显示,对于见过的关系样例,模型的Micror/Macro Average Accuracy分别达到92.6%和86.4%,而对于未见过的关系样例则分别达到了77.3%和73.2%,而原生的HR-BiLSTM模型虽然对见过的样例在两个参数上分别达到了93.5%和84.7%,但对于未见过的关系其性能指标则只有33.0%和49.3%。
同时,针对现存知识库在内容上存在不完整和歧义、同义等问题,Xiong等人[67]提出了SG-KA-Rader模型。该模型利用图注意力机制对知识库中的知识和关系进行标识,并利用相关文档中的丰富语义信息进行补充。在知识库的完整程度不同时,模型的性能指标和与baseline的对比如表7所示。

表7 SG-KA-Reader模型在不同知识库完整度下的性能[66]
综上,基于KBQA的对话系统,为自然语言中复杂的逻辑和知识库中知识查询与交互的问题提供了一些借鉴的思路,随着任务型对话系统能力要求的加深,以及更新、更贴近真实情况的数据集出现,这些工作将很好地为构建性能更强大的任务型对话系统提供帮助。
4 基于多模态的对话内容个性化生成
任务型对话系统除了应该满足目前用户对于语音交流的需求,还应该在以后的研究中更进一步朝着更加人性化和智能化的方向发展。这要求对话系统在理解业务逻辑和用户自然语言之外,具备对于用户情绪、表情、动作及一些用户数据的解析能力。例如,在电影订阅系统中,推荐新电影时需要综合了解用户的观影习惯及情绪状态;在导购、导游等问答系统中,需要分析用户动作,理解用户手指、目光等指向的目标,以此了解用户意图。为了实现这样的目的,需要利用在多模态、个性化推荐等问题上的研究进展来为未来的任务型对话系统研究提供思路。
4.1 基于多模态的问答系统研究进展
随着传感器、摄像机,以及智能穿戴设备的普及,图像、视频、声音以及文字特征的信息为对话系统提供了多模态的数据来源[70]。利用这些多模态数据输入并融合后,结合用户个性化的表情与场景等视觉特征、语音和语气等音频特征,以及对话信息内容特征来实现基于多模态人机对话更贴近于人类对世界的基本认知方式。
在视觉情绪识别领域,You等人[71]利用CNN构建了一个情绪识别问题的基线模型并提出了大型数据集FI,该数据集包含8个情绪类别,每个类别有约11 000张图片样例。Yang等人[72]认为包含的情绪常常并不是单一的,因此将数据重新标注,同时引入情绪标签之间的相似度等先验知识来辅助分类。Zhu等人[73]认为,很多工作并未将图像中的颜色、质地、部位、物体等多种特征作为独立的特征看待,基于此提出了利用CNN-RNN模型来捕获多种要素特征的Bi-GRU模型,测试显示该模型能有效地捕捉颜色、纹理、物体等关键信息。另外,Yang等人[74]基于之前的工作[72]提出了AR模型,将之前引入标签相似程度的先验知识转换为图像中的检测重点区域,对重点区域进行情感和实体的重要性打分,再利用打分和VGG网络的输出对情感进行分类。该模型FI参考文献[70]和flickr上的准确率分别达到86.35%和71.13%。上述四个模型的准确率对比如表8所示。

表8 图像情感识别相关研究基于FI[70]的准确率对比
在基于音频信号进行情绪识别的问题上,Gumelar等人[75]基于对话人的性别和五种情绪类别,利用一维深度卷积网络把梅尔倒谱系数作为额外特征对音频信号进行分类,性别与情绪分类的准确率分别达到了90%和78.83%。Tao等人[76]则基于从电影中抽取数据的MEC2017[77]数据集,将性别、说话人和情绪作为三个分类任务在深度神经网络、SVM、RNN等多种算法模型融合下进行多任务学习。测试结果显示,这种融合方法比单纯的CNN等方式有明显的提升。另外,语音本身也是一种与自然语言含义重合的时间序列,因此利用RNN模型常会获得比CNN模型更好的效果,Xie等人[78]遵循该思路提出使用一种基于Attention加权的多层LSTM模型进行情感分类任务,在ENTERFACE[79]和IEMOCAP[80]两个数据集上的UAR(Unweighted Average Recall)指标分别比Luong等人[81]提出的Attention-Seq2Seq模型提升2%和1%。
综合不同模态技术的研究进展,2014年由Malinowski等人[82]率先提出构建基于视觉信息的问答系统(VQA)设想,VQA不仅需要利用算法识别出图像/视频中的物体对象,还需要根据用户的提问结合图像/视频进行反馈。Jiang等人[83-84]提出了Pythia模型,并选取图像中物体相关的若干候选框,利用问题表示来为候选框计算权值,确定与问题相关的目标对象。在VQA 2.0数据集上,Pythia v 0.1[83]版本达到了68.49%[85]的准确率,v 0.3[84]版本则达到了68.71%[85],并获得了2018年VQA Challenge的最佳模型。同时,图像中的文本常常包含多种有用线索,虽然大量的工作从图片中抽取其中的文本语义信息[86-87],但鲜有研究抽取图像文本特征辅助问答系统的工作。Singh等人[85]在构建TextVQA数据集的基础上提出了LoRRA模型,模型利用Pythia v 0.3[84]和LoRRA两种方法相结合的策略在VQA 2.0数据集上的准确率为69.21%,比单纯的Pythia v 0.3[84]高出0.5%;而在TextVQA数据集上的准确率则达到了27.63%,比Pythia v 0.3[84]算法的测试结果高出13.63%。而在音频、视频结合领域,Alamri等人[88]构建了基于视频和音频数据的数据集,如QA和AVSD,为结合视频和音频的问答系统提供研究数据。Yeh等人[89]于2019年提出了音频-视觉QA模型,融合了视觉与音频信息,该模型将视频,音频,以及问题、对话记录、描述信息分别利用RNN结构编码,在多个阶段融合特征和注意力,来更好地集成多模态特征,测试结果较Alamri等人[88]的基线在BLEU-4、ROUGE-L指标上分别高出0.006和0.023。除此之外,Matsuda等人[70]提出了USI 模型,利用智能设备收集身体反应特征(如头部运动、眼动、心跳等),来估算在旅行领域用户的多维身体反应与用户满意度之间的关系,并发现眼动特征最能体验用户的满意程度,相关程度高达36%。
4.2 基于个性化的对话内容生成
根据个性化信息的来源不同,基于个性化的对话内容生成可以分为基于情感的对话生成和基于用户个人信息的对话生成两大类。Zhou等人[90]率先将情感因素引入对话中,提出了ECM模型。该模型利用emotion embedding来深度刻画情感表示,并利用外部情感词汇来丰富回复内容。在其收集的ESTC数据集下,其情感匹配的准确率达到77.3%,BLEU指标则达到1.68,情感识别性能 (Emotion-a)达到0.810,在生成的回复中包含相应情感词汇的比例(Emotion-w)则为0.687。Song等人[91]则提出了EmoDS模型,利用了情感分类器对情感表达的强度来隐式提供情感生成的全局指导,并通过基于词汇的注意力来显式地在系统回复中加入情感词汇。该模型与ECM相比在BLEU/Emotion-a/Emotion-w三个数据集上分别提高了0.05/0.45/0.107。Colombo等人[92]则基于ECM的思想将情感通过向量进行表示,并提出利用情感调节器对中性词进行惩罚,计算时强制令模型生成与情感相关的一系列单词,最后在生成的过程中利用Re-rank机制来优化模型对情感相关词的响应。该模型在Cornell数据集[93]上的测试结果显示,无Re-rank机制时,在distinct-1/distinct-2/BLEU三个指标上分别为0.034 2/0.153 0和0.010 8,分别高出ECM模型12.1%/9.1%和12.5%。加上Re-rank机制后,模型比相应的Baseline[94]在三个指标上则分别高出7.1%,37.8%和7.7%,达到了0.040 6/0.203 0和0.014 0。而Lubis等人[95]基于Seq2Seq结构加入了情感编码器来保证语句生成时的情感极性和情感一致性,构建了一个基于同理心的Emo-HRED对话模型,在DailyDialog[96]数据集中的内容和同理心通过人工评分的均值为1.26和0.91。Li等人[97]针对细粒度的情感感知,将用户反馈作为后验信号,基于对抗生成网络思想提出了EmpGAN模型,提高了模型的内容质量和同理分析能力,并在DailyDialog数据集下两个指标的分数均值分别为1.33和1.08,略高于Emo-HRED模型。
另一方面,针对基于用户个人信息的个性化对话生成,Joshi等人[98]提出了针对任务型对话系统的个性化功能集成的数据集Personalized bAbI。围绕该数据集可进一步分为以下五个任务:对话系统中对用户缺失信息的询问和查询(Issuing API Calls)、用户请求更新时的系统响应(UpdatingAPI Calls)、用户请求查询和对话状态的记录(Displaying Options)、根据用户信息在备选方案中的选择推断(Providing Information),以及上述四个任务的集合(Full Dialogue)。Luo等人[99]针对该数据集的存储记忆网络提出了一个端到端的个性化任务型对话模型Personalized MemN2N,并在bAbI数据集上的五个任务中每轮回复的准确率为99.91%、99.94%、71.43%、81.56%和95.33%。Zhang等人[100]在MemN2N基础上,进一步将Mem2Seq模型与门控机制相结合,并将用户个性化信息表示与对话历史相结合,提出了Personalized Gated-Mem2Seq模型,该模型在Personalized bAbI数据集中五个任务上的每轮回复准确率分别达到100%、78.94%、91.83%、87.26%和97.98%。
综上,针对多模态条件下的内容个性化生成这一问题,目前还存在许多关键问题有待进一步解决。例如,基于多模态的情感识别以及蕴含情感的个性化对话等问题,如何通过多模态特征的有效融合,来构造出一个可以听、说、看、共情的个性化对话系统将成为未来重要的研究方向。另外,由于基于多模态的内容个性化生成的问题横跨多个领域、并且其参数的构成复杂,因此,如何设计一个满足在多可用场景下,构造基于多模态个性化生成的带标注数据集,以及设定相关的评价标准,也是迫切需要开展的一项重要研究任务。
5 总结
随着新技术和新需求的不断涌现,任务型对话系统正在向着复杂环境与场景的适应性以及内容生成的多样化与个性化方向发展,本文在对目前任务型的智能对话系统进行分析的基础上,围绕着复杂业务场景下基于自然语言的用户意图识别、训练数据的标注依赖和知识库结合,以及多模态条件下对话内容的个性化生成这三个核心挑战与问题展开了深入研究、进展分析与综述,从而促进了人机交互过程中用户意图的精确识别与对话内容的智能化且个性化的生成,为开发更强大的下一代任务型对话系统提供借鉴和帮助。
除了上述的核心问题,还存在一些值得进一步思考和研究的问题,其中主要包括:
(1)基于任务型对话系统构建新的基础训练数据集:数据以及数据标注质量对算法的性能影响巨大,尤其是在不同主题的实际场景中,语言风格与特征的个性化,也迫切需要建立类似于FI[70]的基础语料资源库来改进模型的预训练模型的质量,这会极大地促进对话学习与内容生成的质量。
(2)提出更好的任务型对话系统的评判指标:一般地,这些评判指标主要可以分为两类:一是对于实体、关系等要素能否成功检测并响应的指标,如EntityF1,Per-Dialogue Acc[3]等指标,二是对生成的对话内容的通顺性与可读性的评价指标,例如BLEU等,但在实际的任务型对话系统的质量评测方面远比上述指标评测复杂,这也导致目前对话系统与实际需要之间存在明显的差异。因此,如何提出一个有效的针对任务型对话系统的判别标准,还需要进一步的思考与优化。
(3)提高模型的小样本学习能力和迁移能力:面对全新的业务,由于数据样本的稀缺,也迫切需要为模型提供小样本的自学习能力以及跨主题、跨模态、跨语言的迁移学习能力。这些工作将会成为下一代任务型对话系统的优化方向,值得进一步深入研究。
