Codis分布式缓存架构在电力系统中的应用研究
2021-11-15王加阳
马 克 王加阳
(中南大学计算机学院 湖南 长沙 410083)
0 引 言
随着电网运营模式的智能化,逐步实现“智能电网”工程目标[1]及“互联网+智慧能源”新型思路在电力供给侧的重点推进[2],未来可能将有更多的电力设备投入到电网系统中。据统计,截至2017年底,城乡居民中智能电表的覆盖率已达99.03%,累计采集用户约4.47亿,新装智能电表3 748.7万只。
新形势下,必将导致电力数据的爆发性增长,电力系统中的电力数据覆盖设备检测、电力营销、电网运行等多个领域,随着数据增长及业务的扩展,各领域下电力数据的存储效率及响应能力,将成为整个电力系统运行中至关重要的一环。传统电力系统主要存在以下三种数据存储模型。
(1) 关系型数据库存储模型。多采用小微型主机作为存储设备,电力数据全部存放于关系型数据库中,如Oracle、SQLServer等。该模型部署简易,运维便捷,在初期,受到诸多电力企业青睐。但是,随着数据量的增长,格式单一、扩容性差、响应缓慢等问题逐渐暴露。
(2) 单一式非关系型数据库与关系型数据库混合存储模型。引入非关系型数据库,如Redis、MongoDB等,集中管理部分热点数据并对其进行缓存处理,另一部分非热点数据仍然存放于关系型数据库中。该模型消除了关系型数据中的数据格式单一、响应缓慢等问题。然而,单节点服务器提供的缓存服务在内存容量、可用性、稳固性等方面存在巨大局限。
(3) 分布式非关系型数据与关系型数据库混合存储模型。分布式非关系型数据库能够将请求数据分布至不同节点,易于实现负载均衡和服务器水平扩展,进而提高响应速度与并发性能。其中典型的代表即Redis集群作为分布式缓存架构,像新浪、GitHub、Pinterest[3]等互联网公司已投入应用。目前,电力行业也正深入研究并逐步向此模型迈进。
Redis官方在3.0版本后终于提供了集群化方案,但是官方并没有对此集群方案在实际生产环境中进行充分验证[4]。在实际生产环境中,Redis集群常会遇到以下问题:动态扩展能力较弱、可视化性能监测缺失、节点状态切换耗时长等。而且,一旦出现异常情况,运维人员不仅要熟知Redis集群相关架构,还要在组网架构和路由转发等方面有一定的知识沉淀,对运维人员技能要求高。
针对这种情况,本文基于Codis分布式缓存架构进行研究及应用,描述了整个架构完整的部署方案及核心配置文件,并从电力系统中业务存储能力、数据检索效率、性能优良检测等多角度,对此方案进行深度测试。
1 Codis分布式缓存技术研究
1.1 Redis特性
基于键值对(Key-Value)储存的非关系型数据库凭借着灵活的数据模型及高性能的体验[5],被广泛应用于互联网及分布式计算等各个领域。在诸多Key-Value非关系型数据库中,Redis是应用最广泛且最具有代表性的方案[6]。
Redis是开源的、高性能的、键值对存储数据的NoSQL数据库,常常被用于缓存和中间件[7]。相比于其他非关系型数据库,Redis具有以下特点:
(1) 数据类型丰富。支持字符串(String)、链表(List)、普通集合(Set)、有序集合(Sorted Set)、散列(Hash)五大数据类型,轻松应对实际产生环境中的各种数据结构。
(2) 操作命令多样。每种数据类型都对应着多样的操作命令,以字符串类型为例,除了常用的set、get命令完成字符数据的存取外,还支持替换字符串setrange、批量设置键值对mset、自增存储数据的长度incrby、指定字符追加数据值append等命令,极大地方便了开发者对数据属性的管理操作。
(3) 性能体验极佳。Redis数据存取都是基于内存中完成的,因此不会受到磁盘I/O读写速度的限制,读写速度高达10万/s[8],远远优于常规的关系型数据库读写速度。
(4) 数据存储安全。Redis提高了AOF和RDB两种数据化持久方式[9],允许开发者自定义时间周期,定期地将内存中的数据保存至磁盘中,以确保异常情况时迅速恢复数据集。
(5) 应用范围广泛。目前Redis应用于网站访问量统计、网站在线人数统计、积分排行榜、消息缓存等多个方面。
1.2 Redis Cluster架构
单节点Redis服务无法提供高并发、大数据服务的特性,因此必须采用Redis集群架构进行弥补。
以官方提供方案中的Redis Cluster架构为例,如图1所示。Redis Cluster是一个去中心化的结构模型,通过动态扩展多台主机节点,实现Redis分布式架构。多节点服务器间相互连接,并通过Gossip协议进行广播消息通信,确保数据之间的同步。对于客户端,只需任意连接其中一台节点服务器进行相关读写操作,集群便会通过定义配置进行负载均衡,通过路由转发去请求真正的服务器节点。

图1 Redis Cluster架构
通过架构图可知,Redis Cluster部署方案比较单一,集群内部节点耦合度严重。一旦业务扩展,需要动态扩展成百上千节点时,部署庞大Redis集群将给运维人员带来极大困难。同时,数据迁移、繁琐配置文件、成千上万行的运维命令,同样会给运维人员带来巨大的挑战。
1.3 Codis分布式缓存架构
Codis是由豌豆荚基于Go语言开发的一个分布式Redis集群解决方案,并于2014年11月对外开源。
Codis分布式缓存架构底层将Redis集群按照一定规则进行分组,且每个组内可以自定义主从配置,如图2所示[10]。Codis架构将Redis节点群进行分组细化,形成多个组群,分解了Redis集群中的整个去中心化网络结构,简化了Redis大集群部署的复杂度且降低了大集群管理难度。
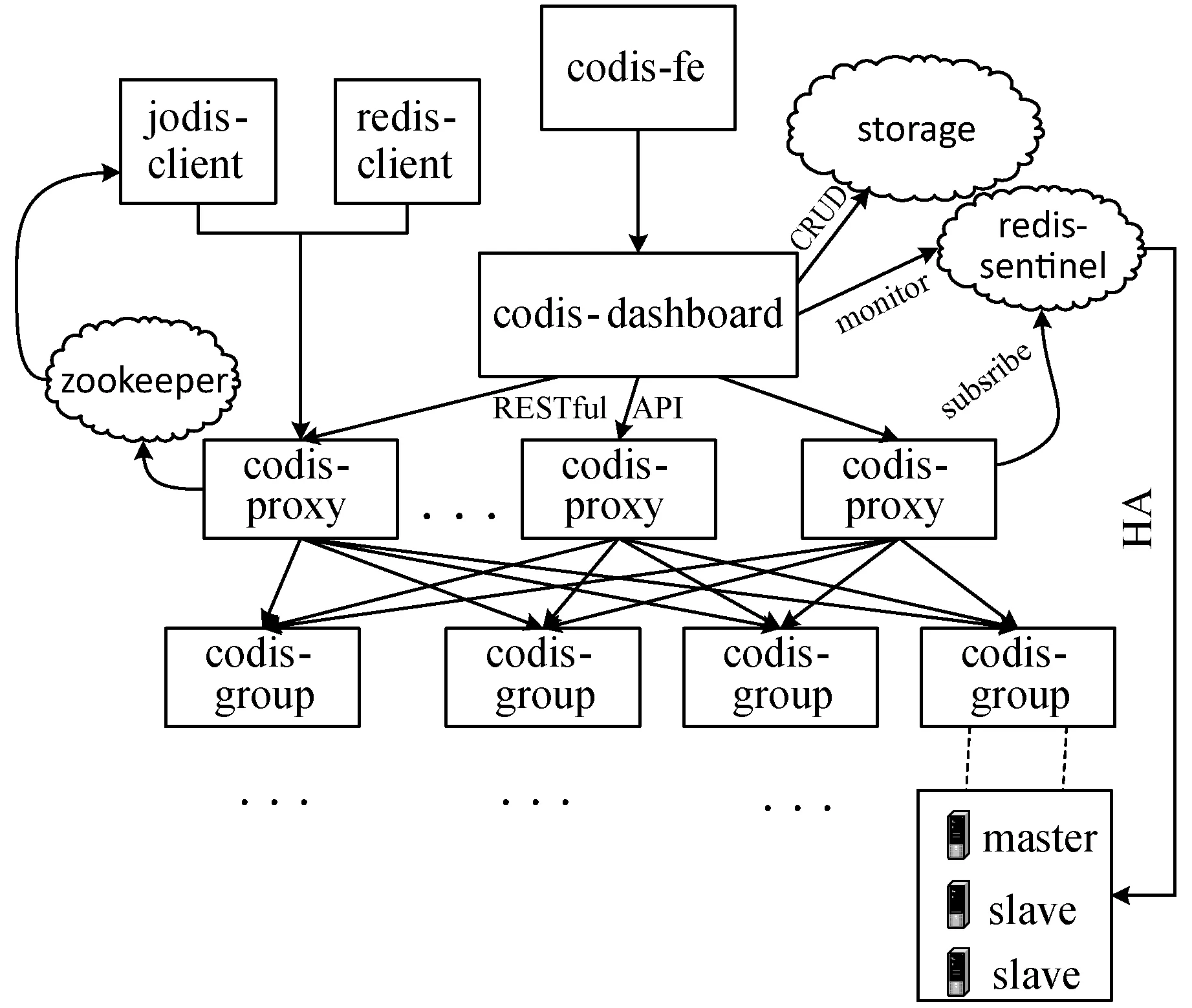
图2 Codis分布式缓存架构
所有的Redis服务组通过codis-proxy代理进行管理,由于codis-proxy代理是无状态的且无缝衔接Redis协议,因此上层客户端可以直接通过codis-proxy代理与整个Redis服务组进行对接。当发生读写请求的时候,客户端的操作流程与原生的Redis Server并没有太大差异。底层的转发流程关键点在于codis-proxy代理,codis-proxy代理会根据请求按照一定的算法进行路由转发及数据的迁移工作。正是由于codis-proxy代理的出现,使得底层读写工作对客户端相对透明,因此能够充分利用动态扩展的Redis实例计算能力,从而完成大数据量和高并发的读写操作。除此之外,Codis架构还提供了可供选择的运维便捷、高性能化管理的交互组件,组件如下。
(1) Codis Server。在Codis集群架构中,会采用插槽(slot)的方式来分配数据,默认将slot分为1 024份,开发者可以自行对这1 024份slot进行group分组操作,当客户端进行存储的时候,会调用CRC32取模算法,将指定的key映射至对应的节点。redis-server启动、每部分数据插槽管理及数据迁移的工作都可以交给Codis Server进行处理。
(2) Codis Dashboard。Codis Dashboard负责Codis集群的配置工作,该组件支持开发者通过指定的RESTful接口完成codis-proxy、codis-server的添加及删除任务。同时,该组件可以通过Redis的哨兵机制确保codis-proxy状态信息一致性。
(3) Codis FE。利用Codis FE,开发者可以通过可视化Web界面,一键式部署Redis服务节点、创建codis-proxy代理节点,甚至可以实时监控整个集群运行的性能状况。
(4) Codis Admin。利用Codis Admin组件,开发者可以使用命令行工具完成codis-proxy创建、codis-dashboard状态变更等控制任务。此组件的存在,使得Codis整个架构更加完整,开发者不仅可以通过图形化界面管理集群,而且还可以使用传统的命令行工具进行管理操作。
2 Codis分布式缓存架构部署
2.1 硬件环境
整个Codis架构的部署共涉及5台服务器进行模拟实际生产环境,各台服务器的硬件信息如表1所示。

表1 服务器硬件信息
2.2 软件环境
此集群架构每台服务器节点上所涉及软件环境为:Go 1.7.1、JDK1.7.0、Codis 3.1、Redis3.2.4、ZooKeeper3.4.9。具体节点部署信息如表2所示。
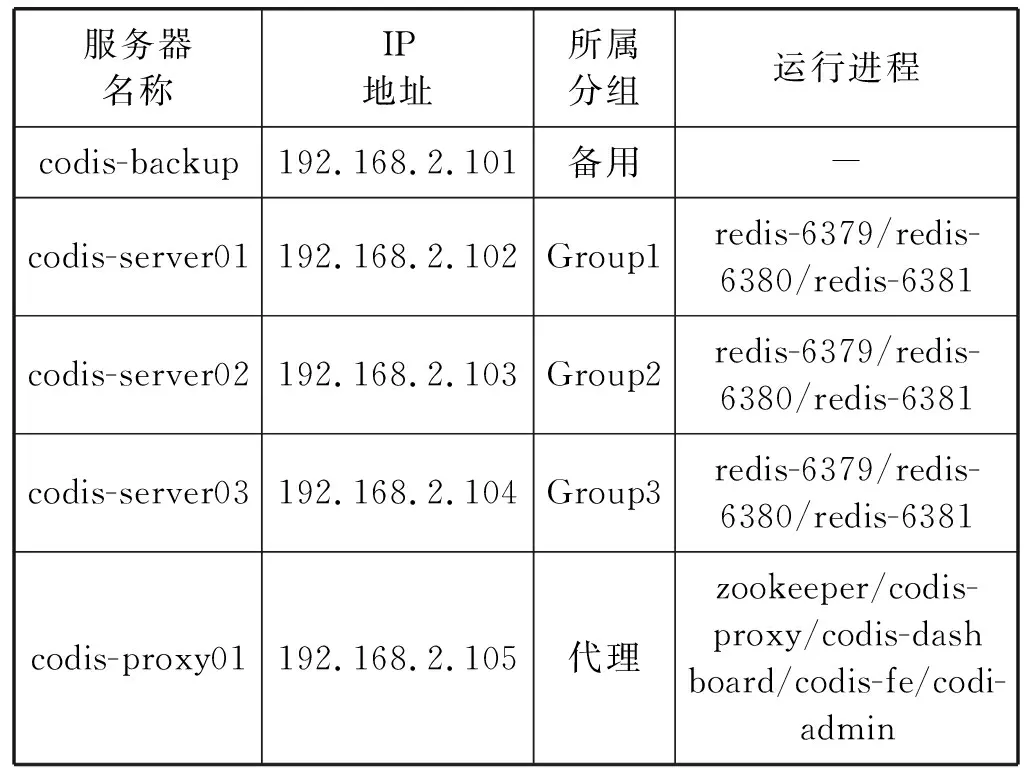
表2 服务器软件信息
2.3 部署流程
由于整个Codis分布式缓存架构组件较多,接下来主要描述架构搭建关键步骤及部分核心配置,其他非关键性配置信息省略。
(1) Go语言及依赖库的安装。由于Codis是基于Go语言开发的,因此首先必须确保基础环境的存在,具体命令如下:
yum install autoconf automake libtool -y
yum install -y gcc glibc gcc-c++ make git
cd $GOPATH/src/github.com/CodisLabs/codis
make
(2) Java环境及ZooKeeper安装。ZooKeeper核心配置文件zoo.cfg部分配置信息如下:
tickTime=2000
#自定义心跳检测发送时间
dataDir=/usr/data/zookeeper
#自定义产生数据路径
server.1=192.168.2.105:2888:3888 #添加主机服务地址
(3) Codis Server安装与配置。codis-server部署成功后将替代redis-server进行启动,关键配置如下:
#bind 127.0.0.1
#为了安全考虑建议绑定内网IP,防止外网访问
port 6379
#redis节点监听端口,生成环境中建议更换为非常用端口
daemonize yes
#开启守护进程模式
pidfile/usr/local/redis/redis-6380/run/redis_6380.pid
#自定义pid进程文件生成的位置
logfile/usr/local/redis/redis6380/logs/logs_6380.log
#自定义log日志文件生成的位置
dir/usr/local/redis/redis-6380/db
#自定义数据文件生成的位置
requirepass mark-codis
#开启登录主机密码
(4) Codis Dashboard安装与配置。Dashboard安装编译成功后会生成一个dashboard.ini配置文件,需要对此文件进行如下修改:
coordinator_name="zookeeper"
#使用的协调器的名称,只
#能设置两个zookeeper、etcd关系的键值对
coordinator_addr="192.168.2.105:2181"
#使用的协调器的节点地址
product_name="codis-demo"
#该产品名称
product_auth="mark-codis"
#该产品的授权秘钥
admin_addr="0.0.0.0:18080"
#自定义后台管理路径的地址和端口
(5) Codis Proxy安装与配置。codis-proxy安装编译成功后会生成一个proxy.ini配置文件,需要对此文件进行如下修改:
product_name="codis-demo"
#该产品名称
product_auth="mark-codis"
#该产品的授权秘钥
jodis_name="zookeeper"
#使用的协调器
admin_addr="0.0.0.0:11080"
#连接地址
jodis_addr="192.168.2.105:2181"
#设置zookeeper地址
(6) Codis FE安装与配置。使用codis-admin提供的相关命令即可快速完成codis-fe的安装:
/usr/local/codis/bin/codis-admin—dashboard-list—zookeeper=192.168.2.105|tee/usr/local/codis/conf/codis.json
所有组件部署并启动成功后,在浏览器中输入codis-fe进程运行所在节点的主机地址,即192.168.2.105:18090/#codis-demo,可以发现Codis架构已经正常启动。Codis架构部署成功后启动界面如图3所示。
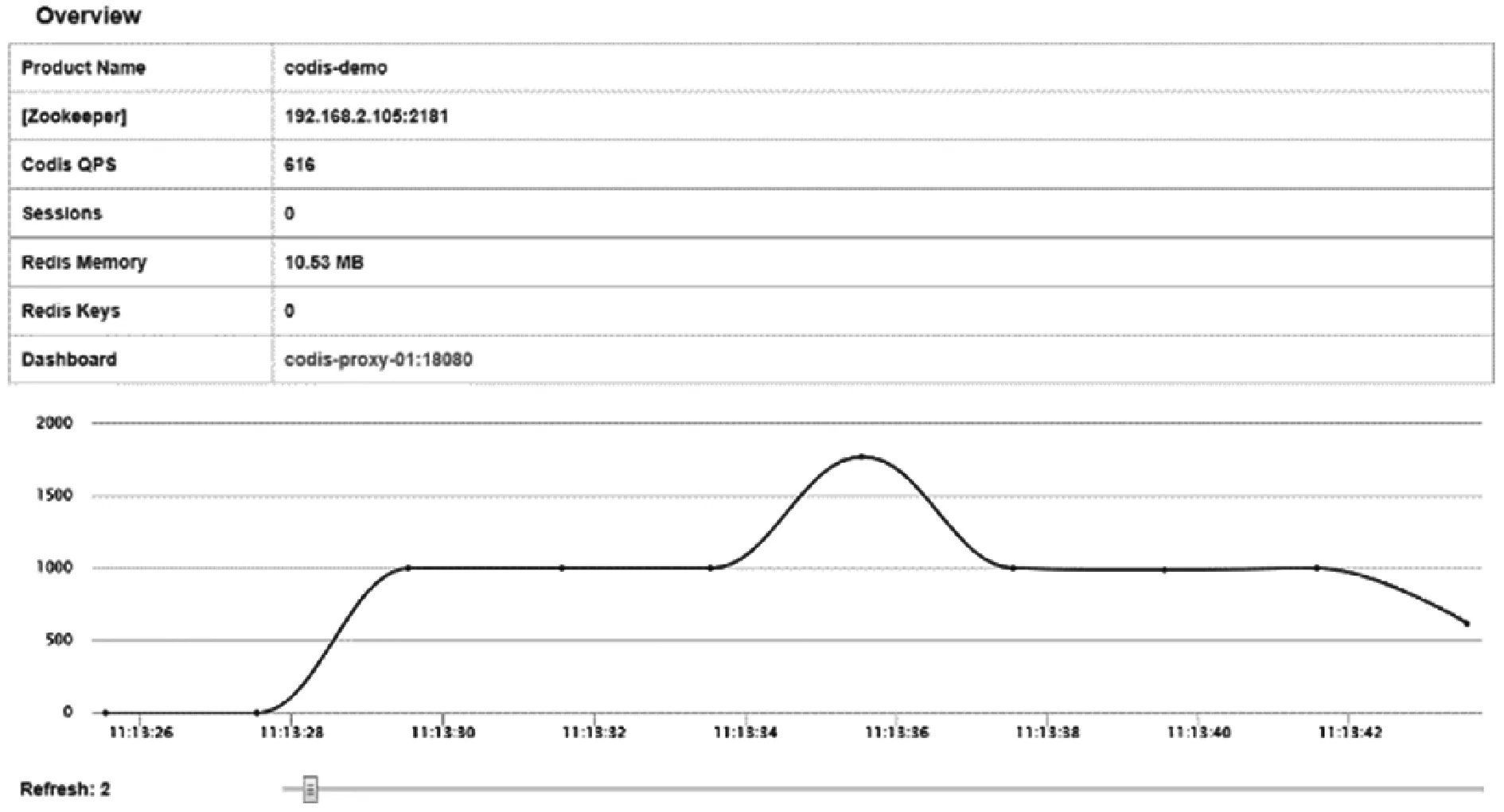
图3 Codis架构部署成功部分界面
3 电力系统中Codis架构应用及测试
3.1 业务存储
漏电、过载、短路等电气异常是火灾引发的重要因素[11-12],因此电力系统中通常存在监控子模块,不间断采集用电线路中的电压、电流、谐波、功率等数据,并通过时分秒等时间刻度趋势图进行分析预测。这就意味着短时间内电力系统中将要存储大量电力数据,并且需要在不同时间刻度之间进行快速的数据运算,而这些短时间内电力数据并不需要长期保存,因此可以采用Hash结构存储电力属性数据,并根据线路、时间刻度等关键信息为基础设置Key值(electric_线路_秒),具体存储模型如图4所示。

图4 电力线路数据存储结构
当准备向Codis架构中存储采集到的电力数据时,首先需要先连接至codis-proxy代理,命令如下:
/home/mark/Cluster/gowork/src/github.com/CodisLabs/codis/extern/redis-3.2.4/src/redis-cli-h 192.168.2.105-a foobared-p 19000
然后通过hset命令向Codis架构中存储电力数据,当存储部分电力数据后,试图分别登录codis-server01、codis-server02、codis-server03,寻找electric_trunk1_road01对应的Hash值,发现并不是每台redis服务组上的每个redis节点都储存着指定的key值数据,实际上这条指定的key对应的键值,会经过CRC32的取模算法映射至一台指定redis节点。这意味着该集群底层可以被无限地扩展,形成一个原则上内存无限大的Redis服务。动态扩展的多节点可以通过自定义规则按照组别划分,对Redis集群中复杂交错的网络拓扑结构进行了解耦,有力地加强对Redis集群的管理。而且Codis架构底层运作原理对于开发者来讲又是透明的,开发者只需要像操作原生单节点Redis服务一样操作Codis架构即可完成数据存储,这将大大提高电力业务数据的存储能力与效率。
3.2 索引检索
在电力系统中监控模块往往存在一些公共的数据信息,如线路坐标信息。这些信息通常不会变更,需要持久保存,但在系统中却经常去检索相关线路坐标信息。为了能够快速地按照建筑、楼层等要素值进行检索,可以仿照3.1节中涉及的业务存储模型建立相关的Hash结构储存。
为了测试Codis架构检索的速度,设置电力数据请求参数集:不同数量的客户端并发数,每个客户端请求均为1 000次,请求数据量大小均为10 000 B,分别在Codis架构和部署了3台相同硬件配置服务器(共计9个Redis服务节点)的Redis集群上进行测试,测试结果如图5所示。
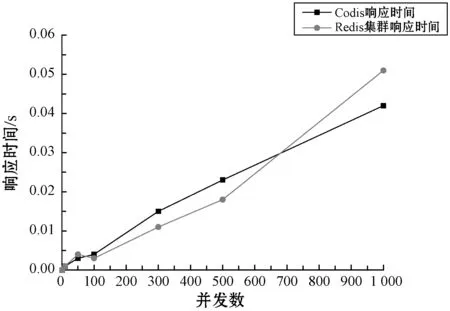
图5 并发响应时间对比
从实验结果来看,Codis架构虽经过Proxy代理真正Redis服务节点并且配置了多种组件的情况下,性能并不输于Redis集群,当客户端并发量超过700个左右时,Codis架构的性能甚至略优于Redis集群;当客户端并发量达到1 000个时,Codis架构可以在40 ms内检索到数据,由此可推断Codis架构可以高速地完成电力数据的检索工作。
3.3 性能监测
电力系统业务复杂,性能指标不仅仅体现在数据存储容量、检索效率方面,数据吞吐能力也是关键一环,数据吞吐能力高低直接决定了Codis分布式缓存架构是否能够应用于电力系统中。
为此,分别设置不同的请求量对Codis分布式缓存架构中操作频繁的命令进行QPS测试,测试结果如图6所示。

图6 Codis架构中频繁操作命令QPS
测试结果表明,对于产生环境中操作频繁的命令在多客户端情况下进行请求,每秒钟能够响应的请求次数依旧有着不俗表现,而且在测试期间,后端codis-server平均CPU占用率约为60%~85%,意味着此时Codis架构并非满负载运行,每台codis-server服务器仍存在空余空间完成其他操作。与同硬件环境的9台Redis集群相比,同指令相同请求量下QPS没有太大差距,Codis架构的数据吞吐能力依旧可以胜任电力系统中缓存数据读写的工作。
3.4 部署运维
Redis集群作为缓存架构在电力系统中长期运行,一方面,随着电网规模的扩张和电力业务的变动,快速地部署更多Redis服务节点是必经之路;另一方面,不可避免地会因为内部代码Bug、硬件问题或者外部因素出现故障,从而导致整个电力系统运行不稳定。及时地锁定故障节点并排查故障原因,能够极大地减少故障处理时间,减少运维人员工作量,进而提高电力系统运行的稳定性。然而,Redis集群关于以上两点都没有给出相应的解决方案,但是Codis架构却提供了图形化界面,完成新的Redis节点部署与故障节点的定位排查,如图7所示。

图7 Codis架构中Redis节点管理可视化界面
4 结 语
本文从电力系统中缓存架构存在的实际问题出发,对Codis分布式缓存架构进行研究,并给出该架构的核心配置步骤及方案,然后对其在电力系统中的业务存储能力、索引检索效率、性能优良分析等方面进行实际应用与测试。实验证明,该架构在数据储存与索引查询上具备优异性能,在可视化分析、运维管理角度突出于Redis集群,具有一定的研究与推广价值。
下一步将继续结合电力系统中实际应用场景,对Codis分布式缓存架构的高可用、故障转移方面做进一步的研究。
