维度情感模型下的表情图像生成及应用
2021-11-12杨静波赵启军吕泽均
杨静波,赵启军,2,吕泽均
(1.四川大学 计算机学院,四川 成都 610065;2.西藏大学 信息科学技术学院,西藏自治区 拉萨 850000)
面部表情是一个人表达情绪最直接的形式之一。由于人机交互的发展,许多领域开始关注人脸表情识别。近几年深度学习方法显著提升了人脸表情识别准确率,但在实际应用中仍存在一些问题:首先,深度学习需要大量训练数据,但现有人脸表情数据库不足以训练出在实际应用中能产生可靠结果的深度神经网络;其次,不同个体的差异,如表达情绪的方式和表情强度的差异,也会给人脸表情识别带来挑战[1]。
现有大多数表情识别方法一般基于文献[2]提出的6种基本表情:高兴、厌恶、惊讶、悲伤、愤怒和恐惧,以及中性表情,共7种表情类型进行分类。然而,这样分类过于离散,忽略了情绪的连续性和复杂性。情绪也会有强弱之分,如高兴可以分为:微笑、开心和兴奋。现有表情识别往往忽略了这一点,缺少表情强弱分布均衡的大规模数据库。
针对上述问题,笔者提出了在Arousal-Valence空间中基于生成对抗网络的表情图像生成方法AV-GAN,对不均衡训练数据进行数据增强,可提高表情识别模型的准确率。AV-GAN基于Arousal-Valence情感模型划分表情空间[3],利用Arousal-Valence值表示表情类别以体现表情的复杂性和连续性。为了生成高质量的人脸表情图像,AV-GAN引入了身份控制模块和表情控制模块,分别控制合成图像中的身份信息和表情信息。为了解决训练数据规模较小和数据分布不均衡的问题,基于表情在Arousal-Valence空间中的连续性,该方法使用标记分布[4]表示人脸图像中的表情,使拥有较少甚至缺少训练样本的表情也能包含在训练数据中。
1 相关工作
1.1 Arousal-Valence情感模型
量化面部情感行为的模型一般分为3类[5]:①分类模型。从情感相关类别中选取代表性的情感分类,如文献[2]提出的6种基本表情;②维度模型。在连续的情感区域内选择一个值来代表情绪;③面部动作编码系统模型。所有的面部动作都由动作单元[6]表示。
Arousal-Valence情感模型是一个维度模型,从Arousal和Valence两个维度描述情感。在Arousal-Valence空间中,Arousal代表激活度(activation),取值从-1到1代表情感从平静到激动。Valence代表愉悦度(pleasantness),取值从-1到1代表情感从消极到积极。基于Arousal-Valence情感模型[3],根据Oulu-CASIA数据库的实际情况,将Arousal-Valence空间按图1进行划分。按间距0.1将Arousal-Valence两个维度各划分为21类,共21×21个表情粒度,用来表示更连续和更多样的表情。
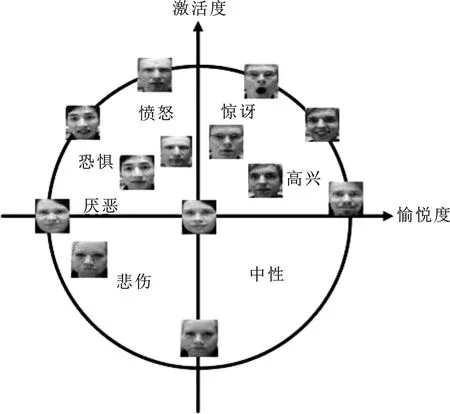
图1 Arousal-Valence空间划分以及基本表情在其中分布
1.2 人脸表情编辑
人脸表情编辑一直受到学者们的关注。随着深度学习的发展,人脸表情编辑方法慢慢转变为以基于深度学习的方法为主流。其中生成对抗网络在近几年越来越多地被用于人脸表情编辑。AttGAN[7]在生成对抗网络的基础上,加入重建部分和属性分类器对人脸的属性进行编辑。IA-gen[8]和Comp-GAN[9]更关注于表情编辑,但其生成的表情仍是更关注于传统的表情类别,忽略了表情的强度。ExprGAN[10]结合条件生成对抗网络和对抗自编码器,提出了可控制表情强度的表情编辑模型。
与文中工作比较接近的是文献[11]提出的连续标签人脸表情编辑,其在ExprGAN的基础上,引入Arousal-Valence二维空间表示表情。笔者提出的方法与之相比有如下3个特点:①实现了在小规模数据库中的应用;文献[11]的训练数据来自AffectNet 数据集[5],共10 000 000个训练样本,而文中训练数据来自Oulu-CASIA,共10 000万个训练样本;笔者提出的方法能在小规模训练数据上有很好的表现;②文献[11]生成的图像分辨率为96×96,文中方法能生成更高分辨率的图像(128×128);③文中方法在传统7种基本表情的基础上对Arousal-Valence进行划分,更有助于提升传统表情识别的准确率。
1.3 生成对抗网络
生成对抗网络[12]是现今主流的生成模型之一。生成对抗网络由生成器和判别器两个网络组成,通过两个网络在训练时相互对抗来达到最好的生成效果。生成器网络训练产生生成数据来欺骗判别器,让判别器网络以为其是真实数据,判别器网络则在训练中试图区分真实数据和生成数据,这是一个博弈的过程。传统生成对抗网络的输入是随机噪声,通过生成器生成图像[13]等。条件生成对抗网络在传统生成对抗网络的基础上加上了约束条件[14],起到对生成对抗网络的监督作用,用以控制输出。数学模型可表示为
(1)
其中,G表示生成器,D表示判别器,x表示真实数据,z和y分别表示随机噪声和约束条件。
2 AV-GAN方法
AV-GAN的输入为128×128的原始人脸表情图像xs和表情标签fexp,输出为保留xs身份信息拥有fexp表情信息的128×128的人脸表情图像xt。AV-GAN的网络结构如图2所示。
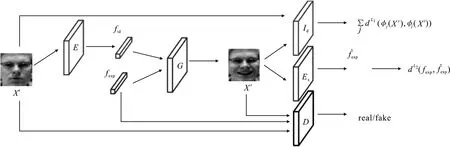
图2 AV-GAN网络结构
2.1 网络结构
AV-GAN首先经过编码模块E将人脸表情图像xs∈R128×128×3转化为包含身份信息的特征fid∈R50;然后将表情标签(V,A)转化为包含表情信息的标记分布fexp∈R42;最后,通过生成器模块G,根据fid的身份信息和fexp的表情信息,生成图像xt∈R128×128×3,即xt=G(fid,fexp)。同时判别器模块D,身份控制模块Id,表情控制模块Ex分别被用于约束生成图像的真实性、身份的准确性和表情的准确性。总的损失函数可表示为
(2)
其中,λ1、λ2、λ3、λ4是不同的权重参数。各个损失函数将在后续小节具体介绍。
2.2 表情标记分布
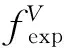
(3)
(4)
(5)
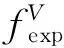
2.3 编码模块E和生成器模块G
编码模块E和生成器模块G共同完成图像生成。输入人脸表情图像xs,首先经E转化为包含身份信息的低维特征fid。这一特征和标记分布fexp共同作为G的输入,G通过解码生成具有xs身份和表情fexp的图像xt。图像生成过程的损失函数Lpix2pix通过计算xs和xt之间的L1距离(平均绝对误差)来实现:
fid=E(xs) ,
(6)
(7)
其中,L1()表示计算L1距离。
2.4 身份控制模块Id
身份控制模块Id用来确保xs和xt拥有相同的身份。Id使用预训练好的人脸识别模型,与文献[5]和文献[11]相同,文中采用VGG Face模型[1]。损失函数计算前5个卷积层的特征图之间的L1距离和:
(8)
其中,φj是VGG face前5层卷积中第j层的特征图。
2.5 表情控制模块Ex
使用fexp表示表情,表情控制模块Ex的目标是确保G学习到fexp代表的表情信息。Ex本质上是一个表情识别模型,使用在Arousal-Valence空间中用表情标记分布标注好的数据对Resnet-50模型[16]进行微调训练后获得。损失函数Lexp定义为
(9)
(10)
其中,MSE()表示计算均方误差。
2.6 判别器模块D
判别器模块D是为了确保生成图像的真实性而设置的,它的输入是xs/xt,及他们对应的表情fexp。训练D以区分生成图像xt和真实图像xs,而G则被训练以欺骗D。损失函数被定义为
(11)
其中,Pdata()表示数据分布。
3 实验结果与分析
3.1 数据库
文中的训练数据和测试数据均来自Oulu-CASIA数据库[17]。Oulu-CASIA数据库包括2 880个图像序列,这些图像序列来自80名被采集者,包含了6种基本情绪(高兴、厌恶、惊讶、悲伤、愤怒和恐惧)。每个图像序列由两种成像系统捕捉,近红外和可见光,并有3种不同光照条件。图像序列第1帧是中性表情,最后1帧是峰值表情(情感强度最强)。文中使用VIS系统正常室内光照条件下采集的480个图像序列。在大多数表情编辑和表情识别方法中,往往只使用最后3帧峰值表情图像和第1帧中性表情图像。这样会忽略表情强度的影响。为避免这一问题,文中考虑所有帧图像,并且人工对它们进行Arousal-Valence坐标标注,最终获得10 347个数据样本。数据的分布情况如图3所示。文中基于这些数据进行四折交叉验证表情识别实验。实验中,首先对所有图像中的人脸使用MTCNN[18]进行检测和对齐,并将其中的人脸区域裁剪出来缩放为128×128像素。
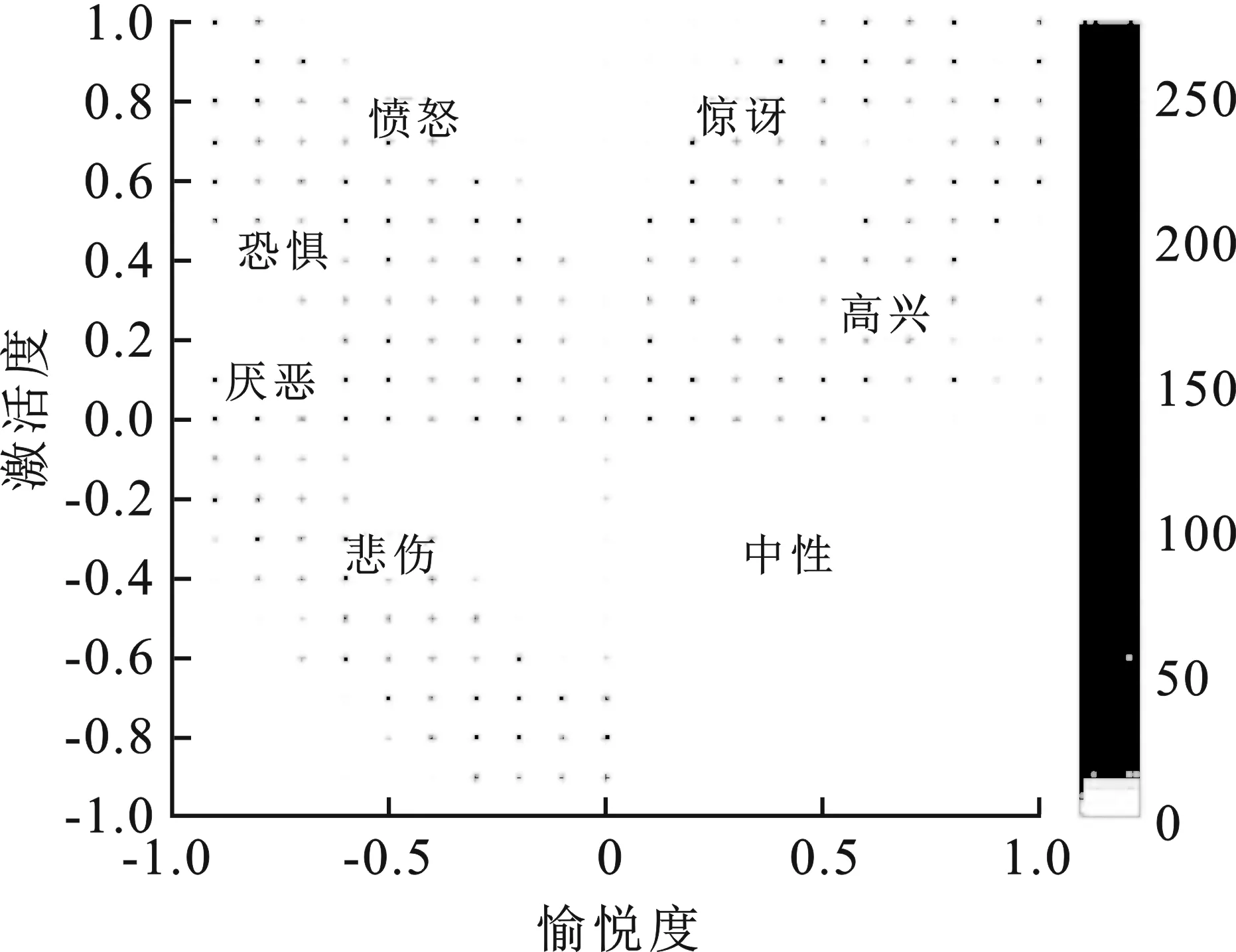
图3 Oulu-CASIA中的表情数据在Arousal-Valence空间的分布图
3.2 实现细节
如图2所示,AV-GAN主要由E、G、D、Id和Ex等五部分组成。E基于VGG-16网络[19]实现,原始VGG-16网络由5层卷积层、3层全连接层以及Softmax输出层构成,层与层之间使用最大池化(max pooling),激活函数都采用ReLU函数。文中不使用VGG-16的Softmax,并将最后一个全连接层通道数改为80,再添加一个通道数为50的全连接层,得到身份特征fid。G包含1个全连接层和7个反卷积层,卷积核大小为3×3,步长为1。全连接层和前6个反卷积层使用ReLU激活函数,最后一个反卷积层使用tanh激活函数。D包含4个卷积层和2个全连接层,层与层之间使用批归一化(batch normalization)。卷积层使用ReLU激活函数,第1个全连接层使用PReLU激活函数,最后输出使用Sigmoid激活函数。在训练E、G、D之前,先训练好Id和Ex。Id使用VGG Face模型[15]。Ex在预训练好的Resnet-50模型[16]上微调训练,使用时将原始Resnet-50的Softmax去除,并添加2个全连接层,用于预测表情。得到的Ex模型在Oulu-CASIA数据库上过拟合,虽然它的泛化能力不够好,但是在训练阶段可以很好地约束合成图像的表情信息的准确性,从而达到控制表情生成的目的。
在训练时,考虑到数据规模小,可采取两阶段训练的方法。第1阶段只有G、D、Ex参与训练,类似于CGAN,fid使用随机噪声代替,噪声服从-1到1的均匀分布。G的输入为随机噪声和fid。第1阶段损失函数为
(12)
其中,ρ1=1,ρ2=0.01。第2阶段加入所有部分,损失函数如式(2),其中,λ1=1,λ2=0.1,λ3=1,λ4=1。优化器选用Adam优化器[20],其一阶矩估计的指数衰减率设为0.5,二阶矩估计的指数衰减率设为0.999,两个训练阶段的学习率均为 0.000 1,第1阶段批大小为50,第2阶段批大小为20。
3.3 消融实验
为了验证网络结构的有效性,本节评估网络中不同模块的有效性。如图4所示,第1行为输入图像(恐惧表情),第2行为使用文中提出的网络结构AV-GAN生成图像,第3行为训练第2阶段去除Id进行训练生成的图像,第4行为训练第2阶段去除Ex进行训练生成的图像,第5行为不使用两阶段训练法,直接进行训练生成的图像(后4行从左至右为中性、高兴、惊讶表情)。
由图4可以看出,去除AV-GAN任何一部分对生成图像的影响都很大,会出现模糊、不能识别等现象。笔者提出的方法,训练第1阶段首先让网络学习如何生成图像,第3阶段加入E、Id和Ex进行微调,使网络更好地学习到身份信息和表情信息。若缺少对身份或表情的控制,则都会对生成图像造成很大影响。缺少第1阶段的训练,由于训练数据不足,会导致第2阶段训练无法正常生成图像。

图4 消融实验视觉效果图
3.4 表情图像编辑
本节验证AV-GAN的表情编辑效果。图5对比了AV-GAN与ExprGAN[10]生成的图像。第1行为输入的厌恶表情的图像,下方3列图像从左到右分别为ExprGAN生成、AV-GAN生成和真实的不同强度愤怒表情的图像。每一列从上至下愤怒强度由弱到强。从视觉效果可以看出,笔者提出的方法能更好地学习到表情和身份信息。

图5 表情编辑视觉效果图
3.5 表情图像数据增强
笔者提出的表情图像生成方法的一个应用是对表情强度不均衡的表情数据集进行数据增强。如图3所示,Oulu-CASIA数据库中表情数据分布并不均衡,大部分数据集中分布在少数表情强度。本节验证了AV-GAN随机生成的图像用于数据增强的可行性。将fid替换为随机噪声,与代表不同表情强度的fexp一起作为G的输入,生成不同身份全部表情强度的图像,如图6所示。
图7展示了图6中框选区域内的图像,这些图像对应图3框选区域,即训练数据中几乎没有的强度区域。这些结果表明AV-GAN能学习到更丰富的表情。因此通过改变输入的随机噪声就可以实现数据增强的目的。
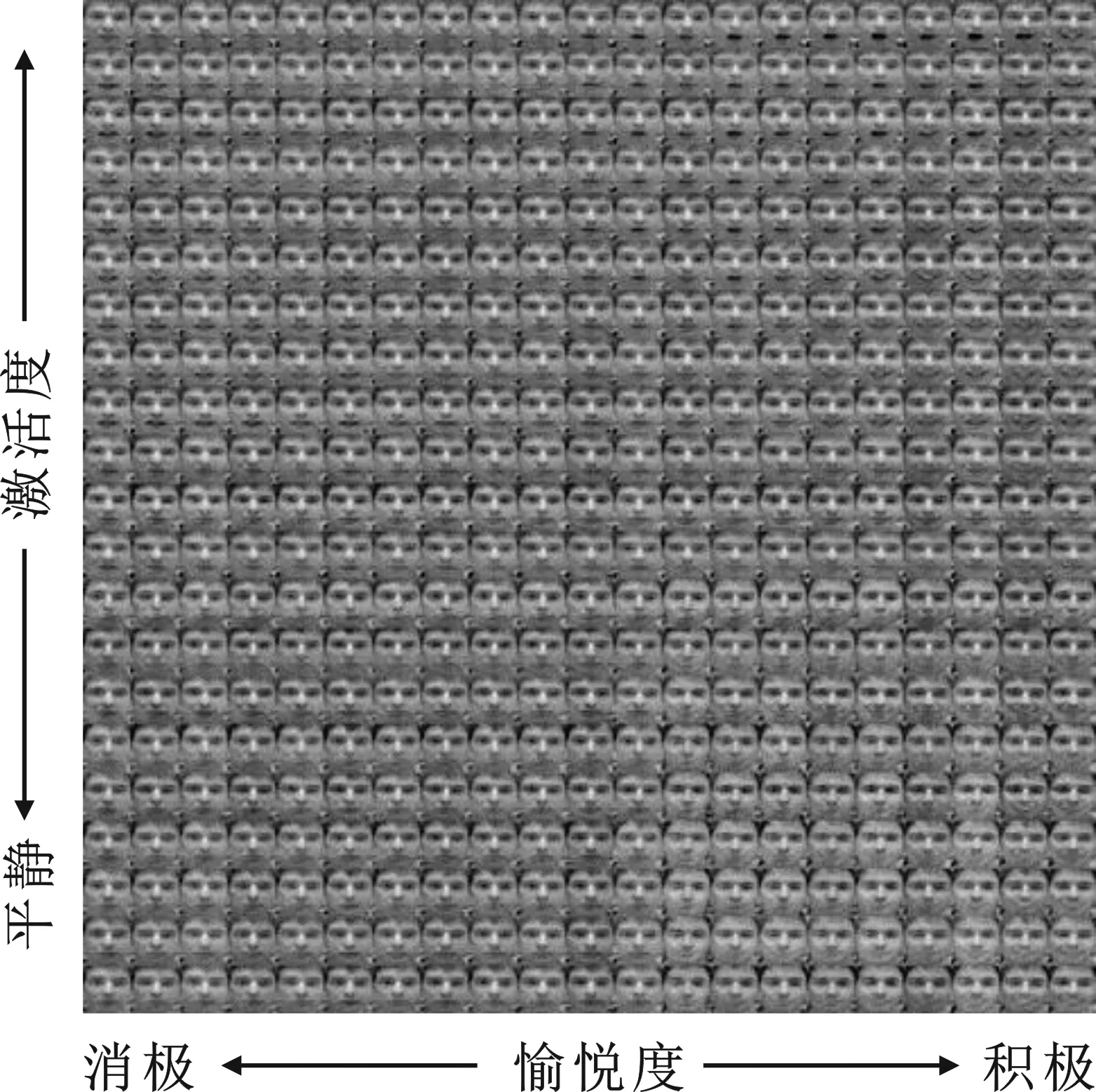
图6 全部表情强度图像生成效果图

图7 部分表情强度生成效果图
3.6 表情识别
使用AV-GAN对Oulu-GASIA数据库进行扩充,生成具有更丰富表情强度的训练数据,改善训练数据集的均衡性。为了验证如此增强后的训练数据对提升表情识别准确率的有效性,实验中使用基本的VGG-19网络[19]作为7种基本表情的识别网络。将Oulu-CASIA中的数据根据被采集者身份按四折交叉验证划分为训练和测试数据,其中60人的表情数据作为训练数据,20人的表情数据作为测试数据。作为对比,基准方法[19]直接使用不增强的Oulu-CASIA数据进行训练测试。表1和表2分别给出了基准方法[15]和文中方法其中一次验证所使用的数据分布。此外,实验中还在文献[19]上使用了文献[1]中提到的传统数据增强方法(随机镜像、随机旋转、随机裁剪)对Oulu-CASIA数据进行增强以使得数据分布与笔者提出的方法增强后的数据分布相近。AV-GAN生成的表情图像对应的7种基本表情类别按照其Arousal-Valence坐标根据图1中的空间划分得到。

表1 基准方法与传统方法数据分布
表3总结了表情识别实验的结果。由这些结果可以看出,由于原始数据的不均衡性,基准方法下的表情识别准确率在不同表情上有很大变化,而传统数据增强方法并不能有效解决这一问题。相反,使用文中方法进行数据增强后,这一问题能够得到有效缓解。但因经文中方法进行数据增强后,如图6所示,表情强度更加丰富,Arousal-Valence空间中各表情类别交叉过渡部分的数据区分度变小,如恐惧、悲伤、高兴表情数据,在数据标注时接近原点的一部分数据和中性表情较为相似,其实也一定程度上增加了表情识别的难度,导致使用文中法进行数据增强后个别表情识别准确率略有下降。但得到的总体表情识别准确率明显高于对比方法的总体表情识别准确率。
4 结束语
为了解决深度学习表情识别中表情训练数据不均衡的问题,笔者提出了在Arousal-Valence空间中基于生成对抗网络的表情图像生成方法AV-GAN,对表情强度不均衡的训练数据集进行数据增强。在Oulu-CASIA数据库上的实验结果证明,使用AV-GAN对不均衡训练数据进行数据增强可以有效提高表情识别的准确率。
