一种基于局部表征的面部表情识别算法
2021-11-12陈昌川王海宁李连杰黄向康代少升
陈昌川,王海宁,黄 炼,黄 涛,李连杰,黄向康,代少升
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.山东大学 信息科学与工程学院,山东 青岛 266000)
人脸表情识别可以识别人类面部表情,例如惊讶、悲伤、高兴、愤怒等,且面部表情识别存在广泛潜在应用[1],可用于人机交互、购物推荐、犯罪调查、医疗救助等。例如:人机交互时根据用户浏览商品表情变化推荐商品、推测喜好;刑事侦查中利用犯罪嫌疑人面部表情推测其心理变化;医疗救助时观测患者面部表情调整药品剂量等。
文献[2]提出人类情感信息有55%是通过人脸传递的,若能使用计算机读取面部信息,人机交互将会有更好的体验。基于此,1987年美国心理学家EKMAN等[3]提出面部运动编码系统(Facial Action Coding System,FACS),该系统对常见的面部肌肉运动单元(Action Unit,AU)做出详尽描述并将其具体到编码,同时,他们将人脸表情分为6种基本表情:愤怒、厌恶、惊讶、高兴、悲伤、恐惧。
在EKMAN等的研究基础上,面部表情识别已取得很大进步。通常情况下,多数方法将面部表情识别分为两步:特征提取与分类,特征提取分析面部图像并获取潜在特征,分类器根据所获潜在特征做出最优分类。特征提取是表情识别关键一步,直接影响表情识别的效果。对于特征提取现有研究将其分为两类:几何特征和纹理特征。一些研究学者[4-7]提出根据人脸特征点形变情况统计进而识别表情,建立在可靠特征点定位与跟踪之上,并根据特征点间数学特征统计求得表情分类;然而仅靠部分特征点变化分析并不能代表整幅人脸表情,导致精度不高。文献[8]提出使用Gabor滤波器与局部二值模式(Local Binary Pattern,LBP)相结合提取表情特征,在CK+[9]和JAFFE[10]数据集最高平均准确率取得82.0%与97.2%,传统纹理特征提取易受光照、遮挡等环境干扰影响。随着卷积神经网络(Convolutional Neural Networks,CNN)兴起,有学者提出将CNN特征用于表情识别,通过事先标定标签提取人脸全局特征迭代回归并取得不错的成绩[11-15],然而只有人脸全局特征,忽略局部细节特征,从而造成难以区分相似表情,例如惊讶与恐惧。文献[16]采用高斯拉普拉斯算子(Laplace of Gaussian function,LoG)对眼睛与嘴巴区域细节增强并提取面部全局特征,经后续支持向量机(Support Vector Machines,SVM)分类,采用增强细节以突出局部特征不够明显,同时面部全局特征会对局部特征提取产生干扰。文献[17]采用人脸关键点定位并在关键点周围提取适量面部突出块(Salient Facial Patches,SFP)的 LBP特征,其最高平均准确率在CK+与JAFFE数据集,分别为93.33%与91.8%;文献[18]在面部68特征点周围提取8个SFP的Hahn特征并级联采用SVM分类,最高平均准确率在CK+与JAFFE数据集,分别为91.33%与93.16%。SFP方法突出了表情局部特征,然而现有研究方法SFP选取未有依据,同时忽略了不同表情局部特征的不同比重。根据文献[19]的研究,面部6类基本表情均有FACS编码中对应的面部肌肉运动单元AU,其将6类表情AU 细细分类,并通过识别统计AU经后续贝叶斯算法分类表情;然而该方法需要大量识别AU且单个AU识别准确率低。
基于此,笔者提出表情识别算法EAU-CNN:① 该算法在人脸68个特征点基础上,依据FACS定义将面部细分43个子区域。文中统计了6类基本表情AU产生域,根据产生域与面部器官将子区域归类到8个局部候选区域AUgi,为SFP选取提供依据,并尽可能避免过多提取不同表情相近面部特征,解决了贝叶斯算法中需大量识别AU与单个AU识别率低的问题;② 为均衡提取各个局部候选区域特征,EAU-CNN采取8个并行的特征提取分支,并按照局部候选区域AUgi面积比例支配不同维全连接层。分支的输出按照注意力自适应地连接,以突出不同局部候选区域的重要程度,最终经Softmax函数将表情分为7类:中性、愤怒、厌恶、恐惧、高兴、悲伤、惊讶。其平均准确率在CK+与JAFFE数据集分别取得99.85%与96.61%,相比CNN[20]方法,提升了4.09%与22.03%,相比M-Scale[16]方法,提升了1.61%与11.86%,相比S-Patches[17]方法,提升了6.01%与10.17%。后续内容分为两部分:EAU-CNN面部表情识别算法、实验验证与分析。
1 EAU-CNN面部表情识别算法
1.1 面部分区
面部肌肉运动形成面部表情,现有做法将其分为45种。表1为部分FACS描述,它可以构成多种表情。根据文献[19]的研究,面部6类基本表情均有对应的单个或者组合面部肌肉运动单元。如表2所示,愤怒时眉毛会皱在一起、眉宇间出现竖直皱纹、下眼皮拉紧同时抬起或抬不起等,面部肌肉运动单元相应表现为AU4、AU5、AU7、AU23、AU24的其中一种或多种;厌恶时眉毛压低、上唇抬起、下眼皮下部出现横纹,面部肌肉运动单元相应表现为AU9、AU17;恐惧时眉毛皱在一起并抬起、上眼睑抬起、下眼皮拉紧、嘴唇或轻微紧张等,面部肌肉运动单元相应表现为AU4、AU1+AU5、AU5+AU7;高兴时眉毛可能会下弯、下眼睑下边可能鼓起或出现皱纹、嘴角后拉并抬高、牙齿可能会露出等,面部肌肉运动单元相应表现为AU6、AU12、AU25;悲伤时眉毛内角皱在一起并抬高、嘴角下拉、眼内角上眼皮抬高等,面部肌肉运动单元相应表现为AU1、AU4、AU15、AU17;惊讶时眉毛抬起变高变弯、眉毛下皮肤拉伸、眼睛睁大、上眼皮抬高、下眼皮下落、嘴张开、唇齿分离等,面部肌肉运动单元相应表现为AU5、AU26、AU27、AU1+AU2。

表1 部分AU描述

表2 表情相应AUs
根据FACS定义,对6类基本面部表情的面部肌肉运动单元产生区域统计,发现面部肌肉运动发生区域集中在眉毛、部分额头、眼睛与面部下半部,对于面部其他部位,如上额、颞部、部分侧面等,面部肌肉运动单元未出现在该区域,然而不同表情时该区域特征过于相像,反而会影响整体表情识别准确率。针对该问题,现有方法[18-19]是构建一定数量SFP提取特征做表情识别,然而SFP选取未考虑FACS,所提面部局部特征还不够突出。为此,根据6类基本表情肌肉运动单元产生区域,将面部划分为43个特征区域,如图1所示,并同时按照面部器官眉毛、眼睛、鼻子、嘴巴所在区域,构建8个局部候选区域AUgi,i表示1至8。每个候选区域包含一定特征区域并负责只提取属于组内的肌肉运动单元特征,分区和候选区域产生表情如表3所示。如图2(a)所示,AUg1属于眉毛与眼睛所在区域,是 AU1、AU2、AU5与AU7产生域,包含1、2、5、6、8、9、12、13、40、41、42、43面部特征区域,是愤怒、恐惧、悲伤、惊讶表情产生区域。如图2(b)所示,AUg2属于眉毛与印堂所在区域,是AU4产生域,包含1、2、3、4、5、6、8、9、12、13、40、41面部特征区域,是愤怒、恐惧、悲伤表情产生区域。如图2(c)所示,AUg3属于横向鼻子与其附近肌肉所在域,是AU6产生域,包含16、17、18、19、42、43面部特征图,是高兴表情产生区域。如图2(d)所示,AUg4属于纵向鼻子与其附近肌肉所在域,是AU9产生域,包含10、11、17、18、22、23面部特征图,是厌恶表情产生区域。如图2(e)所示,AUg5属于鼻子与嘴巴所在域,是AU12、AU15产生域,包含21、22、23、24、25、26、27、28、37面部特征图,是高兴、悲伤、惊讶表情产生区域。如图2(f)所示,AUg6属于嘴巴、下巴所在域,是AU25、AU26、AU27产生域,包含25、26、27、28、29、30、31、32、33、34、35、36、37面部特征图,是高兴、惊讶表情产生区域。如图2(g)所示,AUg7属于下巴所在域,是AU17产生域,包含29、30、31、32、33、34、35、36面部特征图,是厌恶、悲伤表情产生区域。如图2(h)所示,AUg8属于嘴巴所在域,是AU23、AU24产生域,包含26、27、29、30、31、32、37面部特征图,是愤怒表情产生区域。
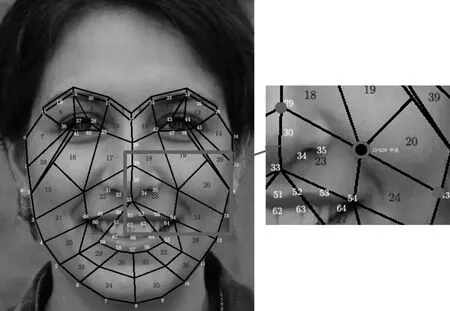
图1 面部区域分区(黑色数字为划分区 域、白色数字为68个特征点)

图2 局部区域示意图

表3 AU组包含区域
1.2 EAU-CNN表情识别算法
EAU-CNN在人脸68个特征点与上述分区基础上,组成的8个局部候选区域AUgi,采用最小矩形框思想截取图像,如图3所示。
图3 最小矩形区域示意
整体算法流程如图4所示,每个AUgi图像归一化至不同固定大小,经过各并行的CNN网络提取特征后,拼接为4 096维的全连接层。拼接的全连接层乘以不同表情权重值,以突出不同表情局部特征,经过后续特征提取与Softmax函数将表情分为7类:中性、愤怒、厌恶、惊讶、高兴、悲伤、恐惧。
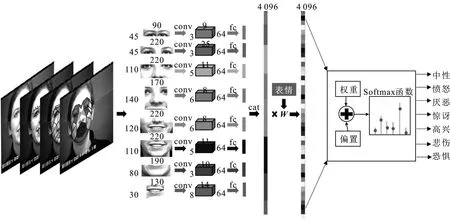
图4 整体算法流程图
AUg1包含左眼与右眼两块区域,笔者将两块区域拼接一起归化到45×90像素,经过3个卷积层与池化层提取特征后,生成64通道的3×9大小特征图,并按照各个AUgi的图像面积比例支配输出129维全连接层。AUg2将图像归化到45×220像素,同样经过3个卷积层与池化层,生成64通道3×25大小特征图,按照局部候选区域面积比例支配输出290维全连接层。AUg3将图像归化到110×220像素,经过5个卷积层与4个池化层,生成64通道5×11大小特征图,并按照面积比例输出716维全连接层。AUg4将图像归化到140×170像素,经过5个卷积层与4个池化层,产生64通道6×8大小特征图,并按照面积比例输出704维全连接层。AUg5将图像归化到120×220像素,经过5个卷积层与4个池化层,生成64通道5×11大小特征图,按照面积比例输出782维全连接层。AUg6将图像归化到110×220像素,经过5个卷积层与4个池化层,生成64通道5×11特征图,按照面积比例输出717维全连接层。AUg7将图像归化到80×190像素,经过5个卷积层与4个池化层,生成64通道3×10大小特征图,按照面积比例输出451维全连接层。AUg8将图像归化到80×130像素,经过3个卷积层与池化层,生成64通道8×14特征图,按照面积比例支配758维全连接层。将各个候选区域输出拼接得到4 096维全连接层。
1.3 损失函数
为突出不同表情局部特征,拼接所得4 096维全连接层乘以不同表情权重值Wfj,j表示1到7种不同表情。根据上述分区,文中定义G表示局部候选区域的个数,Cgi代表表情发生时产生面部肌肉运动单元的AUgi个数,i表示1到G,定义SCgi表示表情发生时产生面部肌肉运动单元的AUgi总面积和,定义Sm表示单个AUgi的面积,其中m属于1到Cgi,定义b为表情权重偏置,那么可得表情突出增强因子α,如式(1)所示。对于中性表情,均未有面部肌肉运动单元分布在候选区域,不需要特别突出某个局部候选区域AUgi特征,因此,各个候选区域输出全连接层权重参数保持不变,可得中性表情权重值Wf1为[1…,1…,1…,1…,1…,1…,1…,1…]T。愤怒表情时,面部肌肉运动单元在候选区域分布为AUg1、AUg2、AUg8,为突出该区域特征,包含发生面部肌肉运动单元的候选区域,乘以增强因子α权重值,未发生候选区域权重值保持不变,可得愤怒表情权重值Wf2为[α…,α…,1…,1…,1…,1…,1…,α…]T。厌恶表情时,面部肌肉运动单元在候选区域分布为AUg4、AUg7,候选区域突出权重值如上所述,可得厌恶表情权重值Wf3为[1…,1…,1…,α…,1…,1…,α…,1…]T。恐惧表情时,面部肌肉运动单元在候选区域分布为AUg1、AUg2,其表情权重值Wf4为[α…,α…,1…,1…,1…,1…,1…,1…]T。高兴表情时,面部肌肉运动单元在候选区域分布为AUg3、AUg5、AUg6,高兴表情权重值Wf5为[1…,1…,α…,1…,α…,α…,1…,1…]T。悲伤表情时,面部肌肉运动单元在候选区域分布为AUg1、AUg2、AUg5、AUg7,悲伤表情权重值Wf6为[α…,α…,1…,1…,α…,1…,α…,1…]T。惊讶表情时,面部肌肉运动单元在候选区域分布为AUg1、AUg6,可得其表情权重值Wf7为[α…,1…,1…,1…,1…,α…,1…,1…]T。定义各个标签实际输出为y,W为候选区域全连接层权重,定义C代表表情类别,那么可得到EAU-CNN表情识别算法损失函数A为
(1)
(2)
2 实验验证与分析
2.1 实验数据集及配置
选用CK+与JAFFE公开表情数据集进行实验验证。CK+数据集由卡耐基梅隆大学LUCEY等[9]于2010年发布,其中包含123个人的表情序列,每组表情序列是从表情的中性到表情表达的最大程度。JAFFE[10]数据集在九州大学心理学系拍摄,包含由10个日本女模特构成的7个面部表情(6个基本面部表情+1个中性)的213个图像。为了验证算法的准确性,分别选取数据集中6个基本面部表情外加中性表情共组成7类,实验采用GPU为RTX2080Ti、CPU为i5-9500、内存为16 GB、硬盘为256 GB固态硬盘,并搭建所需的软件环境:Ubuntu16.04、CUDA10.1、Cudnn7.5、Opencv3.4.3、Pytorch1.2.0,同时根据数据集特点,按照类别内训练集与测试集7∶1的比例划分训练数据与测试数据。实验所用CK+数据集除中性表情外,其他6类表情每个序列均取最大幅度表情5张。采用的CK+图像个数为5 430张,其中中性1 350、愤怒570、厌恶895、恐惧280、高兴910、悲伤275、惊讶1 150,7个情绪类别依据类别内7∶1等比例划分数据集。CK+的训练数据与测试数据图像分别为4 725张与705张。对于JAFFE数据集实验所采用图像个数为213张,其中中性30、愤怒30、厌恶29、恐惧32、高兴31、悲伤31、惊讶30,7个情绪类别依据类别按照7∶1等比例划分数据集。JAFFE的训练数据与测试数据图像分别为154张与59张。
为排除因训练集图像过少导致算法过拟合进而造成平均准确率不精确,将上述CK+与JAFFE数据集合并同时融入互联网获取与自行采集的图像,组成新的数据集命名为融合情感数据集(Fusion Emotion Datasets,FED)。该数据集与EAU-CNN训练预测代码均已上传至github。FED数据集共采用8 123张图像,其中中性 1 460、愤怒1 000、厌恶1 324、恐惧712、高兴1 341、悲伤706、惊讶1 580,并按照各个分类内训练集与测试集7∶1划分数据集,得到训练集与测试集图像分别为7 049与1 074张。假设T代表样本识别正确的个数,F代表样本识别错误的个数,可得出整体与各个分类平均准确率p的计算公式:
(3)
2.2 实验结果与分析
为了验证AUgi选取是否合理,文中选取另外2组局部候选区域进行对比验证,选取区域如表4所示。如图5所示,经测试文中所划分的区域在CK+数据集的平均准确率达到99.85%,相比于选取的特征区域1与特征区域2,分别高出6.83%与9.33%精度;在FED数据集的平均准确率为98.60%,相比于选取的特征区域1与特征区域2,分别高出8.28%与8.92%精度;在JAFFE数据集的平均准确率达到96.61%,相比于选取的特征区域1与特征区域2,分别高出11.87%与18.65%精度。可以发现,相比于面部器官区域简单选取SFP区域,根据FACS定义与面部器官区域选取的SFP区域,对平均准确率的提升起到关键作用。

图5 不同候选区域精度图

表4 对比局部候选区域特征组成
为了验证不同表情权重值Wfj对于表情识别准确率的影响,选取不使用增强因子α、使用增强因子α并采用不同偏置b的方式验证算法平均准确率。对于偏置b选取0、1、2、3、4,共5种不同偏置,如图6所示。对于CK+数据集,当采用偏置b为1时精度最高,达到99.85%的精度,相比未使用表情权重值Wfj高出0.56%。然而偏置并不是越大精度越好,对于偏置为4时,其精度为99.43%,相比未使用权重值提升0.14%,这是因为偏置的增大导致增强因子α变小,接近未使用表情权重值。对于FED数据集,当采用偏置b为1时精度最高,达到98.60%的精度,相比未使用表情权重值Wfj提升1.4%;对于JAFFE数据集,当采用偏置b为0时精度最高,达到96.61%的精度,相比未使用表情权重值Wfj提升5.09%。从实验可以看出,笔者所采取的不同表情权重值Wfj方法对于平均准确率的提升起到重要作用。
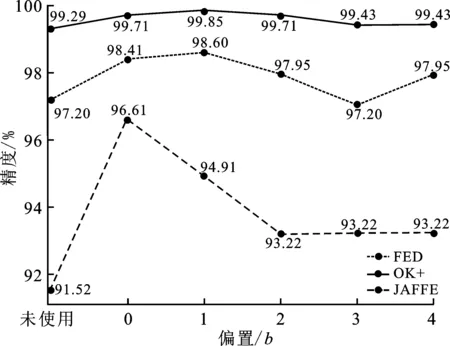
图6 不同偏置值精度图
2.3 算法对比与分析
经测试EAU-CNN算法在CK+数据集的平均准确率达到99.85%。如图7与表5所示,除悲伤分类1张图像被错误识别成中性外,其识别准确率为97.06%,其余6类均实现正确识别,识别准确率达到100%。EAU-CNN算法比CNN[20]算法识别平均准确率提高4.05%,每个分类识别准确率均超过CNN算法的,其中单个分类准确率最高提升类为悲伤分类,提升14.92%;相比于LeNet-5[21]算法平均准确率提高16.09%,每类识别准确率均超过LeNet-5的,其中单个分类准确率最高提升类为中性,提升34.63%。EAU-CNN算法比M-scale[16]算法平均准确率提高1.61%,除高兴分类识别准确率等于M-scale算法的,均为100%,其余分类识别准确率均超过M-scale的,其中单个分类准确率最高提升类为恐惧,提升4.67%;相比于S-Patches[17]算法平均准确率提高6.01%,每类识别准确率均超过S-Patches算法的,其中单个分类识别准确率最高提升类为愤怒,提升12.02%。
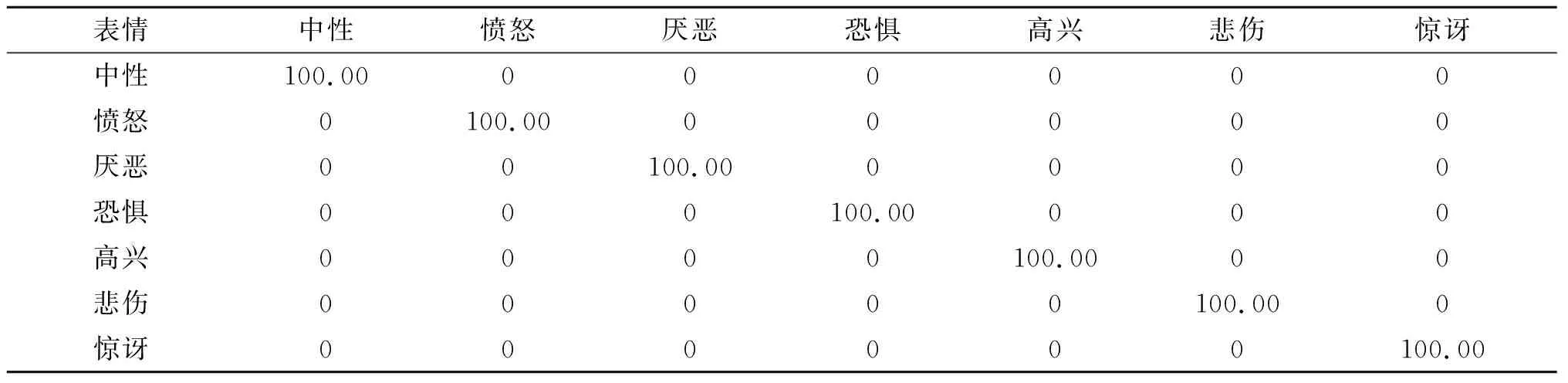
表5 EAU-CNN CK+数据集表情识别分布表 %
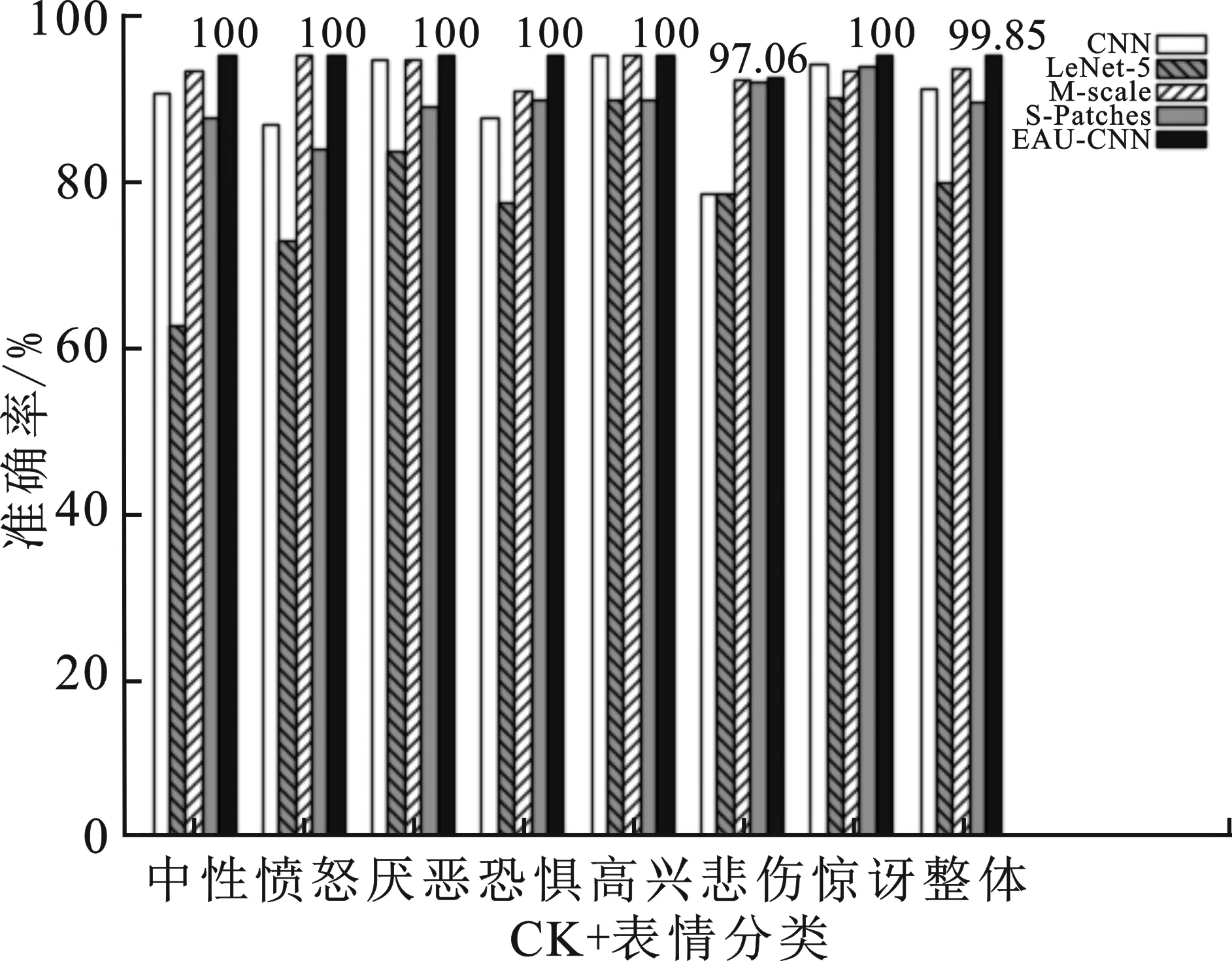
图7 不同算法CK+数据集准确率
如图8与表6所示,除厌恶分类1张图像被错误识别为愤怒,其识别准确率达到87.50%;恐惧分类1张图像被错误识别中性,其识别准确率达到75.00%,其他分类识别准确率均达到100%。EAU-CNN算法在JAFFE表现相比于CNN算法平均准确率提高22.03%,除厌恶类别与CNN算法识别准确率相等,为87.50%,其他分类识别准确率均超过CNN,其中分类准确率最高提升类为悲伤,提升30%;相比于LeNet-5算法平均准确率提高25.42%,每个分类识别准确率均超过LeNet-5算法的,其中分类准确率最高提升类为恐惧分类,提升50%。对于M-scale算法,EAU-CNN平均准确率提升11.86%,除厌恶类别准确率与CNN算法识别准确率相等,为75.00%,其他分类识别准确率均超过M-scale算法的,其中分类准确率最高提升类为中性类别,提升22.22%。相比于S-Patches算法,EAU-CNN算法平均准确率提升10.17%,除恐惧与惊讶分类准确率与其相等,为75.00%和100%,剩余分类识别准确率均超过S-Patches算法的,分类准确率最高提升类为悲伤分类,提升20%。EAU-CNN在JAFFE数据集的识别效果图如图10所示。
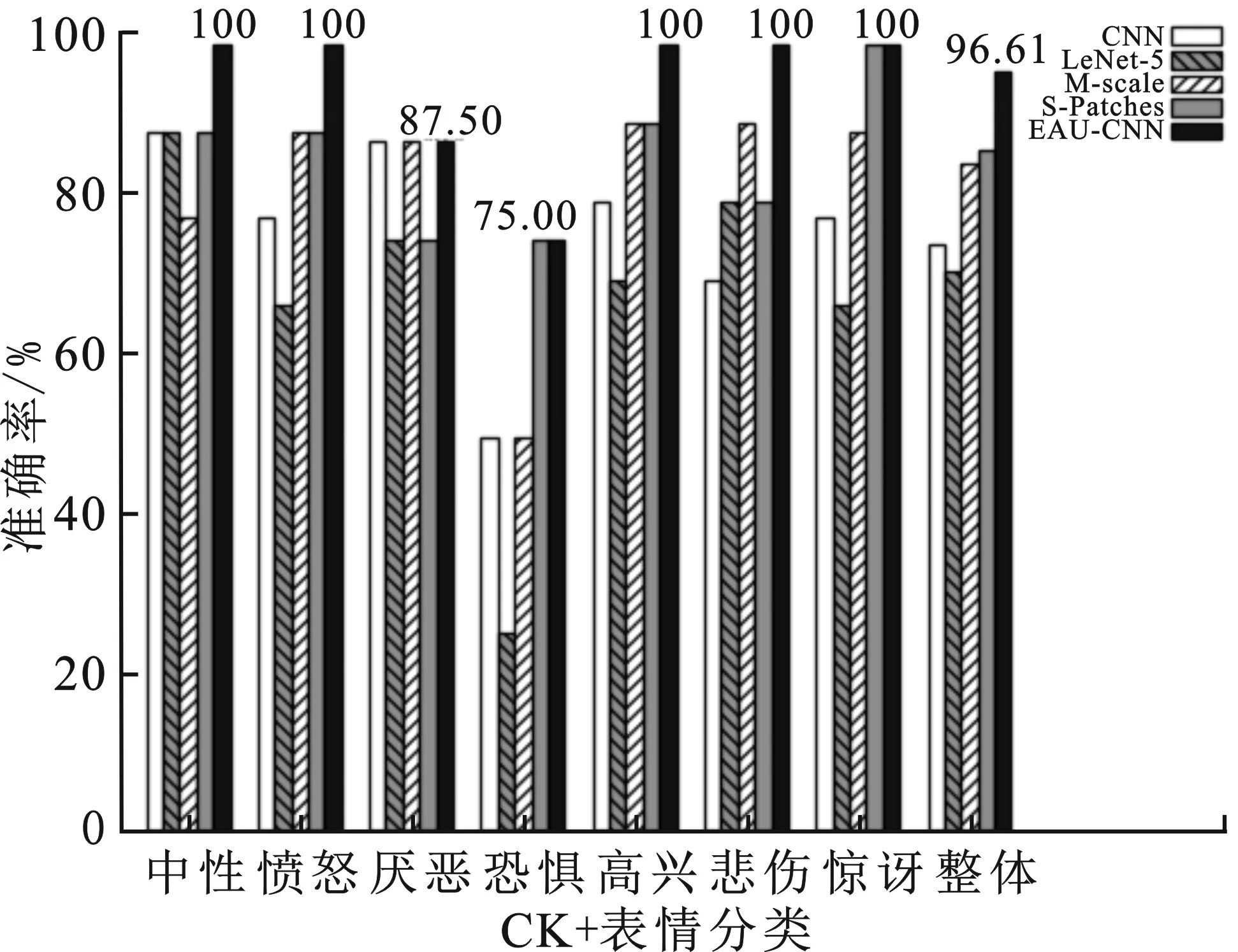
图8 不同算法JAFFE数据集准确率
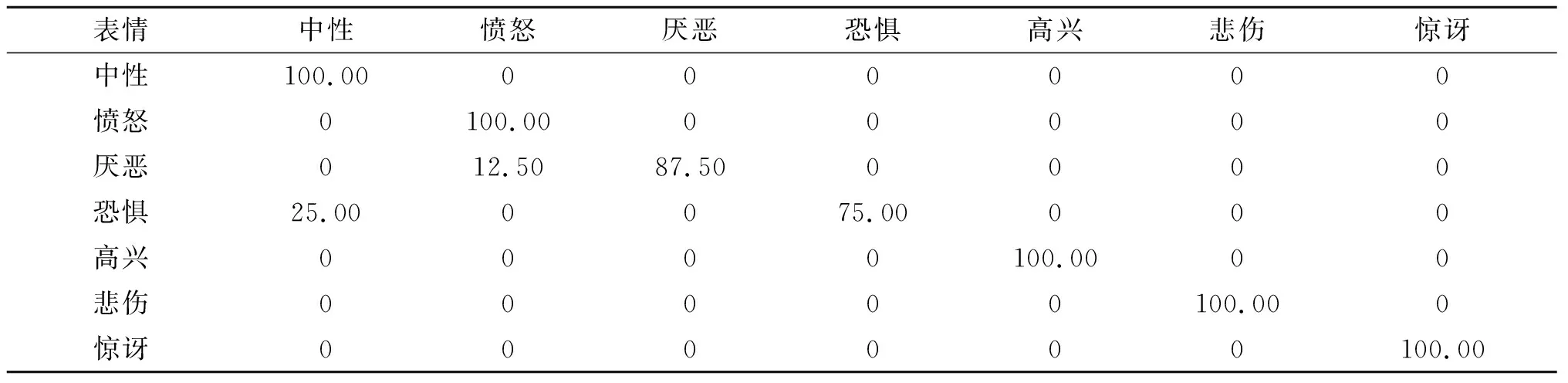
表6 EAU-CNN JAFFE数据集表情识别分布表 %
EAU-CNN算法CK+数据集识别效果图如图9所示。经测试EAU-CNN算法在JAFFE数据集的平均准确率达到96.61%。为了测试算法的鲁棒性,在FED数据集上,采用K折线交叉验证。该做法将全部图像划分K段,K次训练时保留第K段作为测试集,其余段作为训练集,求得K次训练测试集的准确率均值。根据训练集与测试集划分通常做法,取K值为8,全部图像按照类别划分为8段。如表7所示,经测试EAU-CNN算法平均准确率达到98.29%,CPU平台每帧耗时50.25 ms,相比S-Patches算法平均准确率提升6.09%,除厌恶、恐惧分类外,剩余分类准确率均超过S-Patches算法的,耗时增加44.39 ms;相比M-scale算法,平均准确率提升4.54%,所有分类准确率均超过M-scale算法的,耗时增加43.82 ms。EAU-CNN相比CNN算法,平均准确率相差不大,提升1.99%,但耗时缩短1 300.76 ms;相比于STNN算法,平均准确率提升16.31%,耗时增加49.02 ms,所有分类准确率均超过STNN算法。可以发现文中所提表情识别算法,无论在小型数据集还是大型数据集,平均准确率均达到同类表情识别算法中最高且耗时适中。其次,文中算法还具备一定鲁棒性,通过在FED数据集交叉验证,平均准确率仍在同期算法中达到最高。图11为部分算法对比效果图,S-Patches算法存在识别错误,剩余算法均实现正确识别。

图9 CK+数据集EAU-CNN算法效果图 图10 JAFFE数据集EAU-CNN算法效果图

表7 算法对比 %

图11 部分算法效果图
3 工作展望与结束语
笔者提出一种新颖的表情识别研究方法。该方法基于面部肌肉运动单元,并行均衡提取局部表征,并按照注意力自适应连接,对提高表情识别准确率起到重要作用。相比其他算法,该算法解决了整体面部特征不突出与SFP方法忽略面部肌肉运动等缺点,同时结合SFP突出局部表征与采用AU分区等优点,在CK+与JAFFE数据集平均准确率达到99.85%与96.61%,相比整体面部特征方法LeNet-5提升16.10%与25.42%,比一般SFP方法S-Patches提升6.06%与10.17%。研究工作中忽略了提取特征后降维,提取大量特征数据将大幅增加训练时长。特征提取后的降维,将是下一步重点研究工作。
