基于光谱技术的草莓SSC含量无损检测方法研究
2021-11-12邱白晶
闫 润 邱白晶
(1.江苏大学农业工程研究院,江苏 镇江 212013;2.江苏农林职业技术学院,江苏 句容 212400)
可溶性固形物(soluble solids content ,简称SSC)是评价草莓内部品质的主要指标之一,为满足草莓采摘后鲜食或深加工的需要,迫切需要采取准确、无损、快捷的草莓可溶性固形物检测方法。近红外光谱技术具有绿色无污染、成本低、分析简单、高效精确等优点,在水果内部品质检测方面具有良好的应用前景。但因数学模型的预测精度低,使草莓可溶性固形物近红外光谱检测技术的应用受到了限制。
1.材料与方法
1.1 光谱的采集
实验用草莓样品采摘于镇江市句容草莓种植园,优选当地特色品种红颊草莓。实验当天,依据草莓表面着红率挑选半熟、八分熟、全熟三种成熟度的红颊草莓131个,逐一编号。采摘后用保温箱包装运输,送回实验室冷藏。近红外光谱测量所用仪器为美国ASD(Analytical Spectral Device)公司生 产的Field Spec 3型便携式光谱仪,光源为光谱仪配套的石英卤素灯,色温3200K。
采集光谱时,调整石英卤素灯光源与水平面呈45°角,用空调控制实验室内温度为20℃,相 对湿度为70%。将光谱分析仪探头固定在三脚架上,设定光纤视场为25°,根据被测物直径及视场角推算出探头高度,调整传感器探头位于工作台上方 5cm 左右处,垂直于被测物。测定过程中,将样品间隔120°采集3次数据,以3 次采集均值作为一个样品的原始光谱数据。采集的光谱如图1所示。
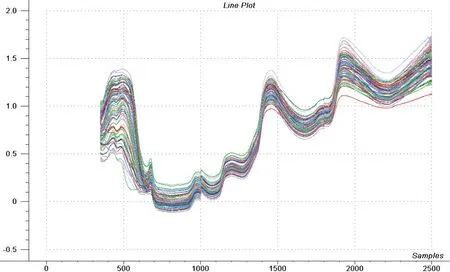
图1 草莓原始光谱
1.2 可溶性固形物的测量
每个 采集光谱后的草莓样品沿赤道圆周处切取5克果肉用研钵捣碎并研磨成半黏稠状,用纱布压滤,将草莓液汁倒入均衡烧杯中。检测时用玻璃棒蘸取草莓汁液2~3滴于折光仪棱镜平面的中央,迅速闭合棱镜,静置1分钟,读取测量值后以脱脂棉蘸酒精擦净棱镜,重复上述操作三次,取三次均值作为每个草莓样品的可溶性固形物含量的实际值。用Kennard-Stone算法对样品集进行划分,从131个草莓样品中选取101个作为校正集,剩余的31个为预测集,实验测量的草莓样品SSC实际值统计特性如表1所示。

表1 SSC的Kennard-Stone划分统计
2.实验结果预处理及特征提取
2.1 光谱预处理方法及特征提取方法
受到样品的颗粒不均、仪器的随机噪声、基线漂移、光散射等因素影响,草莓原始光谱 中掺杂了噪声信号。这些噪声信号会对草莓样品的光谱信息产生干扰,影响校正模型的预测精度,因此有必要对草莓原始光谱进行预处理。
由于草莓近红外光谱波长范围350~2500nm多达2151个变量,在全光谱内直接进行GA搜索,运算速度过慢,不利于变量筛选。若将全光谱波段划分为若干个子区间,先优选出部分区间,再在选中区间里进行GA搜索则能有效提高运算速度。因此本研究拟采用一种改进的遗传算法,即向后阈值区间偏最小二乘法(Backward interbalPLS,简称biPLS)与遗传算法相结合的算法(简称biPLS-GA)进行草莓近红外光谱信息的提取。
2.2 预处理方案确定
为了精确得到最佳预处理方案,在Unscrambler软件中采用PLS回归分析。在PLS模型中,设置主成分数为10,按照Kennard-Stone法划分131个样品的校正集和预测集分别为101和30。对30个预测及样品进行PLS预测,所得不同预处理方案下的预测集相关系数和均方根误差如表2所示。
调整主成分数进行对比,确定主成分数为10时,各预处理方法的预测效果好,故统一采用主成分数为10,在350~2500nm全波长范围内应用不同预处理方法建模,结果如表2所示。

表2 不同预处理方案的结果
从表中可以看出,在草莓的SSC含量检测的近红外光谱预处理方案中,SGF优于MAF,1D优于2D。
2.3 特征光谱的提取结果分析
为快速分析提取结果,先将全光谱(共计2151个变量)划分为10个子区间,每个区间的起止变量见表2。将SSC化学值以及分别用SGF、1D和SNV+SGF+1D三种方法预处理后的草莓吸光度光谱按照biPLS算法要求输入matlab程序中,运算得到10个区间的校正集的互验证均方根误差(RMSECV)如表3所示。
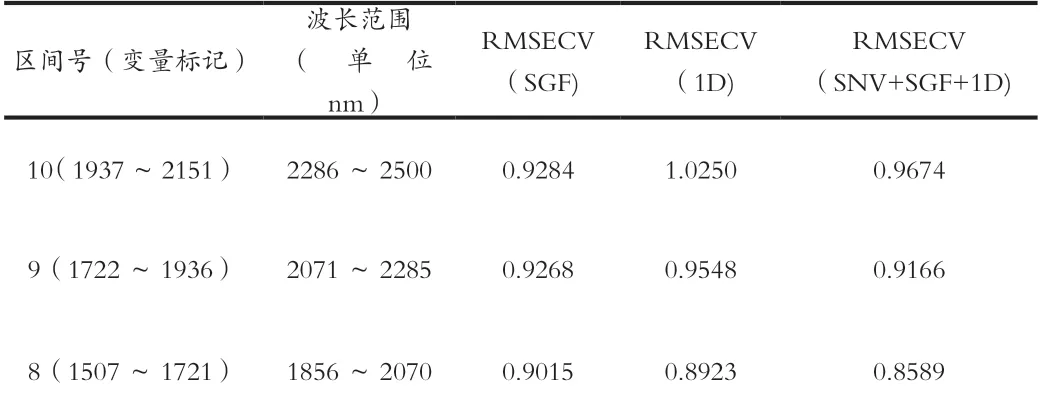
表3 预处理方法对SSC的影响
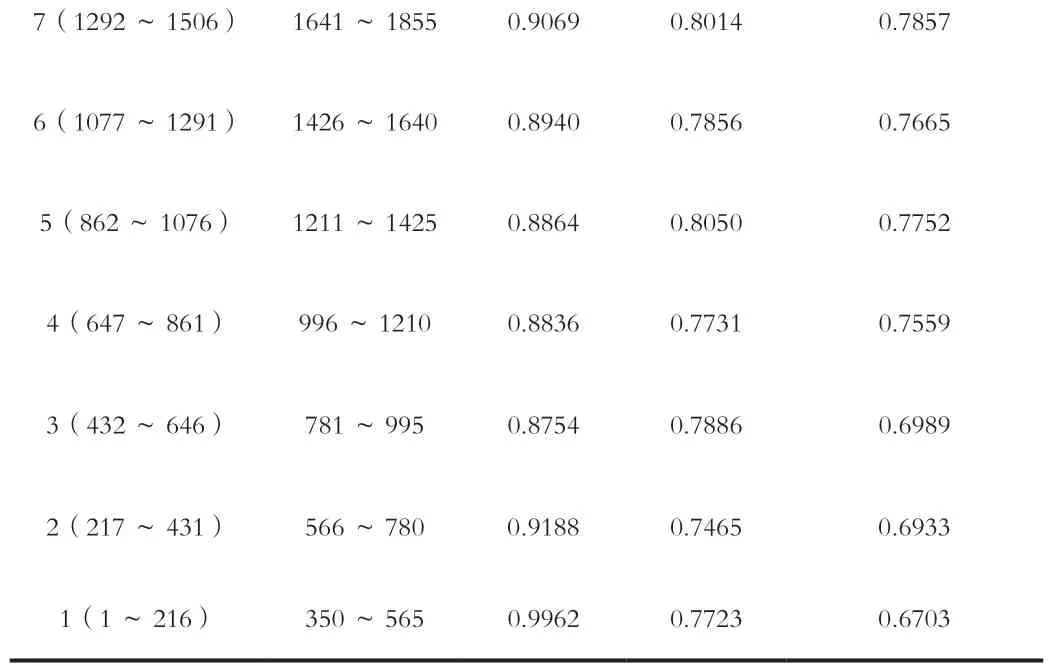
7(1292~1506) 1641~1855 0.9069 0.8014 0.7857 6(1077~1291) 1426~1640 0.8940 0.7856 0.7665 5(862~1076) 1211~1425 0.8864 0.8050 0.7752 4(647~861) 996~1210 0.8836 0.7731 0.7559 3(432~646) 781~995 0.8754 0.7886 0.6989 2(217~431) 566~780 0.9188 0.7465 0.6933 1(1~216) 350~565 0.9962 0.7723 0.6703
经过biPLS算法的光谱谱区筛选,共提取出2、3、4三个子区间,查看表3的区间变量编号,总计645个变量入选,变量数目仍较多,需要进一步筛选。下面将采用遗传算法对提取出来的645个变量继续筛选。
设定GA算法中的初始种群大小为30,染色体长度为10,变异概率为0.01,交叉概率为0.5,遗传迭代次数为100。迭代100次后,645个变量被选中的频次图。依据F准则(P<0.1)设定的频次阈值线,高于该频次阈值的变量被算法建议选中。依据GA算法的F准则频次阈值筛选出的40个变量及其对应的波长如表4所示。
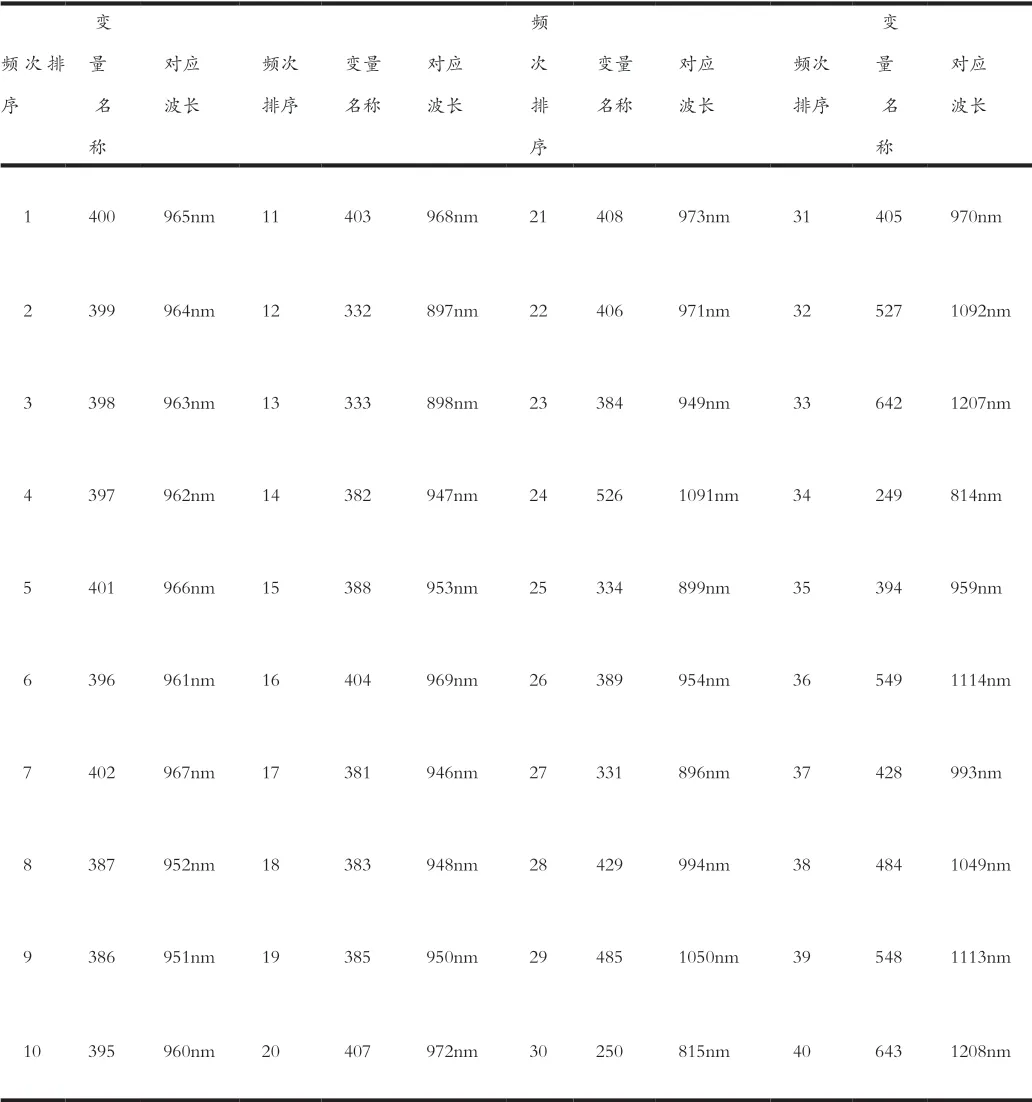
表4 GA筛选的SSC变量及其波长
3.实验结果的验证
3.1 ELM-ANN和SVR建模方法
为了解决回归拟合方面的问题,Vapnik等人在1992年在SVM分类的基础上引入ε不敏感损失函数,从而得到回归支持向量机(Support Vector Machine for regression,简称SVR)。SVR的基本思想是寻找一个最优分类面使得所有训练样本离该最优分类面的误差最小。
极限学习机(Extreme Learning Machine Artificial Neural Network,简称ELM-ANN)算法不同于上述算法,属于单隐含层前馈神经网络(Single-hidden layer feedforward Artificial Neural Network,简称SLFN),因其具有训练速度快、泛化能力强、能获取全局最优解等特点近年来逐渐成为研究热点。2005年Huang等人通过上述结构的研究,得出结论:若给定任意Q个不同样本,则对于任意的输入层与隐含层间的连接权值和隐含层的阈值b,SLFN都 可以零误差逼近训练样本,即样本的观测值。
3.2 ELM-ANN模型的建立及预测
为了验证变量提取的准确性,将由biPLS-GA算法提取的40个SSC的特征光谱作为ELM-ANN模型的输入量,设置隐含层神经元个数为30,隐含层传递函数为sig函数,建立一个40—30—1的三层ELM-ANN模型,该模型对草莓预测集的30个样品SSC的预测效果如图2所示。预测集的相关系数2R为0.93713,均方根误差mse为0.091839。

图2 ELM-ANN预测SSC
3.3 SVR模型的建立及预测
将由biPLS-GA算法提取的40个SSC特征光谱作为SVR模型的输入量。在SVM方法中,选择不同的核函数,可以生成不同的SVM。本研究采用径向基(RBF)核函数,利用MATLAB环境下的libsvm工具箱函数实现。在采用径向基(RBF)核函数计算时,主要涉及惩罚因子C和训练误差ε(这里用方差g表示)的确定。针对草莓光谱数据,利用交互验证二维网格搜索方法,寻找惩罚因子C和方差g的最优参数,具体计算实现时,分别在[-10,10]的取值范围内,设置步长为0.5,寻找最优参数,再利用该参数训练SVR模型。该模型对草莓预测集的30个样品SSC的预测效果如图3所示。预测集的相关系数2R为0.95823,均方根误差mse为0.06642。
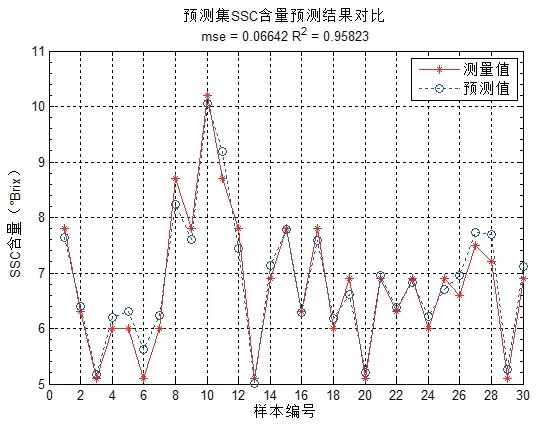
图3 SVR预测SSC
从表5中看出SVM模型对草莓SCC预测的相关系数R2分别达到了0.95823,为二者中最高;预测集均方根误差RMSEP分别为0.06642,为二者中最低,说明SVM模型的建模效果优于他三种ANN模型。因而可以得出结论,SVM算法建立的回归模型具有较好的泛化能力,能有效地预测草莓SSC的含量。

表5 草莓SSC检测的建模结果对比
4.结论与展望
通过获得品种为红颊草莓的全光谱并对全光谱进行预处理,利用biPLS算法和GA方法提取了样品的40个特征光谱,最后利用ELM-ANN和SVR建模方法对特征光谱进行了建模验证其有效性。结果表明利用SVR所建立的验证模型中,预测集的相关系数达到0.95以上,达到了较高的精度。该模型在实际应用中,可作为核心算法进行该草莓品种的固态可溶物无损检测。
