Apriori优化算法评测
2021-11-07杨丰源梁燕陶以政唐定勇李龚亮
杨丰源 梁燕 陶以政 唐定勇 李龚亮

摘要:Apriori算法是第一个被提出的关联规则挖掘算法,也是数据挖掘十大算法之一。从其诞生至今众多研究者致力于从不同角度改进Apriori算法,以提高挖掘关联规则的效率。为了深入比较各优化算法的特性,选取自顶向下、I-Apriori和T-Apriori等三种应用广泛的Apriori改进算法,详细介绍其优化的依据和方法。通过实验证明三种优化算法相较于经典Apriori算法取得了更优的挖掘效率,对比分析了三种算法优化效果和使用场景。
关键词:Apriori算法;优化;关联规则;自顶向下;数据挖掘
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2021)25-0044-04
Abstract:Apriori algorithm is the first association rule mining algorithm proposed and one of the top ten algorithms for data mining. Since its birth, many researchers have devoted themselves to improving the Apriori algorithm from different perspectives to improve the efficiency of mining association rules. Three widely used Apriori improved algorithms, top-down, I-Apriori and T-Apriori, are selected, and the basis and methods of their optimization are introduced in detail. Experiments show that the three optimization algorithms have achieved better mining efficiency than the classic Apriori algorithm. The optimization effects and usage scenarios of the three algorithms are compared and analyzed.
Key words: Apriori algorithm; optimization; association rule; top-down; data mining
关联规则挖掘理论与Apriori算法是由R.Agrawal等[1]在1994年同时提出的。经过20多年的发展,关联规则挖掘已经是数据挖掘一个重要的分支领域,大量研究人员将关联规则应用到了其他领域[2,8],或是利用关联规则改进协同过滤,精准推荐等算法[3]。
关联规则挖掘算法主要是从给定的事务数据集中找出形如A→B的关联规则。该过程又可以被分解为两个子过程:首先从事务数据集中找出所有满足阈值的频繁项目集;再利用频繁项目集生成关联规则。其中,耗费时间更多的往往是第一步从数据集中挖掘出频繁项集。因此,更多的研究关注于优化挖掘频繁项目集的过程,也提出了一些非常经典的算法,如完全不同于Apriori算法思想的FP-growth算法。但Apriori算法作为关联规则挖掘的第一个算法,仍然在关联规则挖掘领域具有非常重要的地位,被IEEE会议选为数据挖掘十大算法之一。尽管Apriori算法如此经典,依然有它的局限性,不断有Apriori算法的优化方法被提出[4-7]。本文对Apriori经典算法及该算法的几种优化算法详细描述,并通过实验对比分析其优化效果和适应场景。
1 Apriori算法
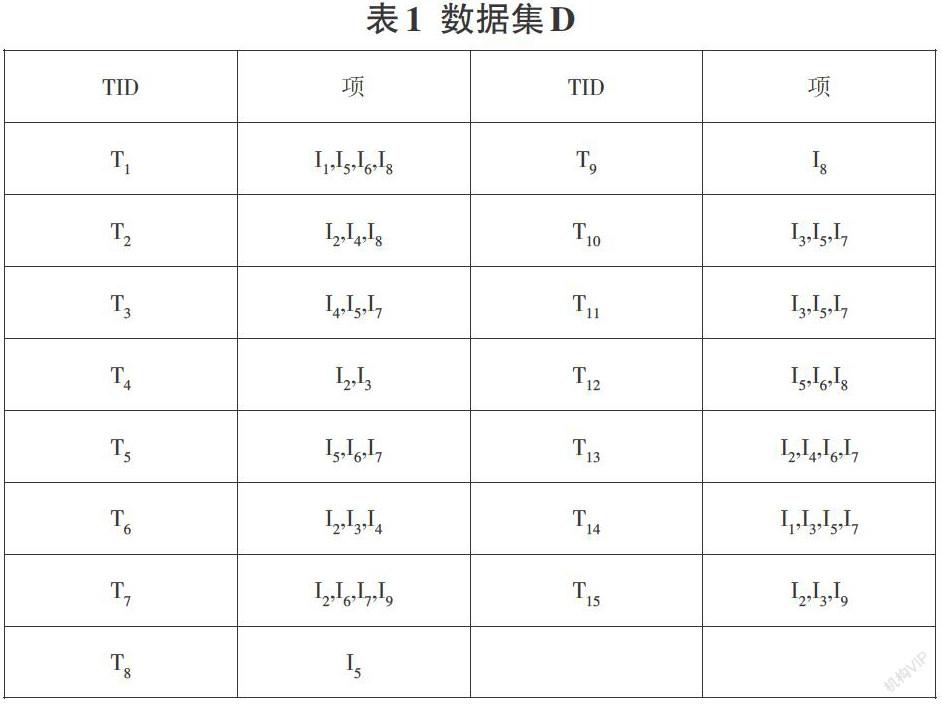
设项的全集为I=(I1,I2,… ,Im),数据集为D,其中的每个事务T有唯一的主键标识自己,记为TID。
1.1 相關概念
定义1 设A、B为项集,并且是I的非空子集,则形如A→B的式子就是一条关联规则。
对于每条关联规则,我们定义了如下的支持度和置信度来衡量关联的强度。
定义2 对于一条关联规则,它的支持度s是数据集的事务中包含所有项集的比例,如A→B的支持度就是D中事务包含A∪B的概率,即
support(A→B)=P(A∪B)=count(A∪B)/count(D)
置信度c则是D中包含A的事务同时包含B的比例P(B|A),即
confidence(A→B)=P(B|A)
= support(A∪B)/support(A) =count(A∪B)/count(A)
对支持度大于阈值min_sup且置信度大于阈值min_conf的关联规则,称为强关联规则。
包含k个项的集合被称为k-项集。满足最小支持度的项集被称为频繁项集。若一个频繁项集内部只包含k-项集,则该频繁项集被称为频繁k-项集或k-频繁项集。对于频繁项集,有以下几条性质。
性质1 任何频繁项集的非空子集是频繁项集, 非频繁项集的超集是非频繁项集。
性质2 如果频繁k-项集还能产生频繁k+1-项集, 则频繁k-项集中的项集的个数必大于k。显然,若频繁2-项集中只包含{(I1,I2)},则不可能形成频繁3-项集;若是包含{(I1,I2),(I2,I3)}则有可能生成频繁3-项集{(I1,I2,I3)}。
性质3 支持频繁项集Lk的任意一条事务至少支持Lk-1中的k个k-1项集。
