面向关键字流图的相似程序间测试用例的重用∗
2021-11-09钱忠胜
钱忠胜,宋 涛
(江西财经大学 信息管理学院,江西 南昌 3 30013)
软件测试是为了发现程序错误,以提高程序质量的一个过程[1,2].软件测试贯穿软件开发的整个过程,是软件开发不可或缺的一个环节.通常在软件生命周期中,30%~40%的时间和精力花在软件测试上[3].研究表明:在软件测试中,毫无限制地对所有程序进行验证,将会花费维护费用的50%[4,5].而软件测试的重用在提高软件测试质量、缩短测试周期和改善测试人员的经验不足等方面,均起着十分重要的作用.目前,软件测试重用的研究已成为软件测试工程化研究的热点之一[6].
软件测试重用技术是指在新的软件测试工作中重复使用已有的测试资源,其目的是充分利用之前软件测试中的经验和成果,增强测试的效率和可靠性[7].测试用例的重用是指测试工程师在执行回归测试或者一项新的测试工作时,通过直接调用或修改已经生成的测试用例,并将它们运用测试的过程,而不用每次面对新的测试工作都需要从头开始设计测试用例.测试用例作为软件测试的核心内容,它的重用是整个软件测试重用的关键环节[8].
测试用例重用的研究主要包含两个方面:可重用测试用例的生成和可重用测试用例的管理[9].本文主要研究将程序已有测试用例使用到相似程序测试用例的生成过程中,故检测待测程序之间的相似度是研究用例重用的前提.
程序代码相似性的研究技术基本成熟,主要运用于计算机教学和软件剽窃检测等领域[10].最长公共子串和Levenshtein 距离等程序相似性度量算法重点考察源代码之间的相似程度,而基于图的结构特征的相似性分析方法使用图的结构来反映程序功能特征的相似性分析方法[9].图的结构特征是较为高级的语法特征,主要包括控制流图和数据流图两种:控制流图反映了程序的逻辑结构,数据流图反映了程序的数据流转关系.
可见,程序相似性的判定可以从序列和图等不同的特征进行.本文研究程序间相似性的目的是研究相似程序间测试用例重用的方法,以此提高测试用例的生成效率,减少软件测试的工作量.主要做了以下工作.
1)对于待比较相似性的程序,构建它们的关键字流图.比较流图节点中的关键字是否相同,具有相同关键字的节点构成公共关键字流图子图;
2)程序的关键字流图和关键字流图最大公共子图构建完成后,利用最大公共子图距离方法比较待测程序的相似程度,相似程度较高的程序可用于测试用例的重用;
3)测试用例的重用是将程序已有的测试用例共享于相似程序.采用遗传算法来完成测试用例的重用,将相似程序已经生成的测试用例引用到种群进化的过程中,种群的其他个体通过向这些测试用例学习加快进化速度,完成测试用例的重用.
本文第1 节分析程序相似性及测试用例重用的相关工作.第2 节研究相似程序的判定,主要涉及关键字流图构建方法、关键字流图最大公共子图的查找以及根据最大公共子图距离求得待测程序的相似度.第3 节提出相似程序间测试用例重用的方法,并阐明将遗传算法用于测试用例重用的原因;实验多方面将本文方法与传统方法在测试用例生成中的效率进行对比,根据实验结果给出本文存在的不足以及有效性分析.第4 节总结全文,并提出下一步的研究工作.
1 相关工作
程序相似性的制定标准是一项重要工作,近年来,不少学者从语义结构和图等不同方面探究程序的相似性.
Kwon 等人[11]利用子图作为检测恶意程序的特征,因为同一个恶意程序家族中的程序会共享子图.子图的查找则需要程序样本中抽取API 调用建立分层级行为依赖图,用它们寻找子图.Wang 等人[12]提出了使用控制流图和数据流图特征对二进制程序进行相似性比较和同源分析的方法,实验对象采用微软不同版本的动态链接库验证算法的有效性.该算法比较适用于同一公司发布的同源良性程序相似度的比较.
1965年,Levenshtein[13]提出Levenshtein 距离算法,该算法常用于字符串的比较,计算两个字符串差异的大小.源字符串通过添加、修改、删除等操作变化到目标字符串,其最少的改变次数看作是 Levenshtein 距离.Levenshtein 距离越小,字符串的相似度越大.Wang 等人[14]提出两种基于双向比较的最长公共子串算法,该算法将动态规划算法(LCSstrDP)与后缀数组算法(LCSstrSA)相结合,有效地解决了动态规划算法计算速度较慢的问题,却增加了算法的复杂度,计算效率不高.Rong 等人[15]为了解决程序需要从两个给定集合中找到所有类似的字符串对的问题,提出一种在单个操作符中支持不同相似阈值的字符串相似性连接的方法,就判定程序相似性阈值的设定,设计了新的索引技术,针对不同的程序设计了不同判定程序相似的阈值,使得判定程序相似性更加准确,但复杂度较高.
Mc.Cabe[16]提出了圈复杂度的结构度量技术,该技术在流图基础上计算它的圈度,很多时候需要与其他特征结合进行程序结构的度量.陈浩与王广南等人[10]提出了基于程序依赖图的动态胎记技术来检测程序的相似性,该方法首先对流图的公共子图进行胎记标记,通过比较最大公共子图距离来判断程序相似性.这兼顾了局部特征和整体特征,但公共子图同构判定的局限性比较大.
分析程序相似性的目的是为了探究相似程序间测试用例重用的有效性,而测试用例的生成是用例重用的前提,只有保存足够的已生成的测试用例,才能完成它们的重用.近年来,国内外开展了许多关于重用测试用例和测试用例的生成等方面的研究工作.
Mayrhauser 等人[17]通过领域建模来构造可重用的测试用例,其构造包括脚本化、命令模版和参数值选择这3 个部分,并开发出基于领域建模的测试用例生成工具Sleuth.Vouffo-Feudjio 等人[18]提出了基于TTCN 的测试模式,并探讨了该模式的重用规则,包括怎样在不同产品之间的水平重用和不同版本之间的纵向重用.
巩敦卫等人[19]就提高回归测试中测试数据的生成效率,提出一种新的回归测试数据进化生成方法.该方法利用已有的测试数据穿越路径与目标路径的相似程度,选择相似程度较高的测试数据作为初始化种群的部分个体.进一步,根据已有测试数据穿越路径与目标路径的对比,确定个体实施遗传操作的位置.姜淑娟等人[20]提出了基于模式组合的粒子群优化测试用例生成方法,通过新设定的交叉算子,将个体中的含有模式的部分组合成新个体,利用遗传算法生成测试用例的过程中,种群中其他个体均可向该适应度较高的新个体进行学习,加快种群进化速度,提高测试用例生成效率.
将程序的相似性应用在计算机教学和恶性程序检测等领域的研究比较多:最长公共子串算法[14]比较字符串的相似性,字符串的相似性完全取决于最长字符串的长度,具有片面性;Levenshtein 距离算法[13]比较适用于规模较小的程序相似性的比较;基于程序依赖图的动态胎记技术[10]来检测程序的相似性,需要公共子图的同构作为前提条件,局限性比较大.
在前人研究的基础上,本文提出面向关键字流图程序相似度的方法.该方法兼顾了源代码序列和程序功能结构相似度的比较两个方面.另外,借鉴巩敦卫和姜淑娟等人[19,20]的思想,提出了相似程序间测试数据的重用方法,通过相似程序间测试用例的共享实现用例重用.即:待测程序利用遗传算法生成测试用例,在种群进化阶段引入相似程序中已经生成的测试数据;在迭代过程,以一定概率向这些个体学习.与传统遗传算法种群个体之间相互学习的进化方式作对比,测试用例生成效率较高,证明了测试用例重用的有效性,而相似程序间测试用例重用的效果证明了判断相似程序方法的可行性.
2 程序相似性的判定
本文对程序相似性的判定结果应用到相似程序间的测试用例重用中,故程序相似度的判定不仅注重语义上的相似性,更加注重程序功能结构上的异同.本节提出关键字流图的构建方法,通过构建的关键字流图查找待测程序的关键字流图最大公共子图.最后,通过最大公共子图距离算法求得程序的相似度,程序相似性的比较如图1所示.本节给出判定程序相似性的步骤以及与程序相似性判定相关的定义.程序相似性判定的流程如下.
1)判断待测程序能否实现测试用例的重用:首先观察测试程序所输入的参数是否受到个数限制,如果测试待测程序时输入的参数数量都是一定的,而且它们所限定的数量是不同的,意味着它们的测试用例无法直接共享,本文不作比较;
2)关键字流图最大公共子图的构建:若待测程序之间能够实现测试用例的重用,则构建关键字流图,利用动态规划算法比较关键字流图中关键字的异同.若关键字相同,则该关键字所属的节点即属于公共流图子图,并对此节点进行标记,以此构建待测程序的关键字流图最大公共子图;
3)相似度的判定:使用最大公共子图距离算法计算关键字流图子图距离,该距离的大小决定了程序的相似程度.

Fig.1 Determining program similarity图1 程序相似性的判定
2.1 相关定义
定义1(关键字).作为代码核心的标识符,用于表示一种数据类型或程序结构.像Java 和C 语言等编辑语言都有自定义的关键字.本文选择Java 代码编写的程序作为实验对象,表1 列出了Java 语言中的关键字.

Table 1 Key words of Java language表1 Java 语言的关键字
定义2(关键字流图).关键字流图(keyword f low g raph,简称KFG)是一个五元组(V,E,keyword,entry,exit),其中:V表示节点集,源程序的每个基本语句块都对应流图的相应节点;E是边集,表示语句的流向;keyword表示关键字集,存储着节点中的关键字,若源代码中无关键字,该节点储存字符null;entry 和exit 分别表示程序唯一的入口节点和出口节点.
定义3(关键字流图公共子图).节点集V中的每个节点均是关键字流图G1中的节点,同样又是关键字流图G2中的节点,那么节点集V在流图上构成的图即为流图G1和G2的公共子图.若存在节点集G,且G1和G2不存在其他的子图的节点数大于G,那么G是G1和G2的一个最大公共子图[8].
定义4(前缀与后缀)[14].前缀Pref[S,i](1≤i≤L),指从字符串S的第1 个字符开始至字符串的某个位置i结束的特殊子串,可记为S[1,i];后缀Suffix[S,i](1≤i≤L),指从字符串S的位置i开始至整个串末尾的一个特殊子串,可记为S[i,L].
根据定义4,公共前缀(后缀)表示一个字符串既是字符串S的前缀(后缀),又是字符串T的前缀(后缀),那么该字符串是字符串S和T的公共前缀(后缀).
定义5(最大公共子图距离).给定两个非空图G1和G2,以及它们的最大公共子图mcs(G1,G2),它们之间的距离[21,22]可表示为

其中,|G1|和|G2|分别表示G1,G2的节点数,mcs(G1,G2)表示最大公共子图的节点数.那么图G1与G2的相似度可以定义为

定义6(组间变异和组内变异).在统计学中,组间变异表示数据的各组平均数与总平均数之间的离均差平方和,记为SSTR;而组内变异表示每组数据中的每个测量值Xij与该组平均数之间的离均差平方和,记为SSe.它们的公式分别表示为

其中,ni为第i组的组内数据个数,k为组数.
定义7(方差分析).在统计学中,方差分析(analysis of variance,简称ANOVA)是用于两个及两个以上样本均数差别的显著性检验,又称为“变异数分析”或“F检验”.F值为组间均方MSTR与组内均方MSe的比值,表示为
F=MSTR/MSe(4)
其中,MSTR=SSTR/k−1,MSe=SSe/N−k.这里,N为各组数据个数的和,k为组数.
2.2 关键字流图的构建
关键字是代码核心的标识符,能够代表代码的结构或者数据类型.某些代码中的关键字相同,意味着它们的代码结构相同.源代码中,每行代码或者功能相近的若干行代码为一个基本块,每一个基本块构成一个节点.关键字流图的节点中存储了形成该节点基本块中的关键字,若基本块中无关键字,此节点存储字符串null;若该行代码存在两个及以上的关键字,记录第1 个关键字即可.构建关键字流图的步骤类似于控制流图的构造过程,已有很多研究,本节不再做具体说明.下面是冒泡排序的关键字流图构造示例.
图2 中,图2(b)是图2(a)冒泡排序源码所对应的关键字流图.可以看出,关键字流图节点中存储了形成该节点的关键字.例如:生成第2 个节点的基本块中含有关键字int,该基本块在生成关键字流图过程中将该关键字储存在相应的节点上.待测程序的关键字流图构建完成,接下来比较待测程序关键字流图中关键字的异同,构建待测程序的关键字流图最大公共子图.图3~图5 分别给出了冒泡排序的控制流图、程序流程图和数据流图等几种比较常用的软件结构图与关键字流图的比较.通过对比发现:
•关键字流图比较程序相似性,注重程序的结构和功能上的异同,符合功能结构相同的程序,其测试用例会以更大概率共享的理念;
•控制流图能表达程序的结构,但不能展示图中每个节点的功能;
•程序流程图能清晰地表达程序的流程及功能,但存在许多相似节点合并的现象;此外,用自然语言总结节点功能存在一定的主观性,会因个人用语不同而存在文字上差别较大的情况;
•数据流图比较详细地阐述了程序主体及功能,也因此使其更加复杂,在比较程序相似性方面存在与程序流程图相同的缺点.

Fig.2 Bubble sorting program and its keyword flow graph图2 冒泡排序程序示例及其关键字流图

Fig.3 Control flow graph and keyword flow graph of bubble sorting program图3 冒泡排序的控制流图及其关键字流图

Fig.4 Program flow chart and keyword flow graph of bubble sorting program图4 冒泡排序的程序流程图及其关键字流图

Fig.5 Data flow diagram and keyword flow graph of bubble sorting program图5 冒泡排序的数据流图及其关键字流图
2.3 关键字流图最大公共子图的生成
待测程序根据第2.2 节关键字流图的构造方法生成关键字流图,在关键字流图的基础上寻求它们的最大公共子图,最大公共子图的大小关系到待测程序的相似程度.动态规划算法[14]寻找公共子字符串是解决公共子字符串的经典算法之一,该算法能得到全局最优解.本节利用该方法求得相似程序的关键字流图最大公共子图.
在利用动态规划算法求解两个长度分别为p,q的字符串S,T的最长公共子串的问题之前,先给出求它们任意前缀子串对S[1,i],T[1,j]的最长公共后缀的算法.该问题的递推关系如公式(5):
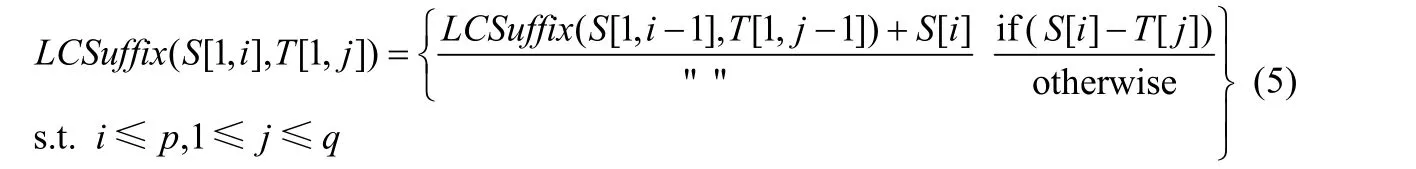
其中,LCSuffix(S[1,i],T[1,j])表示前缀子串对S[1,i],T[1,j]的最长公共后缀.
在字符串S和T所有前缀子串对的最长公共后缀中,长度最大的即为字符串S和T的最长公共子串,即:

其中,LCS(S,T)表示字符串S和T的最长公共子串.
关键字流图节点中的关键字可以看作由这些关键字组成的字符串中的一个字符,关键字流图节点中的关键字构成字符串,利用动态规划算法生成关键字流图最大公共子图,步骤如下.
1)利用公式(5)和公式(6)求得最长公共子串;
2)null 字符代替两个关键字字符串中的最长公共子串.在进行关键字比较时遇到同为null 时,需要考虑null 所在节点边的情况,若来源于相同的关键字而且又指向相同的关键字,则将该节点计入最大公共子图中;
3)判断最长公共子串的长度是否大于0:若长度大于0,重复步骤1)和步骤2);否则,结束.
例如,字符串S=“public,int,if,null,for,if,null”,T=“public,int,for,for,if,null”,使用递推关系(见公式(5)和公式(6))求得字符串S和T所有前缀子串对的最长公共后缀,见表2.
字符串S为快速排序程序关键字流图的节点中关键字的组合,T字符串则代表了冒泡排序程序关键字流图中关键字的组合.从表2 中可以看出:字符串S和T的公共子串为“for,if”和“public,int”,字符串S和T的最大公共子串为“public,int,for,if”.字符串S和T分别为快速排序和冒泡排序关键字流图节点存储信息组合而成.根据字符串S和T的最大公共子串构建关键字流图最大公共子图.

Table 2 Finding common keywords using dynamic programming algorithm表2 动态规划法查找公共关键字
图6 是冒泡排序和快速排序关键字流图的最大公共子图(灰色部分).灰色部分节点存储了字符串S和T公共子串中的关键字,关键字流图的最大正是由S和T公共子串的关键字所在的节点构成.

Fig.6 Maximum common sub-graph of keyword flow graph(in gray)图6 关键字流图的最大公共子图(灰色部分)
2.4 程序相似性的判定
待测程序快速排序与冒泡排序的关键字流图最大公共子图已经生成,本节利用最大公共子图距离算法(见定义5)计算程序相似程度.最大公共子图距离公式(公式(1))中,|G1|和|G2|分别表示程序快速排序和冒泡排序的节点数,mcs|G1,G2|表示最大公共子图的节点数.由图6 知:冒泡排序与快速排序存储关键字的节点都为5,关键字流图最大公共子图的节点为4,故max(|G1|,|G2|)=5,mcs|G1,G2|=4,将具体数值带入公式,可得最大公共子图距离D(G1,G2)=0.2.公式(2)将程序相似度定义为1−D(G1,G2),已知冒泡排序和快速排序的最大公共子图距离0.2,故两程序的相似度S(G1,G2)=(1−D(G1,G2))×100%=80%.
基于关键字流图判定程序相似度的伪代码见算法1.
算法1.程序相似度的判定.
输入:待测程序program1,program2;
输出:待测程序相似度similarity.

本节采用自适应的方法进行实验来选取程序是否相似的阈值[23],实验对象为已知功能相近的程序或者不相近的程序,实验方法为本节所提的程序相似性检测方法.表3 和表4 分别给出了本文方法验证部分基础程序及系统中常用功能程序的相似性实验结果.

Table 3 Testing of the similarity between basic programs(%)表3 基础程序间相似性的检测(%)

Table 4 Testing of similarity between commonly-used programs in the system(%)表4 系统常用功能程序间相似性的检测(%)
表3 考察了多个查找算法和排序算法两种不同功能的程序.从表中实验的数据可以看出:功能相近程序的相似性皆超过70%;而不同功能的程序即使程序规模相近,其相似度也在70%以下.本文将70%设定为程序是否相似的阈值.
表4 中选用系统中常用的功能程序考察其相似度.用户登录a与用户登录b是两种不同脚本的登录算法,登录验证为用户登录时后台的验证算法.用户登录、身份验证、数据处理和信息下载为同一系统下不同功能的算法.表4 中的实验结果再次验证了功能相同的程序间相似性较高,而功能不同的不相似程序的相似度均在70%以下,证明本文将判定程序是否相似的阈值设定在70%的合理性(在判定规模较小的程序时存在一定的偶然性,应将特例排除).
2.5 用关键字流图比较程序相似性的优势
公共关键字流图子图比较程序相似性具有以下优势.
1)将程序转化成关键字流图,关键字是代码的核心标识符,关键字相同的节点意味着生成该节点的代码语句结构相同.通过比较关键字流图来判定程序的相似性,解决了两个程序功能相同但源代码差异较大的问题;
2)本文是在关键字流图最大公共子图的基础上比较程序的相似度.相对于最长公共子串比较相似性,公共关键字流图子图更大程度比较了两个程序,避免了最长公共子串比较程序只取决于最长公共子串大小片面性的问题;
3)关键字流图的节点代表程序中的基本块,用关键字流图比较程序的相似性比较方便.而不在源代码上直接比较关键字是否相似,因为从源代码上比较关键字是以行代码为单位,容易造成程序代码的书写格式不同带来的误差.
例如,图7 为冒泡排序另一种编写方式的部分代码,由于编程习惯不同,有些程序员会把第2 行~第4 行代码写成“intt,i,j;”,两种书写方式功能完全相同.第2 行~第4 行代码的作用是定义整型变量,属于一个基本块,会生成关键字流图的一个节点.而基于源代码进行关键字比较时,则会因为不同的书写格式造成不同的结果.

Fig.7 Partial source code of bubble sorting program图7 冒泡排序部分源代码
2.6 程序相似性检验插件的原型
插件服务于软件项目主体,有效地扩展和完善了寄主软件的功能[24].基于本文第2.2 节~第2.4 节程序相似度比较的方法,开发了一个检测程序相似程度的插件,如图8所示.此插件的制作,方便了程序相似性的比较.下一节探究相似程序间测试用例重用的问题,其前期工作就是需要判断程序之间的相似程度,此插件将减少了判断程序相似性的工作.
插件的开发选用Java 作为编辑语言,开发环境为MyEclipse 20 10.计算机配置为Windows(Intel(R)C ore(TM)CPU i5-6500,3.20GHz,8.00GB RAM,64 位操作系统.图8 为检测程序相似程度的插件运行界面.

Fig.8 Plug-in for detecting program similarity图8 检测程序相似性的插件
按钮“Select pr ogram 1”和按钮“Select pr ogram 2”是两个选择待测程序的按钮,测试程序的相似度时,分别点击这两个按钮选择待测程序所在的文件,实验选择的待测程序为冒泡排序与快速排序.点击“Testing”按钮,将以百分数的形式显示两个待测程序的相似度.
通过检测,冒泡排序与快速排序的相似度为80%,大于设定的阈值,可以判定冒泡排序和快速排序为相似程序,并被设定为下一节研究相似程序间测试用例重用选择的实验对象.
3 基于遗传算法的相似程序间测试用例的重用
本节利用遗传算法完成测试用例的生成,实现测试用例的重用.遗传算法作为一种基于自然选择原理和自然遗传机制的通用搜索算法[25,26],通过进化过程获得的信息自行组织搜索,适应度大的个体具有较高的生存概率,并获得更适应环境的基因结构.在进化的遗传操作中,适应度较高的个体以更大概率将更优秀的基因遗传给下一代.
遗传算法具有良好的可扩展性,容易与其他算法相结合,也可以调节遗传操作和适应度函数等方式提升算法的效率.本节在种群进化过程上引入适应度较高的个体来提高测试用例生成的效率.其基本思路(重用模型如图9所示)如下.
1)假设一个程序适应度较高的测试用例已经生成,将这些测试用例应用到其相似程序的测试中.实验采用遗传算法来完成测试用例的重用;
2)利用遗传算法测试待测程序时,将重用的测试用例引用到遗传操作的种群进化中,种群的其他个体通过向这些测试用例学习,目的是加快种群进化速度,提高测试用例的生成效率.

Fig.9 Reuse model of test cases for similar programs图9 相似程序间测试用例重用模型
3.1 适应度函数
遗传算法具有种群初始化、个体评价、选择运算、交叉运算、变异运算、进化终止条件判断等步骤.遗传算法的初始种群通常采用随机的方式生成,个体评价通过相应的适应度函数计算种群中各个个体的适应度值,选择运算就是将适应度较高的个体进行交叉变异操作,产生的个体组成下一代种群.重复选择进化的过程,直至终止条件满足,算法结束.
适应度函数是衡量种群个体优劣的标准[27],根据优胜劣汰的生存法则,通过淘汰生存能力低的个体实现种群的选择、进化.因此,适应度函数决定了种群的进化速度.合理的适应度函数能够全面提高种群个体的质量,有利于快速进化至最优解.适应度函数的设置是算法操作重要的一环.
分支距离法[28]和层接近度法[24]是两个设置个体适应度的经典方法.为了便于与主要参考文献作比较,实验选用了相同的函数(即分支距离法)设置个体的适应度.在程序的每个分支节点都插桩分支函数fi(插桩方式见图10),记录当前的测试用例与该分支的距离.当某分支被覆盖时,则将fi设为0,若该目标路径共含有m个分支节点,其总的适应度函数值FT的计算见公式(7):

由适应函数的计算公式可以推算出,测试用例的适应度跟分支节点覆盖率成正比例关系.特别地,当程序的每个分支节点均被覆盖时,该测试用例的适应度为1.
例如,对于数组inta[⋅]={3,4,2}的测试用例测试冒泡排序,参考图10 冒泡排序插桩后的伪代码.由于a[0]

Fig.10 Pseudo-code of bubble sorting program after being instrumented图10 冒泡排序插桩后的伪代码
3.2 测试用例生成算法
测试用例生成算法采用Java 语言编写,并在MyEclipse 2 010 中运行.计算机配置为Windows(Intel(R)Co re(TM)CPU i5-6500,3.20GHz,8.00GB RAM,64 位操作系统.算法的具体流程见算法2(传统方法).
算法2(传统方法).
输入:种群大小pop_size,个体individual,染色体长度chro_size,进化代数gen_size,交叉概率pc,变异概率pm;
输出:新种群.

算法2 是利用传统方法生成测试用例的遗传算法,采用随机方式初始化种群,轮盘赌法选择个体,以一定概率进行交叉与变异等操作,生成新的种群;判断新种群中是否有个体满足目标路径被覆盖,若其被覆盖,记录种群的进化代数;判断是否满足算法的终止条件,即种群是否达到最大进化代数,若满足则终止算法,若不满足则循环种群进化的过程.
算法3 将测试用例重用到待测程序的测试数据生成中,并作为对比实验检验测试用例的重用效果.该算法的初始种群采用算法2 中的初始种群,以避免初始种群不同对实验结果造成的影响.在种群交叉进化的遗传操作过程中,算法3 引入相似程序的测试用例作为个体交叉的对象,其他步骤与算法2 一致.
算法3(本文方法).
输入:种群大小pop_size,个体individual,染色体长度chro_size,进化代数gen_size,交叉概率pc,变异概率pm,引入的新个体shared_pop;
输出:新种群.

3.3 测试用例生成实验
选取第3 节讨论的两个相似程序(即冒泡排序和快速排序)为实验对象,提出两个问题探究本文判断程序相似性方法的合理性以及相似程序间测试用例重用的有效性,收集实验结果加以分析.具体问题如下:
问题1.本文设计的关键字流图比较程序相似性,相对于其他方法比较程序相似性有什么优点?如何检验方法的有效性?
最长公共子串等方法只比较代码的相同程度,而忽略了源代码略有差别、但功能结构却相同的情况.提出利用关键字流图比较程序的相似性,将比较全部源代码简化为比较代表代码语句功能结构的关键字.
最大公共子图距离能够判断待测程序的相似程度.而通过遗传算法将程序已有的测试用例应用到相似程序的种群进化的遗传操作中,检验测试用例的生成效率来判断程序相似性判断的有效性.即:通过用例的共享,待测程序的测试效率明显提高,可证明两个程序相似性判断是正确的.
问题2.相似程序之间用例的共享能够减少多少测试工作量,提高多少测试效率?
检测关键字流图判别程序有效性的实验,也能完成用例的重用.我们结合姜淑娟等人[20]的思想,在初始化种群的环节中引入相似程序中已有的测试数据,种群其他的个体通过向这些测试用例的学习加速种群进化,主要通过4 个评判标准来检验测试效率.评判标准见第3.3.2 节.
我们采用对比实验来解答上面两个问题.实验的不同点主要在于种群进化的方式不同.
•传统方法测试程序,初始种群随机生成,在初始种群中用轮盘赌法选择两个体进行遗传操作,轮盘赌法选中的两个个体以一定概率进行变异:若满足交叉条件,则两个个体进行交叉,进化成两个新个体.循环此操作,直到产生的新种群个体数与初始种群相同;
•而利用本文方法测试程序,初始种群使用传统方法生成的种群,以排除初始种群不同对实验结果造成的影响.引入相似程序已经生成的测试用例集,在种群进化的交叉部分,仍用轮盘赌法选择的个体与该用例集中的个体交叉,生成两个新的个体.其他操作与传统方法相同.
3.3.1 实验对象
第2 节表明:冒泡排序和快速排序两个程序的相似度为80%,判定为相似程序.实验对象仍选取此相似程序来探究相似程序间测试用例的重用问题.
实验假设快速排序的适应度较高的测试用例已知.研究测试用例的重用就是将已知的测试用例共享于与其相似的程序,故测试冒泡排序程序时,将引入快速排序已有的测试用例.测试用例有32 个二进制的字符,其中,4 个二进制字符代表一个十进制的阿拉伯数字,意味着每个测试用例代表着长度为8 的整数数组,整数大小在0到15 之间.测试用例的生成采用遗传算法,种群的个数为40.具体参数设置见表5.

Table 5 Para meters setting in genetic algorithms表5 遗传算法中的参数设置
3.3.2 评价标准
为了检验程序相似性检测方法的有效性及相似程序间测试用例重用的效果,并便于与丁蕊等人[28]提出的关键点路径法进行比较,同时也为了将遗传算法中随机因素对实验结果造成的影响降低到最小,我们将实验结果的4 个评价标准(即覆盖率、平均进化代数、执行时间和方差分析)的定义如下.
1)覆盖率:对程序运行100 次,记录在最大进化代数T=1000 内目标路径被覆盖的总次数,覆盖率为这100次中被覆盖次数的平均值,以百分比的形式表示;
2)平均进化代数:目标路径被覆盖的每个程序运行100 次,若该程序在最大进化代数T=1000 内覆盖到了目标路径,记录此时程序的进化代数;若在最大进化代数内目标路径没有被覆盖,记录最大进化代数,平均进化代数即为这些记录值的平均值;
3)执行时间:该评价指标记录两种方法(即传统方法与本文方法)的时间开销.传统方法生成测试用例的执行时间是测试数据或路径的选择与测试数据生成所消耗的时间总和;本文方法生成测试用例的时间除了测试数据或路径的选择与测试数据生成的时间以外,还包括判定程序相似性和测试用例重用花费的时间;
4)F值:在方差分析中,每个被测程序运行100 次,记录目标个体首次出现的进化代数,将传统方法与本文方法下获得的该数据作为两组样本来计算F统计量,即组间均方与组内均方的比值(见定义6 和定义7),该值能验证随机因素对实验结果造成的影响程度.
传统方法和本文方法均采用遗传算法测试同一程序,上面4 种评价标准作为衡量两种方法测试效率优劣的指标,检验本文方法是否能够有效地提高测试用例的生成效率,完成测试用例的重用.
3.3.3 实验结果分析
测试冒泡排序来验证相似程序间测试用例重用的有效性,传统方法中的测试种群通过轮盘赌法选择个体进行交叉变异产生下一代,而作为对比实验的本文方法在种群进化中将引入相似程序快速排序适应度较高的测试用例.为了减少随机因素的影响,两种实验均独立运行100 次,本文方法采用的初始种群为冒泡排序随机生成的初始种群.种群进化达到最大进化代数时算法终止,并记录100 次实验共有的总时间.
表6 表明:将快速排序适应度较高的测试用例运用到冒泡排序的测试中,测试用例的生成效率明显提高.其中:在传统方法的100 次独立实验中,在种群最大进化代数前只有15 次能够覆盖目标路径,覆盖率为15%,平均进化代数为890.9,所用的总时间为8.20s;采用本文方法的实验中的目标路径覆盖率为100%,平均进化代数为3.5,所用总时间为2.74s.其F值为160.36,经查表,组数为2,每组数据量在100 时,F界值为3.04,本文方法与传统方法的目标个体的进化代数作为两组数据所得F值远远大于F界值,意味着本文方法有效地改变了目标个体的平均进化代数,排除随机因素对实验造成的干扰.从实验结果可知,目标路径覆盖率、平均进化代数和时间3 个衡量指标都能证明相似程序间测试用例重用效果明显.

Table 6 Evaluation result of testing bubble sorting program using traditional method and our method表6 传统方法和本文方法测试冒泡排序的评判结果
为更加全面检测用例重用的效果,实验将改变种群大小,检验种群大小是否对实验结果造成较大影响.表7是不同种群大小下传统方法和本文方法在冒泡排序中的测试结果.

Table 7 Test results of bubble sorting program under different population sizes表7 不同种群大小下冒泡排序的测试结果
表7 的实验结果验证了不同种群下对比实验的覆盖率和平均进化代数.实验结果显示:随着种群规模的增大,传统方法中的目标路径的覆盖率有增大的趋势,平均进化代数随之减少,F值变化很小,但仍远大于F界值3.04.本文方法下的实验结果表明:3 种种群大小下的目标路径覆盖率都为100%,当种群的个体数量增加时,平均进化代数随之减少.该方法下的100 次独立实验中目标路径皆被覆盖,平均进化代数远低于传统方法,测试效率比传统方法明显要高.表8 是不同变异概率下测试冒泡排序的结果.

Table 8 Test results of bubble sorting program under different mutation probabilities表8 不同变异概率下冒泡排序的测试结果
由表8 的实验结果可知:变异概率的改变,给实验结果带来了很小的变化.变异概率由0.1 变化到0.3 时,冒泡排序中目标路径的覆盖率提高了7%,平均进化代数减少3.7,F值仍远大于F界值3.04.本文方法测试结果表明:在3 种变异概率下,其目标路径的覆盖率皆为100%.对比两个实验的实验结果可知:3 种变异概率下使用本文方法的测试效率远远高于传统方法,相似程序检测时用例重用效果较好.
表9 中的数据为本文方法和业界测试用例生成效率较高方法的各性能指标.为了检测相似程序间测试用例的重用效果,排除其他因素造成干扰,本实验遗传算法的各种参数和关键点路径法[20]中的参数保持一致,并且选择相同的目标路径.通过比较平均迭代次数可看出,本文方法实验中的种群能更早地覆盖目标路径.

Table 9 Performance comparison between our method and the key-point path method表9 本文方法与关键点路径法性能比较
3.4 进一步实验
为了证明面向关键字流图判断程序的相似性,并将测试用例重用到相似程序测试用例的生成中的效果较好,实验特别设计了基于控制流图、程序流程图及数据流图的方法来判断程序的相似性,并将相似度较高的程序作为实验对象检验测试用例的重用效果,以便于与我们基于关键字流图的方法作对比.实验按照与关键字流图相同的方法计算程序的相似性,例如:利用控制流图计算程序相似度时,首先将待测程序生成控制流图,接下来查找控制流图的最大公共子图.由于控制流图的节点中没有存储关键字等信息,故而查找公共节点时,考察有向边的数量与方向.若节点边的来向、去向和数量完全相同,则该节点属于公共子图中的节点.最后使用最大公共子图距离算法计算程序的相似度.详细过程可参考第2 节.表10 为待测程序的基本信息以及实验结果.

Table 10 Basic information and experimental results of the program to be tested表10 待测程序的基本信息与实验结果
表10 显示了3 组待测程序的名称、子函数个数、代码行数以及基于关键字流图、控制流图、程序流程图与数据流图方法下的程序相似度.从数据中能够看出:在3 组程序中,关键字流图下的程序相似度都低于70%,而其他3 种流图判定该程序的相似度时皆有较高的相似度(这样就超过了相似度设定的阈值,把本来不相似的程序也判定成相似了).实验结果显示了待测程序测试用例重用的效果(特别注意:表中的3 个指标值是根据控制流图、程序流程图以及数据流图得到的结果,并且它们的测试过程一样,因此数据一致).从表中的3 个评价指标能够看出:基于控制流图、程序流程图以及数据流图判定待测程序的相似度得到较高的值,其测试用例的重用在一定程度上确实降低了目标个体的平均进化代数,并且提高了其覆盖率,但均未达到100%.结合第3.3.3 节以及本文其他实验的结果,基于关键字流图相似程序间测试用例的重用的效果更好,其目标个体的覆盖率皆为100%,而目标个体的平均进化代数也较为更低.
控制流图、程序流程图和数据流图判定程序相似性时只比较了程序的结构而没有考察图中节点的功能,而基于关键字流图比较程序相似性时,综合比较了程序的结构与功能.因此,判定程序的相似度更准确,其测试用例具有更好的重用效果.
接下来,为了证明相似程序间测试数据是否可以相互引用,实验将测试冒泡排序已经生成的测试用例重用到快速排序的测试用例生成中.此外,进一步证明相似程序间测试用例重用的有效性.实验另外选取了两组典型基准程序和5 组工业程序作为实验对象,分别将传统算法和本文方法利用到这些程序的测试用例生成中.实验对象的基本信息见表11.

Table 11 Basic information of experimental subjects表11 实验对象的基本信息
第2 组基准程序的PG3 被广泛应用于验不同测试数据生成方法的有效性[2],PG4 是测试两个时间之间间隔多少天的函数,测试该函数与PG3 函数输入的参数类型皆为年月日的形式;PG5 函数验证输入的3 个数是否能组成三角形,PG6 函数在此基础上验证三角形是否是等腰或者等边三角形;工业程序PG7 和PG8 摘选自Github网站不同作者编写的实现计算器功能的程序;PG7 和PG8 实现的功能相同,但编写方式和使用的函数存在不同,故将PG7 和PG8 作为实验对象.
PG9 是五子棋游戏的赢棋算法,PG10 是在PG9 基础上做了一定的删减,去掉了悔棋功能.PG11 是通讯录系统个人信息的校验算法.PG12 增加了办公室电话的校验功能.本节对PG9 和PG11 两个工业程序做了不同维护类型的修改,用来验证本文方法是否适应于回归测试.回归测试是确认修改程序是否引入新的错误或导致其他代码产生错误[29].
统计数据表明:回归测试占了软件测试总预算的80%,软件维护阶段总费用50%以上.尽管回归测试的代价如此之高,但它却是不可或缺的测试[30,31].回归测试中有效地利用已经生成的测试数据,近几年得到普遍的关注.程序PG13 和PG15 来源于SIR 测试平台的西门子测试程序集[2],常作为程序测试的实验对象.PG14 和PG16是采用不同方法对PG13 和PG15 更新后的程序.该组程序能够验证相似程序间测试用例的重用效果,还能够验证本文方法是否适合程序的回归测试.
为了验证不相似程序之间测试用例的重用效果,实验还补充了3 组实验(见表11 的最后3 组),将不相似程序PG7,PG9 和PG11 的适应度较高的测试用例相互引用.对于程序功能规模差距较大的程序,其测试用例共用的可能性较小.其中,程序ABS_check1 的测试用例无法与程序Calculator1 和Gobang_algorithm1 的测试用例完成重用.而程序Calculator1 和Gobang_algorithm1 的测试用例规模相近,为了检验其重用效果,实验将Gobang_algorithm1 的测试用例处理成与Calculator1 的测试用例长度一致.
新增实验仍采用传统算法和本文方法进行对比,传统方法测试程序的各种参数设置与第3.3.1 节传统方法测试冒泡排序的参数一致.本文方法利用遗传算法生成测试用例的种群进化过程引用传统方法生成的测试用例,引用的个数为10 个.实验种群大小均为40 个,进化代数统一为1 000 代,详细参数设置见表12.

Table 12 Population size and maximum evolution times表12 种群规模及最大进化代数
表13 为传统遗传算法和本文方法测试程序的执行结果,可见,利用本文方法生成测试用例的效率更高.

Table 13 Results of testing under the traditional method and our method表13 传统方法和本文方法下程序测试的结果
下面分别从4 个评价标准对比测试用例的生成效率.
1)本文方法测试程序的目标路径覆盖率为100%(注意,PG17 对应的是不相似程序);而传统方法测试程序其目标路径覆盖率最高为91%,测试PG2 的路径覆盖率仅有30%;
2)平均迭代次数方面,本文方法测试程序的平均迭代次数均在40 代以内;传统方法除测试PG3 的实验以外,其他程序测试实验的平均迭代次数均在130 代以上,甚至超过600 代;
3)用时方面,利用本文方法测试程序的执行时间皆少于传统方法;
4)F值的大小表明随机因素对实验的影响.实验结果中的F值皆远大于F界值,则说明排除了随机因素对该实验的影响,证明了本文方法的有效性.
实验PG17 的结果表明:虽然不相似程序之间测试用例的重用在一定程度上提高了目标个体的进化速度,但目标路径覆盖率有所降低,还是不如相似程序间测试用例的重用效果.
由测试PG2 的实验结果可知,本文方法有效地提高了测试用例的生成效率.可证明测试冒泡排序可以引用快速排序已经生成的测试用例,测试快速排序也可以使用冒泡排序已经生成的测试用例.即,相似程序之间测试用例是通用的.观察PG9,PG12,PG13 以及PG15 的实验结果,本文方法的前3 个评判标准都优于传统方法,这说明本文方法运用到回归测试是可行的.相似程序间测试用例的重用测试程序是将已经生成的测试用例重用到相似程序测试用例的生成过程.在种群进化的过程中,种群个体不断地向引入的优秀个体学习,实验证明,本文方法能够提高测试效率.本文方法的测试用例重用能够取得这么好的结果,其主要原因包含两个方面.
1)利用遗传算法测试程序的过程中,引用了相似程序适应度较高的测试用例,引入的测试用例可以看作是待测程序适应度比较高的测试用例,甚至某些测试用例作为目标个体参与了种群的进化,因此在种群迭代1 000 次的情况下,种群进化出目标个体(覆盖率100%)是大概率事件;
2)容易陷入局部最优是遗传算法的弊端之一,实验发现:当种群进化到一定代数之后,种群基因种类较少,许多个体的基因相同或者非常相近,很大程度上阻碍了目标个体的生成;而外部个体的引入能够丰富种群基因,加速目标个体的进化.
3.5 问题回答
通过分析第3.3.3 节和第3.4 节的实验结果,对第3.3 节开头中提出的两个问题做如下回答.
回答问题1.本文设计的关键字流图比较程序相似性,相对于其他方法比较程序相似性有什么优点?如何来检验方法的有效性?
第2.5 节已经讨论过关键字流图比较程序相似性的优势,程序的相似程度可以通过最大公共子图距离进行判定.通过相似程序间测试用例的共享,实现数据用例的重用.可根据测试用例的重用效果证实关键字流图比较程序相似性方法的有效性.由表6 传统方法与本文方法测试程序的评判结果,传统方法的覆盖率为15%,平均进化代数为890.9 代;而作为引入相似程序测试用例的本文方法的目标路径覆盖率为100%,平均进化代数为3.5.表11 增加了两组基准程序和5 组工业程序,本文方法测试程序的目标路径覆盖率皆为100%(注意:PG17 除外,因其为不相似程序的测试),前3 项评判标准皆优于传统测试方法,第4 项评价指标能够排除实验的随机影响因素,从而证明了本文方法的有效性.由此可知:将相似程序(如,快速排序和冒泡排序)的测试用例相互引入到对方的测试中,测试效率显著提高.由此证实了本文程序相似性判定方法的有效性.
回答问题2.相似程序间用例的共享能够减少多少测试的工作量,提高多少测试效率?
从表7 和表8 可看出:在不同的种群规模和不同的变异概率下,本文方法目标路径的覆盖率都是100%,4 项评价指标充分证明了本文方法优于传统方法.结合表6 和表13,在所有程序的测试中,本文方法下的目标路径覆盖率均为100%(注意:PG17 除外,因其为不相似程序的测试),平均进化代数最高(即最差情况)也仅为36.13;而传统方法目标路径覆盖率最大才达到91%,平均进化代数除PG3 以外均超过130.可见,本文方法的测试效率显著高于传统方法.因为本文方法在进化遗传操作中引入了相似程序适应度较高的测试用例,种群在进化时随机地与这些个体进行交叉,其收敛速度明显高于传统方法.
3.6 有效性分析、存在的问题及其初步解决方案
影响实验效果的因素包括内部因素和外部因素.
1)内部因素主要是遗传算法本身对实验结果造成的影响.种群初始化采用随机生成的方法,轮盘赌法选择个体进行遗传操作也具有一定的随机性,为了降低算法随机性带来的影响,进行100 次独立的实验,实验结果取100 次重复实验的平均值;
2)外部因素包括程序本身对实验结果的影响.与实验选取的对象有关,本文方法测试不同组的程序,测试用例的重用效果略有差别.另外,实验发现:本文方法的实验结果受引入的测试用例的个数和适应度的影响,一定范围内引入的测试用例个数越多和采用较好适应度的测试用例往往能取到相对较好的结果,实验中引入的测试用例为传统方法生成的测试用例.
针对用例重用的问题,本文探究了相似程序间测试用例的重用,实验取得了较好的结果,证明了方法的有效性.然而,本文仍存在以下不足.
1)本文方法在判定规模较小程序的相似性时会具有一定的偶然性,其准确性有待进一步提高;
2)存在有些相似程序的用例长度不同的情况,测试数据无法共享,该条件有一定的局限性.
若判定为相似程序的测试用例长度不同,那么在遗传算法生成测试用例的过程中,种群个体不能与相似程序的测试用例进行交叉进化.若将引入个体的长度与进化种群个体的大小改成一致,则能够完成用例长度不同的程序间测试用例的重用.
本文就存在的不足设想如下初步解决方案.
1)若待测程序的测试用例长度小于相似程序测试用例的长度,减小相似程序测试用例的长度,使待测程序与相似程序的测试用例长度相同,根据关键字流图最大公共子图,删减不属于最大公共子图节点对应测试用例的部分;
2)若待测程序的测试用例长度大于相似程序测试用例的长度,增加相似程序测试用例的长度,使待测程序与相似程序的测试用例长度相同.找出相似程序关键字流图不存在关键字的节点所对应的位置,随机增添最大公共子图对应相似程序的测试数据,至待测程序与相似程序测试用例的长度相同.
4 总结及进一步研究
本文提出了一种面向关键字流图判断相似程序,并重用已知的测试用例来完成相似程序测试的方法.其主要贡献如下.
1)提出一种面向关键字流图的程序相似性的比较方法.通过构建的关键字流图求关键字流图最大公共子图,利用最大公共子图距离算法计算程序的相似度.该方法兼顾比较程序的序列和功能结构的相似性.通过关键字流图判定相似的程序,程序规模相近,程序功能结构相似;
2)提出一种基于相似程序程度间测试用例重用的方法.将程序已经生成的测试用例重用到相似程序的测试用例生成中,在遗传算法进化时,引入相似程序适应度较高的测试用例,种群个体以一定概率与引入的测试用例进行交叉变异,有利于加快种群的进化速度,提高测试用例的生成效率;
3)开发了一个判定程序相似性的插件,该插件根据本文所提出的方法对程序相似性进行判定,用户选择放在两个待测程序的文件(每个文件内只放待测程序的代码),点击测试按钮运行插件.执行结束返回两个程序的相似度,并根据设定的阈值判定它们是否相似.
在第3.6 节中分析了本文存在的不足,就测试待测程序需要输入测试数据受到个数限制而无法重用的问题,设想了初步的解决方案.在未来的工作中,进一步研究相似程序间测试用例重用的局限性,特别针对相似程序因测试数据数量受限而不能重用的问题,深入分析前面假设的可行性,以提高相似程序间测试用例重用的通用性与准确性.
