融合情感词典与上下文语言模型的文本情感分析
2021-11-05杨书新
杨书新,张 楠
(江西理工大学信息工程学院,江西赣州 341000)
0 引言
近年来,随着网络的高速发展,人们对社交媒体的使用程度逐渐提高,越来越多的人愿意在微博、Twitter、Facebook 等社交网络平台上表达自己对某件事或某样东西的态度或看法,这就产生了大量带有情感倾向的文本数据。通过对这些文本数据进行情感分析,可以更好地理解用户对产品的情感倾向或者对某热点事件的关注程度,由此情感分析技术应运而生。情感分析技术就是处理文本中带有情感极性的短语或句子的技术[1]。
利用机器识别句子情感极性并不容易,目前主要的做法有根据情感词典的规则判断方法和基于传统机器学习统计方法。基于词典的方法[2]主要是利用人工标注的词典对句子中的单词进行极性筛选,然后将这些情感分数累加求均值进行极性判断;但该方法只考虑单个词的语义信息,没有考虑上下文的语义信息。传统的基于机器学习的方法采用统计学方法,从大量的标注数据中选取特征,然后利用朴素贝叶斯、支持向量机(Support Vector Machine,SVM)、决策树等机器学习算法对文本进行情感分类[3-4]。该方法虽然在一定程度上提高了分类的准确率,分类速度也有提升,但是在面向大样本时表现不佳,在多分类任务中效果变差,并且对人工标注的需求极大。随着大数据时代的到来,深度学习方法在自然语言处理情感分析方面有了很多的应用。Wang 等[5]提出利用长短时记忆(Long Short-Term Memory,LSTM)递归网络对Twitter数据进行情绪预测,在否定测试集上的优异表现表明LSTM 模型具有非常好的捕获长序列信息特征的能力。之后,LSTM又被拓展为双向LSTM 以及门控循环单元(Gated Recurrent Unit,GRU)等变体模型。Kim[6]将图像领域的卷积神经网络(Convolutional Neural Network,CNN)首次引入到自然语言处理进行句子分类,发现CNN 可以捕捉文本的局部特征,极大地提高分类效果。
使用深度学习技术进行情感分析最大的难点就是怎么表示词向量。现有的方法大都利用one-hot、Word2Vec[7]、GloVe(Global Vectors for word representation)[8]等词嵌入工具生成词向量,但是上述词嵌入工具在针对例如“bug”等多义词时则会出现无法表示多义词向量的情况,根据训练语料主题的不同,有可能表示程序错误的意思,也有可能表示小昆虫的意思。如果使用词嵌入技术,向量无法同时表示这两种意思。为了解决这个问题,本文提出了一种基于上下文语言模型ELMo(Embedding from Language Model)的文本情感分析模型SLPELMo(Sentiment Lexicon Parallel-ELMo),该模型不仅能够表示单词自身的语义信息,还能表示单词的上下文信息,能根据不同的上下文产生不同的词向量,可以解决类似“bug”多义词的语义表达问题。虽然现有的工作已经可以针对上下文生成不同的词向量,但是在对文本进行特征提取时依旧存在特征提取不充分的问题,导致语义单一,所以本文模型在已有的工作基础上又融合了情感词典等外在信息,使语义单一问题得到了进一步的解决。为了提高训练速度,本文还使用字符卷积神经网络(char-CNN)初始化ELMo模型的输入层。
1 相关工作
1.1 基于情感词典的分类方法
情感词典能够体现文本的非结构化特征,它是文本情感分析所需的重要资源,研究者们对此给予了极大的关注。
Paltoglou 等[9]在更常见的非正式文本例如在线讨论以及Twitter等社交网络上,提出了一种无监督的、基于词汇的方法评估文本中包含的情感极性并预测,实验准确率可达86.5%;Qiu 等[10]等提出了一种基于规则的方法,提取与负面情绪相关的观点句的主题词来作为广告的关键词,在automotiveforums.com 论坛语料库的实验中,准确率可达55%;Jiang 等[11]在文献[10]的基础上对情感词典特征进行了扩充,在Twitter语料的实验中,分类准确率可达85.6%。随着网上一些新词汇的大量出现,基于情感词典的方法在这些新的语料上表现不佳,甚至出现错误,并且灵活度不高。对此研究人员开展了基于机器学习的情感分析方法的研究。
1.2 基于机器学习的分类方法
传统的机器学习一般是基于统计学的分类方法。Pang等[12]通过比较SVM、最大熵算法和朴素贝叶斯算法在一元特征、二元特征、位置等多种特征下的分类效果,在电影影评数据上,发现SVM和一元特征组合的效果最好,可达82.9%;之后,Tang等[13]提出了一种情感特定词嵌入的方法,该方法将特定情感词与手工选择的表情符号和语义词典结合,然后利用SVM进行情感分类,在Twitter语料上准确率可达87.6%。
自Hinton 等[14]提出了深度学习后,深度学习在计算机视觉领域取得了巨大的成就,大量自然语言处理领域的学者尝试引入深度学习的方法,研究发现深度学习方法可以表征文本中更加深层的语义信息,而且基于此的分类方法准确率得到了大幅度的提高。在Bengio等[15]提出了神经网络语言模型后,自然语言处理中的预训练技术开始逐渐发展起来。Peters等[16]在上述研究的基础上,提出了一种基于LSTM 的双层双向预训练语言模型ELMo,该模型通过两层隐向量以及一层词嵌入向量的线性组合可以动态地表示词嵌入向量。赵亚欧等[17]提出了一种融合ELMo 与多尺度卷积神经网络的情感分析模型,在ELMo 的基础上使用多尺度卷积网络对词向量特征进行二次提取,实验结果表明该方法有效提升了分类效果。
2 融合情感词典与上下文语言模型的情感分类模型
为了实现文本中情感单词的筛选、解决情感分析中语义单一的问题,本文提出了融合情感词典与上下文语言模型的情感分析模型SLP-ELMo。该模型主要由4 部分组成,结构如图1所示。

图1 SLP-ELMo模型结构Fig.1 Architecture of SLP-ELMo model
本文模型的第1 部分是词嵌入层,主要功能是采用情感词典对语料中带有情感分数的单词和短语进行筛选处理,并将其进行向量化表示。本文使用的词典是情感词典SentiWordNet 3.0,包含有117 659 条记录,每条词条有6 列信息:第1 列POS(Part Of Speech)表示词性,第2 列ID 表示词条编码,第3 列PosScore 表示正向情感值,第4 列NegScore 表示负向情感值,第5 列SynsetTerms 表示同义词,第6 列Gloss 表示该词注释。SentiWordNet 3.0的部分内容如图2所示。

图2 情感词典Fig.2 SentiWordNet
词嵌入层工作的具体步骤如下:首先对语料进行清洗,去除句子中的链接地址(Uniform Resource Locator,URL)、表情符号等;然后将文本字母小写化。由于在SentiWordNet 中单词或短语对应不同的词性具有不同的情感值,因此在与词典匹配前需要利用Python 的自然语言工具包(Natural Language ToolKit,NLTK)对单词进行词性标注;最后再利用情感词典对语料进行筛选,筛选出句子中带有情感分数的单词和短语。筛选出单词和词组之后,利用Word2Vec 模型训练,得到词嵌入向量。具体做法是对于第k个词wk,首先获取其one-hot 编码hotk,one-hot 编码维度为整个词典的大小Nchar,然后与维度为Nchar×Dchar的嵌入矩阵Mw2v相乘,得到该词维度为Dchar的紧致编码Ck,即词嵌入向量,计算如式(1)所示:
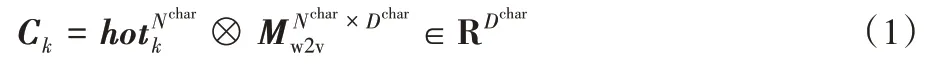
SLP-ELMo 模型第2 部分是语义学习层。该层将情感词典筛选出的单词wk输入到char-CNN 进行卷积操作,再利用ELMo训练,得到词嵌入向量,再将词嵌入向量通过双向LSTM模型训练成带有上下文语义信息的ELMo 词向量ELMok。ELMo模型结构如图3所示。
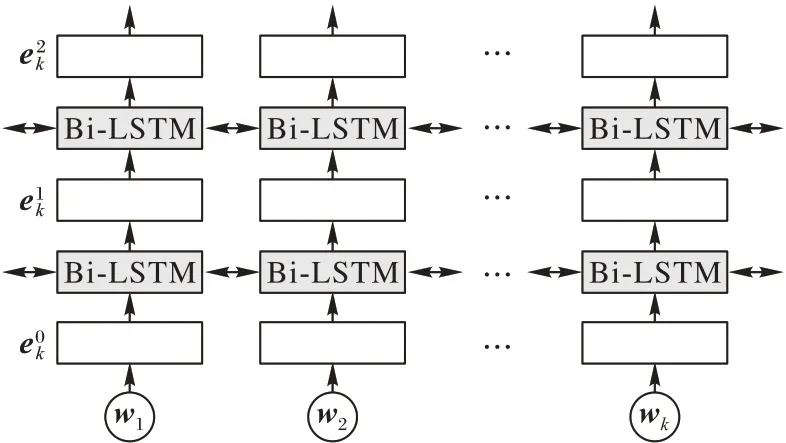
图3 ELMo模型结构Fig.3 Architecture of ELMo model
ELMo 模型与神经网络语言模型(Neural Network Language Model,NNLM)思想类似,也是通过构造语言模型来预测下一个词,从而获取词向量。一个含有n个词的句子S={w1,w2,…,wi,…,wn},第k个词wk出现的概率P(wk)与前面k-1 个词(w1,w2,…,wk-1)有关,因此整个句子出现的概率P(w1,w2,…,wk-1)计算如式(2)所示:

若使用LSTM 来建模语言模型,则单词wk对应LSTM 的隐层状态hk。如果LSTM 有L层Cell,则单词wk共有L个隐层状态。将最后一层输入softmax 得到输出ok,ok为语言模型中单词wk出现的概率P(wk|w1,w2,…,wk-1)。
上一步是对前向模型建模,但一个单词wk不仅可以顺序预测,也可以逆向预测,因此,对后向模型建模。将(wn,wn-1,…,wk+1)依次输入后向模型,得到隐层状态。同理,得到输出ok',ok'为后向语言模型中单词wk出现的概率
ELMo 采用L=2的BiLSTM(Bi-directional LSTM)结构,另外在两层Cell 之间还有一层残差连接,作用是把第1 层LSTM的输入加到LSTM的输出上,目的是保持网络训练的稳定。
最后每个单词可以生成3个Embedding,分别是单词wk对应的词嵌入层向量、第1层LSTM的隐层输出、第2层LSTM 的隐层输出,最后将3个Embedding 线性组合,获得wk的ELMo向量表示,其计算如式(3)所示:
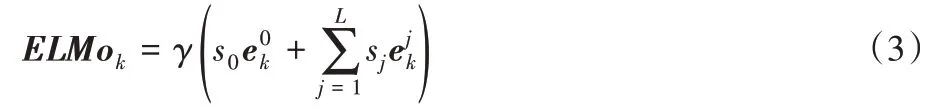
其中:γ是控制ELMo向量组合大小的参数;s是softmax层间归一化的参数。
因为BiLSTM 有两层,深层的Embedding 会带有更多的语义信息,因此本文只选取ELMok词向量的最后一层作为情感分类的基向量,并通过在最后1层添加注意力机制的方法调整权重,以达到更好训练词向量的目的,以此作为新的ELMo 词向量outputatt。具体做法是对于第i个词wi,将BiLSTM 最后1 层该词的输出(i=1,2,…,n)通过tanh函数得到向量,再对调用softmax函数得到注意力权重,计算式如式(4)、(5)所示:

其中:αi表示第i个词对于当前文本的重要程度;Watt和batt为注意力权重矩阵和偏置,可通过训练语料自动学习。最后,通过加权平均方法得到新的ELMo词向量outputatt,如式(6):

SLP-ELMo 模型第3 部分是特征融合层,通过将新的ELMo 词向量outputatt与词嵌入向量Ck并行融合,作为分类层的输入,计算式如式(7):

SLP-ELMo 模型第4 部分是分类层,该层通过接收上述得到的融合特征inputclassify,经过softmax 函数在分类层输出正向或负向分类概率Pc,其计算式如式(8)、(9):

其中:Wclassify、bclassify分别为权重矩阵和偏置向量;C为分类类别数。
最后模型使用整个句子中所有单词wk对应概率乘积的最大似然作为损失函数,其计算式如式(10)所示:
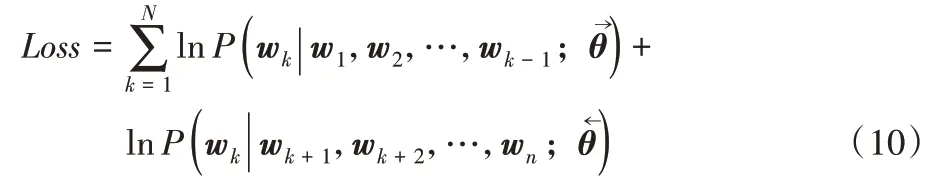
3 实验与结果分析
3.1 数据集
本文的实验在两个数据集上进行:1)IMDB 影评数据集,平均词数为268,属于长文本数据集;2)斯坦福影评情感树库(Stanford Sentiment Treebank,SST-2)数据集,其中SST 数据集数据标签为5 类,通过去除其中的中立评论数据,将数据集划分为2 分类数据集,平均词数为19,属于短文本数据集。IMDB和SST-2的训练集和测试集规模信息如表1所示。

表1 实验数据集Tab.1 Datasets for experiments
3.2 评价标准
本实验采用准确率(Accuracy,Acc)、召回率(Recall,R)、F1 值(F1-measure)、查准率(Precision,P)作为实验的评价标准对模型进行评价,其中,召回率R 是针对原来的样本而言的,它表示样本中的正例有多少被预测正确;查准率是针对预测结果而言的,它表示预测为正的样本有多少是真正的正样本;F1 分数则是P和R指标的调和平均值,同时考虑两者,使两者都达到最高,取得平衡。使用这些指标可以全面评估模型的效果。准确率Acc、召回率R、查准率P和F1 值分别定义为式(11)、(12)、(13)、(14):

其中:TP(True Positive)、TN(True Negative)、FP(False Positive)、FN(False Negative)的含义如表2所示。

表2 分类结果混淆矩阵Tab.2 Confusion matrix of classification results
3.3 实验参数
模型第一部分训练词嵌入向量时采用Word2Vec 工具,Word2Vec词嵌入的维度、LSTM 隐层维度、ELMo 的输出维度、char-CNN 模型dropout 率、学习率、IMDB 语料的批尺寸、SST-2语料的批尺寸、模型的正则化等参数设置如表3所示。

表3 所提模型参数设置Tab.3 Parameter setting of the proposed model
3.4 对比模型
为了验证本文提出的情感分析模型SLP-ELMo 的有效性,将其与CNN 模型、LSTM 模型、Bi-LSTM 模型以及融合了注意力机制与LSTM的CWPAT-Bi-LSTM模型、W2V-Att-LSTM模型分别在IMDB和SST-2两个数据集上进行实验对比。
1)CNN模型:原始卷积网络模型,利用不同的卷积核对语料进行卷积,提取特征,最后输入一个池化层进行分类。
2)LSTM 模型:单向的LSTM 网络模型,只能顺序从前往后对语料进行特征提取,使用最后一个隐层向量更新参数。
3)Bi-LSTM 模型:基于LSTM 网络的双向模型,能对单词前面和后面的词同时进行特征提取,融合了单词过去和未来的信息。
4)赵富等[18]提出的融合词性的双注意力机制的双向长短期记忆网络模型(Character,Word and Part of-speech ATtention model based on Bidirectional Long Short-Term Memory,CWPAT-Bi-LSTM),该模型融合了字、词和词性的深层语义特征,并用注意力机制加权有情感信息的部分进行情感分析。
5)胡荣磊等[19]提出的基于循环神经网络和注意力机制的模型(Word2Vec-Attention Long Short-Term Memory,W2V-Att-LSTM),其方法是将长短时记忆网络模型和前馈注意力模型相结合,利用Word2Vec 工具训练词向量作为LSTM 的输入,之后再利用注意力机制对输出特征进行进一步的特征提取,最后输入分类器进行情感分析。
3.5 结果分析
各个模型在IMDB 数据集上的实验结果如表4 所示。从表4可以看出,在IMDB 数据集上,LSTM 模型及其拓展模型的效果均优于CNN 模型,添加了注意力机制的模型整体效果优于单一模型的分类效果。Bi-LSTM 模型由于增加了后向传播单元,可以同时考虑上下文信息,所以分类效果较LSTM 模型更好。CWPAT-Bi-LSTM 模型和W2V-Att-LSTM 模型都基于Bi-LSTM 和注意力机制,但后者因为使用了Word2Vec 工具对语料进行了预训练,相较单纯融合字词和词性来说,Word2Vec 词向量对特征的表征效果更好。本文提出的SLPELMo 融合模型在LSTM 和注意力机制的基础上又在输入层进行了字符卷积,增加了模型的通用性,在分类层融合了Word2Vec 词向量,充分发挥了融合方法的优势。从整体来看,在长文本数据集上,SLP-ELMo 模型在准确率、召回率、F1值等性能指标方面都优于其他对比模型。
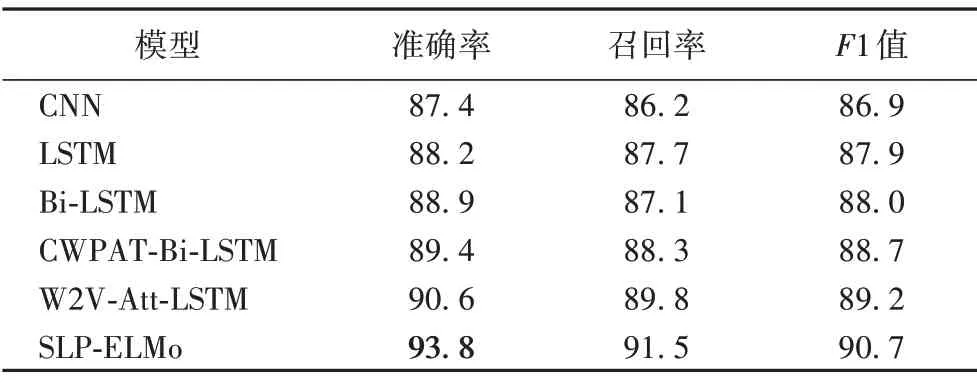
表4 IMDB数据集上的实验结果 单位:%Tab.4 Experimental results on IMDB dataset unit:%
各个模型在SST-2 数据集上的实验结果如表5 所示。从表5 可以看出,在SST-2 数据集上,CNN 模型却比LSTM 模型分类效果更好,这表明CNN 模型在短文本(SST-2)上对文本信息特征的提取要比LSTM 模型好。结合表4的结果,可以发现CNN 模型提取局部特征的能力更强,LSTM 模型提取单词上下文的能力更突出。对比表4 可以看出,虽然数据集的语料长短不同,但本文提出的SLP-ELMo 模型融合了CNN 和LSTM 的优点,在两个数据集上各个性能指标方面都表现优异,表明本文模型具有很好的泛化能力。
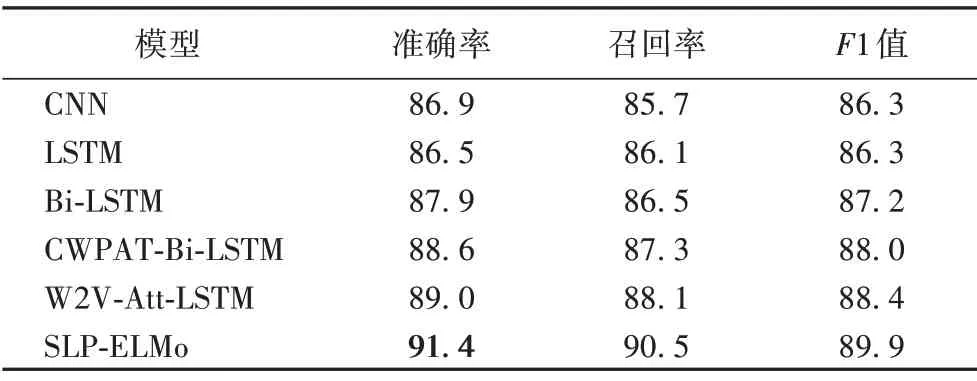
表5 SST-2数据集上的实验结果 单位:%Tab.5 Experimental results on SST-2 dataset unit:%
自然语言处理中情感分析的实验对比一般用准确率的值来衡量实验效果,结合表4 和表5 中数据可以看出,本文提出的模型在不同的数据集上准确率都有明显的优势。在长文本特征提取上,由于Bi-LSTM 记忆了前向与后向的语义信息,因此模型效果非常显著。本文提出的基于Bi-LSTM 的SLPELMo 模型比目前分类效果较好W2V-Att-LSTM 准确率在IMDB 数据集上提升了3.2 个百分点,在SST-2 数据集上比W2V-Att-LSTM模型准确率提升了2.4个百分点。
实验还从Loss 值与训练轮次的角度进行对比,比较了原始ELMo 模型与本文模型的Loss 值与训练轮数之间的关系。实验分别在IMDB 数据集和SST-2数据集上进行。根据每150轮的损失值记分,然后输出打印,实验一共3 150 轮,记分21次。对比结果如图4和图5所示。
从图4 可以看出,本文模型在前600 轮以内收敛快于ELMo 模型,模型的准确率更高;600 轮以后两个模型逐渐趋于平稳,本文模型Loss值较ELMo模型更低,误差更小。
从图5 可以看出,两模型的误差线要小于图4 中,表明在短文本数据集上两模型的损失值更接近,也说明两模型更适合于较长文本。
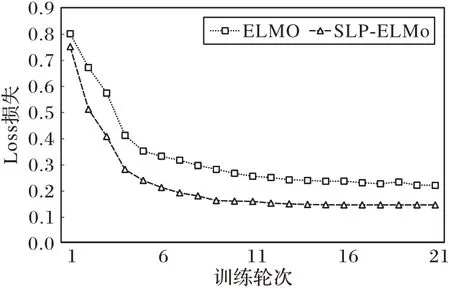
图4 IMDB数据集上的Loss值训练曲线Fig.4 Training curve of Loss value on IMDB dataset

图5 SST-2数据集上的Loss值训练曲线Fig.5 Training curve of Loss value on SST-2 dataset
对比图4 和图5 可以看出,本文模型都比原始ELMo 模型Loss值更低,这表明本文模型不仅在准确率上有更好的表现,在收敛速度上也有优势。
另外,本文研究的问题是二分类问题,所对应的损失函数为0-1 损失,所以Loss 值本身映射的是分类准确度。对比图4~5,在SST-2 数据集上的Loss 值整体高于IMDB 数据集上的Loss值,这表明长文本中所带的特征要多于短文本,因此在训练时模型可以从长文本中学习到更多的特征,分类准确率更高。
4 结语
本文提出了一种融合情感词典与上下文语言模型的情感分析模型SLP-ELMo,可以根据上下文动态调整单词的词嵌入,解决了词嵌入表示语义单一的问题。此外,该模型在词嵌入层使用了字符卷积,使词向量变为字符级向量,能有效避免产生未登录词(Out Of Vocabulary,OOV)的问题。在长短文本数据集上分别进行实验,实验结果表明本文模型有很好的通用性以及收敛性。
本文模型在特征提取能力上有所欠缺,而且ELMo 模型是预训练模型,需要大量的语料才能训练出好的模型,否则在训练集以及测试集上就会出现过拟合的问题。而Transformer模型基于CBOW 的思想提出了Masked 语言模型很好地解决了这个问题,基于自注意力机制的Transformer 模型在自然语言处理领域打破了多个任务的最新记录。下一步将尝试把Transformer 模型与Bi-LSTM 模型融合,发挥各自模型的优势,研究分类效果更好的模型。
