一种多尺度三维卷积的视频超分辨率方法
2021-11-12詹克羽
詹克羽,孙 岳,李 颖
(西安电子科技大学 综合业务网理论及关键技术国家重点实验室,陕西 西安 710071)
超分辨率重建的目的是由低分辨率(Low-Resolution,LR)图像恢复出高分辨率(High-Resolution,HR)图像,主要涉及单幅图像超分辨率以及视频图像的超分辨率。随着显示技术的发展,超高分辨率的视频显示设备已经十分常见,能够带来更好的视觉体验,但原始的高分辨率视频资源却比较少。因此,如何由低分辨率的视频得到高分辨率的视频是一个十分重要且具有挑战性的问题。
图像超分辨率技术在20世纪60年代首次被提出[1]。随着技术的不断发展,超分辨率重建技术的研究已经取得了巨大的进展。目前,图像超分辨率重建方法大致可以分为3类:基于插值的方法[2]、基于重建的方法[3]和基于学习的方法[4]。基于插值的超分辨率方法实现起来最为简单、直接,利用的是图像的局部平滑这一假设。但这类方法在细节纹理、几何结构等方面的效果较差。特别是放大比例较大时,重建图像的边缘处可能会出现模糊、过于平滑等现象,难以恢复出图像中的高频信息,导致视觉效果较差。基于重建的超分辨率方法是结合图像中的先验知识对图像的退化过程进行建模,如低秩先验、非局部自相似先验等等。利用这些先验信息进行约束,对模型优化求解得到高分辨率图像。基于重建的超分辨率方法在一定程度上减少了模糊的情况,能够得到局部细节信息更加丰富的高分辨率图像,且对于复杂运动、未知噪声、未知模糊核等具有一定的鲁棒性。但对于较大的放大倍数,往往很难恢复出图像中的细节信息,且对于大规模的数据,基于重建的方法通常会消耗较多时间,算法复杂度较高。基于学习的超分辨率方法在一定量的数据集上通过模型学习低分辨率图像与高分辨率图像间的对应关系来完成重建。稀疏表示、随机森林、支持向量回归等机器学习方法都可被用来学习高-低分辨率图像的映射关系。
随着深度学习技术的快速发展,其在自然语言处理、图像处理等多种应用中都取得了很好的效果,基于深度学习的超分辨率方法也受到了广泛的关注和研究[5-9]。受稀疏表示和深度学习方法启发,文献[5]在图像超分辨率任务中,提出一个三层卷积的超分辨率网络SRCNN,在重建效果和效率上都要优于传统方法。文献[6]设计了包含20层卷积层的超分辨率模型,并在其中引入了残差连接,通过加深网络的深度,来提取更为丰富的特征,以此实现更加准确的超分辨率结果。文献[7]采用低分辨率图像作为输入,并使用亚像素卷积层对上采样方式进行了改进,将特征图的像素重新排列来得到放大后的图像,有效地减少了网络的参数量。
视频作为连续的图像序列,可以对其每一帧图像进行超分辨率重建来完成整个视频的超分辨率重建。但这种方式没有对视频帧间的信息加以利用,其效果并不理想。目前,大多数深度学习网络模型都是基于光流对视频图像间的运动进行补偿[10-13],重建高分辨率视频图像。文献[10]在SRCNN结构的基础上进行了改进,提出了视频超分辨率网络VSRnet,使用经过放大和运动补偿的连续视频帧作为输入,输出中间帧的高分辨率重建结果。文献[11]提出视频高效亚像素卷积网络VESPCN,利用可训练的空间变换网络来实现运动补偿,然后进行高分辨率视频帧的重建。该模型在一个网络中实现了运动补偿和高分辨率重建,是第一个端到端的视频超分辨率网络。文献[12]提出了基于高分辨率光流的视频超分辨率网络SOF-VSR,首先通过一个光流重建网络来推断高分辨率光流,然后利用其进行运动补偿,最后实现高分辨率重建。该网络中生成的高分辨率光流更为准确,能实现更好的运动补偿效果。尽管这些方法都能实现较好的重建效果,但均依赖于运动估计和运动补偿的准确性。文献[14]提出了基于三维卷积的视频超分辨率网络3DSRnet,使用三维卷积来学习视频图像的时间-空间特征。该方法实现了较好的重建效果,但其网络结构简单,不能充分地利用视频的时间-空间特征。
笔者提出了一种基于多尺度三维卷积的视频超分辨率网络模型。该模型使用多尺度的三维卷积来提取视频图像的多种特征,有助于实现更好的重建效果。利用三维卷积残差结构进行时间-空间特征的融合,可有效利用多尺度的时间-空间特征信息,重构出更丰富的视频图像细节。同时,为减少网络计算量,在残差结构中引入通道分离,有效减少网络参数量。实验结果表明,与其他视频超分辨率网络相比,笔者提出的网络模型具有更好的重建性能,在进行4倍超分辨率放大时,峰值信噪比(Peak Signal to Noise Ratio,PSNR)可平均提高1.40 dB,结构相似性(Structural SIMilarity,SSIM)可平均提高0.077,视觉效果更加清晰。
1 视频超分辨率网络模型
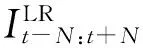
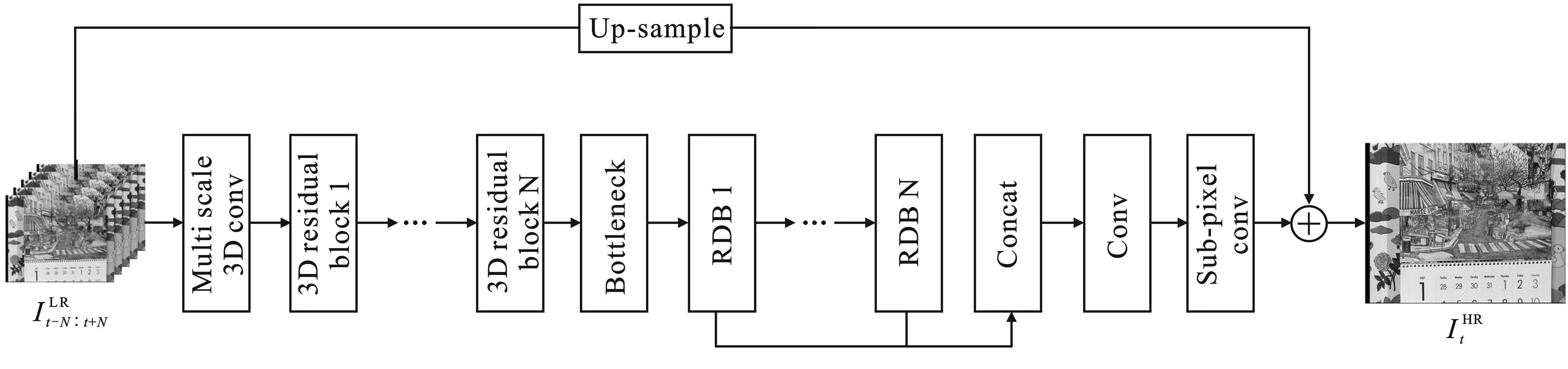
图1 视频超分辨率网络模型结构图
(1)
其中,N表示该网络模型,Θ表示网络的参数。
1.1 多尺度特征提取模块
多尺度特征提取模块(Multi scale 3D conv)的作用是对输入的视频进行初步的特征提取。该模块的具体结构如图2所示。固定大小的卷积核只能提取到一种尺度的特征,而不同大小的卷积核具有不同的感受野,可以提取视频图像中多种尺度的特征信息。因此,该模块使用多个卷积核大小不同的三维卷积来进行多尺度的特征提取,可以提取到更加丰富的特征信息。充分利用这些特征信息,有助于取得更好的重建效果。
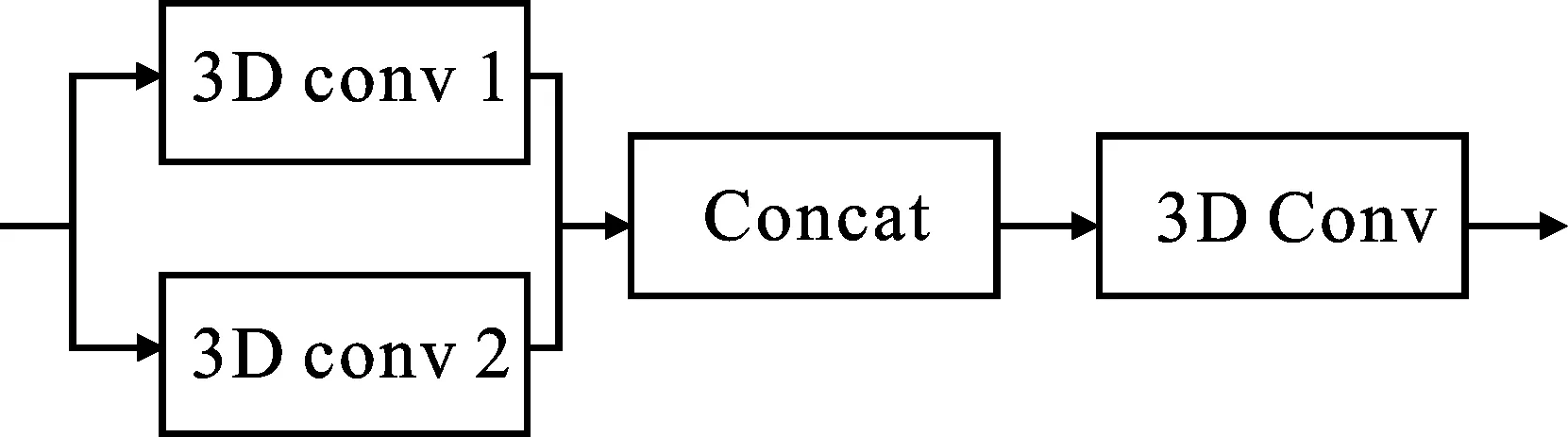
图2 多尺度特征提取模块结构图
在多尺度特征提取模块中,使用2个卷积核大小分别为3和5的三维卷积提取2种尺度的特征。为融合2种不同尺度的特征并减少网络的参数,将各卷积层的输出连接在一起,然后输入到一个卷积核大小为1的卷积层。该过程可以表示为
F=H1([H3(X),H5(X)]) ,
(2)
其中,H表示卷积操作,下标表示卷积核大小,X表示输入数据,F表示输出特征图,[·]表示连接操作。
1.2 特征融合模块
特征融合模块的作用是对上一特征提取模块提取到的特征进行进一步的时间-空间特征融合。该模块中,结合残差结构和三维卷积,使用三维卷积残差块(3D residual block)进行特征融合,其具体结构如图3所示。该三维残差块结构包含3层卷积,前2层使用大小为3的卷积核。
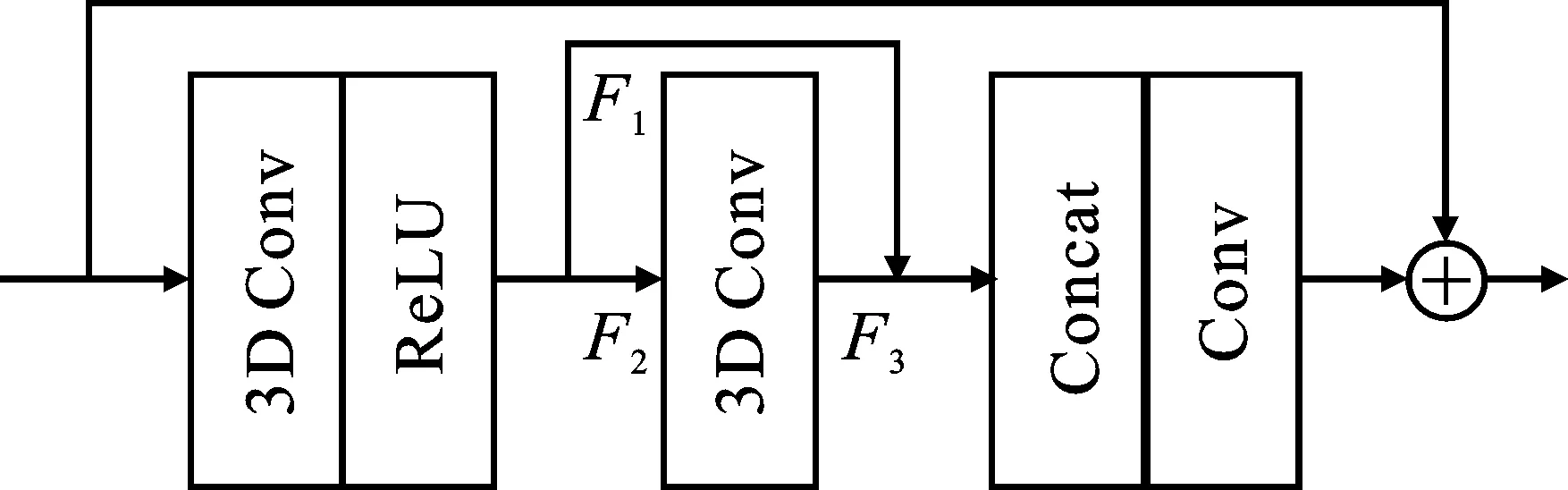
图3 三维卷积残差块结构图
为了减少网络参数量,将第1个卷积层的输出特征分成两部分F1和F2,第2个卷积层仅对F2进行处理,并将其输出特征F3与F1连接,再使用一个大小为1的卷积进行特征融合。该过程可以表示为
(3)
其中,Fin表示残差块的输入特征,s表示通道分离操作,F表示输出特征图。
该模块通过三维残差块同时进行了时间-空间特征的融合,从而有效地对视频帧之间的运动进行补偿,得到更加精确的重建结果。同时,上述连接后的特征图包括了2种不同级别的特征,不仅可以进一步有效利用多尺度的时间-空间信息,还可以有效减少网络参数量,降低网络复杂度。
特征融合模块使用5个三维残差结构进行时间-空间特征融合。为衔接特征融合与后续模块,将特征融合模块中最后一个卷积层的输出特征图进行堆叠(Bottleneck),将尺寸为C×D×W×H的特征图变成CD×W×H的特征图,同时使用大小为1的卷积对堆叠后的特征图进行融合。其中,C、D、W和H分别为通道数、深度、宽度和高度。
1.3 高分辨率重建模块
该模块将融合后的特征作为输入进行高分辨率图像重建,由残差密集连接块[15](Residual Dense Block,RDB)构成,即图1中的RDB,其具体结构如图4所示。该结构所有卷积层之间都有连接,即每一层的输入都包含其之前所有层的输出特征,可以复用大量的特征。通过增强信息流、学习残差特征,可以更充分地学习局部层次特征。
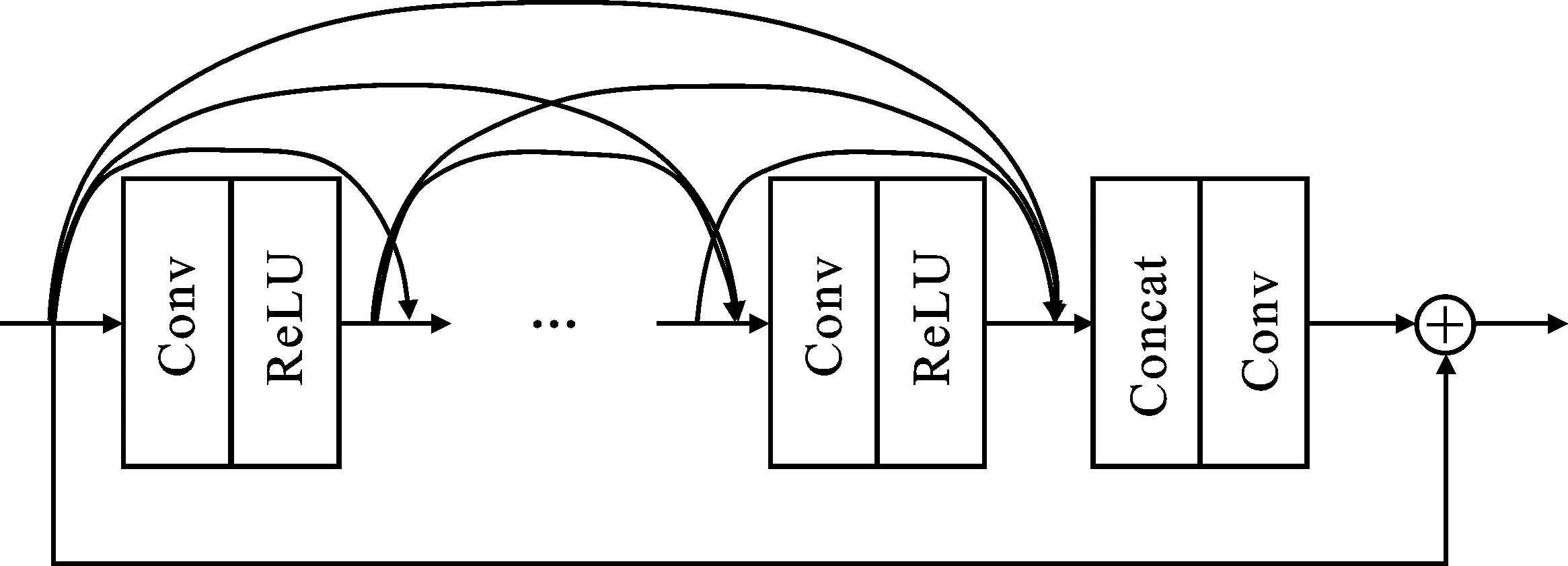
图4 残差密集连接块结构图
每个残差密集连接块使用5个卷积层,前4层使用大小为3的卷积核,最后一层使用大小为1的卷积核来进行特征融合。为了尽可能多地利用不同的特征信息,该模块共使用了5个残差密集连接块,将所有的输出连接在一起,进行特征融合。特征融合后的输出是一个和输入视频帧大小相同,但深度为放大倍数的平方的特征图。
为减少网络的计算量,整个网络都是在低分辨率图像尺寸上进行处理的。因此,在网络末端需使用亚像素卷积层进行放大以得到高分辨率图像帧重建结果。设放大的倍数为s,则亚像素卷积可以将大小为s2C×W×H的输入转换成大小为C×sW×sH的高分辨率图像输出。对于不同的放大倍数s,只需要修改前一个卷积层的输出通道数即可,不需要修改网络的其他部分。由于输入图像和输出图像具有一定的相似性,在模型中使用了全局残差连接,对输入视频的中间帧进行双线性插值放大,然后与亚像素卷积层的输出相加,作为网络的最终输出。
1.4 损失函数
网络模型选取均方误差函数(Mean Square Error,MSE)作为损失函数,其衡量的是重建图像与真实图像各像素之间的差异,可以表示为
(4)
其中,IGT为高分辨率图像的真实值,IHR为网络输出的高分辨率重建图像。
2 实验结果与分析
2.1 数据集及实验设置
使用Vimeo-90K数据集[16]作为训练集,其含有64 612个视频序列,每个视频序列包含7帧连续的视频帧,分辨率大小均为448×256。使用Vid4数据集[17]作为测试集,其包含4个不同的场景,每种场景使用31帧图像用于测试。将训练集中的原始数据作为高分辨率视频序列,使用Bicubic插值对原始图像进行下采样,获得对应的低分辨率视频序列。在产生的低分辨率视频序列中,随机选取大小为32×32的视频序列块作为网络训练时的输入,原始的视频序列也被相应的剪裁作为与之对应的真实数据。
采用文献[12]的处理方式,将视频图像转换到YCbCr颜色空间,将Y通道输入模型进行处理。对于Cb和Cr通道,使用Bicubic插值的方式对其进行上采样。最后将YCbCr颜色空间转换回RGB颜色空间,得到最终的重建图像。
笔者使用PyTorch框架实现了网络模型的搭建,选择Adam优化方法对网络进行训练,参数设置为β1=0.9,β2=0.999,批量大小设置为32。初始的学习率设置为10-4,每20个训练阶段下降一半,共训练60个阶段。
在对比实验中,使用峰值信噪比(PSNR)和结构相似性(SSIM)作为性能评价指标。
2.2 实验分析
首先进行了消融研究,对特征融合模块的作用进行了验证。分别使用普通的三维残差块和笔者提出的三维残差块对网络进行训练,表示为模型1和模型2,并在测试集上测试。表1中给出了2种模型在测试集上进行4倍超分辨率重建时的峰值信噪比(dB)、结构相似性以及网络的参数量。可以看出,与普通的三维残差块相比,笔者所提网络模型中引入通道分离的三维残差块不仅重建效果略有提高,还有效地减少了网络的参数数量。

表1 2种模型4倍超分辨率重建的性能评价指标
为验证模型有效性,将所提模型与Bicubic[2]、VSRnet[10]、VESPCN[11]、SOF-VSR[12]和3DSRnet[14]5种方法进行对比。不同方法在Vid4测试集上的评价指标数值如表2所示。可以看出,笔者提出的模型与其他方法相比,在评价指标数值上均有一定提升,证明了该方法的有效性。进行3倍超分辨率放大时,与效果较好的3DSRnet和SOF-VSR方法相比,笔者所提方法在平均峰值信噪比上分别提高了0.93 dB和0.49 dB,在平均结构相似性上分别提高了0.026 3和0.014 7;进行4倍超分辨率放大时,平均峰值信噪比分别提高了0.83 dB和0.49 dB,平均结构相似性分别提高了0.036 6和0.022 1。表2同时给出了各方法的参数量,笔者所提方法的参数量仅略高于SOF-VSR方法,但可获得更好的重建性能。

表2 Vid4测试集上不同视频超分辨率模型性能评价指标(峰值信噪比/结构相似性)
图5展示了不同方法在Vid4测试集上进行4倍超分辨率放大后某一帧的重建结果。

图5 不同方法在Vid4测试集上4倍超分辨率重建的结果图
以Calendar视频为例,直接由Bicubic插值得到的重建图像十分模糊,几乎无法辨认图中的字母。VSRnet和VESPCN方法的重建结果能勉强看到字母的边缘,但仍然比较模糊。SOF-VSR和3DSRnet的超分辨率重建结果表现较好,可以看到图中具体的英文字母。这是因为SOF-VSR方法对HR光流进行了估计,可以实现更精确的运动补偿,从而恢复出更多的细节信息。3DSRnet虽然网络结构相对简单,但其利用三维卷积同时进行了时间-空间的特征提取和融合,也取得了较好的结果。相比之下,笔者所提模型的重建结果更加清晰,细节也更加丰富,视觉效果更好。从其他数据的结果图中也可以看到相似的结果,因此,笔者提出的方法能够获得更好的视觉效果。
图6针对Calendar视频数据,展示了不同方法重建结果的时间连续性。采用文献[11]中的方法,从视频的每一帧中的一个固定位置取一行像素点,并将所有获得的像素行依次纵向拼接在一起,得到一幅固定位置随时间变化的图像。图像中的内容越清晰,代表视频的连续性越好,视觉效果也就更好。从图中可以看出,笔者提出的模型的结果更清晰,再次验证了该模型的有效性。

图6 不同方法在Calendar数据上4倍超分辨率重建的时间轮廓图
3 结束语
笔者提出一种基于三维卷积的视频超分辨率重建方法。该方法利用多尺度三维卷积进行时间-空间特征的提取,并在三维残差块中结合通道分离来进行多特征融合。实验结果表明,与其他视频超分辨率方法相比,笔者所提方法可充分利用视频序列的时间-空间信息,获得更好的重建性能,细节信息更加丰富,时间连续性较好,具有更好的视觉效果。
