一种LSTM与CNN相结合的步态识别方法
2021-11-12戚艳军孔月萍王佳婧朱旭东
戚艳军,孔月萍,王佳婧,朱旭东
(1.西安建筑科技大学 机电工程学院,陕西 西安 710055;2.西北政法大学 商学院,陕西 西安 710063;3.西安建筑科技大学 信息与控制工程学院,陕西 西安 710055)
步态识别是通过走路的姿态对行人身份进行识别,具有非接触、非侵入、难伪造、可远距离获取的特点,在安全监控、医疗诊断等领域有着广阔的应用前景[1]。由于步态受外部环境(拍摄视角、路面等)以及行走条件(着装、携带物等)的影响较大,因此,挖掘并学习与视角无关的、可抵御行走条件变化的步态特征是步态识别研究的热点之一。
现有步态识别方法多使用由图像或视频序列生成的类能量图(如步态能量图、运动轮廓图等)进行表观建模。基于表观建模的跨视角步态识别方法有聚类视角估计[2-3]、投影映射法[4-5]、视觉转换法[6-7]等。近年来,使用深度学习实现跨视角步态识别的方法不断涌现,这些方法利用卷积神经网络(Convolutional Neural Networks,CNN)[8-9]、3D CNN[10-11]的层级抽象特征提取能力,提取类能量图中与视角无关的时空特征;文献[12]采用GaitGAN网络解决视角、衣着等因素对步态识别性能的影响。这些方法较好地应对了步态识别中的视角变化难题,但是类能量图本质上是步态特征的二维表达,在视角跨度较大的情况下,识别性能急剧下降。同时,部分类能量图在步态叠加过程中也会造成步态时序信息以及细粒度的空间信息丢失问题。
还有学者使用基于模型的步态识别方法。这类方法对人体结构和姿态信息进行特征建模。文献[13]利用Kinect传感器采集的人体骨架数据研究步态,结果表明人体关节包含足够的信息描述步态特征。从步态信息的三维本质出发,文献[14-15]尝试使用三维成像设备或在多摄像机协作环境下重构人体的三维步态模型,但复杂的摄像机参数调整及建模计算限制了应用场景。随着人体姿态估计方法[16]的不断成熟,研究人员可以利用人体姿态估计从图像或视频中实时获取关节姿态信息,这为基于模型的步态识别方法带来了曙光。文献[17]利用姿态估计从视频序列中提取二维关节姿态,构建PTSN网络获取关节序列的时空变化特征,在相同视角下取得了较好的效果,但没有在跨视角场景下验证模型的有效性。文献[18]构建了姿态长短时记忆模块(Pose-based LSTM,PLSTM)对人体的12个关节热图序列进行视角重构,消减了视角变化对步态识别的影响,但是难以同时对3个以上跨视角步态序列进行视角重构。最近,LIAO等[19]首先使用三维姿态估计直接从视频中获取人体关节的三维坐标,并建立关节姿态模板;然后通过卷积神经网络提取关节运动的时空特征。该方法计算简单,在跨视角场景下获得了较好的识别率。在此基础上,该方法还可以进一步考虑挖掘关节姿态的时序特征。
综上可知,步态的三维建模对视角变化具有较高的鲁棒性。而在一定运动周期中,视频行人的关节运动及身体结构变化存在时序相关性,可以利用行人步态的三维数字特征构建步态的时空运动特征模型,进而利用深度网络挖掘行人关节点的三维深度时空运动特征,可有望提高跨视角步态识别的准确率。
1 人体姿态特征建模
人体运动时关节夹角以及关节间的相对位置关系呈周期性变化,且下半身的运动变化较上半身更为明显。关节之间的夹角、足部与行进方向的夹角、身体重心摆动以及身体结构比例等变化关系相互作用、相互约束,形成一个有机的整体,能够反映行人的步态变化特点。此外,每个人运动的快慢、位移变化状况也能通过关节位置来表达。这些关节点间的关系在三维空间并不随拍摄视角而变化,满足视角不变性。因此,利用三维空间下的关节运动约束关系和关节位移变化规律可以综合表达步态的时空特征。
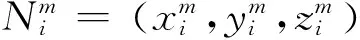
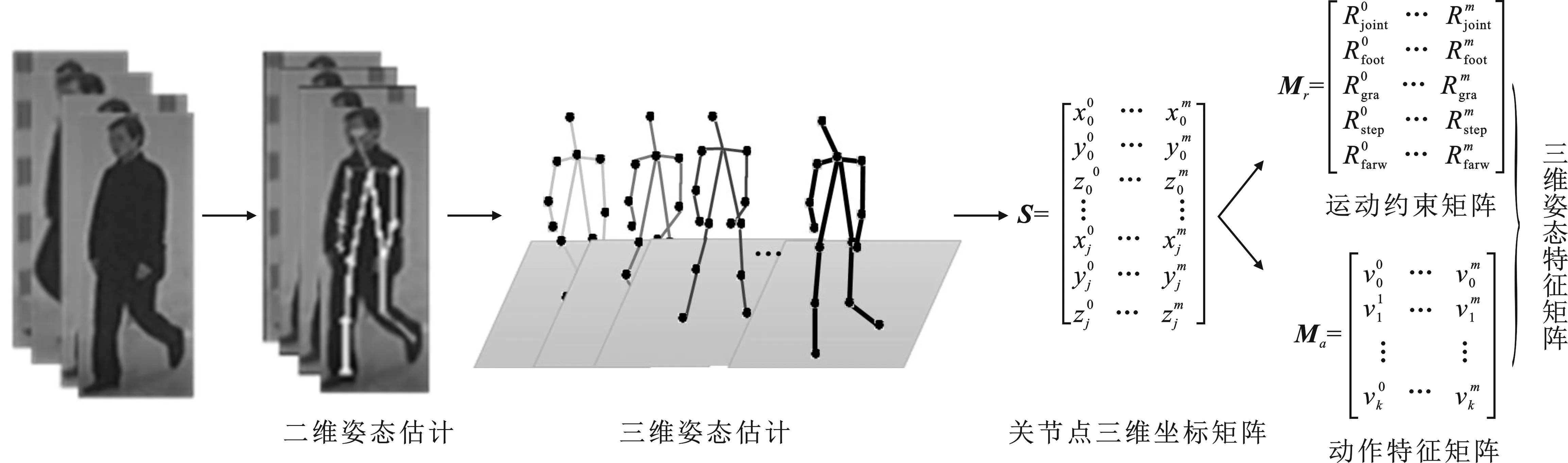
图1 人体三维姿态特征矩阵构建流程
图2是行人关节点及运动约束关系示意图。
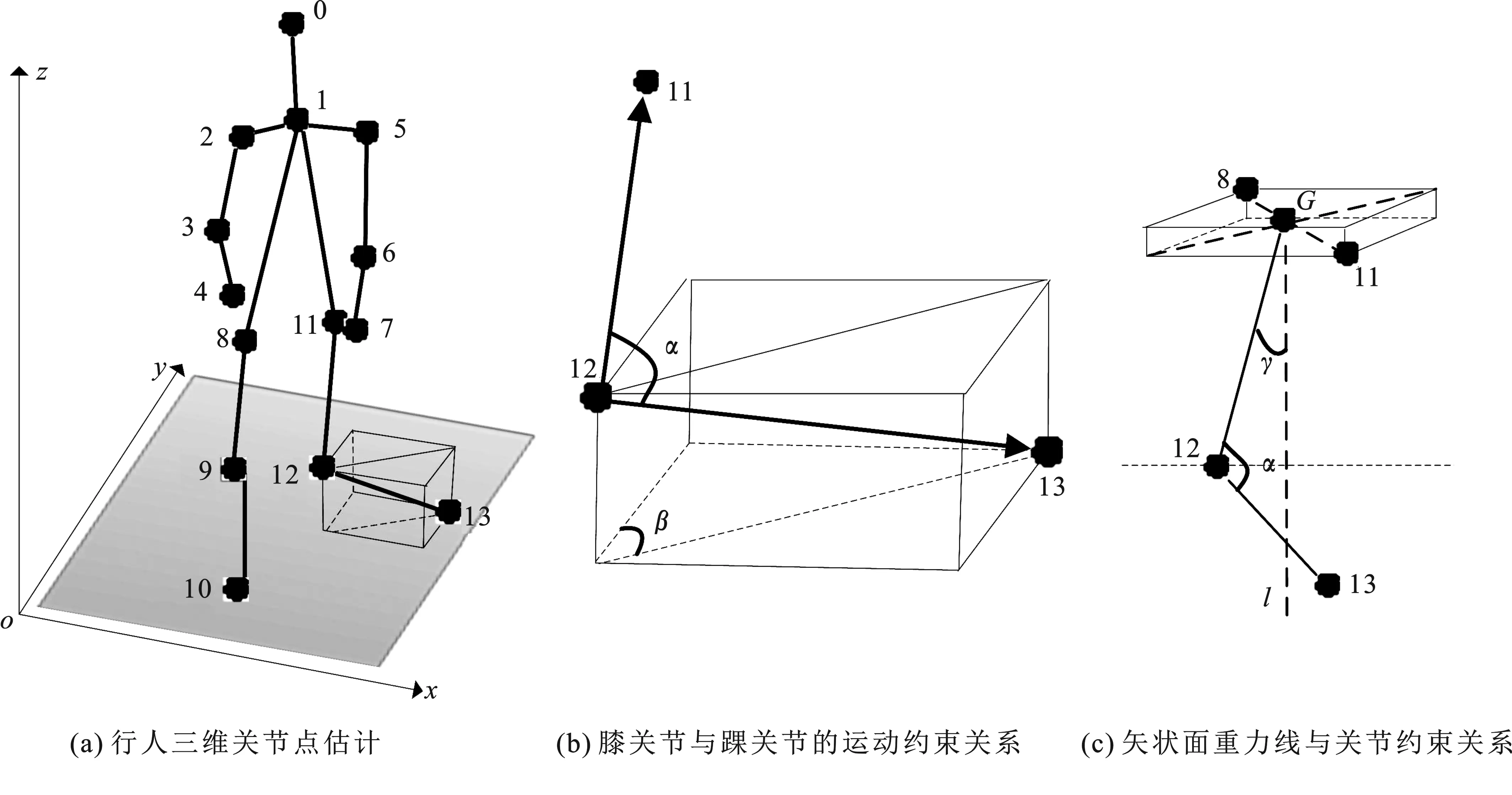
图2 行人关节点及其运动约束关系示意图

(1)
其中,kb为下肢关节点,ki、kj是与kb相邻的关节点。

(2)
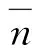
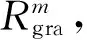
(3)
其中,NG为身体重心,kn、kl为下肢关节点。

(4)

(5)
其中,kb的含义与式(1)中的相同。
将关节运动约束矢量和人体结构约束特征矢量按式(6)方式组合,得到行人的运动约束矩阵Mr。该矩阵保持了关节运动约束的时序特征。
(6)
此外,每个人在时域和空域的运动特点也存在差异,如图3所示。
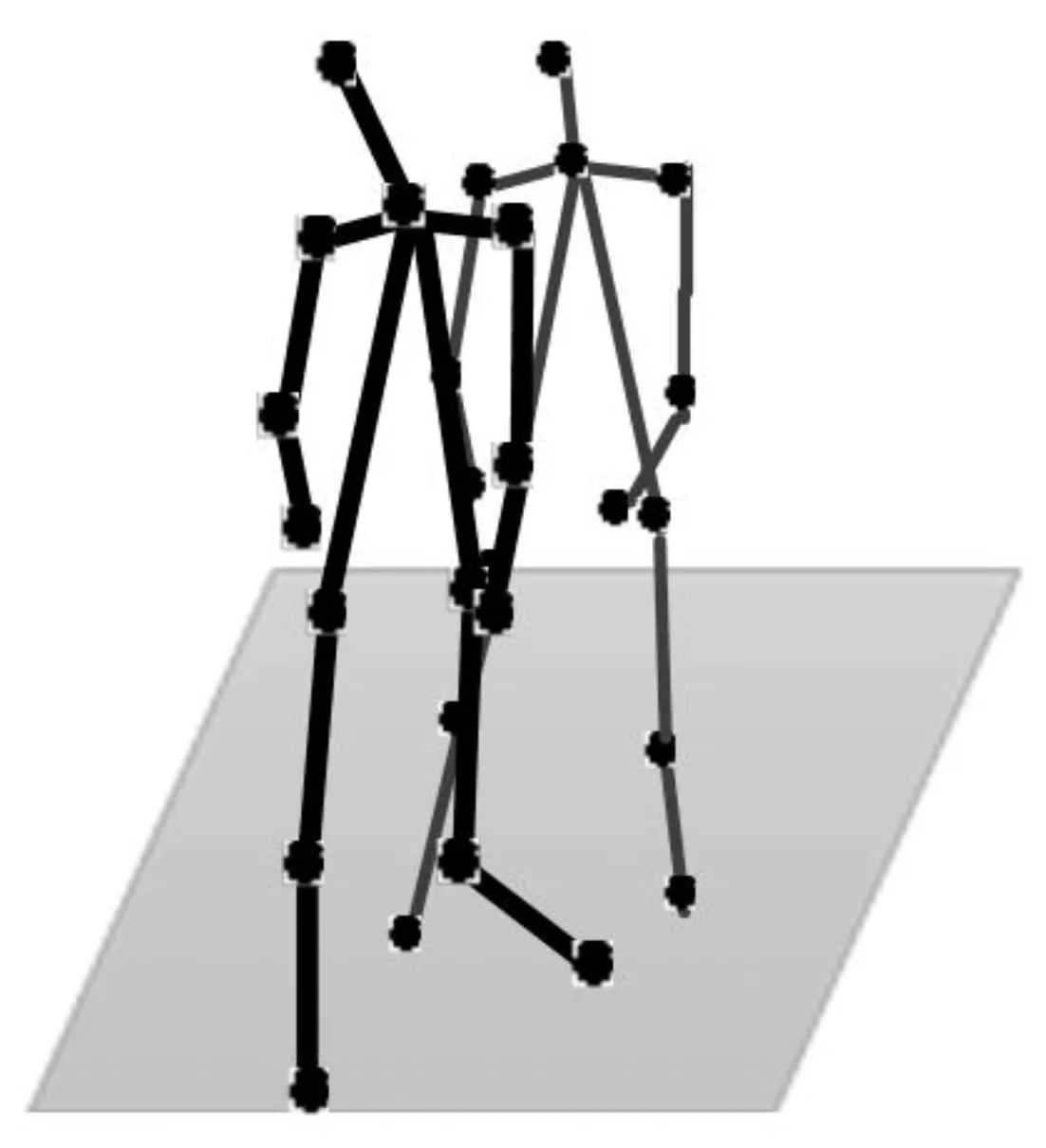
图3 相邻两帧间关节点运动示意图
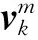
(7)
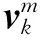
(8)
2 三维姿态特征提取网络构建
为了从三维姿态特征矩阵中挖掘行人的步态特征,同时缓解视角、衣着、携带物等因素对步态的影响,选择使用深度网络的非线性映射能力来提取三维姿态特征矩阵中的步态时空特征。长短时记忆网络(Long Short Term Memory networks,LSTM)是一种时间循环神经网络,它的记忆单元和门机制使其在学习长序列数据的时序依赖关系方面有着优良的性能,适合学习矩阵Mr中的关节约束时序特征;而卷积神经网络(Convolutional Neural Networks,CNN)则通过局部连接、权值共享以及池化机制,可以逐层提取数据的局部相关特征。由于行人的关节位移在局部区域具有自相关性,可借助卷积神经网络捕捉矩阵Ma中的空间动作关联特征。所以,构建了长短时记忆网络与卷积神经网络并行组合的三维步态识别网络,命名为“LC-POSEGAIT”,该网络模型的结构如图4所示。
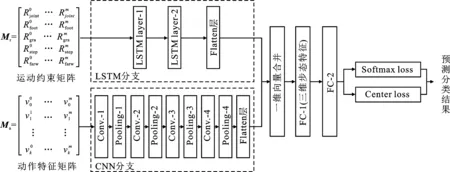
图4 LC-POSEGAIT网络模型结构
LC-POSEGAIT的长短时记忆网络分支由2个长短时记忆网络层和Flatten层组成,运动约束矩阵Mr经过两层长短时记忆网络后在Flatten层转换为一维运动约束向量;卷积神经网络分支由4个卷积层、4个池化层及1个Flatten层组成,动作特征矩阵Ma经过卷积神经网络分支的4次卷积和池化后,在Flatten层转换为一维动作特征矢量。将两路一维向量合并后,经过全连接层FC-1、FC-2降维得到步态特征矢量,使用FC-1层矢量作为行人三维步态特征进行步态识别。
考虑到行人步态相似度较高,加之拍摄视角及行走条件变化会影响步态特征的类内变化,借鉴文献[19]的思想,采用Softmax损失函数LS和Center损失函数LC联合的多损失函数优化网络。其中,LS用于拉大行人的类间距离,LC用于紧凑行人的类内距离,保证不同行人的特征可分离。因此,LC-POSEGAIT网络的损失函数定义如下:
(9)
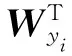
3 实验及分析
为了验证新方法的有效性,在Win10、Pytorch1.4、python3.6环境下使用中科院自动化所发布的CASIA-B多视角步态数据库进行网络训练和行人识别验证。该数据库共有124个行人,3种行走条件(即背包行走bg、穿外套行走cl和正常行走nm),每个人分别在11个视角(每两个视角间隔18°,即0°,18°,…,180°)采集了10种行走状态,即每人拥有13 640(124×10×11)个视频片段。视频分辨率为320×240,帧速为25帧每秒。
根据图1流程,提取124个行人所有视频中的关节点三维姿态数据,计算得到视频片段中每一帧的14个关节运动约束值,然后建立运动约束矩阵Μr和动作特征矩阵Μa。由于部分视角的视频卡顿,致使数据并未完全提取到,在使用时删除不满足训练及测试要求的矩阵。图5(a)是第001人在72°视角的10种行走状态下的某一帧图,图5(b)是001人在bg-01,bg-02,cl-01,cl-02状态下左膝关节运动约束值在一段时间内的变化关系。从图5(b)中可以看出,行人背包或穿外套行走会对步态产生一定的影响。

(a)第001人在72°视角10个行走状态图
将矩阵Mr和Ma送入网络的两个分支。在两个分支网络的最后一层,分别将关节约束二维矢量和动作特征二维矢量展开为一维矢量,然后将它们融合后送入全连接层。其中训练集使用001#-074#行人的全部10个行走状态数据;注册集(gallery set)使用075#-124#行人的nm01-04数据;验证集(probe set)使用075#-124#行人的nm05-06、bg01-02、cl01-02数据。LC-POSEGAIT网络参数设置如表1所示。

表1 LC-POSEGAIT网络参数
当LC-POSEGAIT网络训练完成后,将网络的FC-1层输出的128维向量作为三维步态特征向量。首先进行跨视角、跨行走状态的步态识别实验。表2是在正常行走状态下的识别率。从表2中可以看出,在注册集与验证集相同视角下,平均识别率在90%以上。当验证集样本与注册集样本的视角差在±36°以内时,平均识别率为86%。
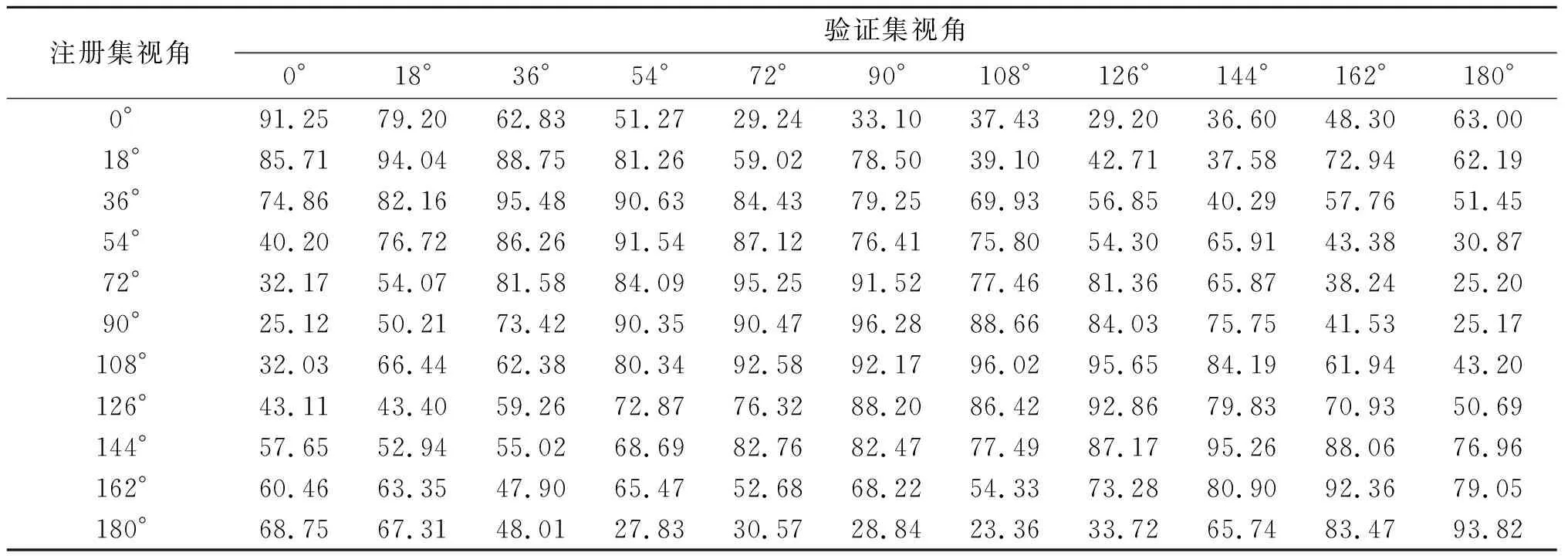
表2 CASIA-B 数据集上正常行走的跨视角识别率 %
其次,分别统计不同行走状态的平均识别率,结果如表3所示,得到nm-nm的平均识别率为66.62%,nm-bg的平均识别率约为45.92%,nm-cl的平均识别率约为33.49%。其中,0°和180°视角的平均识别率最低,这和姿态估计在这两个角度的精度有关。而且从表3中可以看出,穿外套、背包对跨视角步态识别的准确率都有一定的影响。

表3 CASIA-B数据集同状态跨视角平均识别率 %
新方法构建的三维姿态特征矩阵着眼于人体姿态的运动约束和动作特征,保持了人体运动系统的整体特点和时空特性。为了检验两类特征矩阵对步态识别的有效性,将LC-POSEGAIT与LSTM分支、卷积神经网络分支分别学习步态特征得到的识别效果进行比较,在不同行走状态下的平均识别率如表4所示。可以看出,卷积神经网络(CNN)分支的识别率相对较低,LSTM分支次之,LC-POSEGAIT的识别率最高,说明人体运动约束和关节的动作特征能够充分表达步态特征。同时,使用LSTM和CNN结合的模型能挖掘步态的多角度特征,提高三维步态的识别率。

表4 LC-POSEGAIT网络、LSTM分支及CNN分支的跨视角平均识别率 %
最后,将新方法和基于表观特征的SPAE[20]、GaitGANv2[21]方法以及基于模型的PoseGait[19]方法进行识别性能对比,结果如表5所示。可以看出,新方法在3种行走状态下的识别率均高于其他方法。与表观特征方法SPAE、GaitGANv2相比,新方法建立的特征矩阵比类能量图能更好地表达行人运动的时空特性。新方法和PoseGait方法都采用三维姿态估计进行步态建模,由于新方法综合考虑了人体运动的整体约束性、LSTM的时序特征学习以及卷积神经网络对关节动作局部特征的学习能力,识别率有所提高。从两种方法的跨状态实验结果和图5(b)可以看出,正常行走状态和其他两种行走状态的平均识别率有较大差异,其原因可能在于CASIA-B数据集的视频采集分辨率不高,影响到三维姿态估计的准确性;同时,三维姿态估计是两次估计得到的值,其精度波及到三维姿态特征矩阵的向量值,导致识别率低于其他两种行走状态。
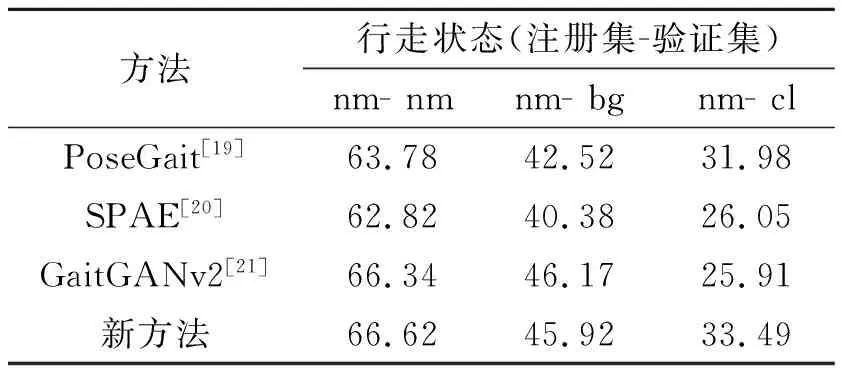
表5 PoseGait、SPAE、GaitGANv2和文中方法的跨视角平均识别率对比 %
4 结束语
为了缓解拍摄角度、行走状态对行人步态识别的影响,以及部分类能量图在表征步态特征时造成的时序信息丢失问题,提出了一种长短时记忆网络和卷积神经网络相结合的并行网络步态识别方法。相比基于步态能量图的表观步态建模,新方法构建的三维姿态特征矩阵很好地表征了行人步态的时空特征,并使用深度步态网络LC-POSEGAIT中的LSTM分支和卷积神经网络分支分别挖掘行人关节约束的时序特征和关节动作的空间特征。由于采用了人体姿态估计,在三维姿态特征矩阵构建过程中避免了行人检测跟踪预处理工作。所设计的深度步态网络充分挖掘了三维姿态特征矩阵的时空特征,使得识别准确率有所提高。对新方法在公开步态数据库CASIA-B上进行评估,并未在真实场景中检验,在有遮挡的情况下,还需要进一步优化三维姿态特征矩阵。
