一种基于Off-Policy的无模型输出数据反馈H∞控制方法
2021-11-13范家璐柴天佑
李 臻 范家璐 姜 艺 柴天佑
1.东北大学流程工业综合自动化国家重点实验室 沈阳 110819
鲁棒控制理论经过多年的完善与发展,已经趋于成熟.所谓的鲁棒控制是指在扰动能量一定的情况下,仍能保证一定性能指标的控制方法.H∞控制算法是鲁棒控制的一种,通过最小化H∞指标来达到鲁棒控制的目的[1-3].文献[4-5]中指出H∞控制和零和博弈存在内在联系.即把输入和扰动看作相互博弈的两个参与者,一般在定义指标时使输入为指标的最小参与者,扰动为最大参与者.对于系统的H∞控制可以归结为求解博弈黎卡提方程(Game algebraic Riccati equation,GARE)[5-6].H∞控制虽然能保证参数在一定波动范围内的稳定性,但需要完整的系统动态模型.这大大限制了H∞的应用范围.
随着信息科学技术的发展,与生活息息相关的实际过程,如冶金、化工、电力、物流运输等方面发生了重大变化,复杂的生产设备与大量不同种类的传感器同时应用使工业过程趋于复杂.因此,这些过程在难以建立准确的数学模型的同时却产生储存着大量反映系统动态的运行数据.数据驱动的控制方法在此基础上产生.经过多年的发展,数据驱动的方法主要利用这些数据实现设计控制器,预测评估系统状态,在线优化决策,甚至诊断故障[7].而数据驱动控制是指在不使用被控过程数学模型的信息的情况下,直接利用被控系统的数据设计控制器的控制理论和方法,且经过严谨地数学论证后可以保证控制器满足一定的鲁棒性与收敛性[8].
强化学习通过启发机制来学习智能体与环境的交互策略,以优化在交互过程中的长期收益的算法[6].在控制领域中,强化学习常用来解决自适应最优控制问题[9-12].其中,Doya[13]首次将基于强化学习的控制器应用于连续系统中.在近期的研究中,强化学习应用于更加有针对性的复杂工业过程中[14-19],尤其是对难以建模的复杂工业过程进行了针对性的研究[15-17].文献[12]对数据驱动的迭代优化控制方法进行了综述性研究.文献[14]将Q-learning 应用于考虑丢包问题的网络环境中,实现了一种数据驱动的浮选过程控制方法.文献[15]考虑了输入受限情况下的数据驱动浮选控制问题,并将强化学习应用在浮选过程的双率控制中.文献[20]针对非线性系统跟踪控制问题,提出了一种基于Q-learning 的直接求解评价函数的方法,避免了求解更复杂的HJBE(Hamilton-Jacobi-Bellman equation).文献[21]针对输出调节控制问题提出了一种新型基于Qlearning 的控制方法.文献[22]针对离散时间非线性系统基于事件的最优调节控制问题,提出了一种基于启发式动态规划的事件驱动方法.文献[23]对非线性连续时间系统自适应评价控制问题进行了综述性研究.Al-Tamimi 等[24]将Q-learning 算法应用于H∞控制问题.
Off-policy 学习算法是强化学习的一种,其主要特点是在学习过程中,Off-policy 算法定义了两个不同的策略,一种是用来产生数据的策略,另一种是求解得到的目标策略[25-27].而On-policy 算法中,两种策略相同,需要将每次迭代所求得的算法代入实际环境中来产生学习所用的数据.因此,与Onpolicy 算法相比,Off-policy 算法更具可用性.同时与以Q-learning 算法[24]为代表的On-policy 学习方法相比,Off-policy 算法可以消除在学习过程中由探测噪声所产生的误差[25].换句话说,Off-policy 学习算法是一种无偏的学习方法.在基于Off-policy算法的连续系统H∞控制的基础上,文献[25] 将Off-policy 算法引入了离散线性系统H∞控制问题中,提出了需要状态反馈值的离散线性系统控制算法.其通过考察状态变化与值函数变化的关系,构造了一种与探测噪声无关的贝尔曼方程,进而提出了一种无模型状态反馈Off-policy 的H∞控制算法.
上述算法由于忽略了在某些应用条件下关键状态变量无法反馈这一问题,降低了算法在实际应用环境下的可用范围.因此,本文提出一种基于Offpolicy 的数据驱动输出反馈H∞控制算法,针对模型未知的离散线性系统模型,实现无限时域上工作点附近镇定控制的同时对能量有限的噪声进行抑制.区别与状态反馈问题,本文的反馈量是输出,本文通过构造了新的值函数,避免了直接使用状态变量.由于无法直接使用状态作为反馈,因而构造了一种增广数据向量,来解决输出反馈控制问题.在线性模型依赖在线策略迭代(Policy iteration,PI)状态反馈算法的基础上,将结合了系统历史输出数据与历史输入数据的增广数据向量作为反馈量,使在线状态反馈算法转换为模型依赖在线策略迭代输入输出反馈算法.通过引入辅助项的方法将模型依赖On-policy 输入输出反馈算法转换为无模型Offpolicy 输入输出反馈控制算法.由于采用了Offpolicy 算法,该算法具有结构简单,可以得到理论上的最优值的特点[25].除此之外,与On-policy 算法相比,Off-policy 算法的可以实现离线学习,克服了On-policy 算法只能在线学习需要频繁和环境交互的问题.在本文的最后,针对飞机短时间周期飞行姿态控制模型进行了仿真实验,以验证算法的有效性.
1 研究背景
1.1 问题描述


1.2 博弈黎卡提方程




2 数据驱动在线策略迭代学习算法
2.1 状态反馈在线策略迭代学习算法


2.2 一种由输入输出数据所组成的增广向量




结合引理1 可以看出,根据输入输出反馈数据与目标策略所得到的决策结果和根据状态数据与中间策略所得到的决策结果相同.
2.3 输入输出数据反馈在线策略迭代学习算法


3 Off-policy 输入输出数据反馈优化算法









4 仿真结果及分析
在本节中,以短时间周期飞机飞行姿态稳定控制模型为例,对算法3 的有效性与可靠性进行考察.H∞算法在该模型下的有效性与必要性已经经过验证[29-30],本文将仿真结果展示的重点放在收敛性的考察.在收敛性方面,本文从初值的选择与学习最优 策略所用数据的影响两个方面来考察算法3.
4.1 模型描述
在短时间段内飞机平稳飞行时,主要考虑迎角、俯仰速角率和升降舵偏角三者对飞机飞行姿态造成的影响.迎角是指飞机的速度矢量与机翼弦线之间的夹角.俯仰角速率是指飞行器绕横轴旋转的角速度.升降舵偏角是指飞机升降舵和平尾之间的夹角.其中,迎角和俯仰角速率可以直接衡量飞机的姿态变化.升降舵偏角的变化会造成升降舵所受到的气动力矩发生变化,进而影响飞机的飞行姿态.因此,将迎角、俯仰角速率和升降舵偏角三者作为系统的状态变量.将控制升降舵变化的升降舵执行器电压作为控制变量.考虑到飞机在平稳飞行时,迎角易受到风向与风速的干扰,将迎角所受到的扰动作为扰动变量.由于飞机的俯仰速率测量比较困难,因此可以将迎角与升降舵偏角作为输出变量.飞机飞行示意图如图1所示[30].
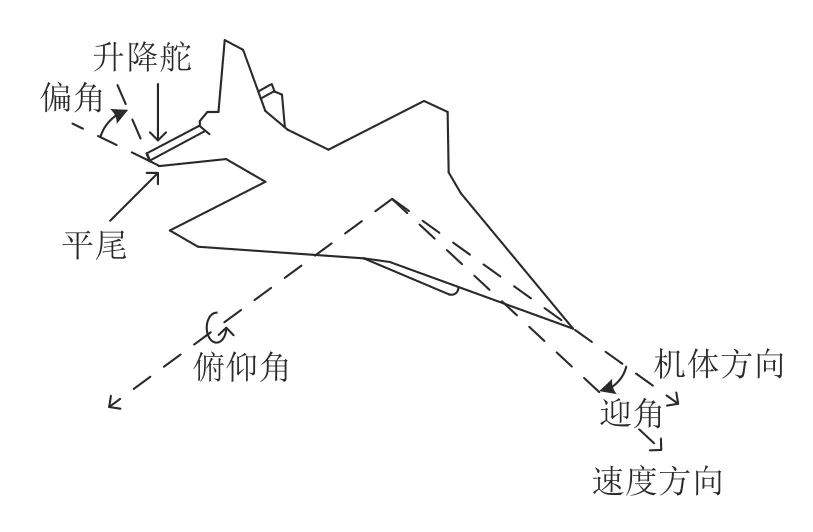
图1 飞机飞行示意图Fig.1 Aircraft flight diagram


4.2 仿真实验


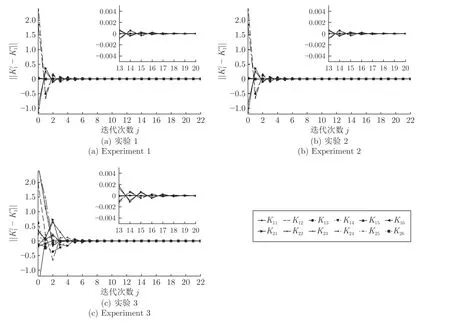
图2 三组实验参数收敛曲线Fig.2 Three groups of experimental parameters convergence curves


5 结束语
本文针对考虑扰动作用的线性离散系统,提出了一种基于Off-Policy的无模型输入输出数据反馈H∞控制方法.该算法针对性解决了状态数据反馈算法难以应用于状态无法测得的应用环境这一问题,通过引入一种由输入输出数据组成的增广数据向量将状态反馈在线策略迭代算法转换成输入输出反馈算法.并通过引入辅助项的方法,最终将输入输出反馈在线策略迭代算法转换为无模型输入输出反馈Off-policy 算法.该算法和On-policy 算法所学习得出的策略相同,且该算法在学习过程中所用的数据默认和在迭代过程中所更新的策略所产生的数据之间存在差异,这为数据驱动的离线算法和在迭代更新策略稳定的情况下再更新策略提供了可能.最后,通过F-16 飞行器仿真模型验证了该算法的收敛性与有效性.在本篇文章的基础上,仍有一些十分重要的问题值得进行研究,如 输入受限情况下的控制问题.考虑在网络控制中,存在反馈数据丢包情况下的控制问题.更进一步将本文所研究的内容延展到非线性系统中,以提高本算法的应用范围与控制效果.
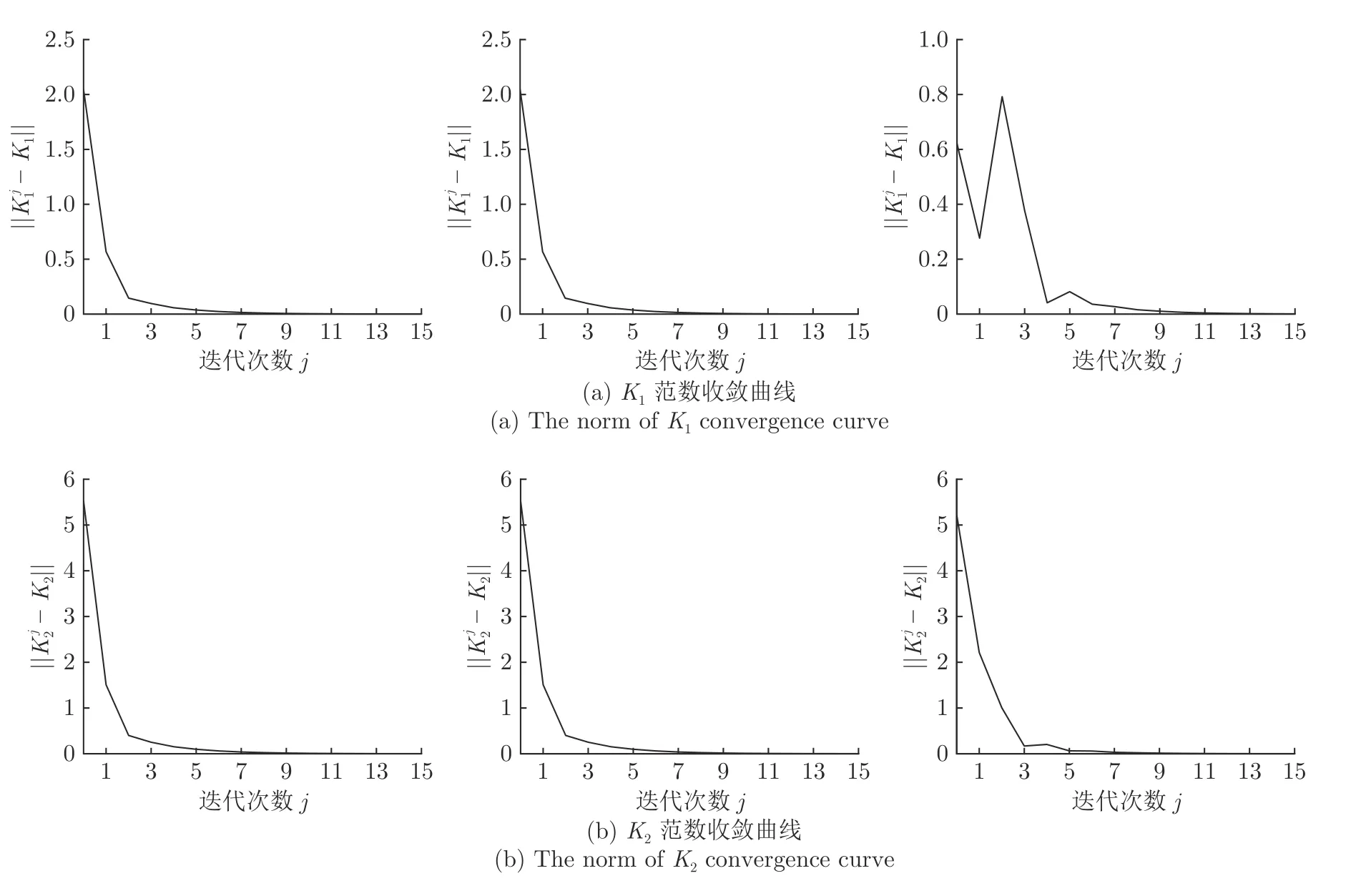
图3 三组实验范数收敛曲线Fig.3 Three groups of experimental parameters convergence curves
