一种生成对抗网络的遥感图像去云方法
2021-11-12王军军
王军军,孙 岳,李 颖
(西安电子科技大学 综合业务网理论及关键技术国家重点实验室,陕西 西安 710071)
遥感成像技术因为能够周期性地实时得到地面的物体信息,而成为了人们关心且大力研究的方向。然而,由于天气及气候等因素的影响,比如高空中云层以及云阴影的干扰,通过卫星拍摄采集到的遥感图像通常会包含云层等无用干扰信息,进而影响遥感图像的进一步使用。因此,移除遥感图像中的云层并恢复图像原始信息,已成为一个亟待解决的热点问题。
根据处理算法的类型不同,遥感图像去云方法大致分为基于统计先验和基于深度学习两类。在基于统计先验的方法中,文献[1]提出利用暗通道先验知识(Dark Channel Prior,DCP)来解决图像去云问题。该方法虽然可以简便有效地移除云层并恢复图像,然而,根据观测统计得到先验知识,对于遥感图像并不是普遍成立。例如,当图像中的景象与大气光本质相似时,该方法得到的恢复图像会出现严重的颜色失真。文献[2]基于图像的低秩稀疏性,提出了移除时序遥感图像云层及云阴影的方法。该方法同暗通道先验法一样,只是对特定的先验场景去云才有效果,并不具备普适性。文献[3]基于分割中值滤波和自适应透射率补偿提出了图像去云雾算法,在一定程度上解决了上述问题。文献[4]在暗通道先验知识的基础上,对暗通道与亮通道先验模型进行带参线性加权运算,解决了去云效果不佳等问题。由于实际环境的复杂多变性,基于统计先验的方法不能很好地处理所有的遥感图像去云问题,很容易造成去云效果不充分或者颜色失真等现象。
随着深度学习在数字图像处理领域的广泛应用,研究者们尝试将深度学习与图像去云任务结合,达到移除云层的目的。通过使用神经网络模型不断训练并预测结果,最终得到无云的清晰图像。文献[5]基于卷积神经网络结构提出了端到端去云模型AOD-Net。该模型不需要估计传输矩阵和大气光参数等步骤,可以直接从有云图像中得到清晰的无云图像。文献[6]提出了基于注意力机制的多尺度网络模型GridDehazeNet,可以更好地缓解传统方法中去云效果不充分的问题。文献[7]针对遥感图像去云提出了SpA-GAN模型。该模型基于生成对抗网络[8],在生成器的设计上使用了空间注意力网络来更好地模拟人类视觉机制,从而更好地得到高质量无云图像。文献[9]基于生成对抗网络提出了pix2pix模型,可以完成图像到图像的转化任务,将有云图像作为输入,通过不断学习便可以得到无云清晰图像。文献[10]结合U-Net神经网络[11]和生成对抗网络提出了two-stage去云算法,可以有效地去除厚云并修复图像。文献[12]基于卷积神经网络,将云图作为输入,输出其介质透射率,之后通过大气散射模型恢复清晰图像。上述基于深度学习的方法虽然都可以达到去云的目的,但仍然存在去云效果不充分或者颜色失真等现象。此外,这些网络结构设计过于复杂,模型训练和预测时间花费较久,不能高效简便地完成遥感图像去云任务。
针对上述问题,笔者提出了一种基于端到端生成对抗网络模型对遥感图像去云。该网络模型包含了生成器和判别器两部分。生成器采用U-Net网络,可以很好地将遥感图像原始信息和云层信息分离。为了充分挖掘生成器输入信息的深度特征,在U-Net网络编码器和解码器间加入连续记忆残差模块,更好地利用流动信息来挖掘特征。判别器则使用卷积神经网络来进行判别处理。为了提高模型训练的精度,更好地测量真实值和预测值间的误差,联合对抗性损失函数和L1损失函数,来衡量网络模型的优劣。RICE数据集上的实验结果表明,与现有的去云方法相比,笔者提出的生成对抗网络遥感图像去云方法可以高效简便地得到清晰的无云图像。从具体定量结果比较来看,笔者提出的方法在RICE1数据集上平均峰值信噪比提高了1.31~7.04 dB,平均结构相似性值提升了0.007~0.123。对于RICE2数据集,笔者提出的方法比SpA-GAN、pix2pix方法平均峰值信噪比提高了3.41 dB、0.74 dB,平均结构相似性值提高了0.090、0.033,与GridDehazeNet、two-stage算法性能接近,但本算法运行时间远优于其他算法。
1 基于生成对抗网络的遥感图像去云模型
1.1 网络模型框架
生成对抗网络结构如图1所示。该网络模型主要由生成器和判别器两个模块组成。首先,将被云层污染的遥感图像作为生成器的输入,随即由生成器生成不含云层的恢复图像;接着,将由生成器生成的恢复图像和未被云层污染过的原图输入给判别器,判别器通过不断学习来评估样本是来自真实图像还是恢复图像,从而达到判断真假的目的。在实际训练时,生成器和判别器交替训练。生成器生成与真实图像数据分布类似的样本,判别器则判断输入信息究竟是来自真实样本还是来自生成的图像,两者相互博弈,从而使得整个网络可以更好地学习到数据的分布特征。
1.2 生成器结构设计
采用的生成器结构如图2所示。该结构利用编码器—解码器网络,即U-Net神经网络,作为生成器的主要框架。为了更好地提取输入特征信息,在编码模块和解码模块中间添加了具有加速网络收敛的连续记忆残差模块。

图2 生成器结构
编码模块(也叫作收缩路径)包含5个卷积层,每个卷积层之后有一个非线性的ReLU激活函数来缓解过拟合问题。为了描述方便,将“Conv+ReLU”操作看作一层。图中Ei(i=1,2,3,4,5)表示编码模块每一层的输出结果。每层卷积网络的卷积核、步长和输出通道大小分别用ki,si,ci表示。编码模块共有5层,对于第1层,设置k1=5,s1=1,c1=16。对于余下的4层,采用相同的感受野和步长大小设置,并且每一层的输出通道数量是前一层的两倍,设置为ki=3,si=2,ci=2ci-1(i=2,3,4,5)。
为了充分利用输入信息的潜在流动特征,在编码模块之后,使用连续记忆残差模块来挖掘输入信息的深度特征,如图3所示。该连续记忆残差模块由两个公共的残差模块(卷积核大小为3)和一个卷积层(卷积核大小为1)组成,它们之间使用连接操作来利用信息之间的流动特征。将X作为连续记忆残差模块的输入,则X1是输入X和第1个残差块输出的连接结果,X2是X1和第2个残差块输出的连接结果。将输入X、第1层的输出X1和第2层的输出X2合并作为卷积层的输入,最终,将卷积操作后的结果与输入X连接,作为连续记忆残差模块的输出。
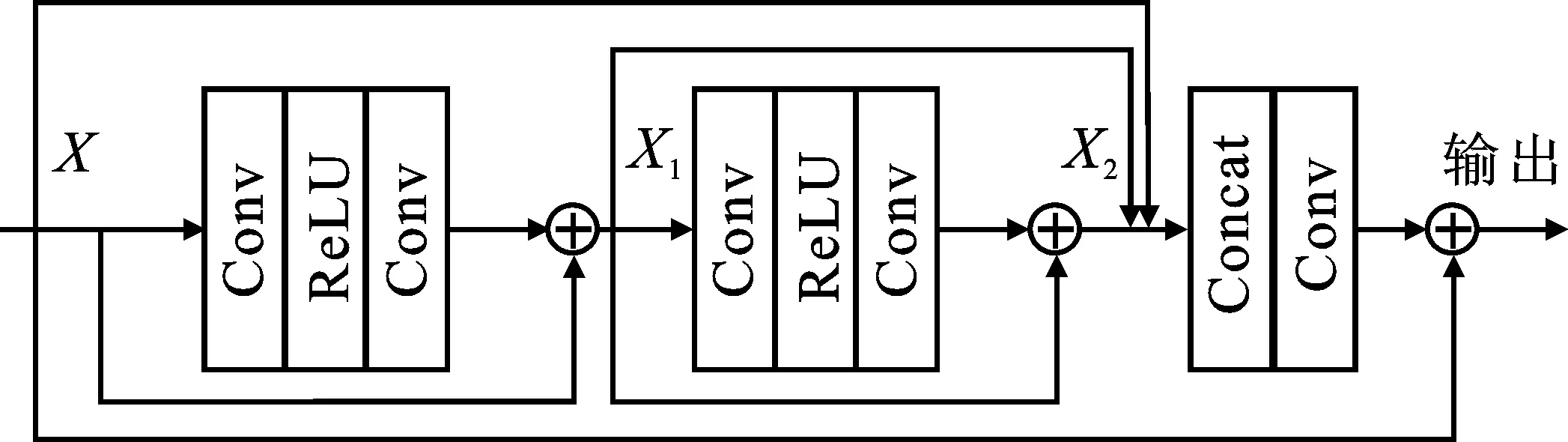
图3 连续记忆残差模块结构
解码模块(也叫作扩张路径)与上述编码模块对称,由4个反卷积层和1个卷积层组成。每个反卷积层后边同样有对应的非线性ReLU激活函数。为了描述方便,将“DeConv+ReLU”操作看作一层,最后一层只有卷积层。如图2所示,D5表示E5和连续记忆残差模块基于通道之间元素相加的结果,将其作为第一层的输入。Di(i=4,3,2,1)表示Ei和前一层的输出基于通道之间元素相加的结果,并将其作为当前层的输入。经过最后的卷积层后,可以得到生成器生成的干净图像。在本模块中,统一设置卷积核大小为3,步长为2,最后一层步长为1。
1.3 判别器结构设计
判别器结构如图4所示。图中C表示卷积层,用来提取输入的不同特征。B表示批归一化层,保证数据归一化后分布一致,从而有效避免梯度爆炸或者消失。R表示激活函数ReLU,防止网络模型过拟合。为了描述方便,将“CBR”操作看做一层,因此判别器共包含5层。此外,图中小括号内的参数分别表示输出通道数量、卷积核大小和步长。判别器的输入为一个三通道的图像,输出为判断输入的图像是否来自真实图像或者是生成图像的“真”“假”标志。
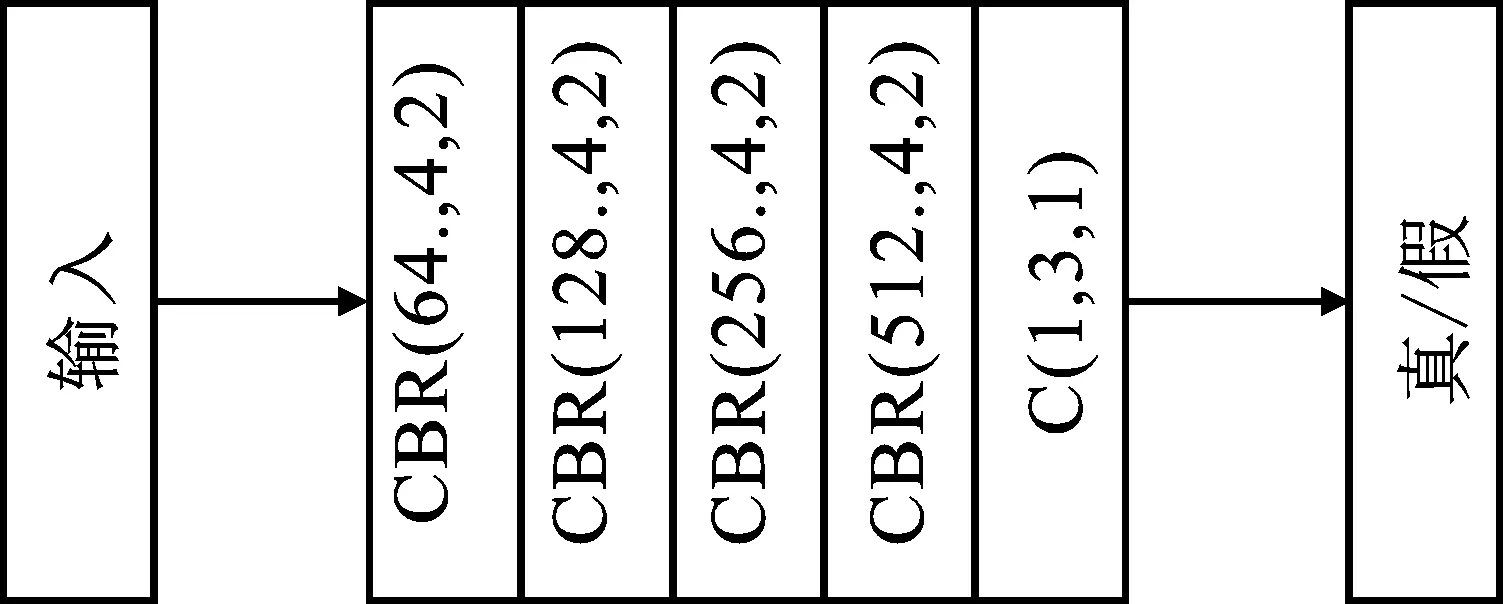
图4 判别器结构
1.4 损失函数
为了更好地提高遥感图像云层去除模型的泛化和预测能力,设计优化目标函数,由对抗性损失函数和L1损失函数两部分构成。其中,对抗性损失函数用来优化和学习生成数据与目标数据之间的信息分布;L1损失函数用于衡量真实图像与生成图像像素点之间的误差。
基于上述生成对抗网络模型的设计,采用对抗性损失函数LGan(G,D),表示如下:
LGan(G,D)=Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1-D(G(z)))] ,
(1)
其中,z表示随机噪声,x表示真实图像,pz(z)表示从z中采集样本,pdata(x)表示从x中采集样本,D(x)表示对真实图像x进行判别,G(z)表示生成器的样本输出。
在对抗性损失函数的基础上,添加了一个L1损失函数来进一步优化目标函数。L1损失函数可以定量地测量真实图像与生成图像之间的误差。同时,文献[13]证明了与均方误差函数相比,L1损失函数对异常值不敏感,可以有效地防止梯度爆炸问题。定义L1损失函数L1(G)如下:
(2)
其中,Iinput是输入的被云层污染的图像,Ioutput是原始真实图像,并且Ψ(Iinput)是笔者提出的网络模型的预测结果图像,C、H、W分别表示图像的通道数量、高度和宽度。
笔者提出的网络模型所使用的整体损失函数Ltotal由上述两个损失函数共同组成来参与模型的优化,定义如下式:
(3)
其中,λ表示平衡参数,用来平衡对抗性损失和L1损失之间的权重。
2 实验结果及分析
2.1 实验设置
使用RICE数据集,该数据集包含RICE1数据集和RICE2数据集。其中,RICE1数据集收集自谷歌地球,共包含500组分辨率为512×512的真实图像和薄云图像;RICE2数据集来源于Landsat8数据集,共包含736组分辨率为512×512的真实图像和厚云图像。
笔者使用ADAM优化器来训练和优化,优化器中的参数β1和β2分别设置为0.5和0.999,学习率设置为0.000 4,损失函数中的平衡参数λ设置为1。针对RICE1数据集,随机选择400组图像作为训练集,100组图像作为测试集。同样地,在RICE2数据集上,随机选择588组图像作为训练集,148组图像作为测试集。统一选择批量大小为1进行训练和测试迭代次数设置为200。
实验所使用软硬件运行环境如表1所示。

表1 实验软硬件运行环境
2.2 定量结果分析
为了验证笔者所提去云算法的有效性,使用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural SIMilarity,SSIM)两个统计度量指标与现有去云方法进行对比。同时,对各模型处理单张图片的运行时间进行测试,来验证各模型的算法复杂度。
对于RICE1数据集,选择DCP[1]、SpA-GAN[7]、pix2pix[9]、GridDehazeNet[6]作为对比方法。如表2所示,笔者提出的算法在RICE1数据集的100张测试集上的平均性能指标最好。从具体数值比较来看,笔者提出的(文中)算法比DCP、SpA-GAN、pix2pix、GridDehazeNet在峰值信噪比方面平均提高{7.04,3.43,1.31,2.44}dB,在结构相似性指标方面平均提升{0.123,0.033,0.007,0.026}。另外,笔者提出的模型运行时间要远小于其他算法的时间。

表2 不同算法在数据集RICE1上的定量结果比较
对于RICE2数据集,该数据集包含较多厚云图像,DCP方法并不适用于厚云数据集,因此选择SpA-GAN、pix2pix、GridDehazeNet、two-stage[10]作为对比方法。如表3所示,与SpA-GAN和pix2pix算法相比,笔者提出的(文中)算法平均峰值信噪比提高了{3.41,0.74} dB,平均结构相似性值提高了{0.090,0.033}。虽然笔者提出的(文中)算法在此数据集上平均量化性能与GridDehazeNet、two-stage算法接近,但本算法运行时间相对约减少了69%和78%,处理速度最快。

表3 不同算法在数据集RICE2上的定量结果比较
表4列举了不同算法的参数量和GFLOPs(每秒10亿次的浮点运算数)定量结果。通过比较,可以看出参数量是同一数量级时,笔者所提算法的GFLOPs计算量最低。综合来看,笔者所提出的(文中)算法具有更低的算法复杂度。

表4 不同算法的参数量和GFLOPs定量结果比较
2.3 主观视觉评价
图5列举了笔者所提算法与其他对比算法在RICE1薄云数据集上的去云视觉效果。从图中可以看出,基于传统统计先验的DCP算法去云结果不是很满意。基于深度学习的SpA-GAN、pix2pix、GridDehazeNet算法,尽管它们可以从输入的云图中去除云层而得到干净的恢复图像,但是往往会造成过分去云或者去云不充分的效果,在视觉效果上表现为恢复的结果看起来偏暗色基调或者有一些残留的云层没有去除干净。相反,笔者所提出的(文中)算法的去云效果图保存了更清晰的物体轮廓,颜色几乎没有失真,视觉上看起来更为接近原始图像信息。

图5 不同算法在RICE1数据集的视觉效果比较图
图6给出了不同算法在RICE2厚云数据集上的去云视觉效果对比。从图中可以看出,尽管SpA-GAN算法可以移除厚的云层,但其恢复结果与原图有较大差矩,颜色失真严重,且厚云覆盖区域会产生一些伪影。pix2pix算法则在移除厚云的过程中产生了许多模糊的像素点。two-stage算法虽然可以移除云层得到地面物体信息,但是其恢复的图像与原始图像信息差距较大,不能达到去云的效果。而笔者所提的文中算法与GridDehazeNet算法相比,可以得到比较清晰的物体信息,主观视觉上更为接近原始图像,能够实现较好的恢复结果。

图6 不同算法在RICE2数据集的视觉效果比较图
3 结束语
针对遥感图像在获取过程中受到云层干扰的问题,笔者提出一种基于生成对抗网络的遥感图像去云方法。该模型采用U-Net网络作为生成器,将遥感图像原始信息和云层信息分离,利用连续记忆残差模块来充分挖掘生成器输入信息的深度特征,联合对抗性损失函数和L1损失函数来提高模型的泛化和预测能力。实验测试结果表明,笔者提出的模型在峰值信噪比(PSNR)、结构相似性(SSIM)性能指标和主观视觉效果方面均优于现有的去云算法,同时具有更低的算法复杂度。
