基于VGG的人脸表情识别与分类
2021-11-12周义飏
周义飏
(北京师范大学 人工智能学院,北京 100088)
0 引 言
表情识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术,在治安、刑侦、医疗、教育、零售等领域发挥着越来越重要的作用。自二十世纪七十年代以来,人们在以面部动作编码系统为基础的表情识别道路上,向高精度、高速率、大数据的方向不断前进。
1 研究背景
人脸表情识别从早期用于治安的道路监控、机场安检所用的基于人脸识别的身份确定,到用于审讯、心理治疗的表情识别与分析,已经成为了社会发展的一个重要课题。
从上世纪六十年代开始,人们已经在探索更精确、更系统的表情识别方法,其中最具代表性的为Paul Ekman提出的面部编码系统(Facial Action Coding System, FACS)[1]。FACS的出现,使所有可能的面部表情都能被描述出来,并进行组合。
2 面部动作编码系统概述
二十世纪七十年代,Paul Ekman与合作者通过对表情的观察和生物反馈实验,描述出了不同的脸部肌肉动作与不同表情的对应关系。FACS将人脸分成了若干个动作单元(Action Units, AU),这些动作单元依据解剖学特点划分,相互独立但彼此间又具有联系。面部动作编码主要分为3大类:主要动作单元编码(见表1)、头部动作单元编码、眼睛动作单元编码。本论文主要研究的是动作单元编码。
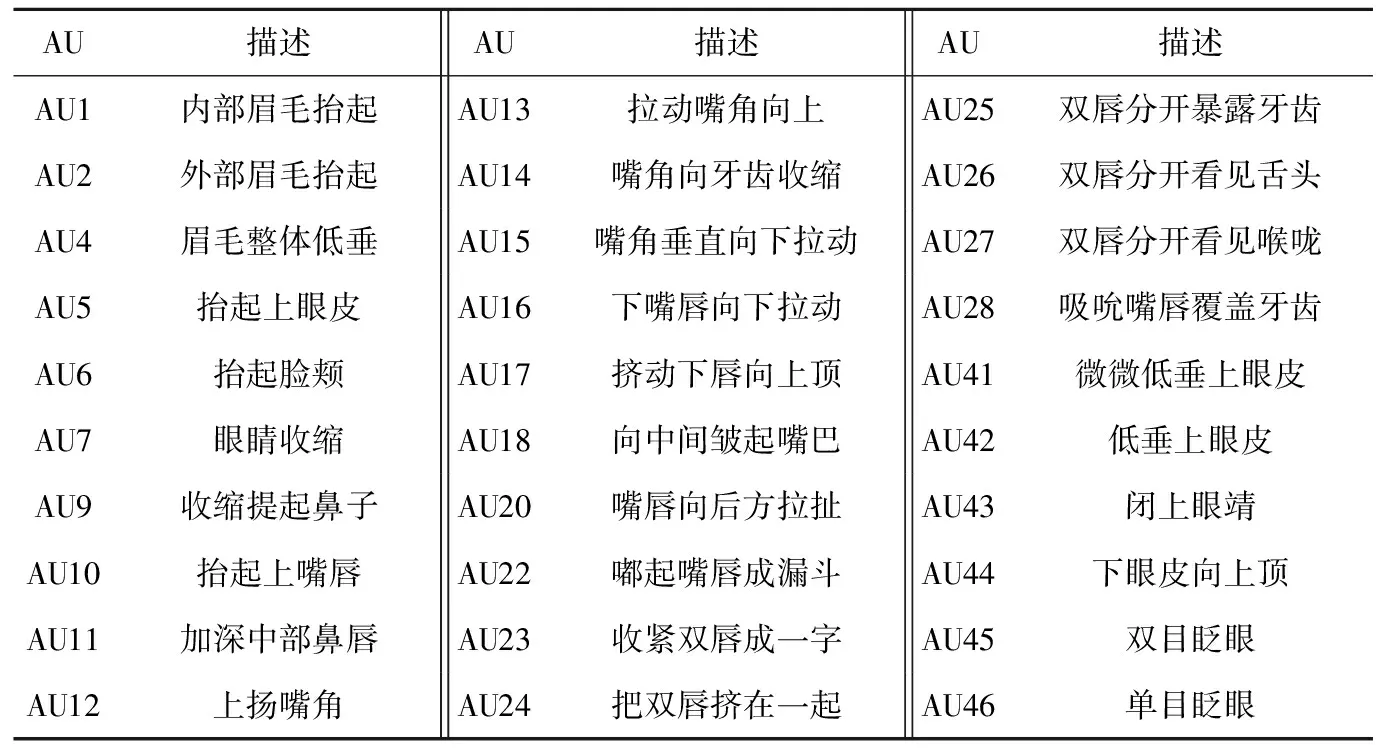
表1 主要动作单元编码
任何表情都能反映成若干AU的组合[2](见表2)。例如表示“快乐”情绪的表情通常表现为脸颊上抬和嘴角上扬,即AU6与AU12的组合。

表2 7种基本情绪与AU对应关系
3 国内外研究现状
3.1 人脸检测
目前,广泛使用的几种深度人脸检测算法及其效率和性能的最低要求见表3。
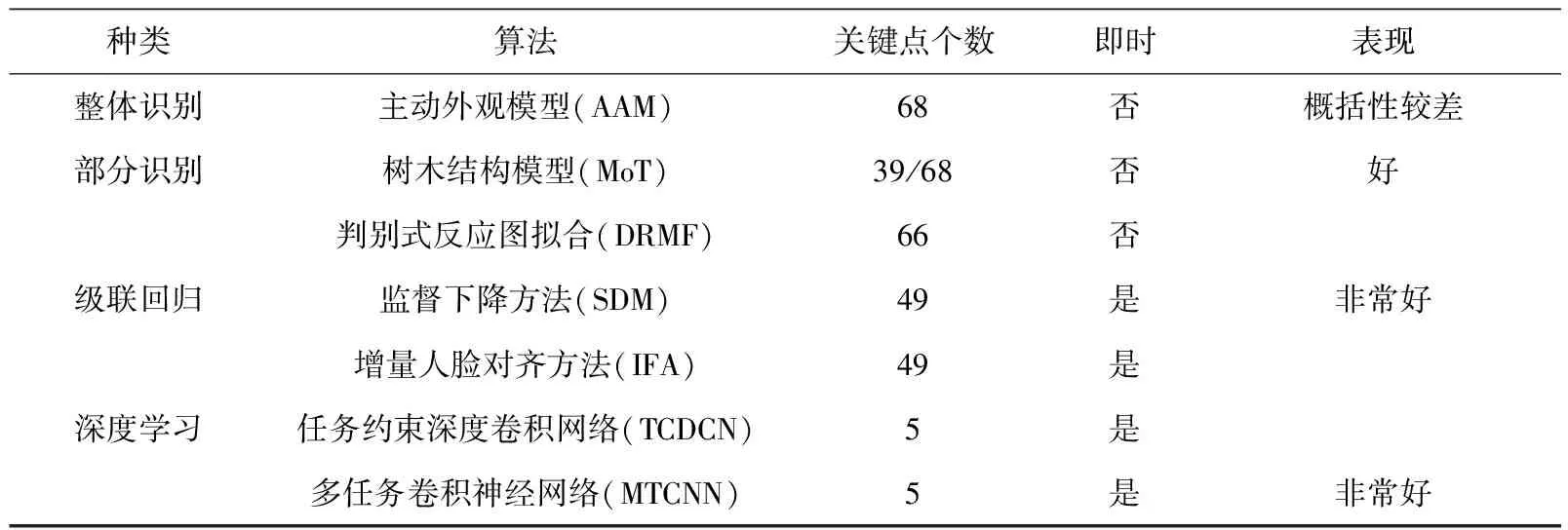
表3 几种深度人脸检测算法及其效率和性能的最低要求
主动外观模型(Active Appearance Model, AAM)可从整体人脸外观和整体形状中优化所需的参数[3]。
在判别模型中[4],树木结构模型(Mixtures of Trees, MoT)和判别式反应图拟合(Discriminative Response Map Fitting, DRMF),通过每个人脸坐标周围的局部外观信息来表示人脸[5]。
3.2 人脸归一化
人脸归一化主要有两种常用的方法:照度归一化和姿态归一化。
照度归一化即通过操作,使一组人脸图像的照度和对比度相同。常用的照度归一化算法包括基于各向同性扩散(Isotropic Diffusion, IS)的归一化、基于离散余弦变换(Discrete Cosine Transform,DCT)的归一化和高斯差(Difference of GAUsian , DoG)。
姿态归一化即人脸正面化。文献[6]提出了一种方法,即在对面部关键点定位后,生成通用的3D纹理参考模型,这些3D纹理参考模型适用于所有人脸图片,能有效估计可见的人脸成分。通过将每个人脸图像,反投影到参考坐标系合成初始的正面人脸。值得一提的是,生成式对抗网络(Generative Adversarial Networks, GAN)在人脸图像处理中的运用次数正飞速增长。GAN常用于生成大量的人脸图片作为训练集与数据集,一定程度上避免了以往因寻找足够的人脸图片而遇到的各种困难。
3.3 面部AU特征提取
3.3.1 基于外观特征的人脸AU特征提取
基于外观特征的人脸AU特征提取,通常会用到Gabor小波,其通过将面部图像与一组特定的具有不同方向和比例的Gabor滤波器进行卷积,来进行Gabor表示,从而提供面部图像的多尺度特征,反映像素之间的局部相邻关系。
文献[7]中通过在面部局部区域分别应用Haar小波分析,设计了自动AU检测系统,并使用AdaBoost来选择特征子集。与Gabor方法相比,Haar和AdaBoost方法有着与Gabor方法相似的精度,但速度却提高了若干个数量级。
3.3.2 基于几何特征的人脸AU特征提取
基于几何的特征,描述了面部几何信息并基于几何形状将面部动作分类。几何信息可以是一组关键点连接起来的面部网格。一些研究中,利用面部分量的变形,表情和中性面部图像之间的基准点的位置或差异[8-9]来进行识别。但并非所有的AU都可以仅仅通过几何表示来识别,例如AU6的特征包括眼睛外角周围的皮肤起皱和脸颊隆起,这很难通过变形来识别。同时,几何特征也无法检测出细微的面部特征,例如皱纹或纹理变化[10]。
3.3.3 基于混合特征的人脸AU特征提取
一些研究整合了基于外观特征与基于几何特征两种方法[11-12],并且结合了整体表示与局部表示、小波分析表示与直方图表示、低级表示与高级表示。文献[13]通过引入拓扑结构和关系约束提出多条件潜在变量模型。该模型将特征和模型级别的AU,依赖项编码用于AU识别的学习中,对于9个AU进行操作,其最佳识别精度达到92.7%。
4 数据预处理
4.1 人脸对齐
本方法对1 268张人脸图片进行识别与检测,在下巴、双眉、双眼、双唇、鼻梁、鼻尖9个部位返回68个关键点(不同部位的某些关键点可能重合)。图1为未处理的人脸图片,经过处理后可得到各关键点的坐标如图2。

图1 8张未经处理的人脸图片

图2 含关键点的人脸图片
这些关键点与人脸各个部位的位置相对应,将在接下来的仿射变换中起到定位作用。本步骤运用仿射变换实现人脸对齐,对齐后的人脸图片如图3所示。

图3 对齐后的人脸图片
本文进行仿射变换的具体思路为:分别计算左、右眼中心坐标、计算左右眼中心坐标连线与水平方向的夹角、计算左右两眼整体中心坐标、以左右两眼整体中心坐标为基点,将图片逆时针旋转相应角度,使左右眼中心坐标连线与水平方向平行,确保人脸图片为视觉上的正向。
4.2 剪裁
实际上,对于执行过上一步骤的图片,CNN可以较为精确地选取出图片中的人脸部分。但为了减少CNN的执行时间,需尽可能减少图片中的无效部分。根据landmark裁剪人脸到固定尺寸,水平方向以最靠左和最靠右的landmark中点为裁剪后图片的中心点,垂直方向上分为3部分:中部(双眼中心到双唇中心的像素距离)、底部和顶部(双眼中心到双唇中心的距离)。裁剪后的图片为边长为138像素的正方形,如图4所示。

图4 剪裁后的人脸图片
4.3 数据增强
本文使用基于68张人脸图片关键点的“图像扩充”,即对每个关键点取子区域,使每个子区域能包含至少2/3的人脸区域,从而将数据量扩大至69倍,原本的1 268张人脸图片扩充为87 492张图片,但依然只反映1 268张人脸,如图5所示。子区域均为边长为92像素的正方形。
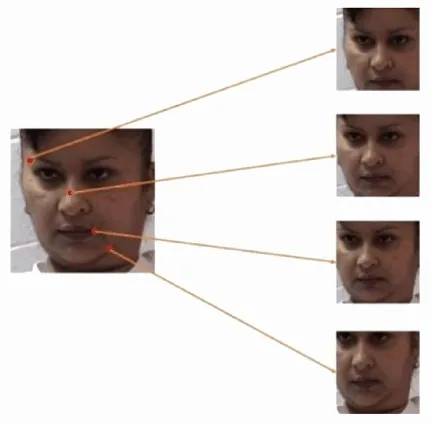
图5 数据增强示例
为了方便表示,建立2个平面直角坐标系记为:坐标系A与坐标系B。分别以经上一步骤剪裁后的图片左上角顶点和每个关键点子区域左上角顶点为原点(如图6)。以图5为例,各个关键点及其对应的坐标见表4。
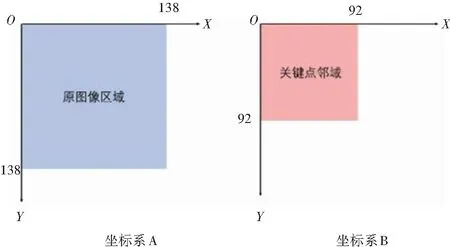
图6 两个坐标系
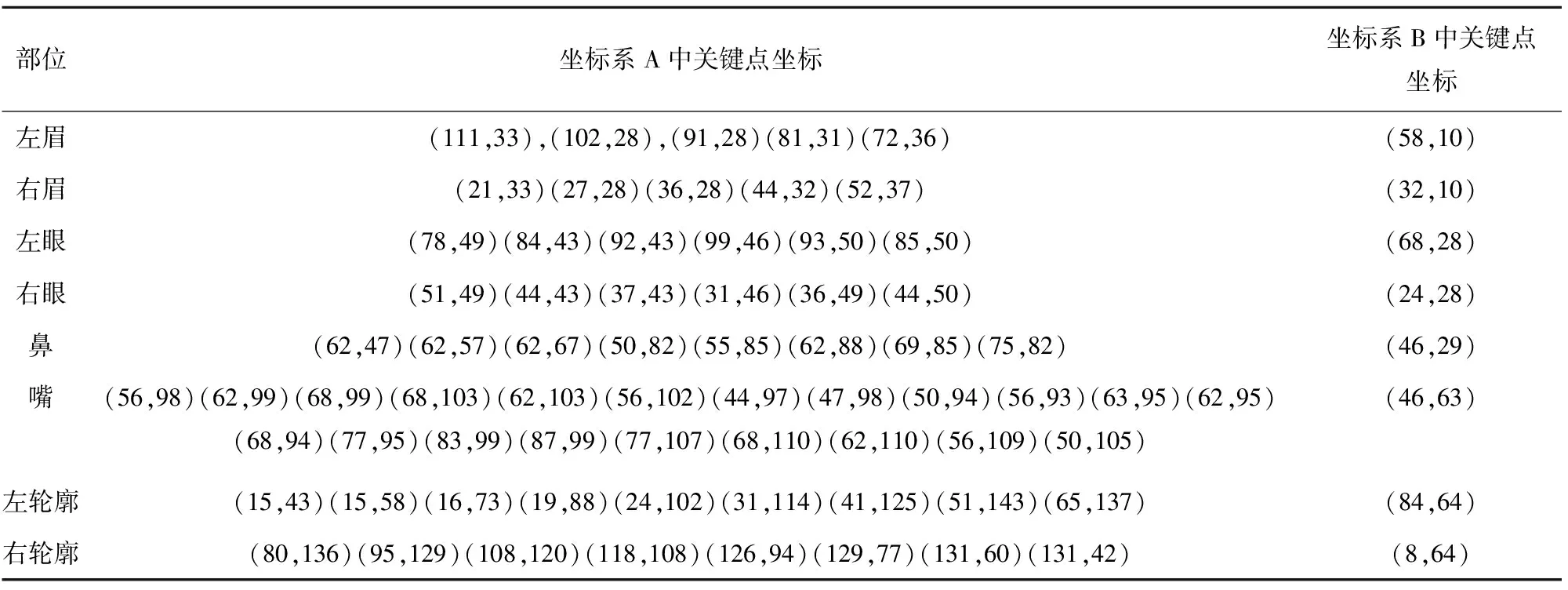
表4 各个关键点及其对应的坐标
5 基于深度卷积网络的人脸表情识别与分类
5.1 卷积神经网络
CNN是一类可进行卷积计算并且具有深度结构的前馈神经网络(Feedforward Neural Networks, FNN),是深度学习的代表算法之一。CNN主要由输入层、池化层、激活函数、卷积层、全连接层5个部分组成。
深度卷积网络将小的神经网络串联起来,从而构成深度神经网络。以三维图进行卷积处理为例,如图7所示,同一卷积核对不同输入层进行卷积操作,得到一组输出,多个卷积核则得到多个输出。
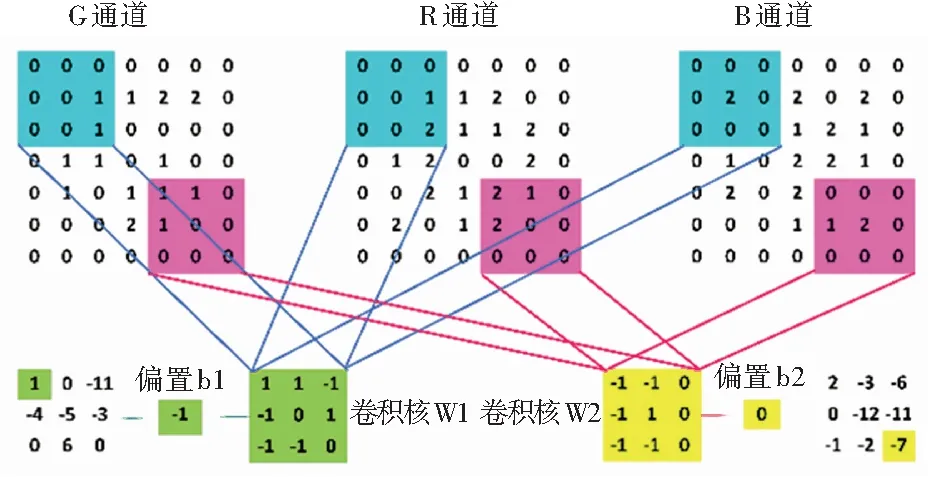
图7 CNN的卷积过程
5.2 基于VGG-19的AU识别网络结构
VGG网络是Oxford Visual Geometry Group于2014年提出的一种CNN模型,其采用连续的小卷积核代替较大卷积核,以获取更大的网络深度。例如,使用2个3*3卷积核代替5*5卷积核(图7)。这种方法使得在确保相同感知野的条件下,VGG网络具有比一般的CNN更大的网络深度,提升了神经网络特征提取及分类的效果。VGG网络与其他几种常用的CNN模型对比见表5。
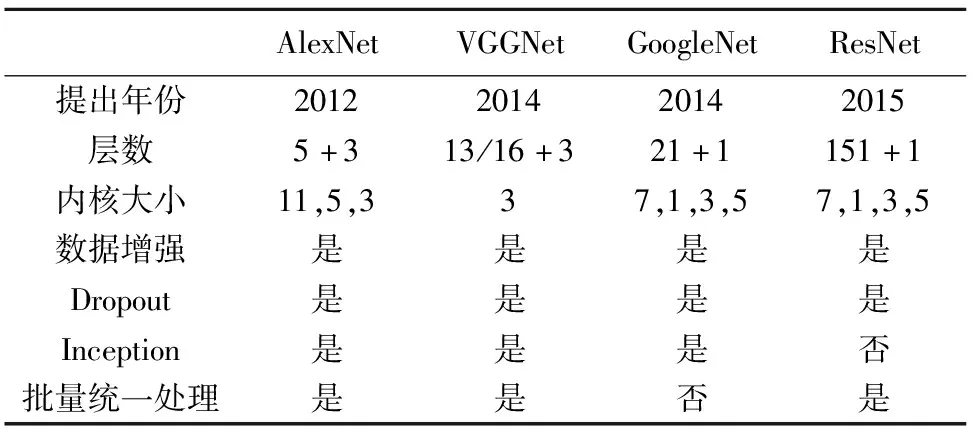
表5 几种常用的CNN模型
本方法使用的VGG-19网络包含了19个隐藏层、16个卷积层和3个全连接层。该网络模型使用的卷积核均为3*3卷积,池化层则采用2*2最大值池化(图8)。
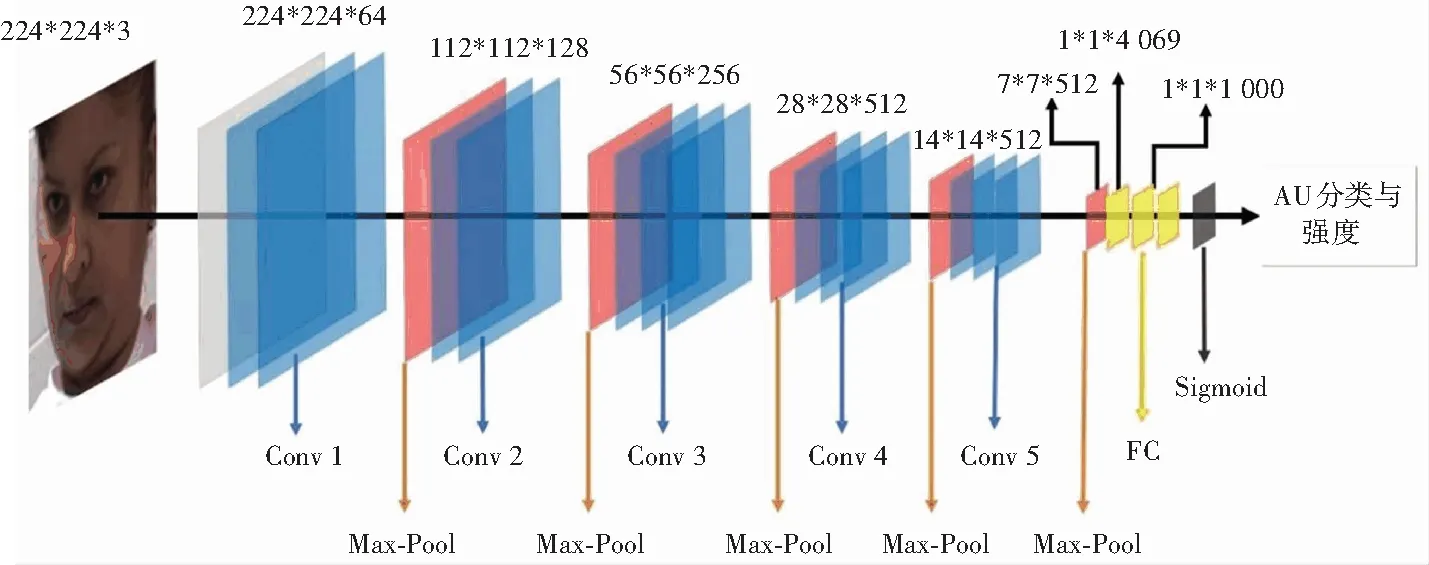
图8 VGG-19网络结构
以往的研究中通常使用Soft-Max作为激活函数,损失函数则使用分类交叉熵,但这种方法仅适用于单标签分类。而本文方法不仅实验AU分类,更要对同一AU的不同强度进行识别和分类,因此需要进行多标签多分类。本文方法需要分类的AU为12个,每个AU分为0~5个强度等级,总共为60种分类项。因此,本文采用二分类叠加使用的方式,即先对不同AU种类进行二分类,再对单个AU所对应的不同强度进行二分类,最后将每种AU与对应强度结合形成对照表。采用Sigmoid函数作为激活函数,损失函数使用二进制交叉熵函数。
在后续的实验中,还将向VGG19网络中加入一个加权处理层。
5.3 叠加的人脸AU特征检测
5.3.1 数据来源
DISFA是一个无姿势的面部表情数据库。该数据库包含具有不同种族的27位成人受试者(12位女性和15位男性)的立体声视频。使用PtGrey立体成像系统以高分辨率(1 024×768)采集图像,由FACS专家手动对所有视频帧的AU(0~5)强度进行评分。
5.3.2 AU分类与强度计算
87 492张图片分为两个数据集,其中86 224个子区域图片为训练集,1 268张人脸图片为测试集,输入至VGG-19网络。
图9与图10分别展现了使用VGG-19网络训练30个Epoch和60个Epoch的效果。
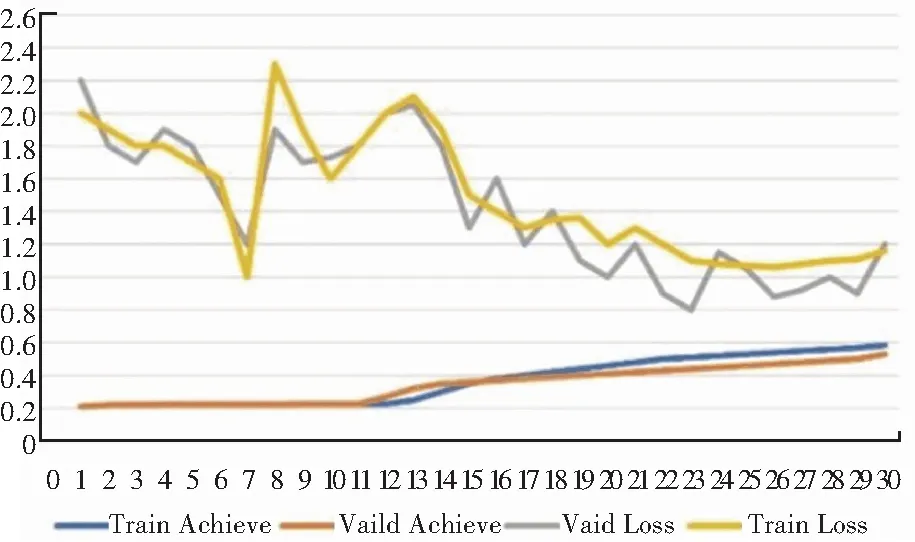
图9 训练30个Epoch的效果
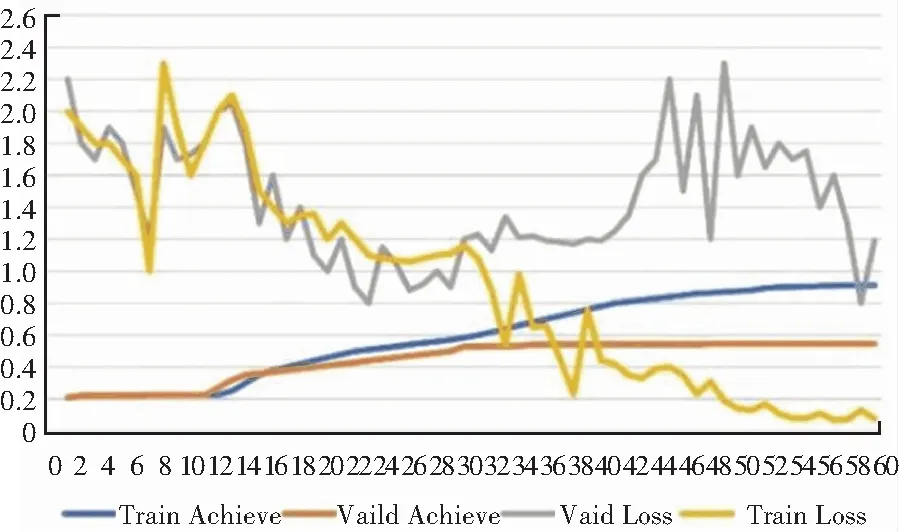
图10 训练60个Epoch的效果
可以看出,训练至第30个Epoch时测试集的准确率几乎不再发生改变,训练至第60个Epoch时测试集的准确率为54.52%。
结果呈现为每个人脸图片12种AU的强度(0~5)。以图11为例,其12种AU的强度呈现在右侧表中所示。

图11 人脸图片及其含有的AU强度
总体来看,该方法能基本满足人脸AU分类与强度计算,实现人脸表情分类。因此,为提高精度,将引入一个加权处理层。
6 人脸表情分类优化
为了提高VGG网络进行人脸表情分类时的精度,本文将通过在VGG-19网络中加入加权处理层,实现加权处理下的人脸表情分类。
6.1 加权处理层
加权处理层在VGG网络中的位置如图12所示。在这一层中,经过4组卷积层处理后的人脸图片会根据含有的AU,被划为若干个子区域,子区域的划分是基于AU区域的中心。AU中心为完成每个AU所需的面部器官对应关键点构成的矩形中心,而以这些中心为中心的边长6像素的正方形区域,为该AU中心的子区域。
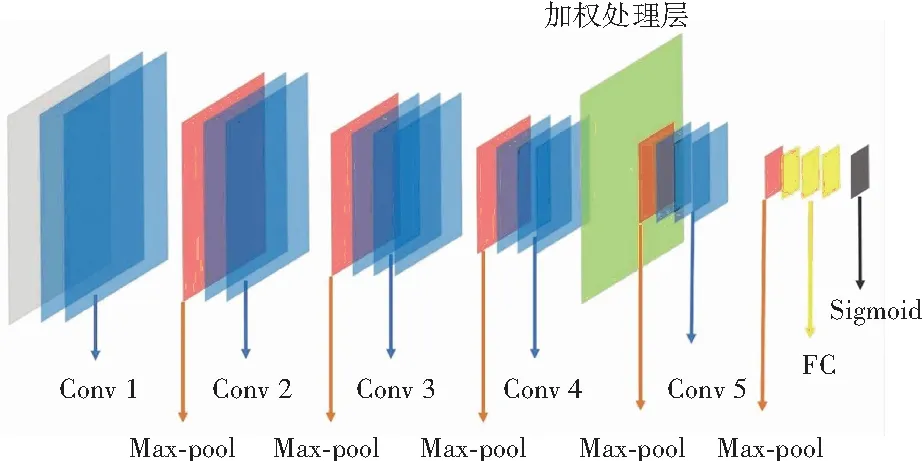
图12 加权处理层在VGG网络中的位置
在划分AU子区域后,对于子区域内的每个1*1像素块,计算其到AU中心的曼哈顿距离。
设A为权重,d为该位置到AU中心的曼哈顿距离。由于经过第三个池化层和第四组卷积层处理后的图片大小为28*28,子区域内每个位置的权重以该位置距离的0.1%进行衰减,即距离每增加1像素,权重减少0.028。A与d的关系如式(1)。
A=1-0.028d
(1)
6.2 结果比较
引入加权处理层后,训练30个Epoch和60个Epoch的效果分别如图13和图14所示。
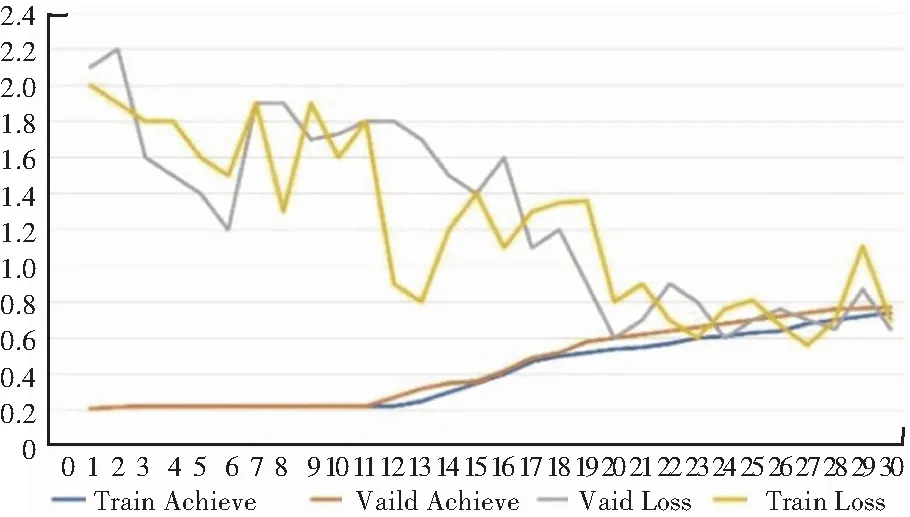
图13 训练30个Epoch的效果
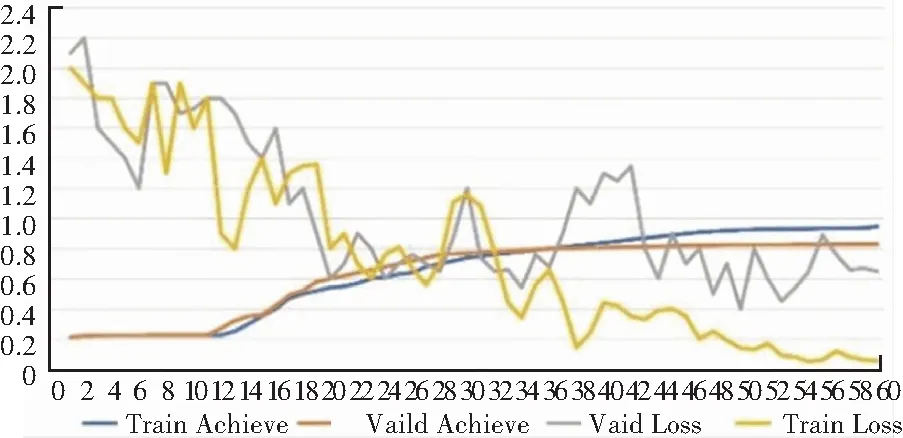
图14 训练60个Epoch的效果
结果显示,直接运用VGG-19网络进行表情分类的测试集准确率在训练60个Epoch时仅为54.52%,而引入加权处理层后的准确率达到了83.76%。即引入加权处理层能显著提高VGG网络进行表情分类的准确率。
7 结束语
本文采用了两种提高准确率的方法:一是在数据预处理阶段对图片进行二次剪裁,实现数据增强,在运用VGG网络进行训练时使用叠加后的数据集,提高了准确率,同时避免了以往研究中为获取庞大数据集而遇到的种种困难;二是在VGG-19网络的第四组卷积层和第五组卷积层之前加入一个加权处理层,从而提高准确率,最终使测试集准确率相比未引入加权处理层时提高了53.63%。
在采用了提高准确率的新方法的同时,也存在一些有待改进之处,主要体现在人脸图片样本较为单一、缺少其它卷积神经网络模型的对比、加权处理层作用较为单一等问题,有待进一步研究解决。
