结合物品属性权重的混合推荐算法
2021-11-12马梦馨王国中
马梦馨, 王国中
(上海工程技术大学 电子电气工程学院, 上海 201620)
0 引 言
随着信息技术和互联网技术的发展,互联网提供的平台和数据越来越多,而不同的人兴趣爱好截然不同,越来越难以从大量的信息中找到自身感兴趣的信息,信息也越来越难展示给可能对其感兴趣的用户,推荐系统应运而生。推荐系统本质上是在用户需求不明确的情况下,从海量信息中为用户寻找有用信息的技术手段。经过二十多年的发展,推荐系统被广泛应用于电子商务平台、新闻媒体领域以及广告的个性化推荐等。
目前市面上比较常用的推荐算法有协同过滤推荐算法(Collaborative Filtering Recommendation,CF),其中包括基于用户的协同过滤(User Based CF)和基于物品的协同过滤(Item Based CF),基于内容的推荐算法(Content-Based Recommendation,CB)和混合推荐算法(Hybrid Recommendation,HR)等。
协同过滤推荐算法在一般情况下表现良好,但是在有新用户或新物品加入时,由于没有历史数据,所以无法进行推荐,存在冷启动和数据稀疏性问题。Liu等人提出在传统矩阵分解模型的基础上,通过整合多关系社交网络的用户偏好,获得信任和信任功能矩阵,有效缓解了数据稀疏性问题[1];Yan等人提出了将Jaccard相似性计算方法用于基于多层感知机的电影推荐模型,解决数据稀疏性问题[2];苑等人根据社交活动提出一种新的用户相似度计算方法来提高推荐精度[3];过等人改进了奇异值分解(SVD)算法和二分K-均值聚类算法,解决协同过滤算法稀疏性较大和扩展性较差的问题[4]。
基于内容的推荐算法不存在冷启动问题,但是存在提取特征困难、无法挖掘用户的潜在兴趣等缺点。王等人将项目粒度化,用户信息生成用户粒度序列来提取特征,提高推荐精度[5]。
混合推荐算法能根据不同的方式将多种算法相结合,扬长避短,提高推荐精度,解决冷启动和数据稀疏等问题。刘等人将不同用户对于不同物品的个性化行为特征指数引入到相似度的计算中,动态计算权重,提高混合推荐算法的推荐效果[6];Fan等人采用分类和聚类算法来挖掘项目和用户的历史数据,改进混合推荐算法,解决电子商务推荐系统的问题[7];李等人考虑了用户评分尺度及用户活跃度对物品相似性的影响,动态生成权重因子,提高推荐精度[8];随着深度学习的发展,田等人提出了一种基于隐狄利克雷分布(LDA)与卷积神经网络(CNN)的概率矩阵分解推荐模型(LCPMF),获取深层项目特征,提高推荐精度[9]。
本文在传统的混合推荐模型的基础上,引入物品属性的权重,改进了相似性计算方法,将协同过滤推荐算法与基于内容的推荐算法动态结合,解决冷启动和数据稀疏性问题,提高推荐精度。
1 相关算法理论
1.1 评分矩阵
定义推荐系统中U={u1,u2,…,um}为所有m个用户的集合,I={i1,i2,…,in}为所有n个物品的集合,两个集合组成了一个M×N的矩阵,此矩阵为用户-物品评分矩阵。见表1,矩阵中rui为用户u对物品i的评分,若rui为0,则说明用户对该物品没有评分,评分值越高说明用户对该物品越感兴趣。

表1 用户-物品评分矩阵
1.2 相似性计算
推荐算法中,常用的计算方法有欧氏距离、余弦相似度和修正的余弦相似度等,使用场景各不相同。
欧氏距离是衡量同一空间下两个点,度量的是两个点的绝对差异,适用于分析用户的能力模型,定义如式(1):
(1)
余弦相似度度量的是两个向量之间的夹角,其在度量文本相似度、用户相似度、物品相似度时较为常用。定义如式(2):
(2)
修正的余弦相似度是将数据中心化后再求余弦相似度,定义如式(3):
(3)
2 结合物品属性权重的混合推荐算法
2.1 物品流行度对相似性的影响
一般来说,热门物品会被用户喜欢的可能性大,但并不能说明用户的兴趣相同,热门物品对计算用户的相似性贡献不大,两个用户对冷门物品采取过同样的行为更能说明其兴趣度相同,二者更为相似,因此引入惩罚因子θi惩罚用户u1、u2共同兴趣列表中热门物品对其相似度的影响,θi的公式定义如式(4):
(4)
其中,N(i)表示对物品i有过评分的用户集合。
引入惩罚因子后的相似度为计算公式(5):
(5)

2.2 物品属性相似性
基于内容的推荐算法是通过抽取物品本身的特征信息,形成关键词向量,然后与用户喜好特征向量进行相似度计算,将物品推荐给用户,通常用于文本推荐。
把一个物品看作一个文档,定义所有的文档集合为D={d1,d2,…,dt},文档中的关键词集合定义为T={t1,t2,…,ts},最终需要用一个向量表示一个文档,定义di=(ω1,i,ω2,i,…,ωs,i)为物品i的关键词向量,其中ωni表示第n个词在文档i中的权重,数值越大表示越重要。定义好之后通常用词频-逆文档频率(TF-IDF)来表示文档,其定义如式(6):
(6)
其中,TF(tk,di)表示第k个词在文档i中出现的次数,nk是所有文档中包含第k个词的文档数量,最终第k个词在文档i中的权重如式(7)所示:
(7)
得到文档的特征向量权重之后,使用余弦相似度,得到文档之间的相似度,相似度定义如式(8):
(8)
其中,Ti,j表示两文档之间共有的关键词。
2.3 混合模型相似性度量方法
通常协同过滤推荐算法效果优于基于内容的推荐算法,但是当新的用户或者物品加入时,系统就无法很好的进行推荐,且当用户物品矩阵极度稀疏时,计算出来的物品相似度可信度也不高,而基于内容的推荐算法能在一定程度上缓解物品冷启动问题,并且基于内容的推荐算法只考虑物品的属性,与用户的评价行为无关,能缓解数据稀疏性问题,所以将协同过滤算法中的相似性计算与物品属性相结合能缓解冷启动和数据稀疏性问题。
本文引入λ将两种相似性进行线性组合,由上文分析可知,当用户-物品矩阵极度稀疏时,使用基于内容的推荐算法要优于协同过滤推荐算法,所以定义λ的公式如式(9):
(9)
其中,Ui、Uj表示对物品i和物品j评分的用户数;Ui∩Uj表示对物品i和物品j共同评分的用户数;Ui∪Uj表示物品i和物品j一共被多少用户评分。引入λ之后,将相似度计算公式进行线性组合,如式(10)所示:
simitem(i,j)=λsimitemcf(i,j)+(1-λ)simitemcb(i,j)
(10)
由公式(10)可知,当存在冷启动问题或者用户-物品矩阵稀疏时,根据物品属性特征进行相似度计算的比重大;当数据稠密时,基于物品的协同过滤要优于基于内容的推荐,所以相似度计算时所占比重较大。这种线性结合的方式改善了推荐系统中的冷启动和数据稀疏性问题。
将混合的相似性计算方法引入到预测公式,得到用户u对物品i的评分预测公式(11):
(11)
其中,Mi为物品i的最近邻。
2.4 用户相似性
以上方法有效缓解了物品冷启动和数据稀疏性问题,但当新用户加入时,因为没有其历史行为记录,依然存在用户冷启动问题,只能根据用户自身的特征,为用户进行推荐。
影响用户喜好的特征主要有性别、年龄、职业、所在区域等信息,本文据此组成用户的内容向量,则用户u的特征集合为Cu={sex,age,occ,zip},因为欧氏距离度量的是空间中两个点的绝对差异,所以本文使用欧氏距离,即公式(1)来计算用户之间的相似性。
冷启动用户的预测公式(12)为:
(12)
其中,Nu表示用户u的最近邻。
2.5 推荐过程
为了解决数据稀疏性和冷启动问题,本文结合物品属性,将基于物品的协同过滤和基于内容推荐的相似性度量方法进行动态结合,形成一种新的相似性度量方法,解决物品冷启动和数据稀疏性问题,并且通过计算用户属性来解决用户冷启动问题。具体推荐过程如下:
Step1判断目标用户是否是冷启动用户,是则跳到Step2,不是则跳到Step3;
Step2冷启动用户的相似性计算,之后预测评分;
Step3非冷启动用户的相似性计算,评分预测;
Step4完成Top-N推荐。
3 实验数据及结果分析
3.1 数据集
为了验证本文算法的有效性,使用MovieLens 1M数据集,该数据集包含6 040个用户对3 900部电影的1 000 209条评分记录,数据稀疏度达95.75%。将数据集按照8:2划分为训练集和测试集,数据集中用户的属性包括了用户的ID、性别、年龄、职业ID和邮编等字段,电影的属性有电影ID、电影名、电影年份和电影风格等。
3.2 评价指标
推荐系统中常用的评价标准有平均绝对误差(MAE)、均方根误差(RMSE)、准确率(Precision)和F值等,本实验采用MAE作为度量标准,其定义为式(13):
(13)
其中,pi,j表示用户u对物品i的预测评分;ru,i表示用户u对物品i的实际评分;n为数据集中记录评分的个数。
MAE计算的是真实值与预测值之间的差异,数值越小说明准确性越高。
3.3 实验结果
通过实验测得本文算法在不同N的取值下的绝对误差,见表2。由表2可知,N取值在[10,60]范围内,精确性逐渐升高。

表2 算法在不同N的取值下的平均绝对误差
3.3.1 算法推荐精准度比较
为了验证本文算法的优化效果,本文选取改进的基于物品的协同过滤、基于内容的推荐算法与本算法进行对比实验,分别设置不同最近邻值测试MAE值的大小,实验结果如图1所示。可以看出本文提出的推荐算法无论N取何值,效果都远大于基于物品的协同过滤和基于内容的推荐。

图1 推荐准确度对比
3.3.2 算法缓解数据稀疏性能力的比较
为了测试本文算法解决数据稀疏性问题的能力,本实验的最近邻数确定为60,并且在数据集中随机删除部分数据,改变评分矩阵的稀疏性再次进行对比实验,测试算法效果,实验结果如图2所示。

图2 数据稀疏性对比
由图2可知基于内容的推荐算法在数据极度稀疏情况下算法效果要优于协同过滤推荐算法,而本文提出的算法在数据稀疏的情况下,效果要明显优于其它两种算法,有效缓解了数据稀疏性的问题。
3.3.3 算法缓解冷启动能力的比较
本实验用来验证算法解决冷启动问题的能力,在测试集中抽取100个物品作为新物品,100个用户作为新用户,将训练集中对应的100个物品和用户的评分记录置为0,使用新的训练集和测试集进行实验。本实验将基于内容的推荐算法作为对比,结果如图3所示。
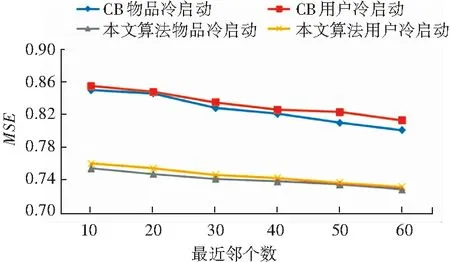
图3 冷启动问题对比
由图3可知,不管是用户冷启动还是物品冷启动,本文算法的精确性都远高于基于物品的协同过滤算法,实验表明,本算法能有效缓解冷启动问题。
4 结束语
本文对传统的混合推荐算法进行了优化,结合物品属性特征权重改进了相似度度量方法,并根据用户-物品矩阵稀疏性的差异,自适应的调整不同算法的相似性计算方法所占的比重,极大地提高了推荐精度。实验结果表明该方法显著提高了推荐准确度的同时,也有效缓解了数据稀疏性和冷启动问题。不足之处在于本混合推荐算法计算量大,复杂度高。
