基于ISODATA的实时动态电动汽车运行工况与耗电特性研究
2021-11-15李广玮王昕扬
李广玮 吴 鸣 王昕扬 徐 毅
1(上海电力大学 上海 200082) 2(中国电力科学研究院 北京 100192)
0 引 言
随着我国经济的快速发展,城市汽车数量逐渐增加[1-2],在面临能源紧张和环境污染问题的前提下,新能源汽车的发展成为了未来交通出行的趋势。针对电动汽车的实际行驶工况进行研究,对确定电动汽车负荷的耗电量、新能源汽车技术开发[3]、充电站规划配置[4]、电动汽车充电导航具有重要意义。目前我国汽车行驶工况参照的是欧洲ECE城市工况,与实际行驶状态差距较大[5],已不能满足我国车辆开发测试的需求。针对这一问题,我国学者已经先后建立了区域性汽车工况,但主要是针传统汽车工况,所使用的方法是K-均值聚类(K-Means Cluster)分析法[6-8]。由于电动汽车与传统汽车的驱动方式不同,二者在速度响应、加速度和扭矩响应等各方面有较大的差异[9],采用传统汽车工况评价电动汽车续航、能耗等特性缺乏一定的合理性。除此之外,K-Means方法聚类需要人为选定类的数量,人为判断聚类结果是否合理,会对聚类效果合理性产生影响。
因此,本文选用迭代自组织数据分析算法(Iterative Self Organizing Data Analysis Techniques Algorithm,ISODATA)[10]构建电动汽车代表性工况,因为ISODATA具有归并和分裂等机制,是一种非监督的算法,有效避免人为判断聚类效果的不合理性。本文使用ISODATA、PCA[11]和运动学片段分析法[12]等方法,对电动汽车行驶数据进行分析和聚类,利用Silhouette函数对ISODATA聚类结果的合理性进行评估。根据聚类结果筛选运动学片段,构建电动汽车的代表性工况,通过测试数据集,计算了代表性工况与测试数据的差异率,并对合理性进行验证。在代表性工况的基础上,分析了电动汽车的耗电特性与剩余电量的实时评估方法。
1 电动汽车道路行驶工况构建与耗电估算方法
本文对电动汽车代表工况与耗电估算的研究基于电动汽车的实时采集数据。由于采集设备、外界因素和人为驾驶等原因,原始数据存在不良数据或缺失信息,因此首先需要进行数据预处理。在对数据进行预处理后,采用PCA进行特征降维以便达到更好的聚类效果。ISODATA能够自主的调节聚类的类别个数,属于无监督算法,能够减少人为判断分类个数的误差。根据ISODATA得到分类结果,构建电动汽车的道路行驶工况曲线,并实现电动汽车耗电的实时估算。
2 数据预处理
2.1 牛顿插值法补足数据
由于建筑物覆盖、隧道遮掩等,采集信号丢失,造成数据时间不连续,需要采用牛顿插值法补全数据[13]。首先对日期数据进行转换,转换成时间序列,检测时间序列异常的点,对于采集信号问题产生的短间隔时间不连续数据区间,插值节点为等距节点,使用牛顿等距插值法进行数据填充,插值节点为:
xk=x0+tht=0,1,…,n
(1)
式中:h代表步长,本文步长为1。在x处的牛顿等距插入值f(x)表达式为:
f(x)=P(x0+th)+Rn(s)
(2)
式中:Rn(s)是函数f(x)在x0+th处的插值余项,代表插值误差。
(3)
(4)
式中:ΔnF0代表f(x)在tk-m+j处的m阶前向差分,j=0,1,…,m。
(5)
2.2 不良记录处理
由于采集设备和驾驶人员的原因,常会产生一些不良数据。因此需要对原始数据进行甄别,不良数据类型包括:
(1) 加减速异常数据(电动汽车0~100 km/h加速时间大于7 s,刹车最大减速度不超过8 m·s-2)[14]。
(2) 长期停车异常数据(停车不熄火、汽车熄火采集设备仍运行)。
(3) 堵车、断断续续低速状态,视为怠速状态。
(4) 怠速超过180 s,视为异常状态。
不良记录数据处理步骤:
步骤一由时间序列和GPS速度已知,可得到汽车加速度的数据,剔除超出阈值的数据。
步骤二断断续续低速行驶情况,重新赋值GPS速度为0。
步骤三将补充完整的数据进行异常怠速和长期停车检测,检测GPS速度连续为0或者怠速时间大于180 s,剔除以上异常数据。具体流程如图1所示。
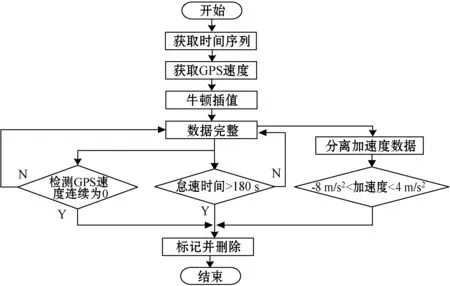
图1 预处理流程
经过数据预处理后的数据速度-时间关系和加速度-时间关系如图2和图3所示。
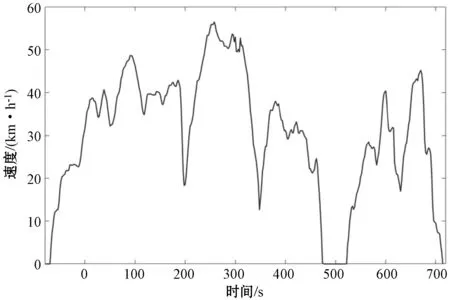
图2 部分速度-时间关系
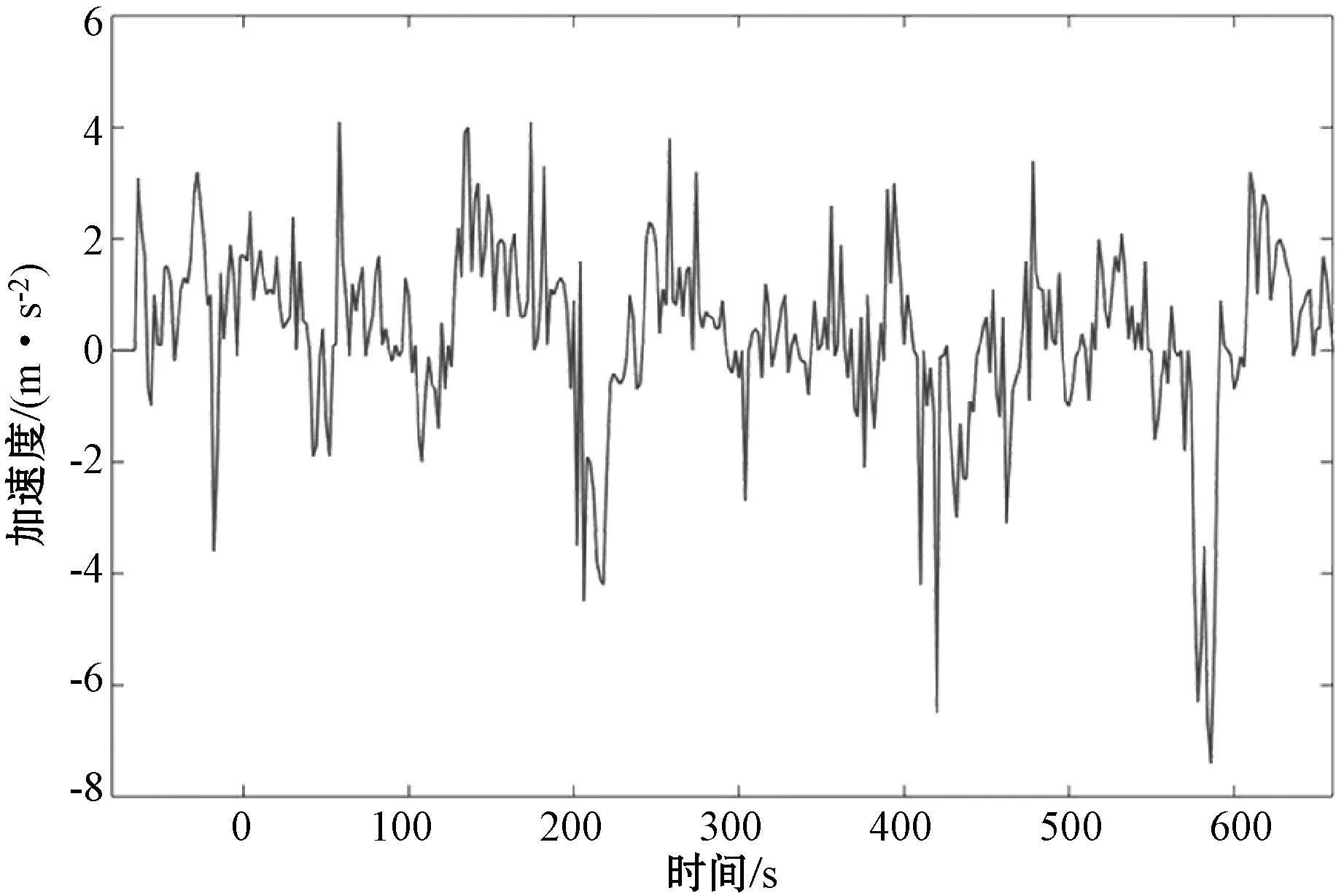
图3 部分加速度-时间关系
3 数据分类
3.1 运动学片段和运动特征
运动学片段指的是汽车行驶过程中,两次怠速状态之间的时间速度分布片段[15]。本文采集数据所提取的部分数据运动学片段如图4所示。

图4 部分运动学片段
在汽车行驶过程中,需要选用一些基本的特征参数反映每个运动学片段的行驶特征。将采集数据源分割成297个运动学片段并计算各运动学片段的15个参数。原始数据转换后,通过15个参数计算得到用于描述运动学片段的7个特征参数,如表1所示。

表1 用于描述运动学片段的7个特征参数
3.2 基于主成分分析(PCA)的数据降维模型
主成分分析是一种特征降维方法[16-17]。将原有的X1,X2,…,XP(比如P个指标)的特征转换为新的特征组Fm来表征[18]。相比之下,Fm维数低且不关联。
F1表示原特征参数进行线性组合得到的第一个主成分,F1=∂11X1+∂21X2+…+∂p1Xp。方差越大,F1能够表征的信息越多[19]。
如果F1无法表征原来P个指标的信息,考虑选取第二个主成分指标F2。F2与F1要保持独立、不相关,协方差Cov(F1,F2)=0,F1,F2,…,Fm为原变量指标X1,X2,…,XP第1、第2、…、第m个主成分。
F1=a11X+a12X2+…+a1pXp
F2=a21X+a22X2+…+a2pXp
⋮
Fm=am1X+am2X2+…+ampXp
(6)
通过对297个运动学片段的特征参数进行主成分分析,得到如表2所列的主成分贡献率及累积贡献率。

表2 主成分贡献率
由表2可知,前4个主成分的累积贡献率97.24%,其中前3个主成分的累积贡献率已经达到91.229 3%,且特征值都大于1。因此,选取前3个主成分足以反映出7个特征参数的大部分信息[2]。
3.3 利用迭代自组织数据分析算法对运动学片段聚类分析
ISODATA是一种改进型的非监督聚类算法。通过设置初始参数K0和每类最小样本数Nmin,引入合并和分裂机制。该算法具备自动判别类别个数是否合理并合并或分裂族群的功能。
当两类的中心过小,可以合并为一类。当样本数目过多或距离某类标准差过大,就会将该类分裂。
根据初始类簇中心和类的初始参数K0迭代计算,最终确定分类结果和最终结果的类别数K[20]。
通过ISODATA将数据分类到不同的类,同一类中的对象有很大的相似性,而不同的类之间的对象有很大的相异性。对于样本数据集S={S1,S2,…,Sn}。ISODATA最终将其划分成K类,表达式为P={P1,P2,…,PK},1≤K≤n。
ISODATA的基本步骤描述如下:
步骤1随机选取K0个样本,作为初始中心。
步骤2针对每个数据,计算它到中心的距离,将其分到距离最小的类中。此时类的数量为K1。
步骤3判断上述每个类中的元素数目是否小于Nmin,如果小于Nmin则丢弃该类。令K1=K1-1,该类中的样本按照距离最小原则,重新分配到剩下的类中[21]。
步骤4按照每一类的数据,重新计算该类的聚类中心。
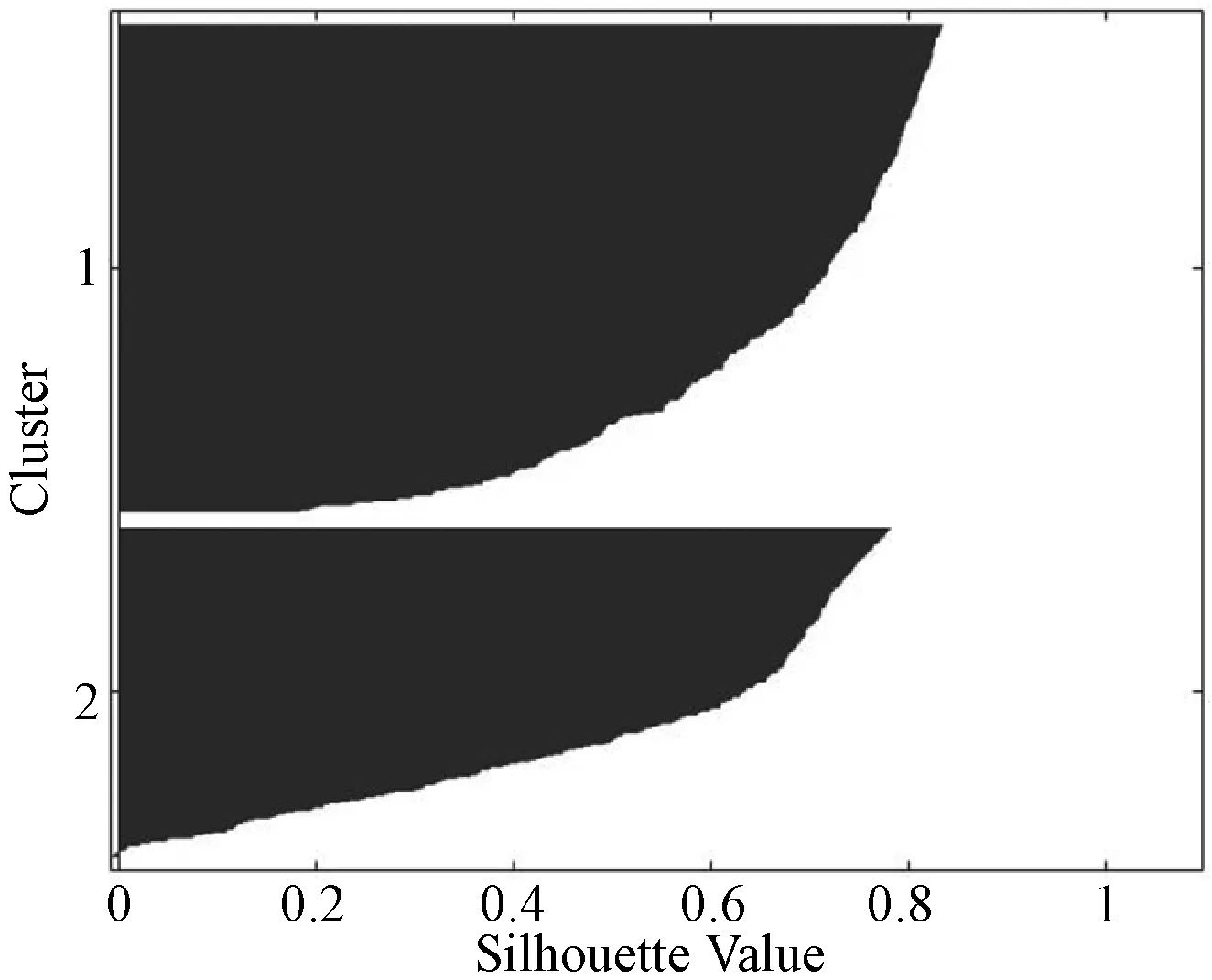
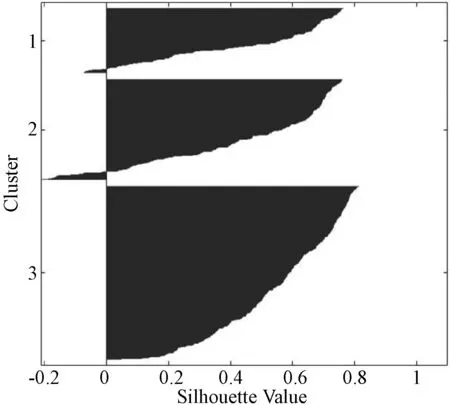
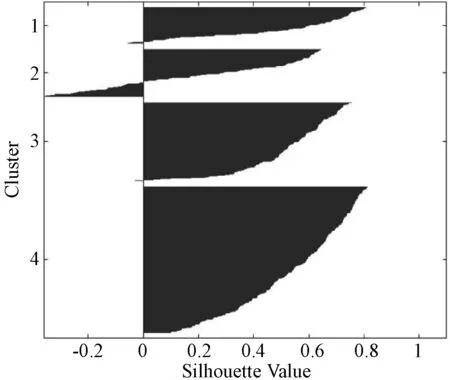
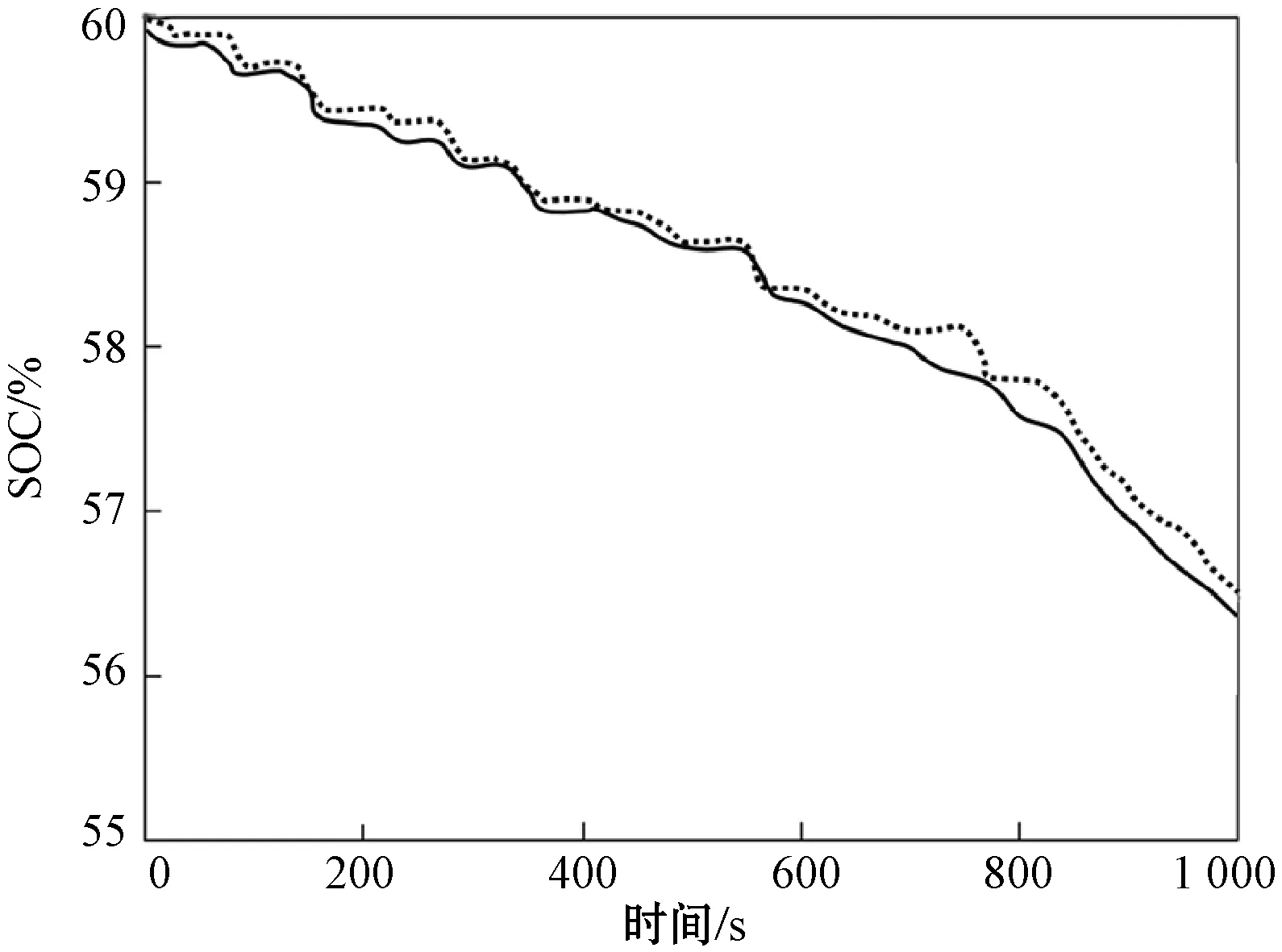
步骤5如果K1 步骤6如果K1>2K0,说明当前类太多,前往合并操作。 步骤7达到最大迭代次数则终止,K=K1,否则返回步骤2。 ISODATA通过计算数据和类中心的欧氏距离进行分类。数值越小,相似度越大。计算公式为[22]: (7) 式中:Si为样本数据集中的第i个数据对象;uj则为第j个聚类中[14]。 运用PCA分析法和ISODATA分析方法对所有的运动学片段进行分析,得到聚类分析结果。运用Silhouette函数绘制轮廓图,判断每个运动学片段的分类是否合理。Silhouette函数表达式为: (8) 式中:a(i)表示样本i与同类样本的差异度,用该样本与当前类别内各点的平均欧氏距离表示;b(i)表示样本i与其他类别样本的差异度,用该样本与其余类别内各点的平均欧氏距离表示。 Silhouette函数的函数值s(i)的取值范围为[-1,1]。s(i)越接近于1,表示样本i更倾向于属于当前样本。s(i)越接近于-1,表示样本i更倾向于属于其他样本。基于ISODATA自动得到的类别个数为2,采用人为定义类别个数为3和4,绘制对应的Silhouette函数如图5所示。 (a) 分2类 (b) 分3类 (c) 分4类图5 不同分类Silhouette函数值的轮廓 由图5(a)可看出,分2类时,Silhouette函数值均大于0,类与类之间区别明显。由图5(b)和5(c)看出,出现少量负值,说明分为3类和4类时,存在未被很好区分的片段。根据分析,ISODATA能够作为聚类分析的依据,且具有理想的聚类效果。 对分为2类时,各类型行驶状态和时间比例进行统计,结果如图6所示。由图6可看出,加速度时间比所占比例较高;类型1和类型2的平均速度和平均行驶速度较均匀。与类型2相比,类型1的加速时间短,平均加速度、平均速度与平均行驶速度较大,可见,类型1的行驶状态和驾驶操作较为顺畅。而类型2加速时间比例大,平均加速度、平均速度和平均行驶速度却较小,因此可能处于较为拥堵或跟车的行驶状态。 图6 各类型行驶状态 电动汽车实行工况的构建步骤: 步骤一根据聚类中心的大小,按照从小到大的顺序分别筛选20个候选运动学片段。 步骤二筛选备用运动学片段,如果某个类型中所包含的运动学片段不足20个。 步骤三以筛选的20个运动片段为基础集合,从中随机筛选并组合成大于等于1 200 s的代表工况。 具体流程如图7所示。 图7 工况构建流程 根据前述的聚类分析法的工况构建过程,按照分类结果的时间比例,合成如图8所示的1 200 s的汽车代表行驶工况。 图8 电动汽车代表工况 对比代表工况和测试数据的特征参数,结果如表3所示。可以看出,构建的代表工况可以反映试验电动汽车汽车的整体行驶特征。 表3 代表行驶工况和实际采集数据源特征参数 基于前述电动汽车行驶工况,首先按照最小距离原则确定电动汽车运行状态的类别: (9) 确定电动汽车在某一路段行驶时的类别为1,2,…,n后,计算电动汽车在该类别工况下的行驶距离dn。则该路段消耗电量E为: E=Eq1×d1+Eq2×d2+…+Eqn×dn (10) 式中:Eqn代表第n类工况每公里消耗的电量。通过该路段后,剩余电量Es为: Es=E0Ssoc-E (11) 式中:E0、Ssoc代表了初始电量与荷电状态。 在每个类别中随机抽取了部分运动学片段,并合成了模拟的行驶情况。绘制出本段模拟行驶片段的实际耗电量与采用耗电评估方法计算所得的耗电量曲线对比图,如图9所示,虚线为所记录的实际耗电曲线。可以看出基于本文提出的基于道路行驶工况的研究,可以实现对电动汽车耗电量和道路行驶耗电特性的有效追踪。 图9 耗电量曲线 目前,国内外针对汽车工况的研究主要以传统汽车为主,对电动汽车工况研究较少。工况提取和聚类结果的判断方法也存在一定不足,在电动汽车能耗特性分析方面也没有与实际工况紧密结合。本文采用无监督式聚类算法ISODATA进行电动汽车的工况合成与构建,并对合成的代表性工况进行了合理性验证,误差均在±5.2%的范围内。在运动片段聚类和代表性工况的基础上,进行了电动汽车道路耗电特性分析和电量实时估算分析,验证了所构建的行驶工况模型与耗电量估算方法具有合理性。本文对电动汽车的能耗分析、基础充电站设施配置、充电策略等方向的研究具有一定的参考价值。3.4 Silhouette函数轮廓图筛选聚类结果

4 构建行驶工况和耗电实时估算方法
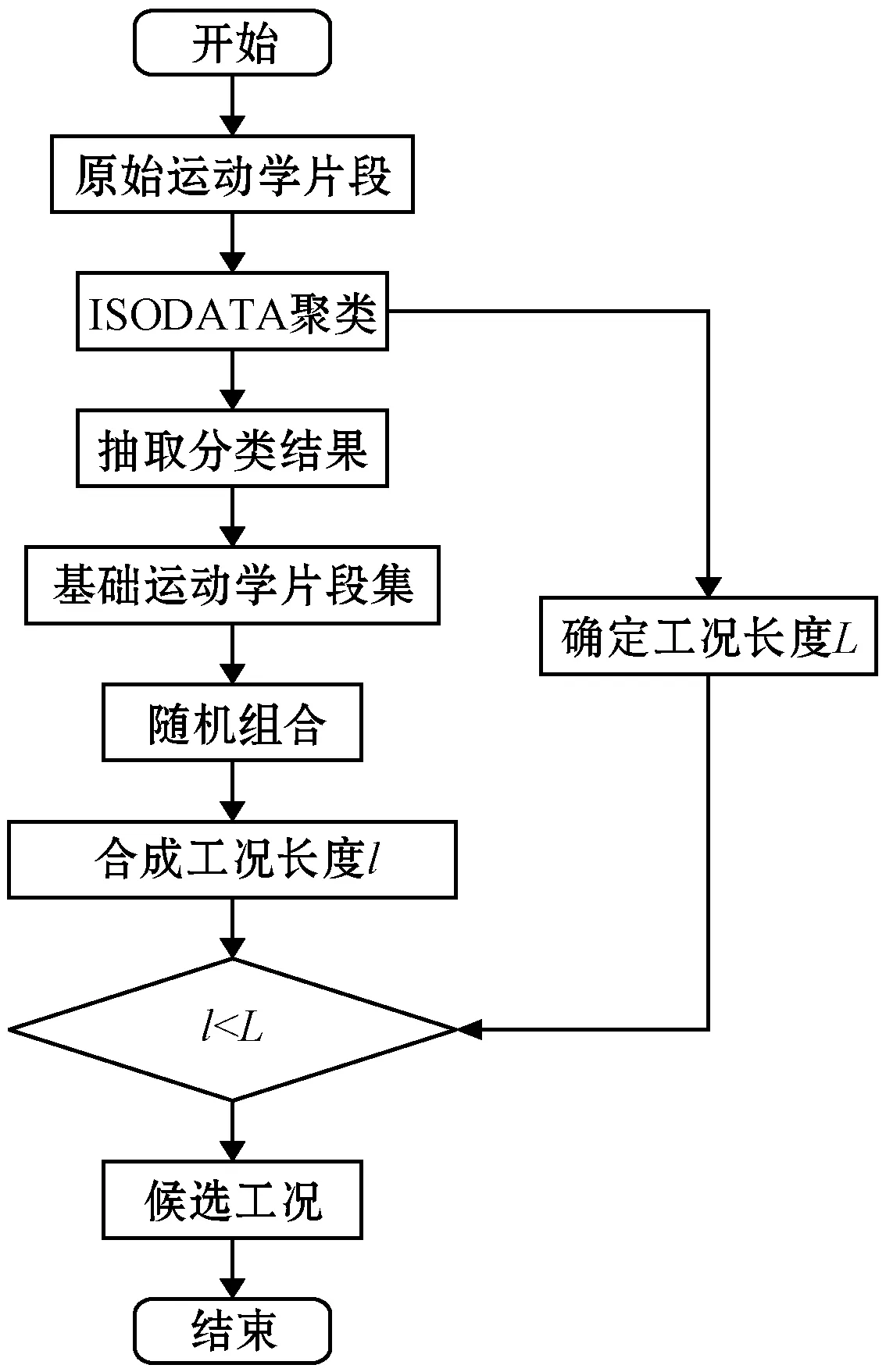
4.1 合成方法
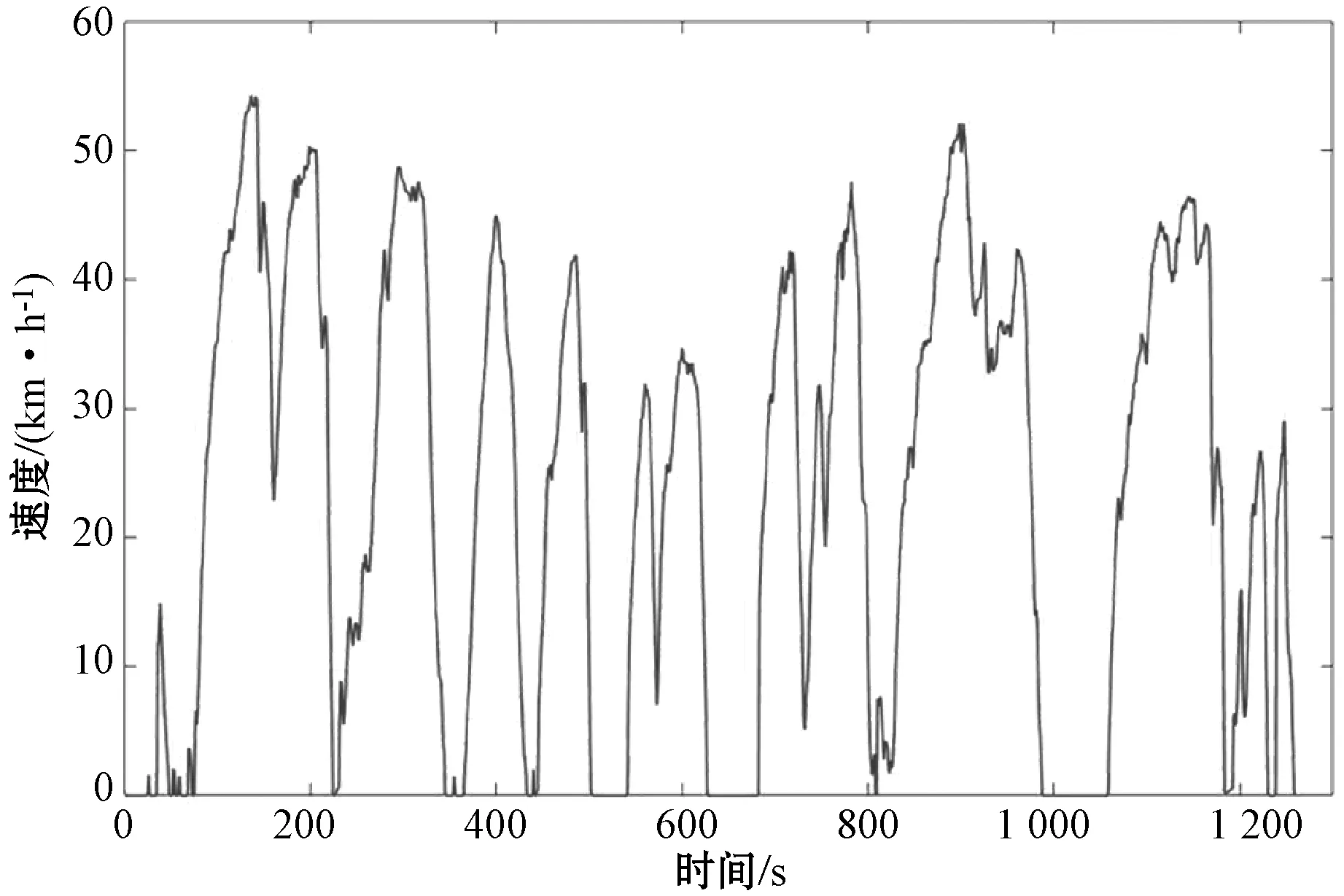
4.2 电动汽车工况合成结果
4.3 电动汽车工况合理性验证

4.4 实际道路耗电估算
5 结 语
