无资料流域径流模拟预测研究进展综述
2021-11-15罗军刚解建仓
杨 雪,袁 丹,罗军刚,张 晓,魏 娜,解建仓
(1.西安理工大学 西北旱区生态水利国家重点实验室,陕西 西安 710048;2.西安理工大学 水利水电学院,陕西 西安 710048)
径流预测研究不仅能够有效帮助掌握河川径流的变化特征、趋势和规律,为水资源合理配置、优化流域水量调度、水资源保护、水资源规划与管理提供科学依据,也能够为提高水资源利用率、水利工程防洪、抗旱、发电提供可靠指导。因此,径流预测具有重要的理论及现实研究价值。目前而言,水量预测主要依据水文模型,通过流域的历史水文监测信息进行模型训练,基于训练结果实现水量预测。然而,我国水文站网平均密度偏低,缺少水文监测资料的区域较多,水文模型应用受阻。因此,开展无资料流域水量预测研究意义重大。
本文将依据国内外研究成果,结合自身的科研体会,回顾当前国内外关于无资料地区径流过程模拟预测问题的研究进展,分析存在问题,展望未来研究,旨在为无资料地区径流模拟预测研究提供借鉴和参考。
1 概 述
中国是世界上洪涝灾害最严重的国家之一,大约2/3的国土面积、80%的耕地受到洪水的威胁[1]。据我国应急管理部及水利部统计,仅2020年上半年,因洪涝灾害造成的直接经济损失就高达393.1亿元,受灾人数达1 770.7万人次。合理开发、利用水资源并减小水灾害损失,提高水资源的管理效率是当前重要的非工程措施[2]。此外,考虑气候变化对水资源及水灾害的潜在影响,2020年联合国发表的世界水发展报告(UNWWDR2020)《水与气候变化》也强调了改善水资源的管理是增强抵御气候变化带来的挑战的一种潜在解决方式。
科学高效的水资源管理前提是充分掌握本流域水资源状况,了解区域水资源时空变化规律[2]。然而,根据国际水文科学协会(IAHS)的报告,由于各种自然条件与人为因素的限制,全球大部分的流域缺乏监测的水文数据[3]。我国也不例外,总体水文站网平均密度不高[4],低于世界气象组织(WMO)推荐的相应地形类的最稀流量站网密度标准[5]。为了对全国的水资源与水灾害有全面、细致的了解和掌握,以改善管理效率,我国也快速地响应了IAHS提出的针对无资料流域水文预测(prediction in ungauged basins,PUB)这一具有挑战性问题的研究计划,明确了PUB也是我国水文研究亟需解决的科学问题[6]。
受PUB研究计划推动,无资料流域水文模拟预测得到了更多的关注,在国内外积累了众多成果。这里需要特别注明,无资料流域在本文中是指缺失流量监测的流域。径流过程模拟预测是流域水资源管理的重要基础,本文将围绕该主题的PUB研究方法进行研究综述。
2 PUB研究方法
水文模型是当代最常用的径流模拟方法[7],而水文模型中存在没有水文特定含义或者不可直接测得的参数,模型需要依据监测的流量数据率定模型参数,进而实现径流过程的模拟与预报[8-9]。面对无资料流域模型参数无法直接率定的困境,研究人员目前最常用对策是“借米”的方式[10],称为区域化方法。通过方法的分解分析,用“借米”方式实现无资料流域水文过程模拟主要为解决以下三个问题。
1)借“什么米”?
2)向谁借“米”?
3)如何使用借来的“米”?
本章将通过回答这三个问题,引导读者实现无资料流域径流的模拟预报。
2.1 借“什么米”?
“米”即可以帮助实现无资料流域径流预报的信息。目前研究中所借“米”的类型包括两种:模型参数;模型参数与流域特征指标的回归关系。
2.1.1模型参数
“借”模型参数是最直接的区域化方法,因为无资料流域缺少用来率定模型参数的流量数据,水文模型参数无法直接获取。“借”用模型参数,直接解决了无资料流域模型参数缺失的困境,其假定是模型参数能够反映水文响应特征,并且相似流域的模型参数可移植。
吴碧琼等[11]为了实现无资料的西充河流域的径流模拟,便直接移用了相近的李子溪流域的BTOPMC模型参数,验证了该方法的适用性。
2.1.2回归关系
“借”回归关系,是指借用模型参数与流域特征指标的回归关系。“世界上没有一片相同的叶子,也很难找到完全相同的流域”。回归法既考虑无资料流域的自身特性,也考虑了与其他相似流域水文响应的共性特征,因此成为了目前全球最流行的PUB研究方法[8]。回归法的假定是:模型参数与流域特征存在相关性;该相关性在一定空间内可移植[12]回归法的表达形式为:
MPi=fi(CD1、CD2…CDs)
(1)
式中:i=1,2,…,m;MPi为第i个模型参数;fi为该模型参数与流域特征指标CD1、CD2…CDs的关系方程;m和s分别为模型参数与流域指标的总数。
在柬埔寨的洞里萨湖,徐长江等[13]在9个典型流域构建了率定的模型参数与6个气候及下垫面特征的因子的回归关系,实现其他3个无资料流域的月径流模拟。
2.2 向谁借“米”?
向谁借“米”,即如何选择无资料流域的参证流域,参证流域数量可以不止一个,选择依据是水文响应特征相似。目前常用的方法包括空间邻近法、流域特征相似法和相似流域分区法。
2.2.1空间邻近法
空间邻近法的基本假定是水文响应特征具有空间连续性,距离相近的流域水文响应特征更相似[14]。参证流域的选择依据主要是Euclid距离公式:
(2)
式中:xt、xg和yt、yg代表目标无资料流域和有监测资料流域的地理坐标。根据目标流域与有监测资料流域的空间距离大小,依据距离最小原则确定借“米”对象。
1976年Egbuniwe和Todd[15]已经通过空间邻近法获得Stanford模型在无资料流域的参数,最终实现了无资料流域的水文模拟并取得了不错的模拟效果。
2.2.2流域特征相似法
流域特征相似法假定流域气候及下垫面条件相似,则水文响应呈现相似特征[14]。判断流域水文相似性的指标在不同研究中的表征方式不同,所用到的气候及下垫面条件的表征指标也受到研究人员的主观判断及掌握资料的情况影响,见表1。表1中SIug为流域相似判定指标,s为参证流域数量,m为特征指标总量,i表示第i个特征指标,j表示第j个参证流域,wi为第i个特征指标的权重,CDu,i为目标流域的第i个特征指标,CDg,i为参证流域的第i个特征指标,ΔCDi=CDmax,i-CDmin,i,其中CDmax,i和CDmin,i分别表示第i个特征指标的最大和最小值(不包含目标流域),σi是第i个特征指标的标准差。
为了实现西北内陆河流域无监测资料地区石羊河流域的水资源管理,赵文举等[23]采用流域特征相似法通过衡量水文相似度,以西营河为参证流域,将其模型参数移植到目标金塔河流域,结果分析表明径流的模拟结果可以满足应用需求。
2.2.3相似流域分区法
相似流域分区法假定组内区域的水文响应方式是均一的[24],认为单个模型结构能够用于描述一类流域的变异性,且组内流域的水文模拟可以使用同一组模型参数。该方法主要依据流域的物理特征指标,通过分组方法判断流域相似分区,属于该分区内的无资料流域可直接使用该分区内统一的模型参数进行径流模拟。
最常用分组方法是聚类法,方法的区别在于如何定义分组以及使用哪种信息[25]。例如,Thoms和Parsons[26]考虑了日均径流、月均径流及多年滑动平均年径流等7种指标类型采用多元分析方法将澳大利亚的Condamine-Balonne地区分成了6组,认为同一组内的流域具有相同的水文响应模式。而Monk等[27]则从径流的量级和形状指标两个方面使用分层的聚类分析法将英国的83个流域分成了10组。
2.3 如何使用借来的“米”?
我们已经回答了实现无资料流域水文过程模拟的两个问题,也明确了通过这两个问题确定的信息,见图1。根据“借”到“米”的来源及类型,使用的方法也不尽相同,本文按照参证流域数量,结合“米”的类型进行“使用米”的方法梳理。
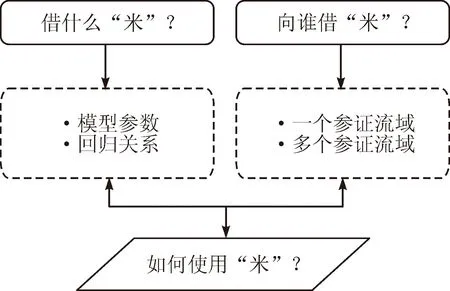
图1 PUB研究的三个比拟问题及相互关系Fig.1 Three questions and the relation in PUB
当参证流域只有一个时,因为一个参证流域信息无法确立回归关系,故“借”用信息-“米”为其模型参数,其使用方式为直接将其参数移用至目标无资料流域。例如,吴碧琼等[11]在无资料的西充河流域的日径流过程模拟研究中直接移用了水文相似的有资料的李子溪流域模型参数,并且模拟结果良好。
当参证流域多于一个时,其“借”用信息-“米”既可以是模型参数,也可以是回归关系,使用方式包括参数平均、结果平均、区域模型参数和区域回归关系四种方法。
2.3.1参数平均
参数平均是使用空间邻近或流域特征相似确定多个参证流域时,最早也最常用的方法。即,无资料流域的模型参数是所用参证流域的参数平均值[8],见式(3)。
(3)
式中:MPu,i为无资料流域的第i个模型参数;MPg,k,i为第k个有资料参证流域的第i个模型参数;wk是第k个有资料参证流域对应的权重系数,n为选择的参证流域的总数,即“借米”对象的总数。
使用该方法实现径流PUB研究的过程为:通过平均参数得到无资料流域的模型参数,结合目标流域的降水、温度等模型的驱动数据,使用在有监测资料流域验证通过的水文模型便可以实现相应的径流模拟。
该方法在国际上得到了广泛的应用,例如,Bao等[28]在我国55个流域通过耦合区域化方法与水文模型Akaike Information Criterion (AIC)以实现无资料流域径流模拟,该研究便使用了多个参证流域模型参数组去推求无资料流域的径流模拟预报。在高纬度的湿润地区的118个流域上,Yang等[17]通过十几种区域化方法耦合WASMOD的方式的比较,发现使用多个参证流域的模型参数组去推求无资料流域的径流模拟预报具有较好的模拟效果。
2.3.2模拟结果平均
模拟结果平均也是用于使用空间邻近或流域相似确定多个参证流域的情况,是为了减小“异参同效性”影响,于近期由McIntyre等[29]提出的新方法。该方法实现无资料径流模拟的过程为:先在无资料流域分别使用参证流域的参数组得到相应的模拟序列,最后将这些模拟序列进行平均(包含使用不同的权重),其结果即为无资料流域的模拟结果。
我国目前关于此方式的研究较少,依据Oudin等[9]在法国913个流域上的研究,其依据空间邻近法及流域特征相似法分别确立了参证流域,进而使用参数平均法与模拟结果平均法两种方式对无资料流域的径流进行了模拟,通过比较评估无资料流域的径流模拟结果,发现模拟结果平均法不比参数平均法差。
2.3.3区域模型参数
区域模型参数是当使用相似流域分区法时,同一分区内所有流域共享的一组模型参数,属于同一分区的无资料流域径流模拟可以直接使用该模型参数组。
区域模型参数既可以是组内某一流域的优化参数组,但通过验证,该组参数能够使所有流域的模拟结果满足要求。如Yang等[17]通过逐一验证分组内各流域模型参数组,以所有流域的综合模拟最优为目标,确定了能够适用于该区域的模型参数组,发现使用区域模型参数实现无资料流域的径流模拟是可行的。在我国,吴国群等[30]通过于模糊聚类法将新安江流域内12个有监测资料的子流域按照相似度分为两组,然后分别在两组内假定两个子流域为无资料流域,直接移用组内其他相似流域的模型参数进行了径流模拟,结果发现模拟误差在规定的许可误差范围内。
区域模型参数的另一种确定方式为多目标率定法,即目标参数设置为使区域内所有流域的模拟结果总体达到最优。如Huang等[31]在5个气候分区内通过同时率定所有流域的方式,得到了区域内统一的可行性模型参数组。
2.3.4区域回归关系
区域回归关系也是基于相似流域分区法,该方法中无资料流域的模型参数将通过在流域分区内所有流域信息构建的回归关系(式(1))与目标流域的相应特征指标计算得到。
Merz和Blöschl[32]在奥地利的308个流域通过构建不同空间尺度的模型参数与流域特征指标的回归关系,以探索流域分组尺度对无资料流域径流模拟的影响。结果发现在相对较小的空间区域内构建回归关系可稍微提高无资料流域的径流模拟效果,因为在较小的空间区域内,流域之间具有较高的相似性,构建的回归关系能够更好地体现该区域特征。
基于以上区域化方法及其过程的描述,我们发现区域化方法最重要的作用是为了给无资料流域寻找水文模型对应的参数。当模型参数被获取后,采用与监测资料流域相同的水文模型模拟过程便可以实现无资料流域的水文模拟。
3 分析讨论
区域化方法是应用最广泛的无资料流域径流预测方法,其核心思想是“找相似”。“找相似”的过程即确定向谁“借米”的过程,根据不同的假定及相似评判指标,模拟效果也不尽相同。
3.1 空间邻近法
空间邻近法因对流域的资料需求少,具有一定的理论基础且模拟结果基本可接受,得到了较多的应用和研究。
受流域面积、水文站网密度等条件的影响,直接使用最近流域的模型参数至无资料的目标流域,模拟结果存在较大的不确定性。因此,有学者提出“借”用多个邻近流域信息的方式改善模拟结果,该提议已被众多研究所采用和推荐[16]。然而,“多个”是多少个?由于研究的区域特征、数据密度及模型选用的不同,不同研究中的数量并不相同。例如,Oudin等[9]基于法国913个流域信息发现使用3个和6个邻近流域信息能够使基于结果平均算法的PUB模拟结果达到最优;而Yang等[17]基于挪威118个流域信息发现通过平均7个邻近流域的参数或平均4个邻近流域的结果信息能够使空间邻近法耦合WASMOD模型达到PUB模拟的最优结果。那么,最优参证流域数量具体受哪些因素影响?影响的特征是怎样的?是否具有空间区域特征呢?类似这样的问题尚未得到足够关注,需要进一步研究。
虽然空间邻近法只考虑了空间距离的因素,但根据英国学者的研究,空间邻近法对于水文站网密度大,气候和地形变化不大的区域该方法能够达到不错的模拟效果[29]。然而,该结论是基于相对湿润地区,在相对干旱的地区尚且缺乏验证。
3.2 流域特征相似法
流域特征相似法因为考虑了更多流域的特征信息,具有更好的理论基础,故比空间邻近法的应用研究更多,并且诸多研究结果表明流域特征相似法是其研究区域内的最优区域化方法[28]。
虽然流域特征相似法已有了众多研究及应用,但如表1中所列研究,该方法中相似程度的判定方式、考虑的流域特征信息选择相对主观,缺乏统一的标准[14]。因此,探究相似度判定方程及流域特征信息对模拟结果的影响,不仅能够为未来该领域研究提供重要参考信息,还能帮助开展已有结果的联合分析,以探索更大空间尺度上方法的适用性特征。
另外,虽然该方法已被较多研究验证了可行性,但关于流域特征相似法假定的合理性,一些研究者提出了质疑。例如,Oudin等[33]比较了基于水文相似法和流域特征相似法的参证流域,结果显示两种方法确定的参证流域只有60%的交叉,说明依据流域特征相似推求水文相似的假定存在一定的不合理。该问题的研究提醒我们,需加强无资料流域研究方法的理论基础,如探究控制流域水文响应特征的主要流域特征因子及其影响规律。
3.3 相似流域分区法
相似流域分区法认为同一区域(分组)内的所有流域存在相同的水文响应,该水文响应可通过相同的模型参数组或相同的区域响应关系描述。
相似流域分区法的核心是确定相似区域边界,那么,什么方法能有效地确定相似区域边界?该问题在PUB研究尚未有统一的答案。例如,李珂等[34]依据模糊聚类分析法实现了秦岭北麓部分区域的水文相似性初步分区;姬海娟等[35]依据K-Means聚类分析法实现了雅鲁藏布江流域的水文分区并论证了分区结果的合理性。不同分类方法在研究中得到了应用验证,但方法选择如何影响结果的合理性、方法之间是否存在明显差异性等问题目前研究存在一定不足,仍需进一步探索。
另一方面,如流域特征相似法的研究困境相同,相似流域分区法中流域特征信息选择也相对主观,缺乏统一的标准。如李珂等[34]在秦岭北麓部分区域的水文相似性初步分区研究中考虑了多年平均洪峰模数、多年平均最小流量模数、径流系数、地貌类型及土地利用占比等5类信息;而姬海娟等[35]在雅鲁藏布江流域的水文分区研究中采用主成分分析法,构建了基于降水、蒸发、高程、坡度、日均降雨、日均径流深、多年平均径流模数、多年平均径流系数及土地利用占比等9类信息的主要聚类因子。因此,研究流域特征信息选择对分类结果的影响,及不同区域内流域特征信息的对水文相似性的贡献差别对区域水文过程的理论研究具有重要价值。
综上,虽然以上方法已经被广泛应用于全球诸多研究中,但是关于方法的适用性边界、相似指标选择及分区方法的影响等问题尚且缺乏综合的分析研究,方法等相关选择仍较主观。如许崇育等[36]所述:“PUB研究在相当长的一段时间内仍是水文研究的重点和难点之一”。
4 展 望
通过回顾、分析无资料流域径流模拟过程研究,结合我国当前的研究现状,建议我国的PUB研究可以在以下一些方面做进一步研究。
1)应发展比较水文学思想,加强多站点、多模型及大尺度的无资料流域研究,以探索方法的适用性边界问题。对比国内外关于区域化方法的应用,国内研究相对分散,研究区域尺度较小,所含站点的嵌套关系严重,对较大尺度,如区域的研究较少,尚未形成系统的关于各方法的区域性适用性研究及结论。
2)应加强我国相对干旱地区的无资料流域水文预报水文预测研究。基于我国站点分布的地域分布不均的地域差异:西北(半)干旱区不仅监测站点密度低于东南地区,水文模拟的精度也相对较低,为落实黄河流域“量水而行”的发展原则,需要加强西北较干旱地区研究。
3)应关注无资料流域水文预测的气候变化响应研究。随着气候变暖,人类活动加剧等因素对水文循环的影响,根据水文手册的查阅结果进行洪水设计显然存在一定风险。例如地区经验公式法中重要流域特征指标的选择是否会发生变化?气候变化及人类活动对构建的地区经验公式是什么样的影响?该影响在不同类型的区域有什么不同和联系?类似这样的问题都值得我们进一步探讨。
