基于改进Mask R-CNN的牙齿识别与分割
2021-11-04赵庶旭罗庆王小龙
赵庶旭,罗庆,王小龙
兰州交通大学电子与信息工程学院,甘肃兰州730070
前言
牙病一直是困扰我国居民的一大问题。截止到2018年,我国仅有16.73 万个口腔医生,每百万人牙医数量只有100多位,相比于发达国家的每百万人牙医数量高达500~1 000 位,中国牙科医生十分紧缺[1-2]。而在欧美等发达国家,尽管其牙科医生数量多于中国且私人牙科诊所普遍,但是其治疗成本过高。面对全球医疗资源短缺的现状以及实际诊疗的需要,利用计算机图形图像处理技术构建智能诊断系统逐渐成为研究热点[3]。
牙齿全景X光片是诊断牙病的常用辅助工具,使用计算机技术实现对牙齿全景X光片中牙齿形状、位置、类别等基础信息的提取能够大量减少医生的工作量。在目前的牙科X 线图像自动化分析研究中[4],主要是针对牙齿、病灶等目标的分割与识别[5-8]。如Hasan 等[9]利用梯度矢量流(Gradient Vector Flow,GVF)Snake 从全景牙科X 线图像中自动分割颌骨。Choi 等[10]采用变分法和卷积神经网络结合的方法,检测牙周受损牙。Patil 等[11]提出利用主成分分析(Principal Component Analysis, PCA)降维和神经网络的龋齿检测方法,用于牙科X射线图像的分析。其中Jader 等[6]提出使用Mask R-CNN 用于分割牙齿,详细讨论了牙齿X 光片中完整与缺牙情况的检测分割效果,但是其分割精度不高且将所有的牙齿都归为一类,忽略了不同牙齿(如门牙与后槽牙)之间的语义差别,无法做到各个牙位牙齿之间的区分。但在实际诊断过程中,对牙齿进行编号是牙病诊断过程中的必要步骤,口腔医生往往会根据病历上牙齿部位的记录来快速了解牙齿情况,同时也方便医生为之后的诊疗工作做病历记录。Chen等[12]首次提出使用Faster R-CNN 来检测和编号牙科图像中的牙齿,为牙齿全景X 光片的分析提供了新的方向,但是其只提取了牙齿的位置与类别信息,忽略了牙齿形状及语义信息的重要性。
考虑到这些牙齿分割和牙齿识别分类的深度学习方法只能单一的提取牙齿的语义信息或者类别信息,当需要更全面的牙齿信息时,只能通过多次提取,这在实际应用过程中需要耗费大量的时间与精力,缺乏高效性。而在神经网络学习过程中对于牙齿的分割和识别有大量的特征参数可以共享,将这两个任务融合,可以实现对牙齿信息的融合提取。因此本文利用改进的Mask R-CNN 同时完成对牙齿全景X光片的牙齿分割与牙齿分类,并通过实验进行验证,充分证明Mask R-CNN 应用于牙齿分割和牙齿检测的有效性。
1 Mask R-CNN算法原理
Mask R-CNN 是由He等[13]提出的一种实例分割架构。实例分割是指从图像中用目标检测方法框出不同实例,再用语义分割方法在不同实例区域内进行逐像素标记。Mask R-CNN 在目标检测网络Faster R-CNN[14]基础上增加了一条分割分支使其能对每个检测出的目标进行语义分割,即实现所谓的实例分割。其网络结构图如图1所示。

图1 Mask R-CNN网络结构图Fig.1 Mask R-CNN network architecture
Mask R-CNN 的网络结构主要分为以下4 个阶段。阶段1:残差网络(ResNet)和特征金字塔网络(Feature Pyramid Networks, FPN)作为特征提取器,对输入的图像进行特征提取。阶段2:得到的特征图通过区域生成网络(Region Proposal Network, RPN)提取可能存在的目标区域(Region of Interest, ROI)。阶段3:这些ROI 输入到ROI Align,并通过双线性插值的方式被映射成固定维数的特征向量。阶段4:映射后的特征分别输入3条分支,通过全连接层进行分类和包围框回归,通过全卷积层进行语义分割。
1.1 RPN
RPN[14]输入特征提取网络的特征图,输出目标候选区域矩形框集合。RPN 预先在原图上生成若干个边界框,并判断其中最有可能包含目标的边界框作为候选区域输出。其原理如图2所示,核心为锚点(anchor)机制。首先用3×3 的滑窗在FPN 输出的特征图上进行遍历,当前位置的滑窗中心在原始图像像素空间的映射点即为锚点,以此锚点为中心,设定不同尺寸(128×128、256×256、512×512)和长宽比例(1:1、1:2、2:1)的锚点框共9 种,根据已知的锚点位置和锚点框的尺寸,便可以得到原始图像中对应区域的尺寸及坐标,这个区域就是预设的候选框。将卷积得到的256 维特征向量经过两个全连接层(cls layer、reg layer)分支进行分类和边框回归,再利用非极大值抑制得到最有可能包含目标的区域。

图2 RPN原理图Fig.2 Schematic diagram of region proposal network
1.2 ROI Align
在Faster R-CNN 中ROI Pooling两次量化会造成区域不匹配问题,为此Mask R-CNN提出了RoI Align的方法来取代ROI Pooling[13]。ROI Align 取消了量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。其原理如图3所示,图中虚线框为5×5 的特征图,实线框为映射到特征图上的ROI 区域。要对该ROI 区域做2×2 的池化操作,首先把该ROI 区域划分4 个2×2 的区域,然后在每个小区域中选择4 个采样点和距离该采样点最近的4 个特征点的像素值(图中黑色小方格的4 个角点1、2、3、4);通过双线性插值的方法得到每个采样点的像素值;最后计算每个小区的池化值,生成ROI区域的2×2大小的特征图。
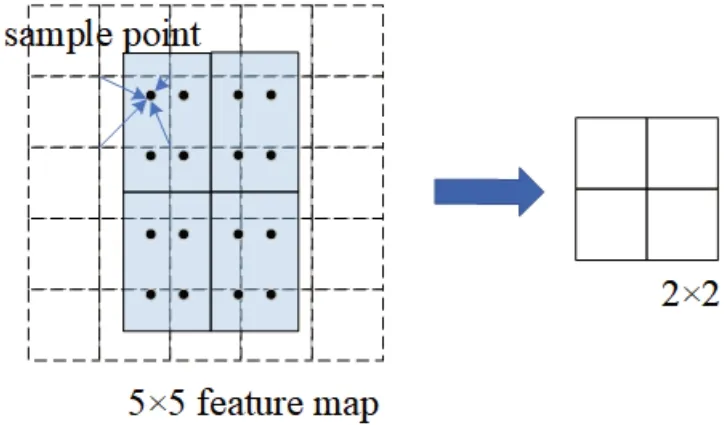
图3 ROI Align原理图Fig.3 Schematic diagram of ROI Align
1.3 Mask分支
对于Mask分支,是Mask R-CNN在Faster R-CNN基础上增加的分支用于生成检测目标的掩码[13]。Mask分支的输入来自于经过ROI Align处理后的ROI。对于每一个ROI,Mask分支有K个m×m维度的输出,对这些大小为m×m的Mask进行编码,得到该ROIK个类别的概率值,由此实现实例分割的目的。如图4所示,Mask分支对其进行4次卷积和1次反卷积操作,并使用了像素级sigmoid激活函数,最后得到K×m×m维度的输出,其中K为检测目标的类别数目,m为特征图的尺寸。由于Mask分支根据分类分支所预测的类别标签来选择输出的掩码,其允许网络为每一类生成一个掩码,不同类之间不存在竞争,这使得分类和掩码生成分解开来,可以提高实例分割的效果。
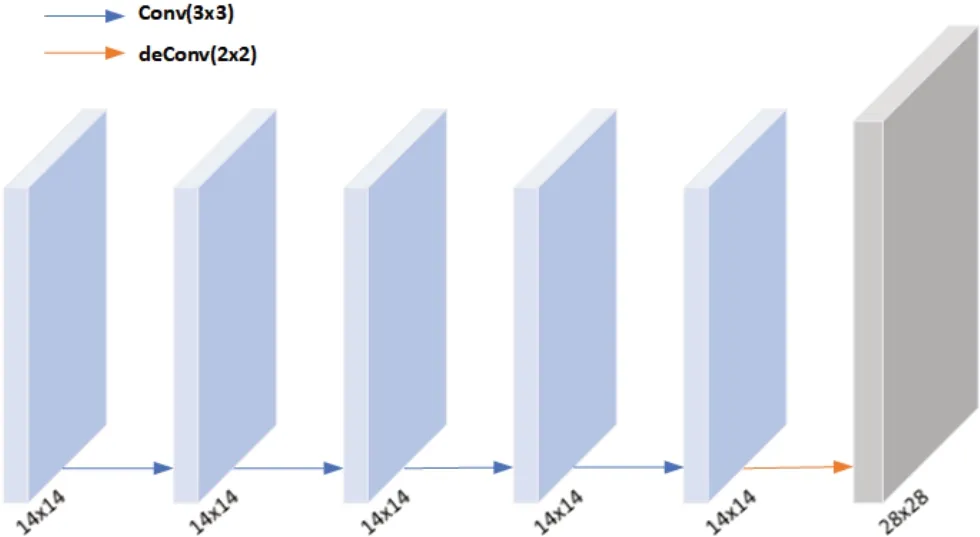
图4 Mask分支Fig.4 Mask branch
然而Mask R-CNN 作为两阶段检测模型,实行先检测后分割策略,其分割效果受检测结果的制约。对于RPN 提取出的ROI 特征图,Mask 分支采用全卷积操作提取语义信息,这对于局部语义信息有较好的敏感度,但是忽略了上下文信息。
2 基于改进Mask R-CNN的牙齿识别与分割
在医疗图像的临床使用中,既需要整副图的全局信息也需要某些特点区域的局部信息,对医学图像各个尺度特征信息的融合,可以一定程度上增大信息量。U-net模型在医学图像分割上取得了优越的效果[15],其通过跳跃连接更好的融合了上下文语义信息。由此提出利用跳跃连接结构融入多尺度注意力信息对Mask R-CNN 分割分支进行改进,弥补Mask R-CNN在掩码分支上所缺乏的深层特征。
2.1 跳跃连接
跳跃连接(Skip-connection)最早由Ronneberger等[16]提出,用于语义分割的全卷积网络(Fully Convolution Network,FCN)中。之后Shelhamer 等[15]在跳跃连接基础上,提出了用于医学图像语义分割的U-net 架构。FCN 和U-net 架构的 不同是,FCN 使用求和运算进行特征融合,而U-net 将特征进行拼接。图5为密集跳跃连接结构图。

图5 跳跃连接结构Fig.5 Skip-connection structure
文中跳跃连接的特征融合方式是特征图在通道维度上的拼接,计算公式如式(1)所示:

其中,W(h,w,a)和V(h,w,b)分别来自不同层的特征图,F(h,w,c)为拼接之后的特征图,h和w为特征图的长宽,a、b及c均为特征图的通道数。这种跳跃连接结构结合了低级特征图中的特征,避免了直接在高级特征图上进行学习,使得最终得到的特征图既包含了高层特征,又包含了很多低层特征,实现了多尺度下特征的融合。
2.2 SE模块
虽然跳跃连接更好的融合了上下文语义信息,有效地提取出更多牙齿细节信息,但低层特征中亮度不均衡、对比度较低仍会对牙齿的细粒度分割造成干扰。通过引入注意力机制SE(Squeeze and Excitation)模块[17]来捕获高级语义信息,根据特征图像的值对各特征通道进行加权,提升重要特征的权重,降低不重要特征的权重,从而提升特征提取的效果,提高模型的分割精度。SE 模块的核心是压缩(Squeeze)和激励(Excitation),结构示意图如图6所示。

图6 SE模块Fig.6 Squeeze and excitation module
在图6中,首先特征X经过卷积将其通道数由C'变为C,将特征图U传递给压缩操作。压缩操作使用全局平均池化将每个特征通道都压缩成一个实数,将感受野扩展到全局范围。压缩计算过程如式(2)所示:

其中,uc为通过卷积后得到的特征图,c为U的通道数,H×W为U的空间维度。接着,激励操作捕获压缩后的实数列信息,使用两个全连接层增加模块的非线性。先经过第一个全连接层降维,再通过整流线性单元ReLU 激活,然后经过第二个全连接层升维,最后经过sigmoid激活函数,整个过程如下:

其中,δ为非线性激活函数ReLU,W1和W2分别为两个全连接层的参数,σ为sigmoid 函数。最后对原特征进行加权,用原特征逐通道乘以激励操作获得的通道重要度系数,得到具有注意力信息的特征:

2.3 网络结构
改进的Mask 分支利用卷积层进行下采样编码,反卷积层进行上采样。其中上采样的计算过程如式(5)所示:
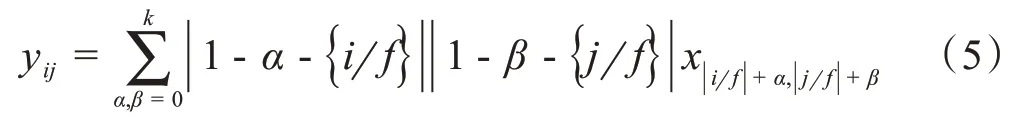
其中,k为反卷积核大小,f为上采样因子即为步长。在上采样的同时通过跳跃连接与SE模块将不同尺度的浅层高分辨率特征输入到反卷积层。改进的Mask分支网络结构如图7所示。
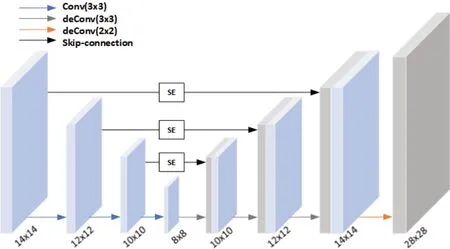
图7 改进后的Mask分支Fig.7 Improved Mask branch
其中1、2、3 层均为卷积层,卷积核大小为3,步长为1。每次卷积之后都跟随了批归一化(BN)层以及ReLU 激活函数。4、5、6、7层为反卷积层,其中4、5、6层的卷积核大小为3,步长为1,第7 层的卷积核大小为2,步长为2。输入14×14 的特征图,经过3 个卷积层得到8×8 的特征图,经过反卷积层得到28×28 的特征图。对于反卷积层的输入,编码器网络和解码器网络对称的层提供跳跃连接,将编码器网络每一层卷积操作的结果经过SE模块之后和解码器网络上采样的结果进行拼接。最后通过sigmoid层生成二进制的分割掩码。这样充分利用了不同尺度特征图所包含的信息,提高特征利用率,使得分割分支在更大的感受野上获取更丰富的细节特征,提高了对目标的细粒度分割效果。
3 实验内容
3.1 实验数据
实验数据使用了包含400 张牙齿全景X 光片的数据集,该数据来源于临床诊断,并经过脱敏处理,数据的使用获得患者同意。其中每张图片的尺寸为1 024×2 161,其标签数据由牙科医生利用VIA 工具所标注存于CSV 文件中,经过数据清洗整理后笔者将其格式转换为Mask R-CNN模型需要的JSON格式标签数据,该JSON 文件中包含各颗牙齿的轮廓坐标、世界口腔联盟(Federation Dentaire Internationale,FDI)牙位编号等信息。
3.2 损失函数设计
本文采用多任务加权损失函数,通过学习不断减小损失函数的值,直到获得全局最优解。损失函数的公式如式(6)所示:

其中,Lcls为分类误差,Lbox为包围框误差,Lmask为分割误差。原始的损失函数中,分类、包围框回归及分割这3条分支并行处理,具有相同的权重[13]。然而不同的任务具有不同的收敛速度,分割任务属于语义级别的分类,其学习难度远高于目标级别的分类。因此采用加权损失函数,平衡各项任务的学习。
3.3 类别编码设计
目前的牙齿分割方法中将所有牙齿划为一类,这意味着不同牙齿之间也会相互学习,从而忽略了的它们之间不同的形态特征[5,18-19]。例如,切牙与尖牙的牙冠呈楔形,而前磨牙与磨牙的牙冠呈立方形;上颌磨牙牙根为3 根,下颌磨牙为双根,而其他牙齿多为单根。
为区分不同牙齿,本文提出了两种牙齿类别编码方法,其表示方法分别如式(7)、(8)所示:

编码算法的伪代码如下所示。

Algorithm Teeth Coding Input:label of tooth 1:for each label do:2: Compute i=label/10, j=label%10 3: Compute Vi,j=(i-1)*8+j;4: if(j=1 or 2):5: Vk=1;6: else if(j=3):7: Vk=2;8: else if(j=4 or 5):9: Vk=3;10: else:11: Vk=4;Output:Vi,j,Vk
其中,Vi,j依据FDI牙位表示法进行编号[20],Vk依据牙齿的形态特点和功能特性进行编号[21],i代表牙齿所在的象限,j代表牙齿的位置,具体分布如图8所示。
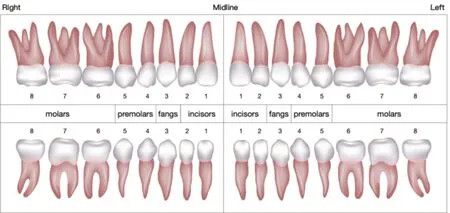
图8 牙齿分布示意图Fig.8 Tooth number indicates
3.4 实验设置
实验超参数设置如下:学习率为0.001,批处理大小为100,迭代次数为35。实验中80%的数据被用于训练集,剩下20%用于测试。考虑到牙齿分割是像素级的分类任务,其对数据量的要求比牙位识别高。由于数据量较少,我们无法从头训练整个深度学习网络,对此我们采用迁移学习的方法来提升网络的训练效果。迁移学习是指将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中[22]。在我们所使用的模型中,主干网络特征提取部分采用迁移学习的思想导入了在MS COCO 数据集[23]上的预训练权重,并运用已有的数据对网络头部进行微调。之后分别采用公式(7)、(8)两种类别表示方法Vk和Vi,j进行实验,并记为实验一(Mask RCNN-1)、实验二(Mask R-CNN-2)。
4 实验结果与分析
4.1 评价指标
为评估实验结果,我们采用了交并比(Intersection Over Union,IOU)阈值为0.50时的精度值和召回率[24],即IOU值大于0.5时为正样本,反之为负样本。其中精准率(precision)反映了查准率,它表示的是预测为正的样本中有多少是真正的正样本,而召回率(recall)反映了查全率,它表示样本中的正例有多少被预测正确,计算公式如式(9)、(10)所示:

其中,TP、FN 和FP 分别表示真阳性、假阴性和假阳性。真阳性是指预测为正,实际为正;假阴性是指预测为负,实际为正;假阳性是指预测为正,实际为负。
4.2 结果与分析
图9为实例分割结果,可以看出牙齿的位置、类别及语义信息都被提取。为方便与其他方法相对比,文中将分割结果与分类结果分开进行对比讨论。
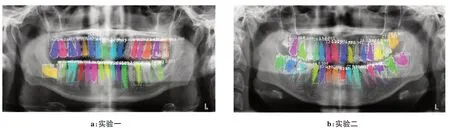
图9 实例分割结果Fig.9 Results of instance segmentation
4.2.1 分割结果两组类别编码方式的实验结果与U-net[18]和传统图像处理方法及原始Mask R-CNN[6]方法结果对比如表1所示,其中区域增长[5]为传统图像处理方法的分割结果;Mask R-CNN-1 与Mask R-CNN-2分别为实验一与实验二的分割结果。可以看出深度学习方法相比于传统图像处理方法有着明显优势,在精准率上传统Mask R-CNN 表现最优,在召回率上Mask R-CNN-1表现最优。相比于U-net,Mask R-CNN-1在精准率和召回率上提升了4%和1%,Mask R-CNN-2在精准率上提升了2%。然而在Mask R-CNN-1 与Mask R-CNN-2 的对比中,Mask R-CNN-2 的精准率和召回率都远低于Mask R-CNN-1。

表1 牙齿分割结果对比Tab.1 Comparison of teeth segmentation results
图10为实验一与实验二的分割结果。在Mask R-CNN-1 中,每颗牙齿都生成了掩膜,但是存在掩膜覆盖不完整的情况,如图中的33、34 号牙。在Mask R-CNN-2 中,存在较多的牙齿并没有生成掩膜,如18、34、38号牙。造成这种结果的原因是Mask R-CNN-1将牙齿分为4 类,同1 类下的不同实例之间相互贡献损失,而Mask R-CNN-2 将牙齿分为32 类,每1 类下只有1 个实例,无法相互贡献损失,因此实验二的分割效果不如实验一。
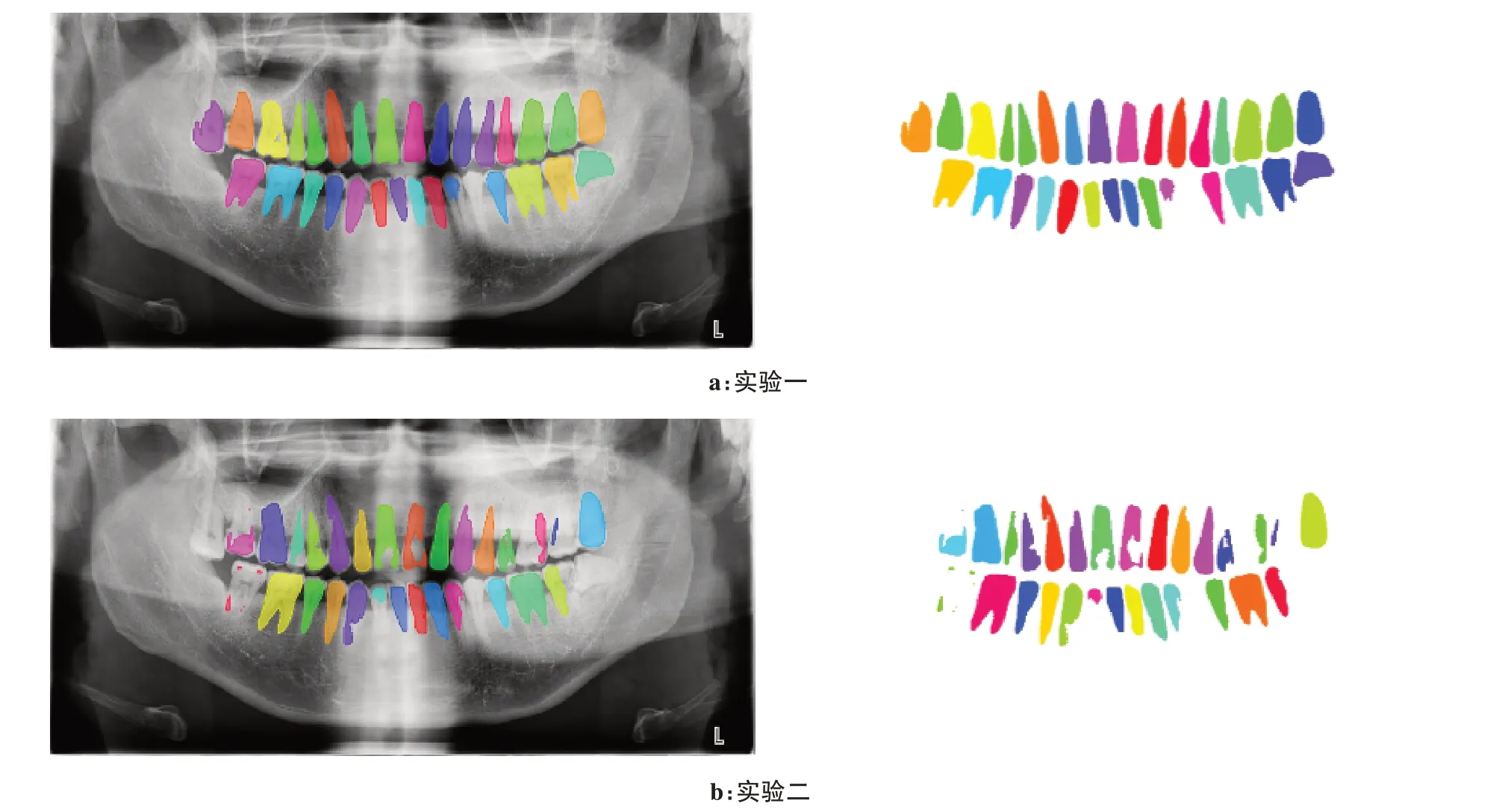
图10 分割结果Fig.10 Segmentation results
4.2.2 分类结果两组实验结果与Faster R-CNN[12]方法的结果对比如表2所示,其中Mask R-CNN-1 与Mask R-CNN-2 分别为本文实验一与实验二的分类结果。表中显示Mask R-CNN-1 表现最优,能准确识别出牙齿并根据功能分类,但是其只做了四分类,无法做到牙位识别的效果。Faster R-CNN 与Mask R-CNN-2 都是对牙齿做32 分类,能够有效识别出不同的牙位,但Mask R-CNN-2 精度相比于Faster R-CNN 有所提升。另外,在Mask R-CNN-1 与Mask R-CNN-2 的对比中,Mask R-CNN-2 的精准率和召回率都远低于Mask R-CNN-1。

表2 牙齿分类结果对比Tab.2 Comparison of teeth classification results
图11为实验一与实验二的目标检测结果,表3对应为图11中目标检测包围框上方的文字即目标分类标签及其分数值。从图11和表3可以看出在Mask R-CNN-1 中的查全率较高,每颗牙齿都被检测且都正确分类,识别分数均值能达到0.93 以上。Mask RCNN-2 中存在没有检测到的目标,如图中14、24、27、34 牙位的牙齿并没有包围框;且检测到的目标分数比Mask R-CNN-1要低,均值在0.95左右。

表3 检测结果对比Tab.3 Comparison of detection results

图11 分类结果Fig.11 Classification results
综合两种实验方案,实验一在牙齿分割任务中表现优于实验二,但是其牙齿分类程度没有实验二精细,无法做到牙位识别的效果。实验二能较好的完成牙位识别任务,却也因其各个牙位之间的分割损失值不能共享而导致分割效果不好.但是两组实验充分证明了Mask R-CNN具备同时实现牙齿分割和牙齿分类的能力,且能保证在牙齿分类与分割的精度达到90%。在过去的研究中[19],我们针对单颗牙齿应用灰度值统计方法进行纹理分析,可以在一定程度上反映牙齿正常与否,与本文方法相结合,可以为单颗牙齿的病理分析提供一定的基础,且对于各颗牙齿之后的龋齿、牙周病、根尖炎的疾病诊断分析有重要支撑作用。但是实验中使用的预训练模型是基于MS COCO数据集,与文中的牙齿X光片数据集相似度较低,在未来的研究中可以考虑采用其他的X光片数据集,这可以在一定程度上降低微调的难度,得到更好的实验结果。另外,实际诊疗过程中的牙齿X光片往往存在缺牙、残根及种植体等非正常情况,这对于本文的模型来说是一个挑战。在之后的工作中可以考虑加入应用牙齿排列的规则等其他后处理方法,有针对性的进行分析。
5 结束语
本文基于Mask R-CNN 模型对牙齿X 射线全景图中的牙齿进行分割和分类研究,以求较为准确的描绘出X 射线全景图上的每颗牙齿的形态与位置。从牙齿功能和FDI 牙位表示两种编码方式的实验表明,使用改进的Mask R-CNN 能同时进行牙齿分割和牙齿分类任务,并在这两项任务中均达到90%以上的精确率,实现了牙齿语义、位置及类别信息的融合提取。但是在语义信息提取上仍然存在一定的提升空间,该问题可能是由于数据集中影像数量较少造成。在将来的研究中,我们考虑进一步提高实验精准度,并基于实验结果进行智能分析系统研究。
