基于改进VGG模型的低照度道路交通标志识别
2021-11-09赵树恩
赵树恩,刘 伟
(重庆交通大学 机电与车辆工程学院,重庆 400074)
0 引 言
快速、准确的交通标志定位与识别是自动驾驶环境感知的重要内容,也是决策规划的前提,对降低交通事故率和缓解日趋严重的交通拥堵等问题具有重大作用[1-2]。近年来对交通标志定位与识别的研究众多,且取得了较为满意的成果,但应用于多变的实际场景中,仍存在许多问题。
目前交通标志检测与识别的研究方法主要包含两类:基于传统图像特征提取结合机器学习的两步骤方法和基于深度学习的目标检测方法[3]。传统图像特征主要有:①基于颜色特征的方法,在RGB、H(色调)S(色饱和度)I(亮度)、HSV等色彩空间中分割出指定的色彩区域,然后提取出交通标志;② 基于形状特征的方法,首先需要对道路交通图像进行边缘检测,提取出其中特定的几何形状特征,然后利用机器学习的方法对定位出的交通标志分类,识别其语义信息。常用的机器学习方法为AdaBoost及支持向量机(SVM)。C.BAHLMANN等[4]同时考虑图像颜色特征及Haar特征,然后基于AdaBoost算法实现交通标志检测。C. G. KIRAN等[5]首先对图像进行色彩分割,将分割后的小块与边缘特征结合,然后利用SVM实现交通标志分类。
基于传统图像特征检测结合机器学习分类的方法可快速实现定位和识别,但对光照敏感性强,在有阴影、亮度低和存在遮挡和运动模糊的情况就难以取得较好的识别效果[6-7]。
随着深度学习理论的发展,卷积神经网络在目标检测方面的优势明显,避免了传统方法中的人工特征提取过程。基于卷积神经网络的主流目标检测算法有:①包含两个阶段的快速区域卷积神经网络(Faster- RCNN)[8],该类神经网络模型往往参数量和计算量巨大,需巨大存储空间保存模型,难以达到实时性要求;②端到端的单阶段模型,主要有YOLO(you only look noce)[9]、SSD(single shot multibox detector)[10],该类方法可直接定位和识别出交通标志的位置和类别,比前者效率提升,但精度有所下降。在实际场景中难以实现实时性与精度之前的平衡,王海等[11]对YOLO、Faster-RCNN及其改进的算法在道路交通图像中进行了验证,虽达到了较好的精度表现,但始终不能满足实时定位的需求,而定位失败的样本大多为阴天、傍晚或存在背光的情况,因此,实现低照度条件下的交通标志检测与识别,能大大优化无人驾驶车辆在感知过程中的表现。
针对上述问题,笔者提出一种快速的低照度道路交通标志检测与识别方法。首先采用CLAHE算法对图像进行增强;通过设定相关阈值,在HSV色彩空间分离出红色、黄色、蓝色像素区域(对应禁令标志、警告标志和指示标志);然后设定约束,定位可能的交通标志;为避免训练样本中各类别标志图像数据量差距过大发生过拟合,利用DCGAN模型对交通标志图像进行样本量增强;最后使用DC-VGG轻量化模型实现多类交通标志识别,论文的思路构架如图1。
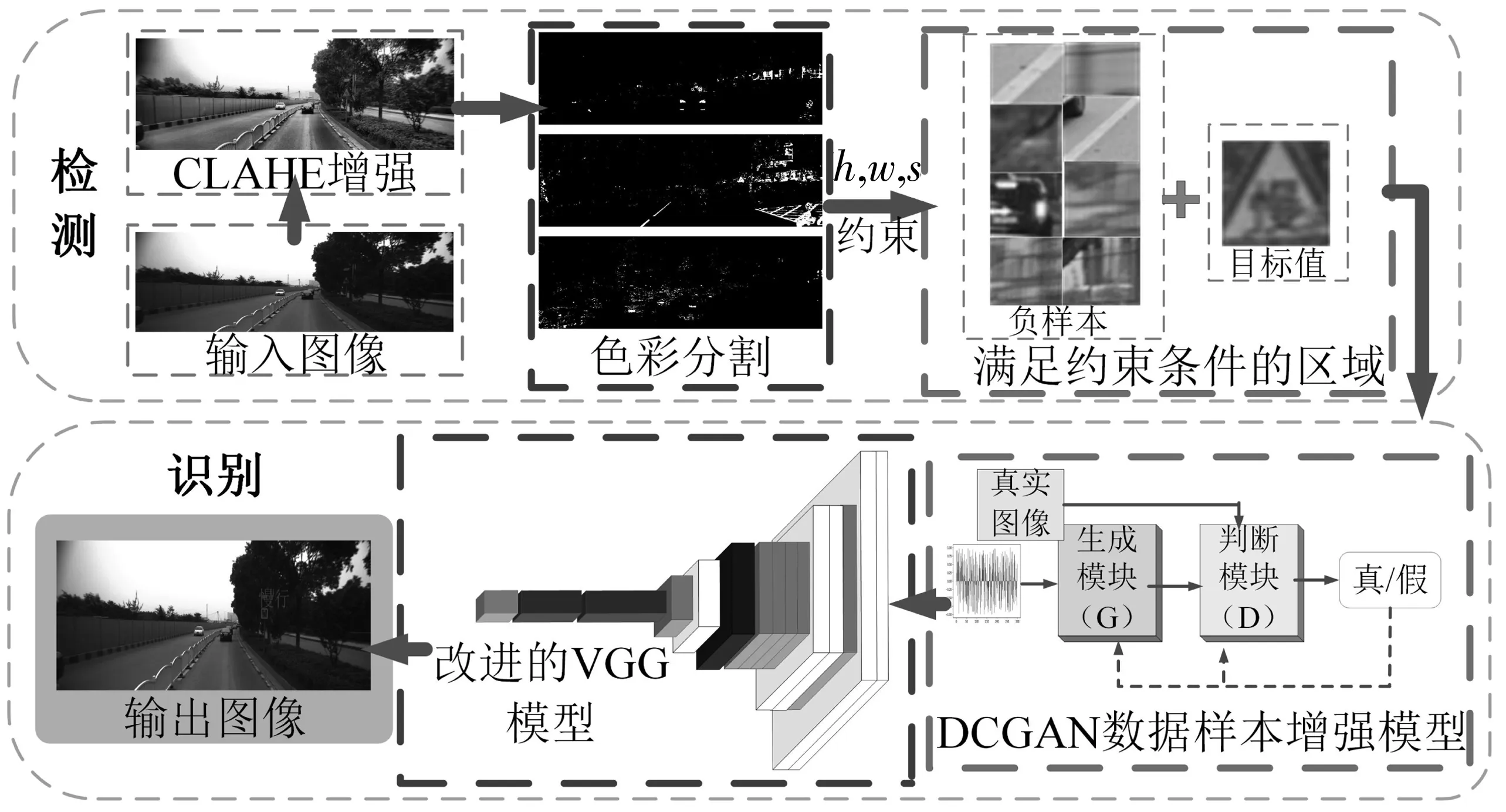
图1 思路构架Fig. 1 Idea framework
1 图像增强及交通标志定位
1.1 图像亮度自适应增强
为增加低照度条件下的识别精度,笔者利用CLAHE算法[12]增强输入图像的亮度。该算法通过对局部对比度进行限制,有效防止了噪声放大造成的图像失真,该算法常用于处理灰度图,实现灰度图的图像增强。针对彩色的道路图像,将其由RGB换到HSV色彩空间,利用CLAHE对V通道进行直方图均衡化,再将V通道重新聚合到原始图像中。该方法能在抑制高亮区域过曝的同时,有效提高暗部亮度,具体步骤如下:
1) 子块划分。将V通道均匀分割为d个子块。
2) 对比度阈值设定。对每个子块进行灰度级均分,每个灰度级最后分得像素量Na=m/Nc,其中m、Nc分别为各个子块中包含的像素个数及其灰度级。
阈值计算方式为:
T=Mc×Na
(1)
式中:Mc为截取限制的倍数。
3) 像素重新分配。将每个子块直方图中超出阈值T的像素,重新平均分配至各灰度级,再对各个子块进行直方图均衡化。
4) 双线性插值重构。双线性插值能有效防止直接拼接导致的块状效应,计算过程如下。
按x方向插值:
(2)
(3)
按y方向插值:
(4)
式中:P为插值点;v为该点像素值;x,y为各点的坐标,详细见图2。
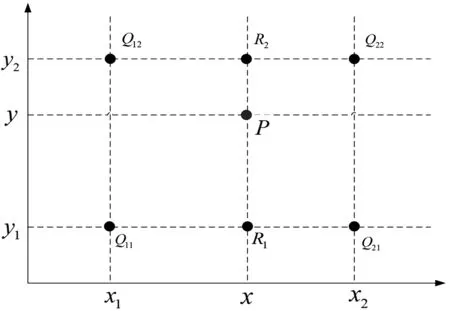
图2 双线性插值各点坐标Fig. 2 Coordinates of bilinear interpolation points
设定图像子块为8,经CLAHE算法增强后的道路图像如图3。
图3(a)、图3(b)为两张低照度道路交通图像;图3(e)、图3(f)为对应CLAHE增强之后的图像;图3(c)、图3(d)为对比了图像增强前后V通道直方图,显然低像素值区间像素个数得到很大抑制,增加了高像素值个数,从而一定程度上抑制高亮区域过曝,同时为暗区域提升亮度。
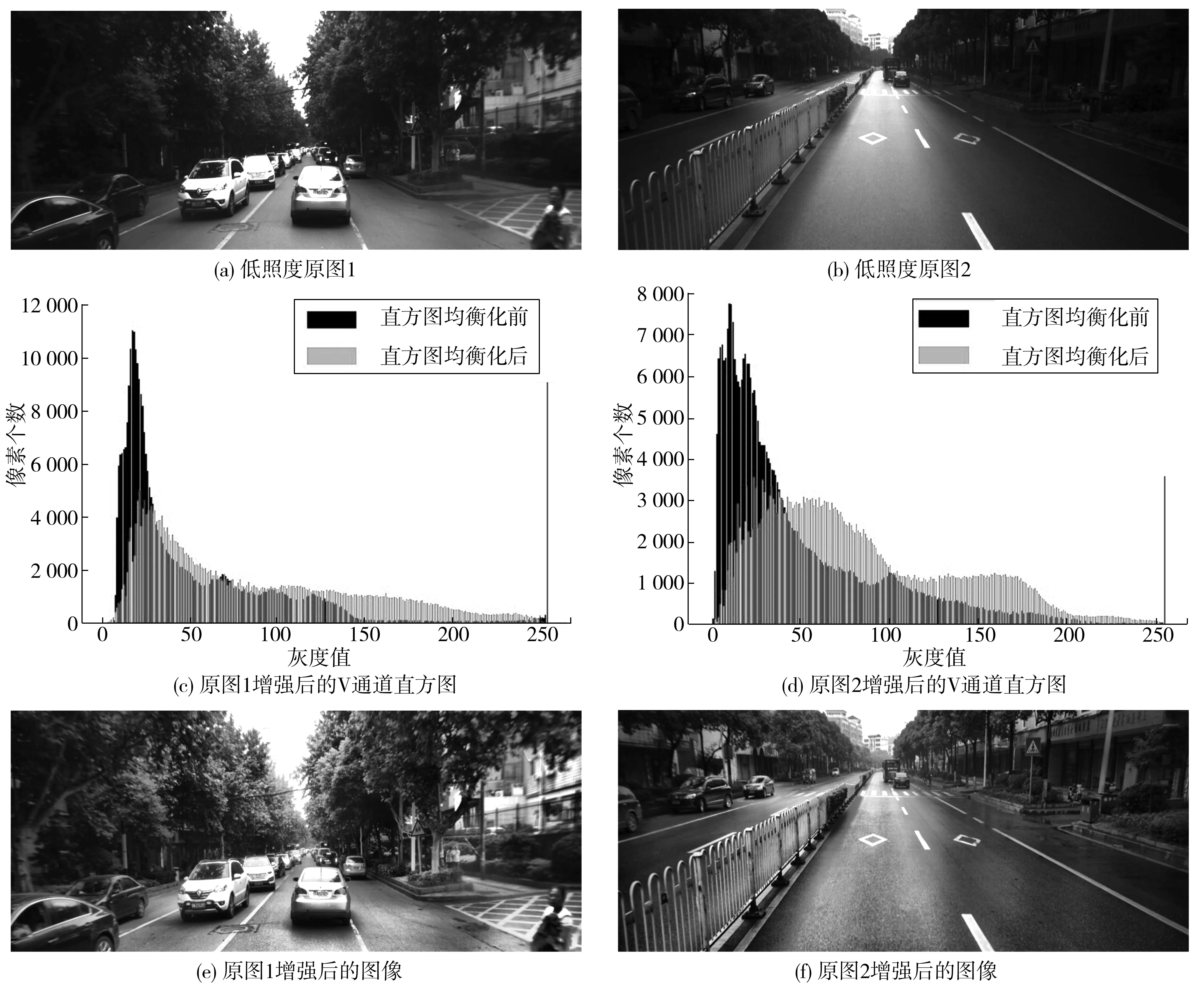
图3 图像亮度增强结果Fig. 3 Image brightness enhancement results
1.2 基于色彩特征的交通标志定位
由于国内的交通标志主要分为3种颜色:红色、黄色、蓝色,分别对应禁令标志、警告标志和指示标志。因此,要定位可能的交通标志,需将图像分割为仅包含红色、黄色、蓝色的二值图像。通过设定阈值,将转换到HSV色彩空间的道路图像进行分割。根据经验,阈值设定如表1。

表1 色彩提取阈值Table 1 Color extraction threshold
为了更好的提取红色像素,设定了两个区间的红色阈值,将鲜亮及较暗的红色均作为检测的目标,以降低漏检率。然后对得到的3个二值化图像进行轮廓检测,得到感兴趣区域外接矩形。设定约束条件为:
(5)
式中:w、h分别为外接矩形的宽高;s为输入图像的面积,以上变量均以像素为单位。
满足式(5)所述条件的区域即为可能的交通标志的位置。则图4中方框区域即可能为交通标志所在位置,但只有白色方框中的图像为真实的交通标志,其余框中图像标定为负样本。

图4 基于色彩特征的交通标志定位结果Fig. 4 Location results of traffic signs based on color features
2 交通标志识别模型
2.1 DC-VGG分类模型
传统VGG-16[13]共有13个卷积层、5个池化层及3个全连接层,其结构如图5。该模型共有6个阶段:1、2阶段由两个卷积层和一个池化层组成,提取图像的低级特征;3、4、5阶段均为3个卷积层加1个池化层的结构,通过设定大小为3×3的卷积核,既得到了较大的感受野,同时有效限制了参数量。
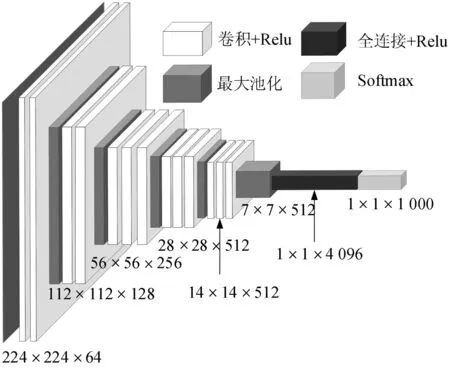
图5 VGG-16结构Fig. 5 VGG-16 structure diagram
传统的VGG-16网络模型全局使用3×3大小的卷积核,通过多个卷积层与池化层的堆叠实现深层特征提取达到较好的识别效果,但参数量巨大,导致训练和预测时需强大的硬件支持,且会耗费大量时间;此外,该模型浅层到深层特征关联性低,易导致细腻特征丢失。
为加快图像分类速度并保留细节特征,笔者在传统VGG理论基础上,提出基于膨胀卷积结合残差结构的DC-VGG轻量化道路交通标志快速识别模型,其基本结构如图6。
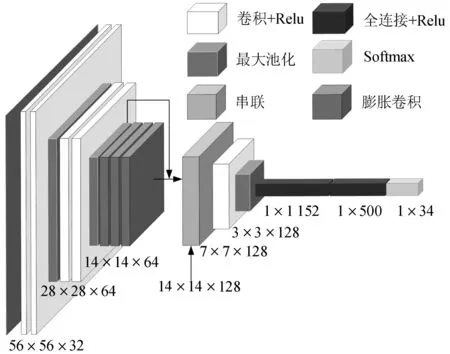
图6 DC-VGG结构Fig. 6 DC-VGG structure diagram
DC-VGG将传统VGG-16中的经典结构(3个3×3 卷积)替换为空洞率为3,卷积核为3×3的膨胀卷积层,为防止多层膨胀卷积叠加导致的局部信息丢失,引入残差结构,以确保图像的细节特征。
笔者所提出的DC-VGG模型由5个普通卷积层、3个池化层、3个膨胀卷积层及3个全连接层构成。相比于传统VGG-16该模型结构大大简化,引入膨胀卷积[14]可在卷积核不变的情况下,获取更大的感受野,从而减少参数量。感受野的计算方式为:
k′=k+(k-1)×(d-1)
(6)
RFi+1=RFi+(k′-1)×Si
(7)
式中:k为卷积核大小;d为空洞率;RFi+1、RFi分别为当前层和上一层的感受野;Si为当前层之前的所有层步长乘积。因此,1个空洞率为3,大小为3×3的卷积核感受野与3个3×3的卷积核感受野相同。
为适应文中输入交通标志图像大小,对每个卷积层大小进行了修改,修改后的结果见图5。在全连接层末端利用Softmax进行概率计算:
(8)
式中:aj、ak分别为输入Softmax向量的第j和第k个值;W为数据的类别数;Sj为Softmax输出的第j个值,即输入图像属于第j个类别的概率。对应的损失函数为:
(9)
式中:yj是图像的真实标签,维度为L,若y中第i位为1则标志该图像属于i类,其余位置的值均为0。
为与原模型形成对比,将传统的VGG-16模型每个卷积层的大小和通道数分别调整为原来的1/4和1/2,且令全连接层与DC-VGG相同。经调整,新的VGG-16总参数量为3 862 194,而文中的DC-VGG总参数量为953 970,参数量减少了75.3%。
2.2 基于DCGAN的数据样本增强
为避免不同类别的交通标志样本数量不均衡导致分类模型训练结果出现过拟合现象,笔者应用深度卷积对抗神经网络扩充交通标志样本量。
DCGAN实际上是在GAN的基础之上增加了深度卷积神经网络[15],由generator(G)和discriminator(D)两个模块构成,其结构如图7。D负责下采样提取图像深度信息,判断图像真假。通过形状变化和上采样,G将输入的噪声数据转换成目标图像,在每次学习中更新,与D相互博弈,以生成接近真实的目标图像。
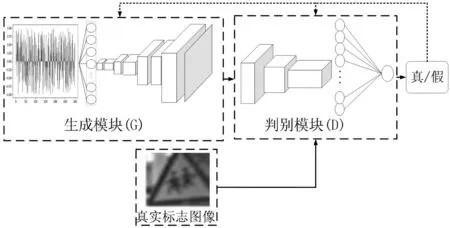
图7 DCGAN结构Fig. 7 DCGAN structure diagram
3 实验结果
文中的实验环境配置如下,硬件:使用Intel i7-8300 处理器,内存为DDR 8GB,显卡为NVIDIA GTX1050TI;软件:实验平台为基于Python语言的Tensorflow-GPU深度学习框架。
3.1 数据准备
运用的数据源自CCTSDB公开数据集,共有道路图像15 000余张,包含大量低照度道路图像。对其中13 000个图像进行自适应图像增强及交通标志定位,除去数据量太少的交通标志类别,得到禁令标志16类,警告标志9类、指示标志14类。合并负样本数据,最终确定分类模型的输出维度为34。
由于33类交通标志图像数据量有不同程度的差距,且相较于总数达到6 450的负样本数据,差距甚大。因此,在模型训练之前,先对这33类交通标志数据量增强。DCGAN增强后的部分结果如图8,图中左侧为实际提取到的标志图,右侧为分辨率56×56的生成结果。通过该方法将每类交通标志图像数据均扩充至3 000个。
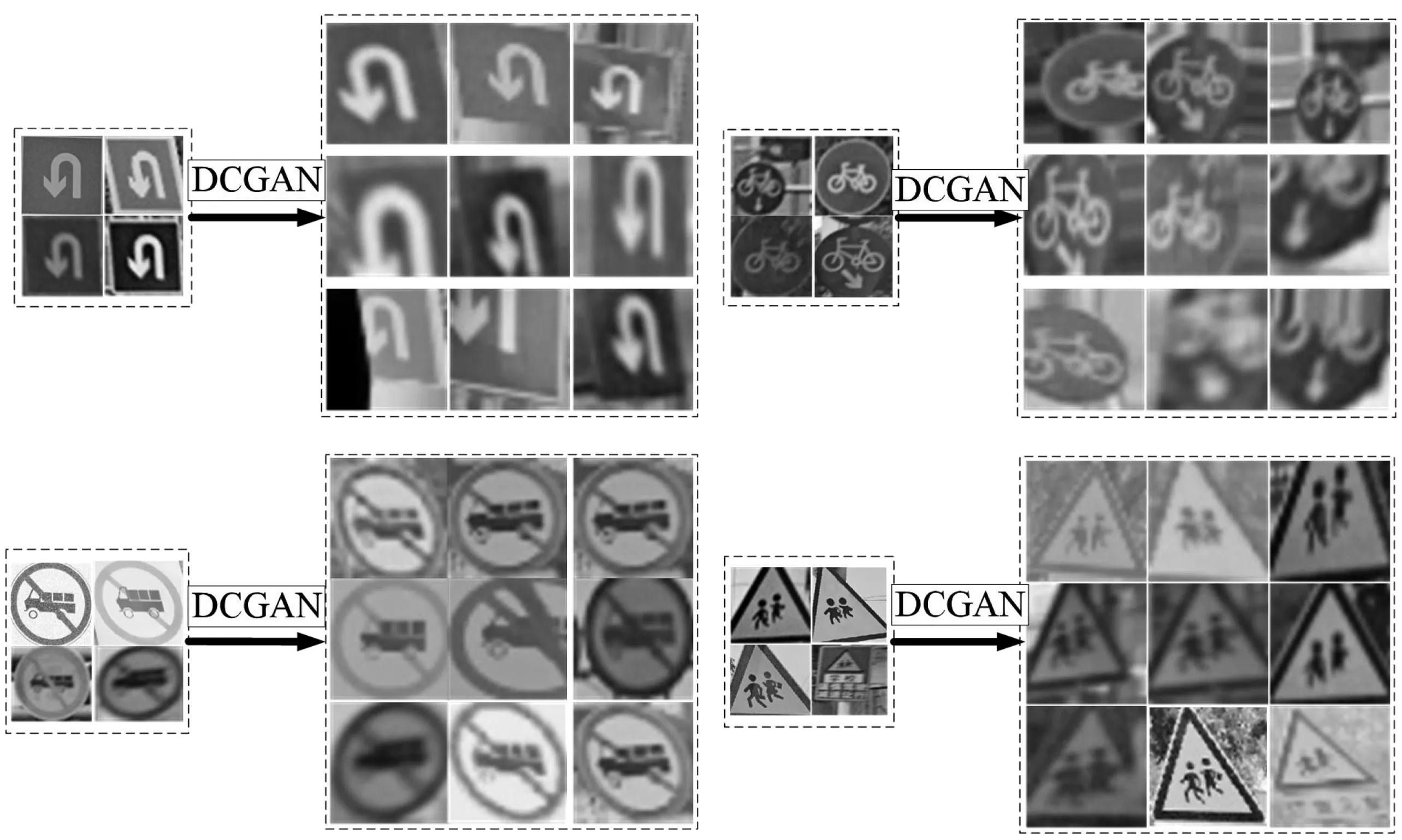
图8 DCGAN数据样本生成示意Fig. 8 Schematic diagram of DCGAN data sample generation
3.2 结果分析
将增强后的数据集,按8∶2的比例划分训练集和验证集。得到的训练结果如图9。
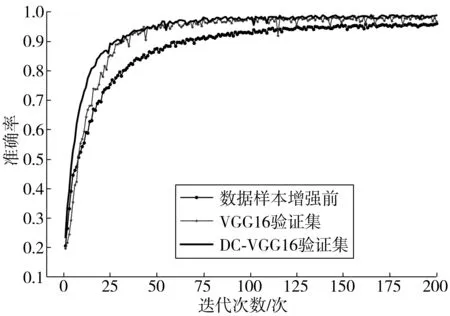
图9 训练结果Fig. 9 Training results
由图9可知,在不进行数据样本增强的情况下,验证集上表现出的准确率最低,且准确率上升的速度最慢;DC-VGG相较于VGG-16准确率上升更快,且具有VGG-16的性能表现。详细数据见表2。

表2 模型训练结果Table 2 Model training results
由表2可知,DC-VGG的准确率略高于VGG-16方法,均达到0.98以上;该方法较VGG-16训练总时长缩短26.6%,平均单个标志预测时长缩减14.4%。
为进一步验证该方法对交通标志识别的有效性,选择在剩余2 000余张图像中随机抽取800张道路图像进行识别。经统计,该方法识别准确率达到94.12%,略低于YOLOv3的交通标志检测模型平均准确率94.6[16],但在1050TI平台下,文中的方法平均检测速度达到28.55帧/s,远高于YOLOv3的8.77帧/s。因此,笔者所提出的方法能保证识别准确率的同时提高辨识的实时性。图10为低照度不同场景下道路交通标志的定位识别结果。

图10 道路交通标志识别结果Fig. 10 Road traffic sign recognition results
4 结 语
针对低照度情况下道路交通标志图像亮度偏低、饱和度过高、图像模糊、识别不精确等问题,提出了基于膨胀卷积-VGG模型的道路交通标志快速定位与识别方法。通过CLAHE算法增强原始图像亮度,并运用深度卷积对抗神经网络算法对样本进行扩增,实现了道路交通标志快速识别。实验结果表明,笔者所提出的方法能在低照度、遮挡等情况下都有优异的表现,并且即使在硬件不佳的情况下也能实时检测高分辨率图像。由于车载视觉成像设备获取的道路交通标志标线图像质量受气象、光照、环境等因素影响较大,进而直接影响标志标线识别算法的可靠性和鲁棒性,在未来工作中,还有进一步研究交通标志特征的自适应提取方法,从而提升识别模型的辨识速度与精度。
