基于生成对抗网络的主机入侵风险识别
2021-11-15李元培潘梓文
林 英 李元培 潘梓文
(云南大学软件学院 云南 昆明 650500)
0 引 言
随着计算机与网络技术的飞速发展,人们的生活越发依赖电子设备带来的便利,但与之伴随的计算机安全问题也越发尖锐。根据2018年Windows平台漏洞数据统计,Windows主机系统漏洞提交量总体呈逐年上升趋势,并且2018年相较之前三年同比上升最高超过40%[1],针对主机漏洞发起的入侵层出不穷。如何对入侵进行有效检测,成为了网络安全研究的重点之一。一般来说,根据检测数据的来源,入侵检测可以分为基于网络的入侵检测及基于主机的入侵检测。基于网络的入侵检测通过使用原始的IP数据包作为数据源,检测是否存在入侵。基于主机的入侵检测则一般通过检测系统、事件、系统日志等方式来发现入侵。
随着机器学习技术在各个研究领域的应用,基于机器学习的入侵检测模型也逐渐成为目前的研究趋势[2-4]。然而,诸如贝叶斯算法、决策树等传统的机器学习模型与深度学习模型相比,在特征不明显或内部约束较复杂的数据处理及特征关联等方面的表现有所欠缺[5],因此基于深度学习模型来进行入侵检测成为了研究热点之一。如Javaid等[6]提出一种基于深度学习的自学习技术,从未标记的数据中学习良好的特征表示,再进行入侵分类。Yin等[7]使用递归神经网络进行入侵检测,提高检测的准确性。Qu等[8]提出基于深度置信网络的入侵检测模型。Shone等[9]提出基于无监督特征学习的非对称深度自动编码器(Nonsymmetric Deep AutoEncoder,NDAE)。可以看出,目前基于深度学习的入侵检测系统主要侧重于高维数据特征提取的自动化、高维数据特征降维,以及提高样本识别能力等方面,而且大部分研究均使用NSL-KDD[10-11]作为其训练及测试的数据集。
虽然基于深度学习的入侵检测能够有效检测恶意软件、恶意行为、恶意代码等,但仍然存在如下局限[12]:1) 训练过程中攻击样本远远少于正常样本,导致检测模型失衡,无法正确检测出恶意攻击;2) 恶意攻击技术的发展,使得攻击者的攻击手段也在不断改变, 通过已知的入侵知识库进行学习将导致模型无法检测未知的攻击数据。因此研究者们引入生成对抗网络(Generative Adversarial Networks, GAN)[13]生成可使用的攻击数据, 增强训练数据集, 达到提升检测模型性能的目的。
2014年,Goodfellow根据博弈的思想提出一种可在一定程度上自我演化的模型GAN,该模型目前在图像分类与样本生成等方面得到了成功且广泛的应用[14-15],主要用于解决训练不稳定、模式崩溃、样本生成等问题[16]。已有研究通过GAN网络对恶意代码库进行样本扩展,解决入侵手段进化导致攻击样本老旧的问题[17]。一些基于GAN的检测模型也相继提出,如t-GAN[18]用于检测恶意代码,t-DCGAN[19]用以提升t-GAN模型训练过程的稳定性,Bot-GAN[20]用于检测僵尸网络,以及CF-GAN[21]用于检测在线支付欺诈。
本文从受保护的设备本身的角度,提出基于主机特征的入侵风险识别框架,旨在建模主机设备特征以及是否曾遭受入侵,并在此基础上基于GAN设计并实现了风险识别网络TR-GAN (Threaten Recognition-GAN)。该模型可以对主机当前遭受入侵的风险程度进行评估,且评估的结果可以在一定程度上作为系统安全管理员部署安全策略的参考。
1 模型设计
1.1 简 介
GAN模型主要分为生成网络和判别网络两个模块,生成网络根据训练集的学习并加入随机噪声生成新的样本,判别网络对输入的样本判断其标签。训练的目的是为了最小化两个子网络的损失函数,其模型目标函数如下:
Ez~Px(z)[log(1-D(G(z)))]
(1)
式中:x~Pdata(x)表示真实数据x服从分布Pdata(x);z~Pz(z)表示生成器的输入z服从某一分布Pz(z);生成器通过学习x的分布,使生成器的输出G(z)服从Pdata(x)来达到误导判别器的目的;D(x)表示判别器对真实数据来源的估计;D(G(z))表示判别器对生成器所生成的数据来源的估计。
AC-GAN[22]、LS-GAN[23]是GAN的变形,在AC-GAN中,每个被生成器产生的样本都附带相应的类别标签,判别器不仅给出了当前样本来源的概率分布,还对样本所属的标签进行了估计。其中:Ls代表输入数据的真实来源,即对被判定为正确类别的样本集合对其是否来自真样本集合进行估计;Lc代表输入数据的正确标签。生成器及判别器都被训练为最大化目标函数Ls+Lc。AC-GAN与GAN相比训练效果较好,但仍采用基于最大似然估计的方法,默认总体上的各个样本独立且同分布,所以当样本属性间有较强内在关联性或异常值与样本数据存在系统相关性时,参数更新过程中可能出现梯度消失的问题。
Ls=E[logP(S=real|Xreal)]+E(logP(S=fake|Xfake)]
(2)
Lc=E[logP(C=c|Xreal)]+E[logP(C=c|Xfake)]
(3)
式中:S=real表示判别器判定该样本来自真实数据;S=fake表示判别器判定该样本是由生成器生成的数据;C表示判别器对该样本标签的预测值;c表示该样本标签的实际值;Xreal表示该样本来自真实数据;Xfake表示该样本是由生成器生成的样本。LS-GAN中的目标函数如式(4)所示,以最小二乘法计算预测样本标签与实际标签间的平均欧氏距离。
(4)
LS-GAN中的目标函数可在一定程度上规避梯度消失的情况,但其生成器需要较多轮次的训练才能达到稳定。本文基于AC-GAN与LS-GAN,设计并实现了名为风险识别网络的变体架构TR-GAN (Threaten Recognition-GAN),在满足识别率和鲁棒性要求的同时,其训练效率更高。
1.2 总体架构
TR-GAN可以辅助系统管理员对主机遭受攻击的风险进行识别,从而便于其采取相应的预防措施以及设置合适的防御等级等安全策略。其主要由以下2个模块构成:
1) 基于主机特征的风险识别模块。识别模块实现对主机遭受攻击风险的预测。
2) 风险样本生成模块。风险样本是指使用真实样本训练的生成网络所生成的,并可以被风险识别模块判定为被攻击风险较大的样本。本文使用9×9的高斯噪声作为噪声输入,利用生成器构建新的主机特征数据。
由于在实际应用中,存在模型因对某些属性取值敏感或部分样本数据不服从独立同分布导致目标函数抖动而出现梯度偏移或梯度消失的问题。本文基于AC-GAN和LS-GAN中的模型优化方法,设计了如式(5)所示的目标函数L,用于降低在数据的非凸区间上因数据不一致或噪声在进行梯度下降优化过程中由于单一判据导致损失函数偏离实际损失,从而计算出的梯度与实际梯度不符。
L=Ls+L2
(5)
式(5)将Ls、L2求和以作为共同判据,式(6)为式(2)中的集合,表示被正确识别的样本集合,其中:X为标签,0表示未受攻击,1表示曾受攻击;Threaten表示模型将该主机估计为易受攻击;Safe表示模型将该主机估计为不易受攻击。
S=(Threaten|X=1)∪ (Safe|X=0)
(6)
2 模型实现
本节根据以上架构将已经预处理好的数据样本作为模型输入,对训练集中的数据进行风险识别。使用训练后的TR-GAN的判别器部分作为最终的风险评估模型,生成器生成的样本作为系统安全管理员设置安全策略的参考。
2.1 主机模型建立
主机模型需要采集能够影响主机安全性的参数,实现对目标主机潜在信息的发掘和安全性的判断,可以针对如下设备参数进行参数采集和规则的建立,如表1所示。

表1 设备参数选择及取值规则
本文从设备硬件、操作系统两方面选取对主机安全具有决定性的关键特征[24-25]用于建立主机特征。根据上述规则,主机安全特征可以由以下向量描述:
feature=[Census_ChassisTypeNameOSEditionCensus_OSVersionCensus_PrimaryDiskTypeEngineVersionSmartScreenIsFwOsBuildCensus_IsTouchEnabled…]
(7)
2.2 数据集
本文使用的数据集来源于数据挖掘网站Kaggle。训练集共包含约4.46×107条遭受攻击的主机样本和4.45×107条未遭受攻击的主机样本[26]。
2.3 数据预处理
本文基于以下规则对数据进行预处理:
1) 删去缺失比例超过80%或单一值比例超过85%的属性。
2) 取值种类超过10 000个的非连续型数据,按K-means规则进行离散化,使其取值种类不多于200个。
3) 数据缺失较少的属性随机填充已有值,且满足填充前后数据分布不变。
4) 对非连续型数据按独热编码(One-Hot Encoding)方式重编码。
5) 因某些属性的实际最值未必会出现在训练集中,故对连续型数据按式(8)规则进行规范化。
(8)

部分转换后的属性前后对比如表2所示,仅列出处理后的十个属性对比。
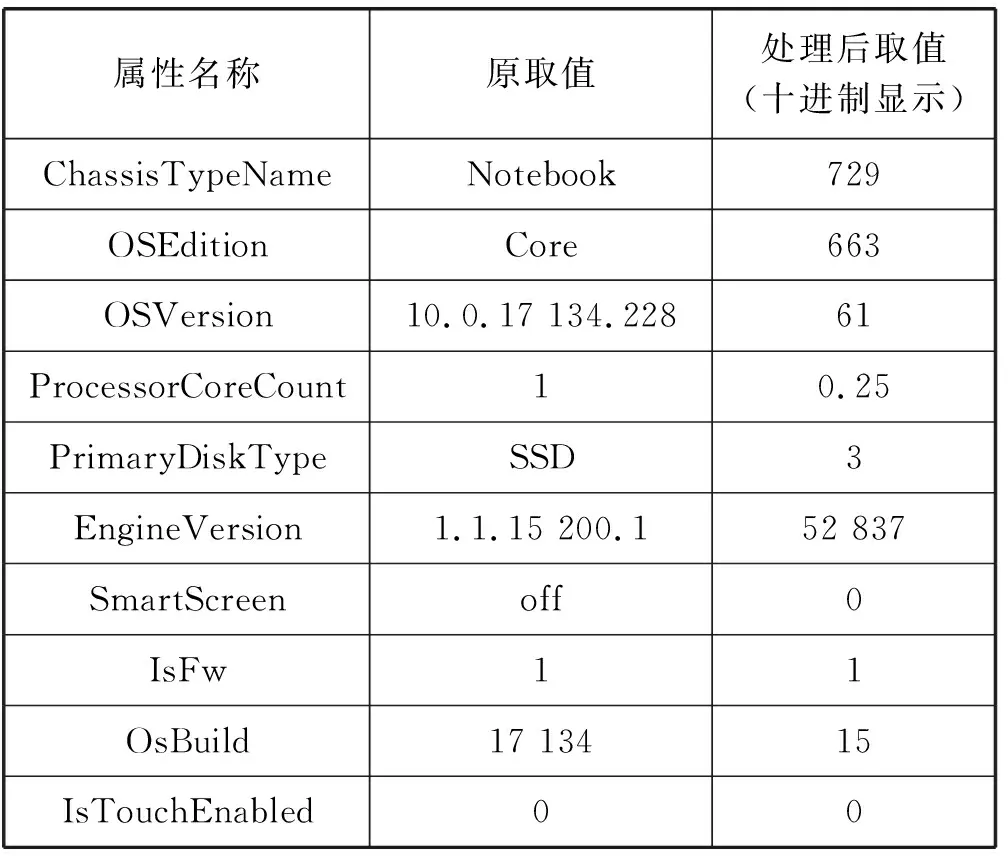
表2 预处理前后属性类型对比(部分)
将每条数据记录按算法1中规则映射为位图,以满足模型的输入格式要求。
算法1数据-位图转化算法
输入:经预处理后的数据集SET1。
输出:位图数组集合BMPSET。
1) PadArray(SET1)
//将每条实例数组填充至N×N
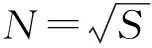
3) WHILE(S>0) DO
4) Feature[S-1]=(Feature[S-1]/MAXS-1-MINS-1)
//对属性取值归一化
5)S=S-1
6) END WHILE
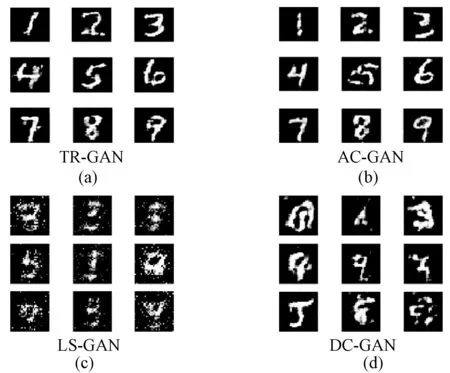
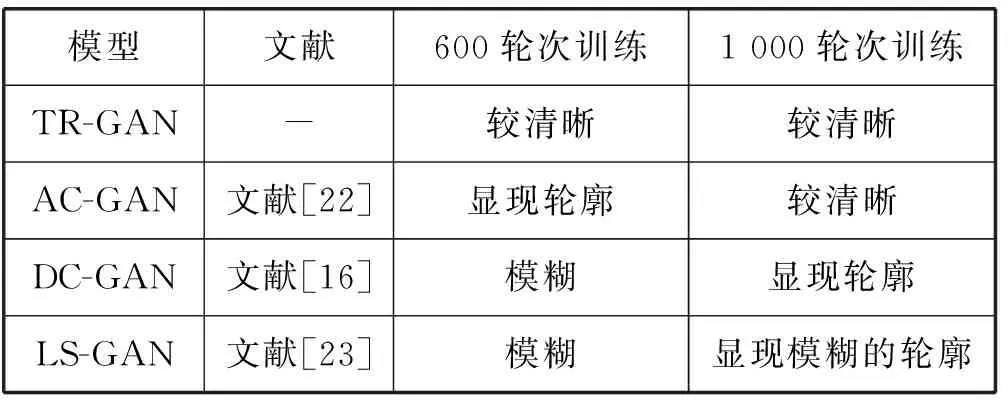
7) WHILE(i 8) FOR EACHm 9) BMP[i][m]=Feature[i*N+m] //将属性取值填入位图数组 10)i=i+1 11) END WHILE 12) RETURN BMPSET 本文随机选用训练集的6×107条实际主机样本作为训练数据,1.5×107条实际主机样本作为测试用数据。在每轮迭代之后对当前训练结果进行测试,并把该判别器的表现和相同参数下的卷积神经网络(Convolutional Neural Network)、LS-GAN、AC-GAN得到的结果进行对比,如图1-图3所示。 图1 TR-GAN与AC-GAN模型损失函数对比 图2 TR-GAN与LS-GAN模型损失函数对比 图3 TR-GAN与CNN、LS-GAN、AC-GAN的逐批次准确率对比 TR-GAN与AC-GAN模型损失函数曲线如图1所示。对模型中的生成器而言,TR-GAN中生成器的损失函数的绝对值较高但收敛更稳定,受噪声影响导致的梯度更新时的方向偏移更小。 TR-GAN与LS-GAN模型损失函数曲线如图2所示。对模型中的生成器而言,TR-GAN中生成器和判别器损失函数二者的差值相比于LS-GAN中更小,模型损失函数收敛更快。且在3 000轮以内,TR-GAN的生成器表现更好。 使用TR-GAN中判别器与相同参数下卷积的神经网络、AC-GAN的判别器、LS-GAN的判别器得到的测试结果进行对比。从图3可以看出,卷积神经网络识别准确率较低,仅约70%,与LS-GAN、AC-GAN相比,TR-GAN判别器的识别准确率更为稳定。这是由于TR-GAN的目标函数中稳定了单一损失函数在其不适宜的数据分布函数上的失效程度,稳定判别器在对模型参数进行梯度更新时选择的方向导数。 故当有较好计算条件且需要较好模型鲁棒性时或当计算资源有限并且需要较高的识别准确率时,更适用TR-GAN。 本文方法与其他相关文献方法的综合比较结果如表3所示。 表3 本文方法与其他相关方法综合比较 1) 在模型的验证方面,文献[27]和文献[31]均只提出了模型概念,并未使用实际数据验证,而本文则依据实际数据对模型进行验证。 2) 在数据规模上,文献[28]和文献[29]使用的数据集数据规模较小,本文使用了较大规模的数据,有较好的鲁棒性和泛化能力。 3) 在模型准确率方面,本文模型的识别效果相比于文献[30]更准确。 为验证TR-GAN生成器的表现,首先对比其生成器与AC-GAN、DC-GAN、LS-GAN在相同训练轮次下生成手写数字的效果,如图4和图5所示。 图4 训练轮次为600轮时手写数字生成情况 图5 训练轮次为1 000轮时手写数字的生成情况 各模型生成器手写数字生成情况如表4所示。 表4 规定训练轮次下各模型生成器生成手写数字效果 图4直观显示出TR-GAN通过较少的轮次训练,生成器就可以生成较为清楚的手写数字,相比其他三种神经网络,模型目标函数收敛更快。图5中在1 000轮次训练下,AC-GAN模型的生成器的手写数字生成效果才与TR-GAN相似,而LS-GAN和DC-GAN生成的手写数字仍处于较为模糊的状态。 通过以上对比得出,TR-GAN的生成器具有更高的样本生成效率,因此选用TR-GAN进行训练并生成主机样本相对于其他生成网络模型具有更高的效率。 同时,为验证生成样本作为系统安全管理员部署安全措施参考依据的可行性,本文从测试数据及训练后的生成样本中随机抽取一条标签为1的样本作比照分析。对每个样本属性填充并归一化后映射为灰度图,如图6所示。 图6 生成样本参考性比较 图6中,当迭代轮数达到一定次数时,由生成器生成的样本表现出了与原始样本相同的特征。生成器损失函数收敛后所产生的生成样本与原始样本的特征具有较大的相似性,并且在判别器中有相同的判别标签。再将该生成样本按照文中设置的规则重新转化回数据记录即可作为系统安全管理员部署安全规则的参考。 本文设计并实现TR-GAN系统用以辅助系统管理员对主机遭受攻击的风险进行识别,从而便于其采取相应的预防措施以及设置合适的防御等级等安全策略。并且通过主机特征模型的建立为入侵风险监测提供了新的思路。值得注意的是,本文模型可以识别出主机是否存在受攻击的风险,但对于具体受攻击的时间方面并没有相应的算法支持,下一步的研究可以围绕如何对主机受攻击的时间进行预测展开。2.4 模型判别器有效性测试



2.5 模型生成器参考性评估


3 结 语
