服务网格性能优化关键技术研究
2021-11-15杨怡滨于新容丘伟森
杨怡滨 杨 伟 于新容 丘伟森
(广东省轻工业高级技工学校信息工程系 广东 广州 510315)
0 引 言
服务网格[1]是致力于解决服务间通信的基础设施层,负责在构成复杂应用系统的微服务间灵活、高效和可靠地传递请求,用于控制和监视微服务应用的内部、服务到服务的通信。
服务网格由数据面和控制面组成,其中控制面用于集中设置相关策略进行服务间交互的流量监控与控制策略实施,而数据面则由一组轻量级网络代理(简称边车代理)构成。边车代理是一个辅助进程,它与主应用程序一起运行,并为其提供额外的功能。每个服务都配备了一个边车代理,它们与微服务一起部署用来实现(即边车部署模式)服务间的交互。
服务网格将服务间通信从底层的基础设施中分离出来使得服务能够被监控、托管和控制,同时为服务运行时提供统一的、应用层面的可见性和可控性,因此有效解决了大规模微服务服务治理问题。
目前服务网格技术仍处于发展阶段,性能是服务网格面临的核心问题和挑战[2]。服务网格(尤其是边车代理)的加入会增加请求调用链路的长度,因此必然会带来性能的损耗。众所周知,服务架构多用于分布式互联网系统应用中,而来自客户端的高并发访问请求(如车票预订、抢红包、双十一购物节等场景)十分常见,在使用服务网格后,并发压力从应用层服务转移到服务网格层面。因此,如何使服务网格具备高性能的、异步无阻塞的通信交互能力十分重要。本文分析发现,影响服务网格整体性能的主要因素如下:(1) 服务网格数据面中的边车代理负责服务间通信,在代理请求、向外转发请求和回传响应三个关键步骤涉及大量网络IO和计算,在高并发场景下使用大量线程资源,频繁的线程切换会严重影响并发性能。(2) 服务间及边车代理间交互通常基于HTTP协议,而传统的HTTP协议具有固定的消息格式,其中可能包含冗余的数据,其次HTTP协议基于TCP协议,因此每次请求建立连接时都经历三次握手,在高并发的场景下可能会造成明显的延迟。
针对上述问题,本文提出了面向服务网格的性能优化方法,首先基于Reactor模式[3],同时结合线程和协程[4]两者的计算优势,设计了一种具有高并发处理能力的计算模型,并将其用于边车代理的设计实现;其次基于HTTP协议设计了一种轻量、高效的应用层交互协议,用以减少服务边车代理间通信时传输的数据量,同时实现了基于零拷贝技术[5]的协议消息编解码算法,可以显著提高通信能力。
本文基于上述技术设计实现了一个原型系统,并通过实验与当前主流的服务网格系统Linkerd和Envoy进行了对比。实验分别从并发性能和通信性能两方面进行分析比较,结果表明本文提出的优化方法使得服务网格系统在减少响应时间和网络传输数据量两方面均有显著的性能提升。
1 相关工作
1.1 服务网格
服务网格是近两年兴起的技术,其相关研究目前较少,但是已经得到了工业界的广泛关注和应用。Linkerd和Envoy是目前典型的服务网格系统,Linkerd从2016年到2018年围绕性能优化发布了1.0.x、1.1.x、1.2.x、1.3.x、1.4.x、1.5.x、1.6.x等版本,尝试使用最新版本的Finagle框架优化、使用GraalVM提高性能、通过Open J9 JVM的支持降低40%的内存占用并大幅降低长尾延迟,目前GraalVM性能优化方案失败,仅存Open J9 JVM的优化版本,其测试版本还在继续发行。Envoy在2017年到2018年发布了1.2.x、1.3.x、1.4.x、1.5.x、1.6.x、1.7.x、1.8.x等版本,从多线程加非阻塞异步IO计算模型、通信协议优化和热重启等方面进行了优化设计。
国内自2017年底大规模开展高性能服务网格技术的研发,其中:华为用Go语言在路由管理、多协议支持方面做优化,自行开发了Mesher;蚂蚁金服从IO、协议、调度策略方面对服务网格进行了优化并开发了SOFAMesh;新浪开发的WeiboMesh在通信方面提供HTTP Mesh方案,支持HTTP与RPC服务之间的交互。但是,服务网格的加入增加了请求调用链路的长度,必然带来性能的损耗,例如:阿里巴巴对基于Envoy自主开发的Dubbo Mesh进行测试,发现Dubbo Mesh的每一次请求转发会造成1.5 ms的延时。
与上述工作不同,本文主要从并发处理模型和服务网格数据传输两方面提出性能优化的方法。
1.2 Reactor模式
基于线程的并发和事件驱动是并发处理的两种基本方法。迄今为止,事件驱动的并发方法因其更高的性能和更好的可伸缩性而得到更为广泛的应用。Reactor模式是当前具有代表性的事件驱动的并发处理模式之一,常用于具有高并发需求的客户端-服务器系统的设计和实现中,许多流行的开源框架和服务器系统均基于Reactor模式,如Netty、Redis和Node.js等。
Reactor模式[3]称为反应器模式,是一种为处理并发服务请求,并将请求提交到一个或者多个服务处理程序的事件驱动并发处理设计模式。当客户端请求抵达后,服务处理程序使用多路分配策略,由一个非阻塞线程来接收所有的请求,然后派发这些请求至相关的工作线程进行处理。Reactor模式主要包含如下四部分内容。
(1) 初始事件分发器(Initialization Dispatcher)用于管理事件处理器(Event Handler),负责定义注册、移除事件处理器等。当服务请求到达时,它根据事件发生的Handle将其分发给对应的事件处理器进行处理。
(2) 同步(多路)事件分离器(Synchronous Event Demultiplexer)无限循环等待新事件的到来,一旦发现有新的事件到来,就会通知初始事件分发器去调取特定的事件处理器。
(3) 系统处理程序(Handles)是操作系统中的句柄,是对资源在操作系统层面上的一种抽象,它可以是打开的文件、一个连接(Socket)、时钟等。由于Reactor模式一般使用在网络编程中,因而这里一般指Socket Handle,即一个网络连接(Connection Channel)注册到同步(多路)事件分离器中,以监听Handle中发生的事件,包括网络连接事件、读/写和关闭事件等。
(4) 事件处理器(Event Handler)用来定义事件处理方法,以供初始事件分发器回调使用。
对于高并发系统,常会使用Reactor模式,其代替了常用的多线程处理方式,节省了系统的资源,提高了系统的吞吐量。由于服务网格系统作为服务间交互的基础设施层常常面临服务请求与响应的高并发场景,因此本文选择基于Reactor模式进行服务网格中边车代理并发处理模型的设计。本文对Reactor模式进行了扩展,结合线程和协程的各自优势,实现由Manager、Worker和Collaborator三类角色协同的高并发处理机制。
2 服务网格性能优化技术
2.1 高并发计算模型
服务网格的典型工作模式如图1所示。以单方面的Microservice A的视角为例:Microservice A的服务网格组件边车(Mesh A)代理Microservice A对Microservice B的网络通信,Mesh A一方面需要维护与Microservice A的连接,另一方面需要将Microservice A的请求数据转发给Microservice B(Microservice B的网络通信由Mesh B代理),然后Mesh A收到响应并回传给Microservice A。
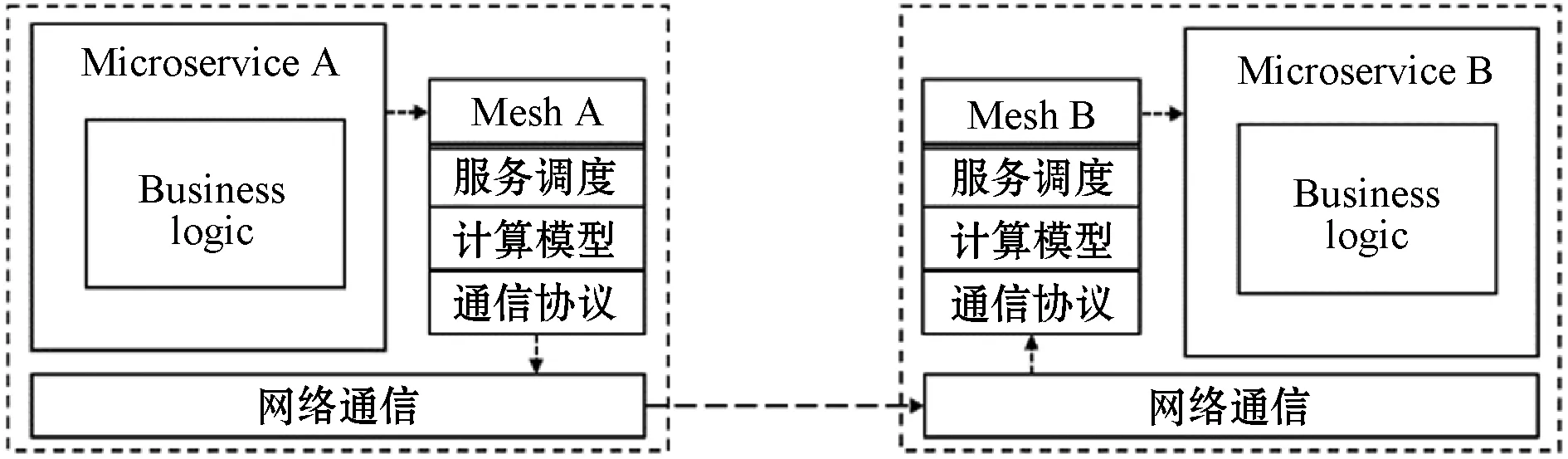
图1 服务网格工作模式
在Microservice A通信的过程中,Mesh A充当了类似“Server”与“Client”的角色,其中的计算过程可以分解成代理请求、向外转发请求和回传响应三个关键步骤。由于Reactor模型通常用于服务器端的设计,而每个服务网格的组件边车代理在图1所示的工作模式中都会承担“Server”的角色,基于这一观察分析,本文提出了基于Reactor模式的并发计算模型,用于设计构成服务网格数据面的边车代理。
如图2所示,该模型分为Manager、Worker和Collaborator三种角色。Manager以线程作为计算实体运行,用于维护服务的连接及分发连接的网络事件给Worker;Worker同样以线程作为计算实体运行,Worker执行相关数据计算的任务,然后通过Collaborator向外转发请求;Collaborator以协程作为计算实体运行,转发请求并等待、计算、处理和回传响应。由图2可以看出Manager和Worker基于Reactor模式,而Collaborator则是在Reactor模式上的进一步扩展。

图2 基于Reactor的高并发计算模型
Manager和Worker基于Reactor模式设计实现,传统的顺序编程采用每条指令依次执行的方式,难以满足高性能的需求。Reactor模式是基于数据流和变化传递的声明式的编程范式,用消息发送的事件流驱动机制取代传统的顺序执行机制[6]。Manager和Worker服务的请求数据作为数据流,Manager建立、维护相关连接后不会阻塞消息处理,Manager会监听各种网络事件并分发给相应的Worker进行处理。
服务网格启动时,绑定操作系统的某个端口后,首先将套接字(Socket)注册到Manager线程的选择器(Selector)上。Manager负责维护连接上下文的一致性,通过Selector监听客户端的TCP连接请求,并将消息的数据流事件循环(EventLoop)调度给相应的Worker进行处理。Worker负责消息的读取、解码、编码和发送,Worker采用串行化设计,1个Worker线程可以同时处理N条链路连接,1条链路只对应1个Worker线程,通过串行化设计有效防止并发操作问题。
随后,Worker和Collaborator协作,应用于服务网格向外转发请求和回传响应的场景。Worker通过scheduler调度器调度Collaborator执行任务,Collaborator协程执行完任务后会动态从其他的任务队列偷取任务执行。Collaborator负责请求转发和响应回传等任务,ClientChannel是转发请求时与目标服务的连接管道,Messenger执行ClientChannel的读、写、解码、编码、转发等,ServerChannel是与代理服务的连接,Messenger回传响应时,将数据写入ServerChannel。与Worker不同,1个Collaborator处理1条链路连接,1个链路对应1个Collaborator协程。Collaborator由Worker触发scheduler调度,Worker的事件循环组可包含多个事件循环,每个事件循环包含1个选择器和1个事件循环线程,每个事件循环线程通过事件机制向scheduler调度器调度Collaborator。
Collaborator基于协程实现。对比线程,协程有以下优势:(1) 更好地利用CPU资源,没有类似线程调度的上下文切换;(2) 更好地利用内存资源,用户只需要分配合适的空间即可。因此能够避免频繁的线程切换和由此导致的因CPU缓存行失效引起的性能下降问题。
2.2 轻量化通信协议
为了减少服务网格中代理间传输的数据量,减轻网络负载,本文基于HTTP协议进行了通信协议的定制化,设计了轻量化的协议和相应的编解码算法,能够有效降低服务代理交互的通信数据量,提高编解码速率。
如图3所示,定制化协议的结构由固定长度的消息头Head(8字节)和不定长度的消息体组成,具体组成如下:Magic Number:表示是否该协议的数据包;Serial ID:表示标志请求的序列号;Event Type:表示事件类型,1表示心跳消息,0表示不是心跳消息;Response:返回数据,0表示服务端可以不作应答,1表示服务端必须应答消息;Message Type:表示请求或响应的消息状态;Response Code:请求响应状态码,200表示成功,400表示失败,每种状态码对应相关原因;Message Length:表示消息长度;Message Body:表示消息数据。
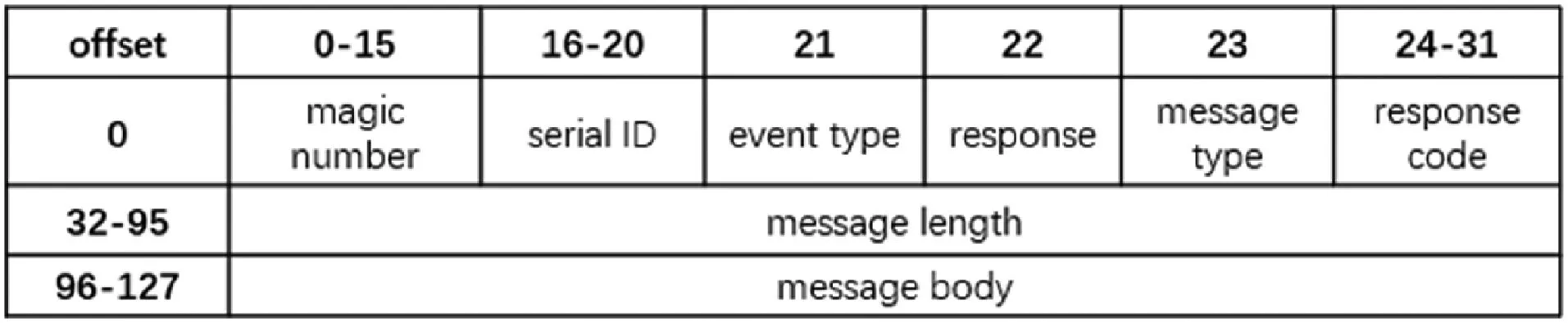
图3 定制化协议数据结构
本文设计的编解码算法主要解决网络传输过程中出现的半包/粘包问题,同时基于零拷贝技术有效减少操作系统内核态切换用户态过程的性能损失。
如图4所示,客户端发送Msg1和Msg2两个数据包给服务端,网络通信过程中会出现以下问题:(1) 无半包、无粘包,即服务端依次收到两个独立完整的数据包;(2) 半包,即服务端收到一个数据包,数据包只包含了Msg1的一部分;(3) 粘包,即服务端收到一个数据包,数据包包含了两个请求的数据。
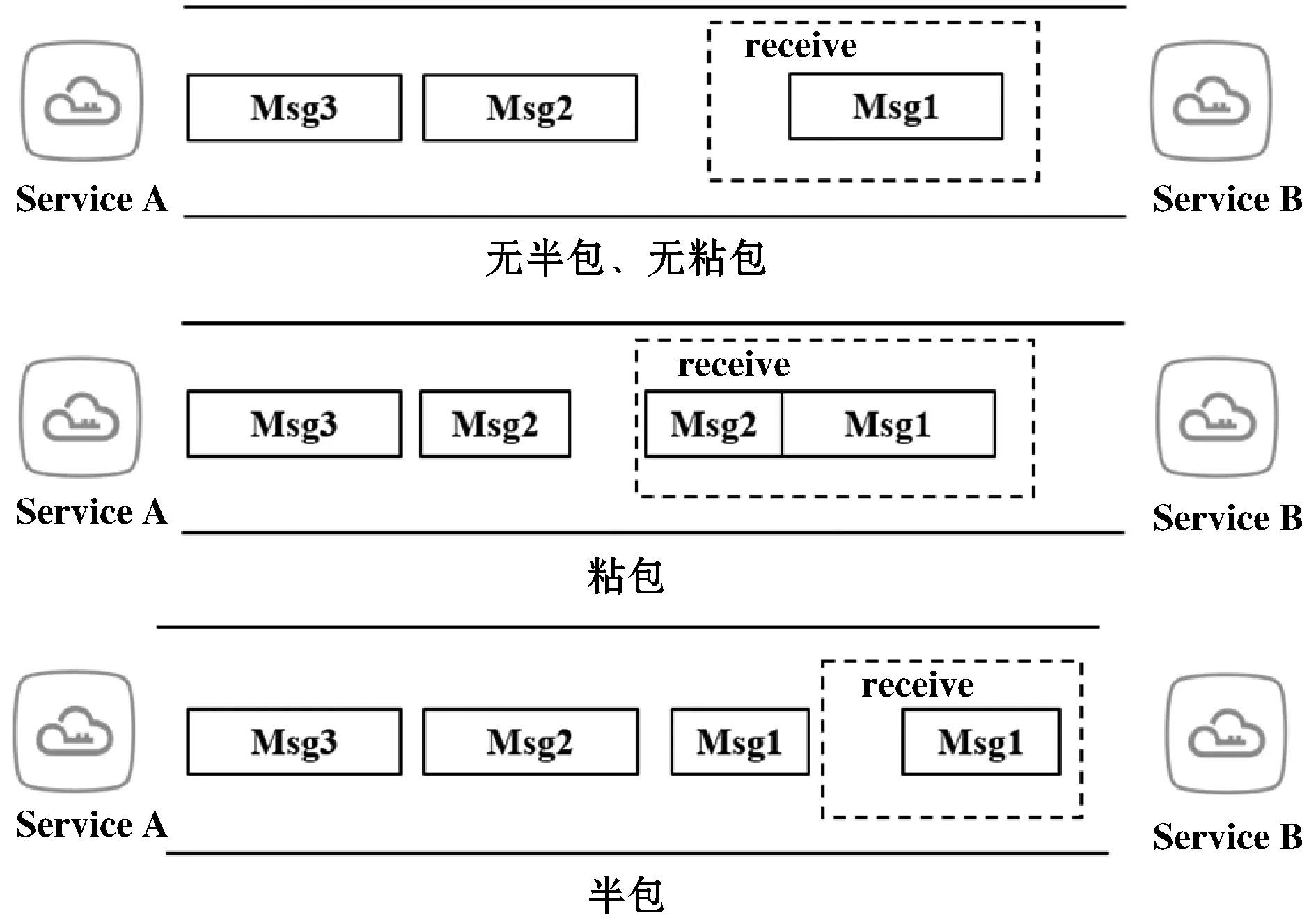
图4 半包和粘包
基于上述情况,本文设计了一个基于计数的可弹性伸缩的链式数据结构BufferLinkList,用以缓存网络交互数据,并进行编解码。BufferLinkList底层是循环链表,由Buffer块构成,Buffer块封装了直接内存,可以指定大小,默认为64字节,RefCnt表示Buffer的引用计数,通过引用计数,系统会自动进行垃圾回收。BufferLinkList能够弹性伸缩,如果数据过多,BufferLinkList会自动扩容,如果数据过少,会自动缩容。基于BufferLinkList的零拷贝体现在以下方面:(1) 在直接内存里面分配空间,而不是在堆内存中分配;(2) BufferLink-List会自动增减Buffer块,对上层提供统一读写接口,避免了数据的拷贝。BufferLinkList的数据结构如图5所示。
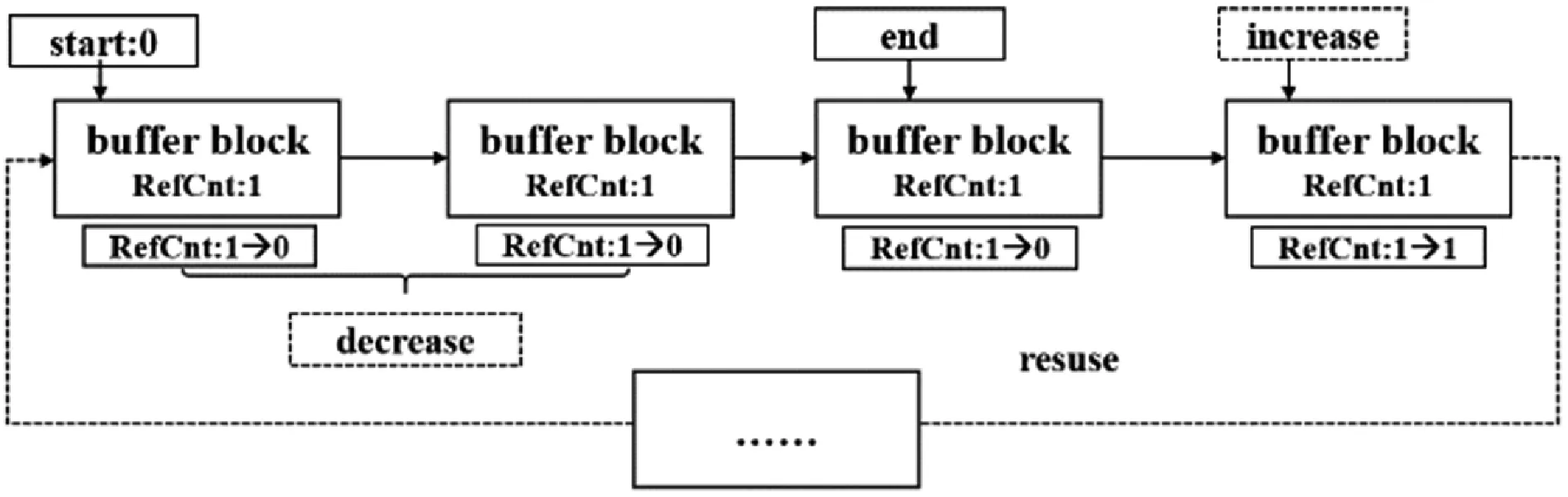
图5 BufferLinkList数据结构
编码时,首先计算数据包的大小;然后根据协议数据结构编码并存储到BufferLinkList中;最后通知操作系统发送网络数据。编码算法如算法1所示。
算法1编码算法
输入:data。
输出:bufferLinkList。
1. size←caculateSize(data)
//计算数据包大小
2. bufferLinkList←ButfferLinkListPool.getBufferLinkList(size)
//申请链表
3. header←HeaderTemplate.getHeader()
//从模板初始化头部数据
4. header.setMagic(MAGIC)
//用户自定义配置
5. header.setld(ID)
6. header.setlsHeartBeat(false)
7. head.setLength(data,length)
8. ……
9. bufferLinkList.write(head,data)
//写入数据
10. bufferLinkList.setRefCnt(1)
11.returnbufferLinkList
EndFunction
解码时,首先用BufferLinkList缓存操作系统收到的网络数据;然后根据已缓存数据的大小判断是否满足Head解码阶段,如果满足则进入Head解码,如果不满足则继续缓存;完成Head解码后计算消息的长度并进入Body解码状态,如果网络数据大于等于消息长度则执行完解码过程,并对已解码的数据重置引用计数,否则继续缓存,等待下一个Body解码状态。解码算法如算法2所示。
算法2解码算法
输入:bufferLinkList。
输出:data。
1. decodeStat←State.Head
//初始化解码状态
2. length←0
3.whilebufferLinkList←receive_data()do
4.ifdecodeState==State.Headthen
//判断解码阶段
5.ifbufferLinkList.size()<32then
6.continue
//数据不足,跳出
7.else
8. length←bufferLinkList.getDataBodyLength()
9. decodeState←State.Body
//进入Body解码阶段
10.ifbufferLinkList.size() -32>=lengththen
11.gotoGetData
12.else
13.continue
14.endif
15.endif
16.elseifdecodeState==State.Body
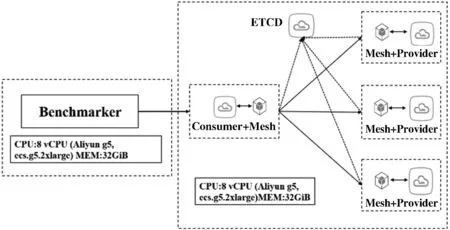
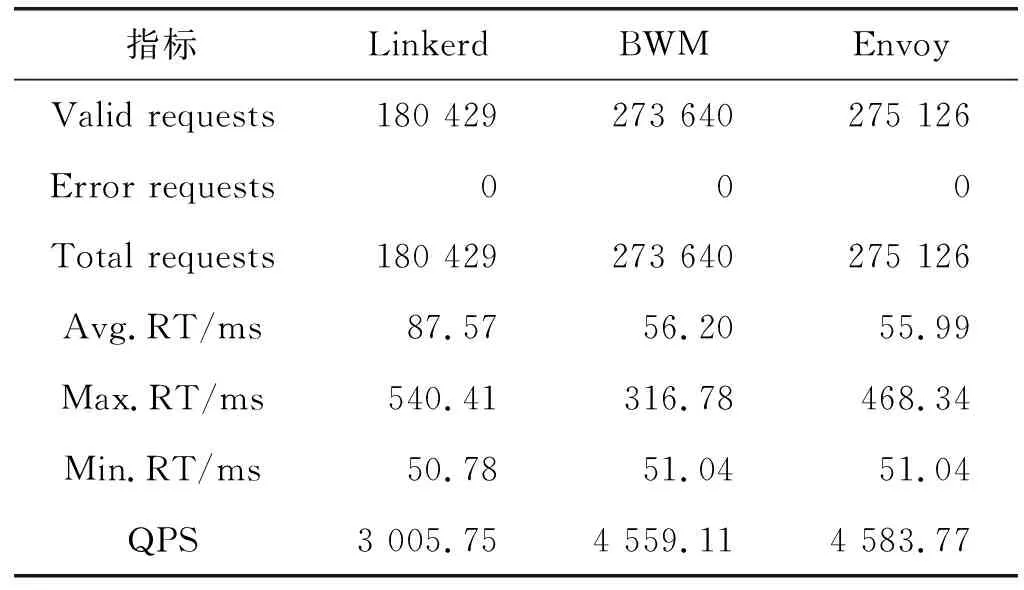
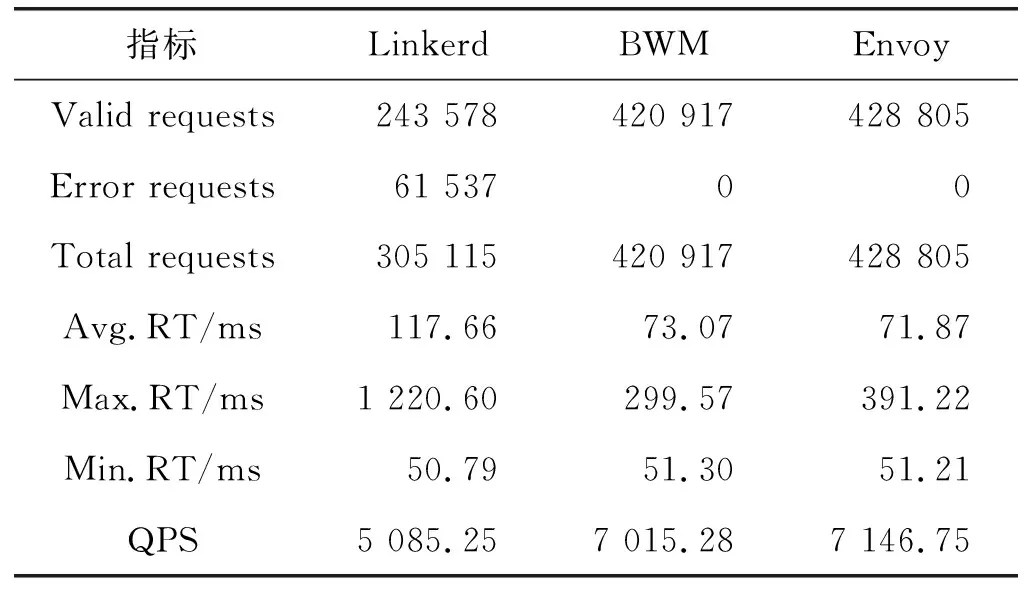
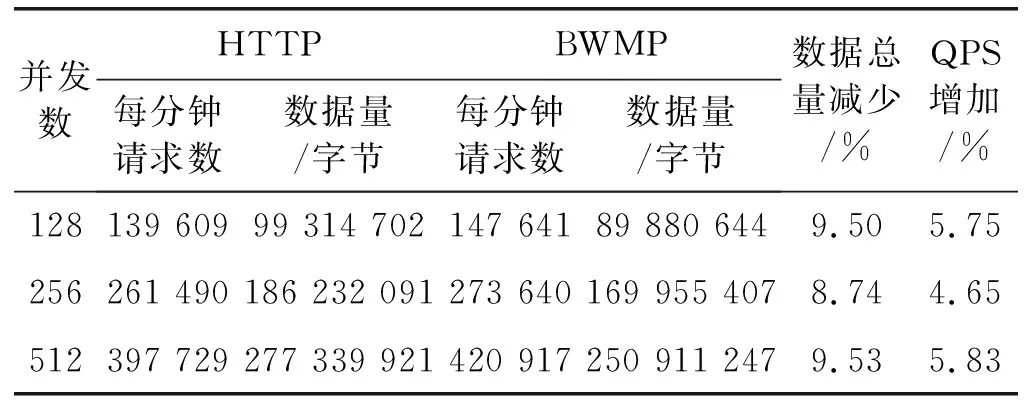
17.ifbufferLinkList.size() -32 18.continue //数据不足,跳出 19.else 20. GetData: data←bufferLinkList.getData(length) //获取数据体 21. endIndex←bufferLinkL ist.startIndex+length+32 //应用计数重置 22. bufferLinkList.setRefCnt(startIndex,endIndex,0) 23. bufferLinkList.setStartIndex(endlndex) //指正清零 24.returndata 25.endif 26.endif 27.endwhile EndFunction 基于上述关键技术,本文基于Java 8设计实现了一个原型系统如图6所示。整个系架构采用分层模型设计,包括核心层、计算层、应用层。 图6 原型系统总体架构 1) 核心层:包括BufferLinkListPool和统一通信接口。BufferLinkListPool提供BufferLinkList,BufferLinkList是封装了直接内存的链式结构,用于缓存网络IO数据,支持基于计数的垃圾回收,并且弹性可伸缩;统一通信API层提供了基于BufferLinkList的通信相关的操作接口。 2) 计算层:提供了以线程封装的Manager、Worker等计算资源及用协程封装的Messenger计算资源,基于本文提出的并发处理模型提供高并发处理能力。 3) 应用层:实现了服务网格的核心服务,如:服务注册与发现服务、协议与编解码服务、路由选取服务等。 网络数据进入服务网格后的处理流程包括以下步骤:(1) 网络数据从物理网卡进入,操作系统陷入内核态处理;(2) 服务网格从BufferLinkListPool获取BufferLinkList,并缓存IO数据;(3) 使用反应式编程的BWM计算模型的计算资源,Manager线程维护连接,并向Worker线程分发任务;(4) Worker线程通过统一通信API处理相关数据,如编解码,然后分发给Collaborator协程,并重新编码向外转发;(5) Collaborator收到请求后回传给代理服务。 为了评价本文方法的有效性,本节首先设计相关实验,将原型系统(简称BWM)与目前主流服务网格系统Linkerd(1.6版本)和Envoy(1.8版本)在相同环境下进行性能测试。实验环境基于2台阿里云服务器搭建,每台服务器配置信息如图7所示,并根据实验结果进行分析对比。 图7 实验环境设计 实验由施压方和受压方组成,施压方Benchmarker会产生三组高并发连接(128并发连接、256并发连接和512并发连接)向Cosumer服务进行压测,Benchmarker生成随机的字符串data并发送请求给Cosumer服务,Cosumer服务收到该请求后会通过服务网格将data发给Provider服务的服务网格,Provider服务的服务网格将data发给Provider服务,Provider服务计算data的HashCode后将HashCode(data)通过服务网格返回Cosumer服务的服务网格,Cosumer服务的服务网格将响应返回给Cosumer服务,Cosumer服务最后将结果返回给Benchmarker校验并统计相关性能指标。 实验时每一组压力测试持续时间60 s,运行10次,去掉最好和最差的实验数据,最终的实验数据取平均值。实验流程如下: (1) 每轮评测在受压方中启动五个服务(以Docker实例的形式启动),一个ETCD服务作为注册表、一个Consumer服务和三个Provider服务,每个服务都会绑定服务网格,Provider服务会Sleep(50 ms)模拟计算时间; (2) 使用另一台独立的服务器作为施压方,分不同压力场景对Consumer服务进行压力测试,得到相关性能指标; (3) ETCD是注册中心服务,用来存储服务注册信息;Provider是服务提供者,Consumer是服务消费者,Consumer消费Provider提供的服务。 为了尽可能模拟真实情况,每个服务实例所占用的系统资源各不相同,运行Consumer服务及其Service Mesh的实例(为了便于描述,下文将简称为Consumer实例,Provider实例类似)占用的系统资源是最多的,而三个Provider实例占用的系统资源总和与Consumer实例占用的系统资源是相同的,并且Provider实例按照small ∶medium ∶large=1 ∶2 ∶3的比例进行分配,分为Provider(small)实例、Provider(medium)实例和Provider(large)实例,服务实例的资源分配如表1所示。 表1 服务实例资源分配 在每个Consumer和Provider实例中,都存在一个服务网格实例,其在整个系统中起到了非常关键的作用。 (1) Consumer服务是基于Spring Cloud实现的Web应用,会发送请求给Provider服务,服务之间数据传递是通过服务网格进行的,服务网格的性能决定了系统的性能;(2) 任何一个Provider实例的性能都是小于Consumer实例的,服务实例的调度选取策略意义重大;(3) Provider实例最高支持200并发的连接,高并发下会产生回压问题。 实验使用wrk作为施压方,wrk是一个基于事件机制的高性能HTTP压力测试工具,能用很少的线程产生极高的访问压力。实验统计性能测试指标如表2所示。 表2 性能测试指标 4.3.1并发性能分析 为了评价本文提出的并发模型对于提高服务网格并发性能的有效性,本文设计相关实验与目前主流的服务网格系统Linkerd和Envoy进行比较,在相同实验条件下,用wrk测试三者的性能表现。 实验结果显示本文原型系统和Envoy(C++实现)有非常相似的表现,两者性能都明显优于Linkerd。详细结果如表3-表5所示,从延时分布上分析,并发连接从128并发连接上升到512并发连接的过程中,BWM和Envoy的延迟分布比Linkerd更稳定。具体来说,Linkerd的平均延迟从58.42 ms至117.66 ms,增加101.40%,在相比之下,BWM和Envoy的平均延迟从约52 ms增加到约72 ms,增加38.46%。Linkerd的延迟变化很大,以512并发连接实验为例,Linkerd的50%的请求在80.44 ms内,99%的所有请求在522.44 ms内,相比之下,BWM和Envoy的变化仅从约67 ms(50%)到大约145 ms(99%)。 表3 128并发连接下的测试结果 表4 256并发连接下的测试结果 表5 512并发连接下的测试结果 可以看出BWM和Envoy的性能表现明显优于Linkerd。最初,128并发连接下,三者性能差异很小,其中BWM的表现最为优秀,BWM和Envoy的差距不大,但是两者都明显优于Linkerd,Linkerd仅比其他两个低约12%;256并发连接下,Linkerd、BWM和Envoy的QPS分别为3 005.75、4 559.11、4 583.77,512并发连接下,Linkerd、BWM和Envoy的QPS分别为5 085.25、7 015.28、7 146.75,差距随着并发的增加而增加。需要注意的是,虽然BWM的性能和Envoy是非常相似的,但是最大响应时间(Max.RT)BWM均比Envoy小,考虑C++语言比Java存在的一定性能优势,因此BWM的性能表现十分优秀。 4.3.2交互性能分析 为了评价本文设计的通信协议(BWMP)的有效性,本文在相同实验条件下,分别测试使用HTTP协议通信和自定义协议通信下的性能表现。 实验结果如表6所示,可见使用BWMP协议传输数据总量平均减少约9.26%,QPS平均增加约5.41%,说明BWMP协议对性能有一定的影响和提高。 表6 通信性能测试结果 4.3.3程序语言层面分析 众所周知,编程语言的特性直接影响所实现系统的整体性能。本文原型系统和Linkerd都是基于Java实现,而Envoy则基于C++实现。C++是基于静态类型编译的编程语言,在本质上相比于Java更加高效。因此,从程序语言层面来看,Envoy的性能应该显著优于BWM和Linkerd,但实验结果是BWM和Envoy的性能相近,显著优于采用同样编程语言的Linkerd。因此考虑到编程语言本身对系统性能的影响,本文提出的服务网格性能优化方法起到了很好的优化效果。 服务网格是面向服务计算的新型基础设施,为服务的灵活交互和全面的服务治理与服务监控提供支撑。服务网格的性能优化是提升系统并发处理能力的有效途径。本文从计算模型和通信协议两个方面提出了服务网格性能优化的关键技术,设计了基于Reactor的高性能并发模型和轻量化的通信协议与高效的编解码算法。通过实验与当前主流的服务网格系统Linkerd和Envoy进行了性能对比,分别从并发性能和通信性能方面进行分析比较,实验结果表明本文方法在响应时间和网络传输数据量方面均起到了性能优化作用。 目前本文的实验只是基于简单的模拟场景对提出方法的有效性进行了分析对比,后续工作将基于更多的真实应用更加深入和详细地进行实验和分析。此外,未来工作将从负载均衡和调度算法方面继续深入研究服务网格的性能优化技术,并将相关成果应用于主流的开源服务网格系统,以进一步分析评估方法的有效性。3 系统设计

4 实 验
4.1 实验设计

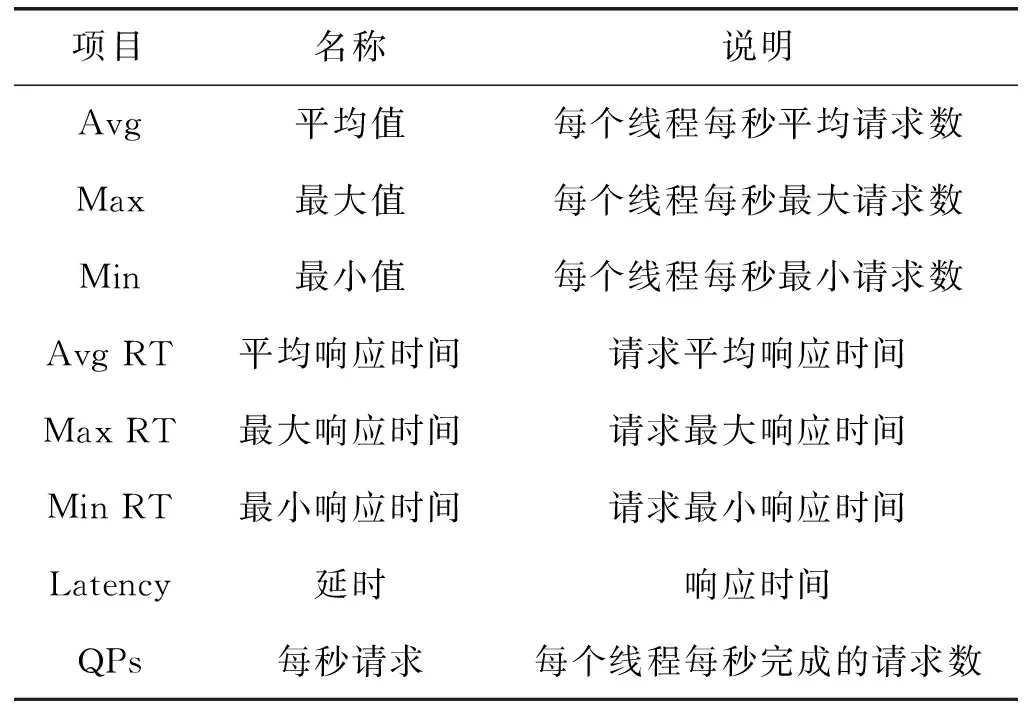
4.2 评价指标
4.3 实验结果分析

5 结 语
