层级标签语义引导的极限多标签文本分类策略
2021-11-16王世龙周宇博史艳翠
王 嫄,徐 涛,王世龙,周宇博,史艳翠
(1.天津科技大学 人工智能学院,天津 300457;2.普迈康(天津)精准医疗科技有限公司,天津 300000)
0 引言
多标签文本分类是利用机器高效自动处理归纳海量文本信息的重要任务,即将一个样本示例与一个标签子集相关联。相关技术可应用在主题识别[1]、情感分析[2]、问答系统[3]等任务中。现实世界中,数据生产速度快、体量大,具有明显的多样性和复杂性。与之对应,类标签个数也不再是以十或百为单位,而是以千、万、甚至十万为单位,典型的有知乎问答分类体系、淘宝产品分类体系等。对此,具有千个以上类标签的多标签文本分类任务,通常被称为极限多标签文本分类任务[4]。
除标签集大之外,极限多标签文本分类任务具有以下特点:①类内类间样本关系复杂,导致标签语义存在部分重叠并非完全正交,具有语义相关性;②不同标签对应的样本数量分布高度不平衡,呈现典型的长尾分布,即少数高频标签对应大量样本,多数低频标签对应较少样本。其中,标签的语义相关性与现有模型对标签语义建模的正交性存在假设冲突,标签与样本对应关系的长尾分布会导致低频标签语义匹配学习的不充分。通过观察数据我们发现,标签语义非正交会体现标签语义的层级性上;高频标签与低频标签常共现在样本标签集中,高频标签语义有助于辅助低频标签语义表达。如图1所示,高频标签“猫和老鼠”和低频标签“秀逗魔导士”同属于“卡通动漫”这一更高级别的语义类别,对于文本,考虑是否可以通过提前在标签语义空间标记更小的标签语义领域来缩小文本多分类任务的分类搜索范围。同时,通过标签语义领域,可以利用高频标签“猫和老鼠”辅助低频标签“秀逗魔导士”的语义建模。基于此,本文考虑在模型训练和预测的同时,利用标签层级信息引入高级别语义范畴的引导标签,其作用如下:①利用引导标签的弱监督语义信息建模标签语义相关性,隐式约束标签搜索范围;②利用引导标签语义辐射范围下的高频标签辅助低频标签的样本学习,优化类间关系,以提升极限多标签文本分类性能。针对任务特点,现有研究方法重点考虑在文本语义表示方法[5-8]和层级标签预测[9-10]两方面进行突破,取得了一定的成绩。然而,这些方法未能同时在模型训练和预测阶段充分地、显式地解决上述两个问题,建模和利用标签语义之间的关联,仍有一定的性能局限。
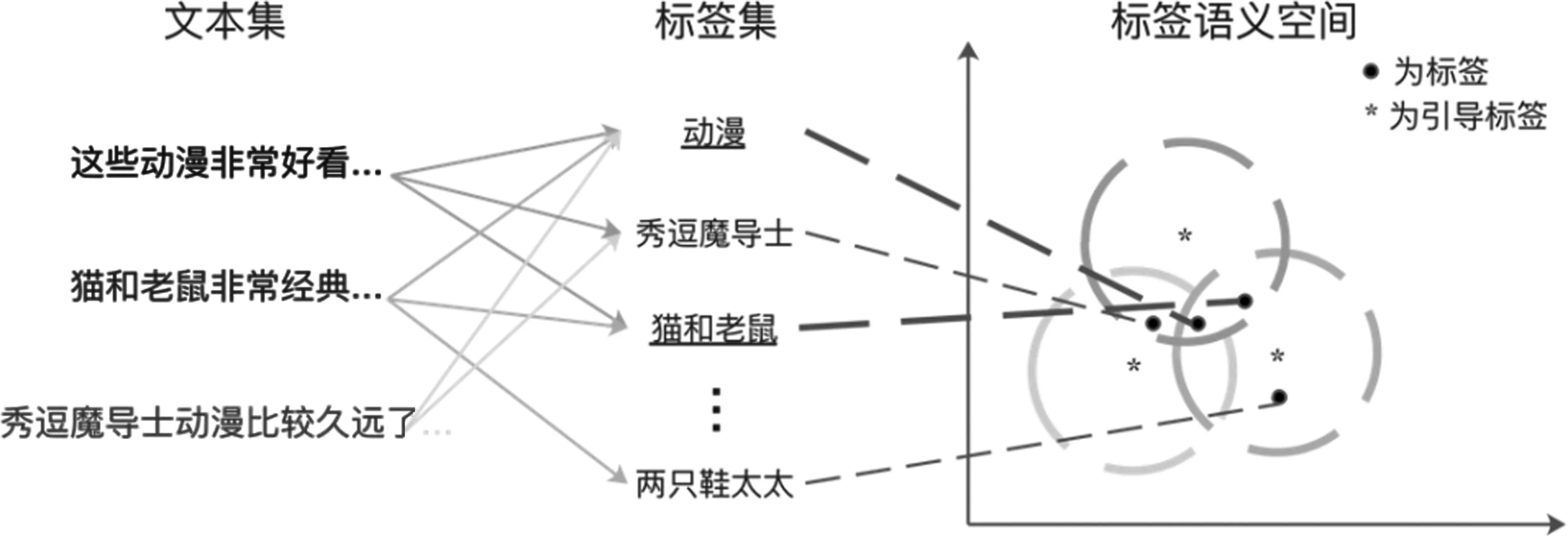
图1 极限多标签文本分类数据语义关系示意图标签集中“动漫”与“猫和老鼠”为高频标签,“秀逗魔导士”和“两只鞋太太”为低频标签,高频标签与低频标签共现在图中三个文本样本对应的标签集中,单条文本样本的标签集的语义可规约在标签语义空间中的同色语义领域中,提前缩小多标签分类搜索范围,定义语义搜索范围的圆心(示意性的,不严格对应计算方法)为引导标签,引导标签不强制要求对应标签集确切标签。
本文的主要贡献如下:
(1)提出一种利用标签层级语义信息引导的极限多标签文本分类模型提升策略,在训练和预测过程中给予模型弱监督语义指导信息,以建模标签语义关联,缓解数据分布不平衡问题。
(2)提出的模型策略简单易行,可以较为容易地迁移到现有极限多标签文本分类模型中。
(3)与同任务代表性模型比较评估,采用本文策略的模型在测试中性能优于基线模型,尤其对短文本数据集有较大提升。
1 相关工作
极限多标签文本分类方法早期工作重点改进传统机器学习方法以适应任务。近年,研究人员重点研究如何利用深度学习方法提升文本语义表示[5-8]或在模型中层级标签预测[9-10]。
早期工作中,研究者主要基于启发式方法,改进传统模型适应任务。如Liu等[11]通过将任务转化为多个二分类问题,基于支持向量机来解决极限多标签文本分类任务;SLEEC方法[12]通过压缩标签向量维度并结合K近邻算法[13]来试图解决极限多标签文本分类中“长尾效应”问题;并且Cai等[14]提出了一种基于支持向量机的层次分类方法来解决极限多标签文本分类任务。但这些传统的机器学习方法基于词袋模型对文本语义进行建模,在一定程度上限制了方法的上限。
近年工作中,研究者主要利用深度学习提升文本语义表示或在模型中进行层级标签预测。提升文本语义表示的工作有,Liu等[4]指出使用多标签文本分类中经典的深度学习算法如Text Convolutional Neural Networks(TextCNN)[5]、Text Recurrent Neural Networks(TextRNN)[6]、FastText[7]等对文本进行特征抽取,并对全连接层进行标签集大小适应后均可以在一定程度上解决极限多标签文本分类问题,并对CNN的池化层进行修改,提出具有动态池化的XML-CNN[4]模型来提升文本语义表示;Chang等[8]引入预训练模型,提出X-Transformer提升文本语义表示。而单纯地利用深度学习提升文本语义表示仍未能建模极限多标签文本分类问题中标签的复杂共现关系,有学者考虑层级标签预测,如Peng等[9]从图的角度考虑,提出Graph CNN预测层级信息,从而解决极限多标签文本分类问题,虽然图的数据层级关联性表现更强,但由于图计算量过大,并且对数据要求较高,容易造成噪声数据传播;Francesco等[10]提出多种词嵌入组合的CNN方法,并预测标签及其所有祖先标签这种扩展层级标签方法进一步解决极限多标签文本分类问题,但由于该模型构建的标签及其祖先标签层级较深且规模庞大,导致方法复杂度过高。这类层级标签预测方法,在预测末端考虑标签层级信息时,标签语义信息利用效率不足。
综上所述,现有的极限多标签文本分类模型均未有效考虑文本标签关系复杂、低频标签建模不充分的问题,难以克服建模高噪和复杂度过高的问题。
2 方法
2.1 定义

定义2(引导标签):引导标签是一种建模了标签语义相关性的高级别弱监督语义范畴信息,其语义辐射范围下的高频标签辅助低频标签的样本学习,优化类间关系。图1中的*为引导标签,以*为圆心的圆范围为引导标签的辐射范围。
2.2 引导标签策略
本节介绍在数据集中标签集内标签存在显式层级语义关系的情况下,实施引导标签策略的方法,如图2所示,以基于TextCNN模型架构的策略为例。

图2 引导标签策略(以基于TextCNN模型架构的策略为例)
为了引入标签层级结构中蕴含的弱监督信息,引导标签策略基于标签层级结构获取文本xi对应所有标签的全部父标签,经过集成得到一个引导标签y′i。在集成过程中,对父标签集合C的语义描述进行平均池化操作,将C中所有父标签的标签描述词序列进行词嵌入得到各个词嵌入描述矩阵,再将词嵌入矩阵对应位置数值相加后取平均,得到引导标签y′i对应的词嵌入描述矩阵Ey′i,具体过程如式(1)所示。
其中,Len(C)表示父标签集合C的大小,Encode(Cl)表示对第l个父标签Cl进行词嵌入编码。
该过程中的平均池化操作不仅可以有效地从多个弱监督语义信息父标签中获取特征,保证生成的引导标签y′i语义信息丰富度,还可以有效降低弱监督信息维度,加快策略执行速度。
在得到与文本xi所对应的引导标签y′i后,策略对文本xi和引导标签y′i的描述同步进行语义映射变化。以TextCNN为例,两者同时进行卷积、池化操作,将两者池化后的输出进行向量连接,最后,经过全连接层预测文本对应的标签子集,具体过程由式(2)~式(6)进行表示。
其中,TextCNN()表示TextCNN中卷积、池化等操作的实现,WPredict表示最后一层输出全连接层权重。
从上述过程可以看出,引入引导标签策略的模型与原始分类模型对输入数据的处理流程是一致的。其区别在于,现有模型为单流输入(仅文本),在面对极限多标签文本分类任务时,难以早期感知标签关联,具有全域的标签搜索范围。而引入引导标签后模型架构为双流输入(文本和引导标签),使模型预测过程受益于来自引导标签的弱监督语义指导信息,隐式地缩小了搜索范围,用高频标签辅助低频标签数据分类学习,从而提升模型效果。
2.3 伪引导标签生成策略
在2.2节中,假定数据集中已含标签层级信息,但实际也存在数据集缺失标签层级信息甚至缺失标签描述词序列的场景。对于这种极端场景,本文提出一种启发式的伪引导标签生成策略。
当数据集中缺失标签描述词序列时,策略通过关键词抽取方法补足描述。首先,集成标签yij对应文本的所有词,得到其冗余表示词序列zj。然后,取zj中TFIDF权重最大的K个词作为标签yij的描述词序列。本文采取这种启发式的标签描述生成方法,也可结合应用采用更为复杂的描述生成方法替换。
当数据集中缺失标签层级信息时,可直接将文本对应的所有标签的描述进行式(1)中的平均池化操作,得到伪引导标签及其对应的词嵌入描述矩阵,作为弱监督语义信息,执行双流的引导标签策略进行模型训练。
2.4 模型预测
在预测阶段,会面临两种情况。第一种是待预测文本对应的层级标签集,如父标签集已知,基于该集合生成引导标签从而进行预测;第二种是待预测文本对应的层级标签集未知,本文策略需要为待预测文本生成引导标签,作为模型输入。
第一种待预测文本对应的层级标签已知的情况常见于如知乎(1)https://www.zhihu.com/、简书(2)https://www.jianshu.com/和CSDN(3)https://www.csdn.net/等论坛网站中,在上传内容前,需要先选择一个大类(可对应引导标签),内容编辑完成后,需进一步自动推荐或标记精确的标签。
第二种待预测文本对应的层级标签未知的情况也普遍存在,如新浪微博(4)https://www.weibo.com/、哔哩哔哩(5)https://www.bilibili.com/等。对此,本文在训练数据集合上进行近邻文本搜索,用近邻文本的引导标签作为待预测文本的引导标签。具体地,首先,将文本所含单词映射为词向量。其次,对这些词向量求平均,得到文本的压缩向量。最后,取与待预测文本压缩向量余弦相似度最大的训练集文本作为其近邻文本,获取引导标签。在计算两两余弦相似度时,使用贪心算法加速求解,即一旦余弦相似度数值超过某一阈值,则将此时对应文本视为最优近邻文本,停止迭代。
3 实验
3.1 实验设置
3.1.1 数据集
本文使用两个极限多标签文本分类任务数据集:Kanshan-Cup和Wiki10-31K。
之后,我们还观看了大象表演的节目——踢球、掷飞镖、画画。节目虽然很精彩,但大象真的快乐吗?我想,也许广阔的大自然才是大象最好的家。
Kanshan-Cup(6)https://www.biendata.com/competition/zhihu/data/:2017知乎看山杯机器学习挑战赛数据集,包含300万个问题文本,及其对应的1 999个标签,包含标签层级信息和标签对应的文本描述信息,是典型的短文本极限多标签文本分类数据集。
Wiki10-31K(7)http://manikvarma.org/downloads/XC/XMLRepository.html#:维基百科数据集,包含14 146个训练文本和6 616个测试及其对应的30 938个标签,未提供层级信息和标签文本信息,是典型的普适情况下长文本极限多标签文本分类数据集。
对于Kanshan-Cup数据集,本文使用词汇级别词嵌入,数据集提供了问题的标题信息和描述信息,本文对长度大于30词的标题信息进行截断,对长度大于120词的描述信息进行截断,对未达到词数的进行补0,然后将标题和描述信息连接,作为模型的输入文本数据。使用2.2节中引导标签生成策略生成引导标签词嵌入描述矩阵,作为模型的引导标签输入。对于Wiki10-31K数据集,本文将长度大于500词的文本数据进行截断,对未达到500词的文本数据进行补0,作为模型的输入文本数据。由于数据集层级信息和标签文本信息均缺失,使用2.3节提出的伪引导标签生成策略生成伪引导标签,K取100,作为模型的引导标签输入数据。表1给出了两个数据集的统计信息。

表1 实验数据集
3.1.2 评价指标


为了充分验证所提出的策略的有效性,本文首先选择TextCNN、TextRNN和FastText作为算法适应型极限多标签文本分类深度学习算法代表,其次选择XML-CNN作为先进的极限多标签文本分类深度学习算法代表,并对这些算法引入引导标签策略以验证策略有效性。虽然X-Transformer[8]引入预训练外部信息提升了方法效果,但本文更倾向于选择经典极限多标签文本分类深度学习算法进行策略引入,以客观充分地验证所提出的策略的有效性。
TextCNN[5]:用卷积神经网络抽取文本特征进行极限多标签文本分类。
TextRNN[6]:用循环神经网络抽取文本特征进行极限多标签文本分类。
FastText[7]:通过平均文本特征嵌入来构造文本表示,在其上应用Softmax层将文本表示映射到极限多标签文本分类标签集上。
XML-CNN[4]:基于卷积神经网络,将网络池化改为动态池化,用于本文任务。
3.1.4 参数设置
在Kanshan-Cup数据集中,本文使用数据集提供的词嵌入进行实验,嵌入维度为256;在Wiki10-31K数据集中,使用GloVe[14]对文本数据进行训练,得到维度为300的词嵌入。为了保证模型对比公平,所有模型训练均使用Adam[15]优化器,各模型参数均按照对应原始论文进行设置,初始学习率为0.001,在训练收敛后,使用学习率衰减进一步提升模型分数。对于引入引导标签策略的模型,本文对输入层的修改如图2所示,使单流输入变为双流输入。
3.2 待预测文本对应的层级标签已知时性能对比
首先分析待预测文本对应的层级标签已知时引导标签策略性能,在使用了待预测文本对应的层级标签已知时的引导标签策略的模型名前加上F-标志。其中,Wiki10-31K数据集的实验,利用对待预测文本的各标签描述嵌入矩阵进行平均池化来模拟层级标签以生成伪引导标签,即待预测文本的引导标签是用2.3节伪引导标签生成策略得到的,实验结果如表2所示。

表2 评价指标macro和micro性能对比(待预测文本对应的层级标签已知) (单位:%)
从表2的实验结果可以看出,在Kanshan-Cup数据集和Wiki10-31K数据集中,引入本文提出的引导标签策略后,所有模型在所有评价指标上均超过了原始模型。在Kanshan-Cup数据集上macro-P、macro-R、macro-F1、micro平均提升13.24%、8.27%、10.21%、8.62%,最高提升21.23%(macro-P,TextRNN和F-TextRNN比较),反映出在层级标签已知情况下,短文本极限多标签分类任务可以非常大地受益于本文提出的策略。Wiki10-31K数据集上macro-P、macro-R、macro-F1、micro平均提升3.56%、5.16%、4.42%、5.75%,没有Kanshan-Cup提升明显,分析其原因,可能是由于该长文本数据集文本语义表达较为充分,单文本自身语义信息已较为丰富。
图3是待预测文本对应的层级标签已知情况下评价指标P@k和nDCG@k在Kanshan-Cup数据集上的结果。可以看出,引导标签策略效果提升显著,分析其原因,可能是由于引导标签隐式地约束了标签范围,从而优化类间关系,有效提升了分类性能。

图3 评价指标P@k和nDCG@k在Kanshan-Cup数据集上的模型性能对比(待预测文本对应的层级标签已知)
图4是待预测文本对应的层级标签已知情况下评价指标P@k和nDCG@k在Wiki10-31K数据集上的结果。可以看出,除了FastText在P@1(nDCG@1)上提升不大,其余所有模型均效果提升显著,引导标签辐射范围下的长尾标签的召回率得到明显提升。
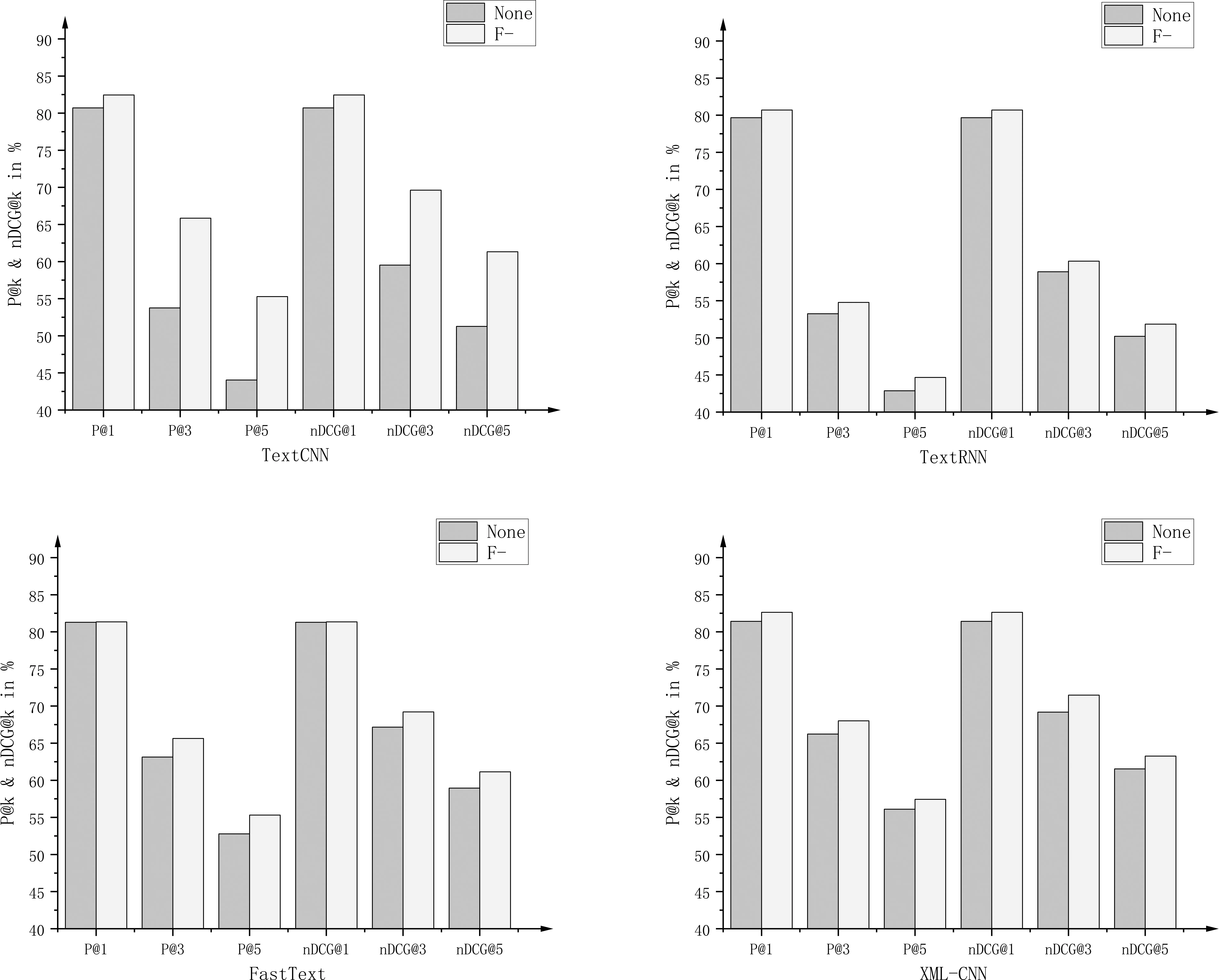
图4 评价指标P@k和nDCG@k在Wiki10-31K数据集上的模型性能对比(待预测文本对应的层级标签已知)
3.3 待预测文本对应的层级标签未知时性能对比
在使用了待预测文本对应的层级标签未知时的引导标签策略的模型名前加上SF-标志,待预测文本的引导标签是用2.3节伪引导标签生成策略得到的,SF-和F-模型上的macro和micro评价指标在Wiki10-31K数据集上的结果如表3所示。
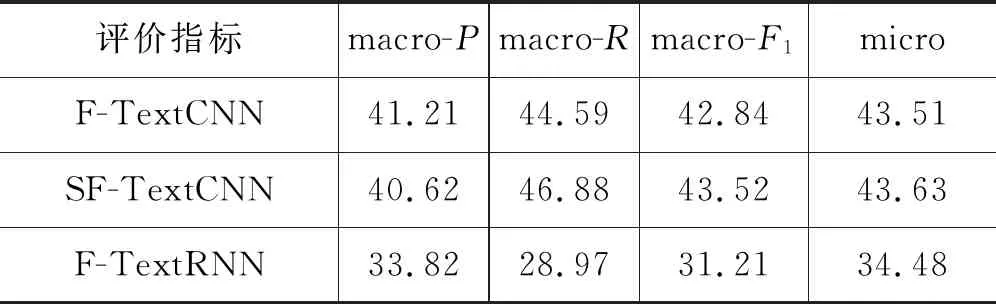
表3 评价指标macro和micro在待预测文本对应的层级标签已知(F-)和未知(SF-)时模型性能对比

续表
从表3可以看出,使用待预测文本对应的层级标签已知时得到的引导标签给模型带来的增益与使用待预测文本对应的层级标签未知时得到的引导标签给模型带来的增益相比,整体评价指标数据相近,没有明显差异。这是由于本文所建模型利用的引导标签是一种高层的较泛化的弱监督语义信息,其目的在于引入先验规约分类范畴和利用高频标签辅助低频标签语义建模,可以有效指导模型学习文本与大规模标签集间的内部隐式的局部关联,来自训练集相似文本或来自数据自身粗略标注的这种弱监督语义信息均是可行的,均能够有效提升模型性能。
图5是对原始模型、SF-模型和F-模型在P@k和nDCG@k评价指标上的实验对比评估,可以从图中清晰地看出,所有的SF-模型和F-模型均性能相当,且均超过了原始模型分数。

图5 评价指标P@k和nDCG@k在Wiki10-31K数据集上模型性能对比
对于FastText方法,使用待预测文本对应的层级标签未知时得到的引导标签(SF-)的方法略优于使用待预测文本对应的层级标签已知时得到的引导标签(F-)的方法,分析得到由于FastText的简洁结构,在使用比F-噪声更大的SF-方法时,根据奥卡姆剃刀原则,其具有着更强的鲁棒性能。
4 总结
本文提出一种利用标签层级语义信息引导的极限多标签文本分类模型提升策略,该策略简单易行,面对不同情况下的数据集均可以生成引导标签或伪引导标签为文本提供弱监督语义信息,并能够较为容易地迁移到任意极限多标签文本分类模型中,且模型性能提升效果显著。实验结果表明,本文提出的层级标签语义指导的极限多标签文本分类策略,能够有效提升现有任务模型的性能。
