基于朴素贝叶斯的在线评论文本的情感分类研究
2021-11-15袁月戎
袁月戎
(南京农业大学 信息管理学院,江苏 南京 210095)
随着社交网络的快速发展,网络已经成为我们日常生活中不可或缺的一部分。网络的普及,极大地方便了我们的生活。在进行网上购物或者浏览社交媒体平台时,很多用户喜欢在公众平台上表达自己的态度[1]。广义上的情感分析,是通过相关的算法识别出文本中能够表达情感的词语,再经过相关计算,得出该文本内容的情感倾向。这样的方法被广泛应用于客户满意度调查、市场监测等多个领域。用户评论可为其他用户的决策起到参考作用,也是开发者把握用户需求的重要信息[2]。为了探讨基于朴素贝叶斯算法在文本情感分类中的应用,本次研究以豆瓣网站上的书籍评论为分析对象,根据热门标签中文学类别下的小说分类,最终选取了路遥的《平凡的世界》和林奕含的《房思琪的初恋乐园》,对这两本书的在线评论进行情感分类研究。
1 相关概念
1.1 情感分析与情绪词典
早期的情感分析都以篇章为对象,情感只分为正负两种,后续的研究逐渐深入到语句,除了关注语句的情感极性,还进一步强调了情感程度,同时关注情感对象,甚至上下文情境[3]。随着情感分析研究的不断深入,不少学者借鉴心理学相关研究,逐渐将正负情感细化为情绪特征。在进行情感分析时融入心理学理论,促进了情绪词典的发展。在英文领域,普遍公认的是由加拿大国家研究委员会专家创建的情绪和情感词典(简称NRC),该词典具有广泛的应用程序开发,可以在多种环境中使用,例如情绪分析,产品营销,消费者行为,甚至是政治活动分析,借助NRC词典,情感分析得以更加细化。在中文领域,大连理工大学信息检索实验室中文情感词汇本体参考 Ekman 情感模型将情感分为乐、惧、惊、哀、恶、怒和好7个大类21个小类[4],该资源的宗旨是在情感计算领域,为中文文本情感分析和倾向性分析提供一个便捷可靠的辅助手段。中文情感词汇本体可以用于解决多类别情感分类的问题,同时也可以用于解决一般的倾向性分析的问题。
情绪代表着人们的主观感受与想法,人的情感极具复杂性。因此,情感分类一直都是相关研究探讨的重点。著名的普拉切克(Plutchik)情绪轮盘(如图1)。将情绪分为生气、厌恶、恐惧、悲伤、期待、快乐、惊讶、信任8个基本类型。 复杂情绪一般也都是由基本情绪派生而来,如具备“快乐”和“信任”的情感就是“爱”[4]。
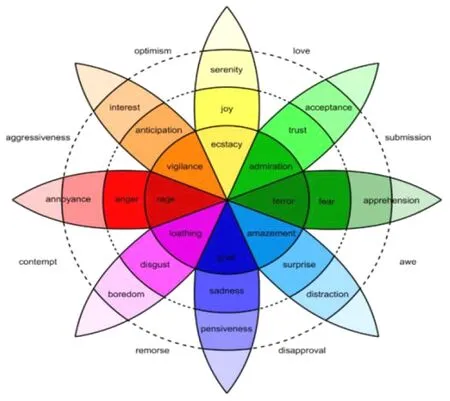
图1 普拉切克的情绪轮盘
1.2 中文情感词汇本体
“中文情感词汇本体库”是林鸿飞教授带领大连理工大学信息检索研究室全体教研室成员,整理和标注的一个中文情感词典,含有情感词汇共计27 466个。该情感分类体系,是建立在国外比较有影响的Ekman的六大类情感分类体系的基础之上的,并在其中加入情感类别“好”对褒义情感进行了更细致的划分,该情感词典中的情感共分为七大类21小类,情感强度分为1、3、5、7、9五档,9表示强度最大,1为强度最小,该情感词典的一般格式见表1。
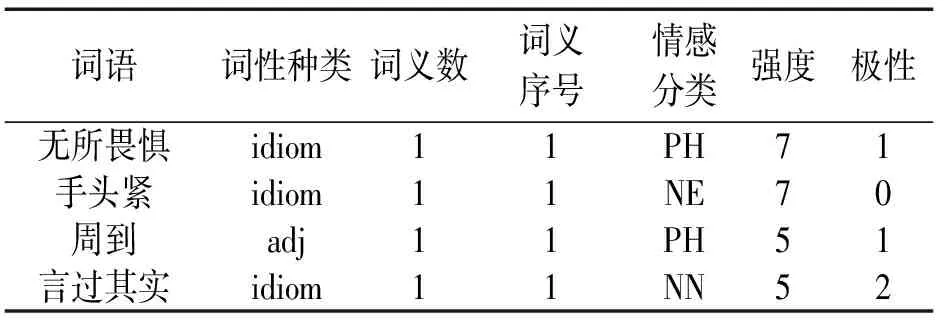
表1 情感词汇本体格式举例
关于“乐”“惧”“惊”“哀”“恶”“怒”和“好”这7 个大类 21 个小类的具体分类可见表2。

表2 情感分类
1.3 朴素贝叶斯算法
朴素贝叶斯是基于概率论的分类算法,是目前应用最为广泛的分类算法之一。概率即指一件事情发生的可能性。联合概率:包含多个条件,且所有条件同时成立的概率,记作:p(A,B)。条件概率:事件A在另一个事件B已经发生条件下的发生概率,记作:p(A|B)。相互独立:如果p(A,B)=p(A)p(B),则称事件A与事件B相互独立。贝叶斯公式:P(A|B)=P(B|A)P(A)/P(B)[5]。例如,“你在街上看到一个黑人,我们十有八九猜非洲。”在你的脑海中,有这么一个判断流程:
这个人的肤色是黑色<特征>
黑色人种是非洲人的概率最高?
<条件概率:黑色条件下是非洲人的概率>
没有其他辅助信息的情况下,最好的判断就是非洲人。这就是朴素贝叶斯的思想基础。再扩展一下,假如在街上看到一个黑人讲英语,那我们是怎么去判断他来自哪里?
提取特征:肤色(黑) 语言:英语
黑色人种来自非洲的概率:80%
黑色人种来自美国的概率:20%
讲英语的人来自非洲的概率:10%
讲英语的人来自美国的概率:90%
在我们的自然思维方式中,就会这样判断:
这个人来自非洲的概率:80% * 10% = 0.08
这个人来自美国的概率:20% * 90% =0.18
我们的判断结果就是:此人来自美国!
通过这样的计算就可以得出该问题的结果,可以看出,朴素贝叶斯算法可以通过这样的计算得出看似不具有规律或者完全不相关的一个问题的概率问题。朴素贝叶斯实际应用场景包括文本分类、垃圾邮件过滤、病人分类和拼写检查。
2 研究思路
本研究首先运用python从豆瓣读书上面去获取所需的评论数据;其次,用excel、Notepad++对文本数据清洗和预处理,文本清洗包括了标点符号的去除、人工筛选等,预处理包括了文本分词;然后,运用大连理工大学标注的中文情感词汇本体库提取表达用户情绪特征的词语,对评论中的内容进行情感词语的抽取和情感分析,抽取的内容主要是评论文本中带有倾向性特征的词语;最后,根据上文所述的情感词典,计算出每条评论的情感综合值;最终确定该评论属于中文情感词汇本体七大类中乐、好、怒、哀、惧、恶、惊下的具体哪一类。最终对这些产生结果的评论采用朴素贝叶斯算法,对情感倾向进行分类(如图2)。
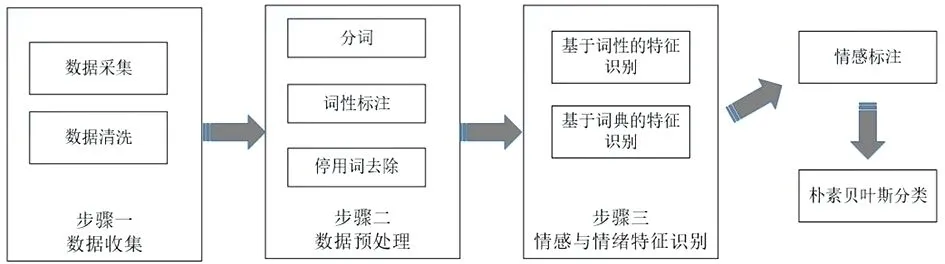
图2 研究思路
3 数据收集及预处理
豆瓣网是国内知名且用户数量较多的网络评论社区,它包含了书籍、电影等多个评论版块,是一个理想的研究对象。豆瓣读书上的读书板块收录了很多的国内外书籍数据,并有大量用户对上面的书籍进行评价,因此选择豆瓣读书上的相关评论为研究对象。
采用python爬取豆瓣读书中《平凡的世界》和《房思琪的初恋乐园》这两本书的用户评论,截至2020年2月1号分别采集到了33 810和28 295条数据,获取的原始数据十分混乱,每条数据包含一些xml标签,并且有各种无意义字符,笔者使用notepad++和excel等工具对这些数据进行整理清洗,去除了只有数字、表情包、无内容和不相关评论的文本,得到的有效数据分别是33 676、27 284条。在完成简单的数据清洗后,又对采集到的数据进行了预处理,包括jieba分词、词性标注以及停用词去除,最终得到的数据如图3所示。

图3 数据收集与预处理
4 情感与情绪特征识别
将上述清洗过的数据与中文情感词汇本体中的词语进行匹配,逐条分析每句评论中出现的情感词,并利用notepad++和excel等工具进行特征词统计(如图4)。
图4 评论词语与词典匹配
5 情感标注
本研究采用基于词典和有监督的机器学习的方法进行结合,采用大连理工中文情感词汇本体进行情感分析,用该词典统计待分析文本中每句评论表达“乐”“好”“怒”“哀”“惧”“恶”“惊”这7个情感词的强度的加权值,取最大值来表达这句话的情感趋向。最后得出的结果分别用A、B、C、D、E、F、G来表达,其中H表达该句没有情感特征词,即判断不出该句的情感趋向(如图5)。
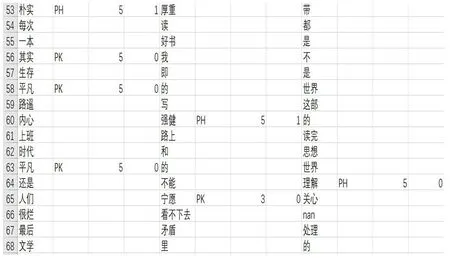
图5 文本情感标注
单个词语情感的标注如图5所示,通过对一句话中相同情感的情感值进行加权,比较每种情感值的大小,最后选取数值最大的情感词来代表该句话的感情趋向(见表3)。
表3 情感类别计算
6 实验结果与分析
根据乐(A)、好(B)、怒(C)、哀(D)、惧(E)、恶(F)、惊(G)、无(H)这8种情感值对该书评论进行统计(如图6)。
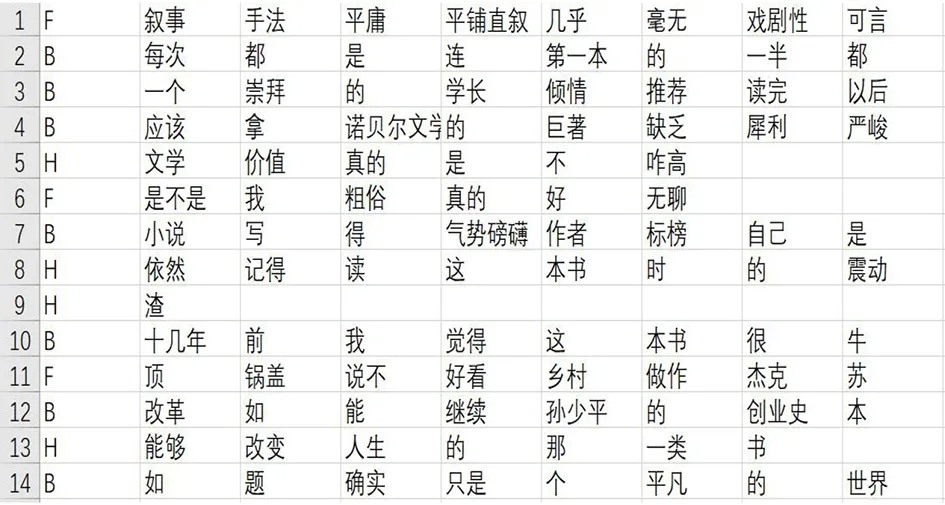
图6 文本情感倾向性分析
对每条评论进行情感倾向统计分析(如表4)。
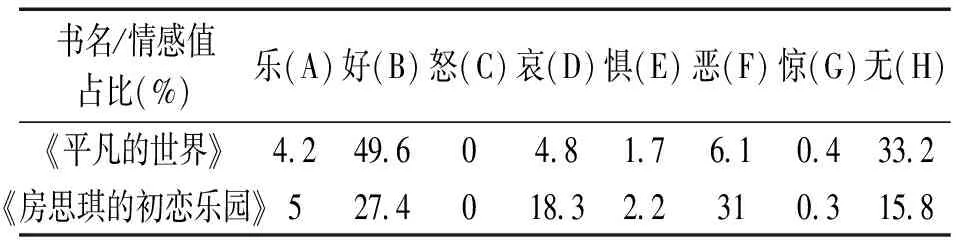
表4 中文情感词典标注结果
从统计数据上看,《平凡的世界》一书中情感值有高到底依次是:好(49.6%)、无(33.2%)、恶(6.1%)、乐(4.2%)、哀(4.8%)、惧(1.7%)、惊(0.4%)。用户对该本书的情感为好的占到了49.6%,其次是“无”到了33.2%,说明大多人对该本书的情感态度大多都为好,很少有其他的负面情感。而《房思琪的初恋乐园》一书中情感值有高到底依次是:恶(31%)、好(27.4%)、哀(18.3%)、无(15.8%)、乐(5%)、惧(2.2%)、惊(0.4%)。用户对该本书的情感为好的只占到了27.4%,其余的几乎都是恶、哀等负面情绪,说明用户在看这本书的时候都是怀着一种愤怒并且悲凉的心态。分析其具体原因,用户的情感可能会受到书的主题内容的影响,《平凡的世界》主要讲述的是中国20世纪70年代到80年代中期普通人在大时代历史进程中所走过的艰难曲折,在大时代的背景下普通人的奋斗故事容易引发读者共鸣,产生的情感也大多是正向的,充满正能量的。《房思琪的初恋乐园》的主题是性侵,这一内容本就会引发大众的抵触情绪,读者可能大多数都在讨论书中塑造的人物,表达自己的愤怒和不满,而忽略了作者的写作能力和写作手法。通过分析可以观察出:读者评论的情感倾向可能会受到书籍主题的影响。
在对所有评论进行情感倾向计算后,运用朴素贝叶斯的分类方法,将计算好的评论按照3∶1(训练集∶测试集)进行运算,最后训练出朴素贝叶斯模型,将评论进行分类(见表5)。其中,准确率:判断正确的类别数目与判断为该类别的数目之比;召回率:判断正确的类别数目与应判断为该类别的数目之比;F 值:作为前两者的调和平均数来衡量评估分析的准确性,F=2PR/(P+R)。通过对比发现,该算法对“乐”的情感判断,效果较好,准确率和召回率都较高。好(A)的准确率分别达到了0.72、0.81。准确率较高的还有哀(D)和无(H)这两个情感,相较于用词典标注的结果,朴素贝叶斯算法的准确率还有很大的提高,尤其是好(B)这一情感,在标注的结果中占比最高,运用朴素贝叶斯的算法准确率和召回率还有待改进。这是因为分类效果的好坏,跟所采用的情感词典有很大关系,词典中包含的该类别的情感词越多,覆盖范围越广,就越能够从读者评论中提取到更多的情感特征,从而才能够准确把握该书评的总的情感倾向,才能够获得更加准确的分类效果。

表5 自动分析结果
最终,我们运用朴素贝叶斯算法对豆瓣网上书评进行分类,分类效果(见表6),训练集的准确率都在70%~80%这一范围,测试集的准确率都在60%~70%这一范围。研究发现,朴素贝叶斯算法能够实现评论文本的情感分类,分类效果较好,但仍需结合规则匹配和人工校对的方式,提升分类效果。后期也可以优化情感词典,扩充情感词典中的与本领域相关的情感词,提高书评情感倾向分析的准确度。

表6 分类效果
7 总结与讨论
研究发现,朴素贝叶斯算法能够实现评论文本的情感分类,分类效果较好,但仍需结合规则匹配和人工校对的方式,提升分类效果。另外本次研究没有自己建立针对书评的情感词典,采用的是通用的中文情感词典。可能会因为个别的评论只有几个字,或者个别情感词在词典中找不到,可能在情感分类时略有误差,不能精确把握每句话总的情感倾向。这样一来,就会导致在情感值计算的时候匹配不到相关的情感词,最后无法得到这部分的得分,这样的数据就存在无法判断的问题。此外,本次研究抓取选取的数据全部来源于豆瓣网,用来分析的书籍只有两本,选取的数据量还不够多,因此在后面的研究中,怎样去选择更加合适的研究对象值得我们进一步去考虑。
