基于深度学习单投影的CT断层成像三维重建
2021-11-04张新阳贺鹏博刘新国戴中颖马圆圆申国盛张晖陈卫强李强
张新阳,贺鹏博,刘新国,戴中颖,马圆圆,申国盛,张晖,陈卫强,李强
1.中国科学院近代物理研究所,甘肃兰州730000;2.中国科学院重离子束辐射生物医学重点实验室,甘肃兰州730000;3.甘肃省重离子束辐射医学应用基础重点实验室,甘肃兰州730000;4.中国科学院大学核科学与技术学院,北京100049
前言
计算机断层扫描(Computed Tomography,CT)以高空间分辨率对患者或物体进行三维(3D)成像的能力在生命科学领域有着广泛的应用。而传统CT 成像需要通过密集扫描获得大量的投影数据,导致重建时间增加,重建速度跟不上扫描速度;另一方面,密集扫描也给患者带来了额外的辐射剂量。随着人们生活水平的提高,辐射对健康的损害逐渐引起人们的注意。此外,在断层成像的许多应用中,成像速度至关重要。于是减少CT 扫描次数,降低CT 的辐射剂量成为科研人员关注的焦点。近年来,很多研究都在寻找减少采集数据量的同时又不降低图像质量的方法,通过压缩感知[1-6]和最大后验[7]等技术对稀疏采样的图像重建进行广泛的研究。这些方法在重建反演过程中引入正则化项,以促使在重建图像中出现原本的特征[8]。如果不能降低对成像质量的要求,这些方法并不能解决在大幅度减少成像对象所受辐射剂量的同时进行实时成像,而且它们的稀疏性通常是有限的。通过机器学习技术,从大量的数据当中提取出先验知识来提高成像速度和质量是最近的热门研究课题。近年来有很多基于机器学习的图像重建的研究[9-12],但是最具有代表性的是Henzler 等[13]基于深度学习的卷积神经网络利用2D放射影像重建出了3D 图像,以及Shen 等[14]和Lei等[15]利用深度学习和数据驱动的图像重建过程方法,将稀疏采样压缩到了单个投影视图的极限,实现了通过深度学习方法基于特定患者的单视图断层成像。但是在临床上,如果对每一个患者都进行数据增强并重复训练适用于每个患者的模型,时间将会大大增加。
基于以上考虑,本研究利用卷积神经网络首次实现了适用于不同患者的深度学习CT 重建方法。这种方法普适性更强,对于不同例数的患者,只需要在治疗前利用他们的CT 图像进行数据增强并统一训练,就可以得到适用于每个患者的神经网络模型。相比于重复训练使用该方法使每个患者特定的模型节约70%的时间,在保持重建图像质量的同时大大提高了效率。
1 材料与方法
1.1 网络模型
深度神经网络因其学习复杂关系的能力以及通过特征提取和表征学习将现有知识纳入推理模型的能力而备受关注[16-18]。这种方法在很多学科都有广泛的应用,如自动驾驶、自然语言处理、计算机视觉和生物医学。而深度残差网络(如ResNet[19])在许多竞赛中表现出良好的性能,它可以加速模型训练,并在很大程度上避免了由于增加网络层数后在反向传播时出现的梯度消失或梯度爆炸现象。目前还没有研究实现适用于不同患者的深度神经网络模型及方法。本研究以Shen 等[14]研究为基础,对其模型进行改进,在生成网络的部分反卷积残差块加入快捷路径,并尝试适用于不同患者的基于深度学习重建方法。本研究采用的网络模型如图1所示,整个网络架构分为3 部分,分别为表征网络、转换模块和生成网络。

图1 深度学习网络架构Fig.1 Architecture of deep learning network
表征网络由5 个二维卷积残差块组成,以便从2D 投影图像中提取层次语义特征。每个2D 卷积块由2D 卷积层、2D 批处理归一化层、ReLU 层、2D 卷积层、2D 批处理归一化层和ReLU 层按顺序组成,可以从2D 图像中提取出特征信息。第一卷积层使用3×3的卷积核和2×2 的滑动步长执行卷积操作将特征图的空间大小下采样一半。为了保持高维特征信息的稀疏性,增加滤波器的数量将特征映射的通道数增加一倍。随后经过批标准化层[20]后通过ReLU 层将特征信息向后馈送。第二卷积层使用3×3 的卷积核和1×1的滑动步长保持特征图的形状大小。另外,在应用第二个ReLU 层之前,使用额外的快捷路径将第一个卷积层的输入相加获得最终输出。通过建立身份映射的快捷路径,鼓励第二卷积层学习残差特征表示。
转换模块在表征网络后,通过卷积和反卷积连接表征网络和生成网络,并关联2D 和3D 特征表示。将表征网络的输出进行整形,跨维度的变换特征表示以便于后续生成3D体积。模型中为了更好地通过该模块进行特征信息的转移,删除了转换模块中的批标准化层。
生成网络由3D 反卷积层、3D 批归一化层、ReLU层、3D 反卷积层、3D 批归一化层和ReLU 层的3D 反卷积块组成。第一个反卷积层使用4×4×4 的卷积核和2×2×2 的滑动步长将特征图的空间大小上采样2倍。第二个反卷积层使用3×3×3 的卷积核和1×1×1的滑动步长保持特征图的形状大小。每个反卷积层之后是3D 批归一化层和ReLU 层,生成网络主要由4个反卷积块组成,第二和第三反卷积块使用额外的快捷路径将第一个反卷积层的输入相加获得最终输出。在生成网络的末端,有一个由3D卷积层和2D卷积层(卷积核大小为1)组成的输出变换模块,用于输出3D 图像。输出变换模块中的批归一化层被移除,并且最后的卷积层后边去掉了ReLU 层。生成网络基于从表征网络学习到的特征信息生成具有细微结构的3D CT图像。
1.2 材料及数据增强方法
本研究采用3 例肺癌患者的4D CT 图像数据,数据来自上海市质子重离子医院。使用Plastimatch 软件将患者的CT 图像生成对应的数字重建放射影像(DRR),并使用一个Nvidia Titan RTX 图形处理器(Graphics Processing Unit,GPU)训练模型。
由于实际情况限制,我们并不是实际获取了大量的2D X射线图像和对应的相同时刻的CT图像进行监督训练,而是利用患者的CT图像模拟生成的DRR与其对应的CT图像进行训练。在训练深度学习模型时,由于数据有限需要进行数据增强。本研究纯粹从深度学习的数据增强角度出发,对CT数据进行平移、变形以及大角度旋转,最终产生了类似于传统CT重建的多角度投影数据域。在研究中,单例患者时,将其10个时相的4D CT数据按照上述数据增强策略扩充为2 940个CT,并用Plastimatch软件生成对应的DRR,每一个CT及其对应生成的DRR就是一个数据样本,最终共产生2 940个数据样本,将所有数据样本随机打乱后按照6:2:2的比例划分为1 764个训练样本、588个验证样本和588个测试样本。研究范围是3例患者时,按照上述方法最终共产生8 820个数据样本,其中包括5 292个训练样本、1 764个验证样本以及1 764个测试样本。
1.3 数据预处理
在将数据样本输入网络之前对其进行预处理。与其它利用深度学习方法对图像重建的研究[11]类似,由于GPU 内存限制以及计算效率的影响,对CT图像进行下采样处理,将CT 图像的大小由512×512调整为128×128。所有的数据样本都被调整为相同的大小,将2D DRR 图像的大小调整为128×128。单例患者时,将其CT 图像仅进行下采样处理,不改变层数,最终得到127×128×128 的CT 断层图像。研究3例患者时,将3例患者的CT断层图像大小统一调整为123×128×128。具体地说就是将其余两例患者的CT 图像从最上边分别减少对应层数与CT 图像层数最少的患者相同,这种方法在保证将3例患者的数据顺利输入网络训练的同时还可以确保3 例患者的CT图像中的关键信息没有减少。此外,为了使模型在训练时更好的收敛,将2D DRR 图像和CT 图像的像素强度归一化到[0,1]。对输入2D DRR 图像进行标准差归一化,计算3类样本中所有数据的平均值和标准差,然后用输入2D DRR 图像减去对应样本域的平均值,然后除以标准差,使其像素强度的统计分布更接近标准高斯分布,得到最终输入网络的2D 图像数据。
1.4 训练策略
输入图像X 为2D DRR 图像,训练深度网络模型用来预测CT 图像Ypred,使预测图像Ypred尽可能接近真实图像Ytruth。将成本函数定义为预测值与真实值之间的均方误差,并通过随机梯度下降迭代优化模型。基于PyTorch 库构建网络,并用Adam 优化器最小化损失函数,通过反向传播迭代更新网络参数。单例患者时,学习率设置为0.000 03,由于内存限制使用大小为1 的小批量进行训练。训练周期为100次,每个训练周期结束后将模型在验证机上进行验证,最后将验证损失最小的模型参数当作最终的模型参数。对3 例患者进行研究时,学习率设置为0.000 03,每次向网络输入的批量为1。模型共训练30 次,在每个训练周期结束后,将模型在验证集上进行验证,以便监控模型的性能并避免模型在训练集上发生过拟合。如果连续6 个训练周期内验证损失没有下降就将学习率自动调整为原来的二分之一,最后将验证集上表现最好也就是验证损失最小的模型参数当作最后的模型参数。在模型训练过程中,网络模型学习从2D DRR 图像到CT 图像的映射函数。本研究单例患者训练时间大约需要43 h,3 例患者训练时间大约为52 h。在测试过程中,单例患者和3例患者的一个测试样本的3D重建时间约为0.5 s。
1.5 结果评价指标
将最终的模型部署在测试数据集上,使用定性和定量的评估指标分析重建结果并评估模型的性能。使用平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error, RMSE)、结构相似性(Structural Similarity,SSIM)和峰值信噪比(Peak Signal Noise Ratio,PSNR)4种不同的度量标准来衡量预测的CT图像的质量。如表1所示,计算所有测试样本的平均值得到4种度量标准。在机器学习中,通常使用MAE、均方误差(MSE)估计预测图像和真实图像之间的差别,取MSE的平方根得到RMSE。MAE、MSE是Ypred和Ytruth之间的L1范数、L2范数误差。SSIM是通过滑窗的方法计算两幅图像的结构相似性,是衡量两幅图像相似度的常用指标。PSNR是影响图像质量的最大信号功率和噪声功率之间的比率,被广泛用于衡量图像重建的质量。
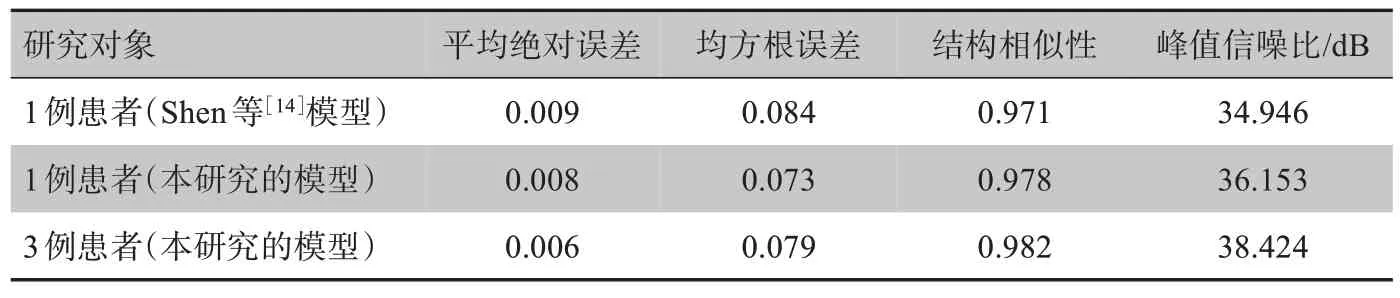
表1 单例患者和3例患者的重建结果Tab.1 Reconstruction results for a patient and 3 patients
2 结果
图2是单例患者和3例患者训练过程中训练样本和验证样本的损失曲线,可以看到模型很好地拟合了训练数据,并且在训练集以外的数据中也表现很好。

图2 训练损失和验证损失曲线Fig.2 Training loss and validation loss curves
表1是各项评估指标在测试样本上的平均值,表中第一行数据是用Shen 等[14]模型得出的结果,第二行和第三行是使用本研究改进后的模型以及数据增强方法得出的结果。从表中可以清楚地看出,本研究所提出的模型和数据增强方法在单独训练单例患者模型中可以得到更好的模型参数。此外,对于不同患者,同样可以得到比较好的模型参数,除了均方根误差略高于单例患者时的结果,其余3个指标都比单例患者时的结果更好。
为了评估该方法的性能,将研究中最终得到的网络模型部署在测试数据集上。图3展示了单例患者以及适用于不同患者的CT图像重建结果以及真实CT图像与预测CT图像之间的差异图像。结果表明,本研究提出的方法可以对3例不同的患者进行较好的CT图像重建,说明深度学习重建CT图像方法具有很大的潜力,进一步证实了本研究方法的可行性。
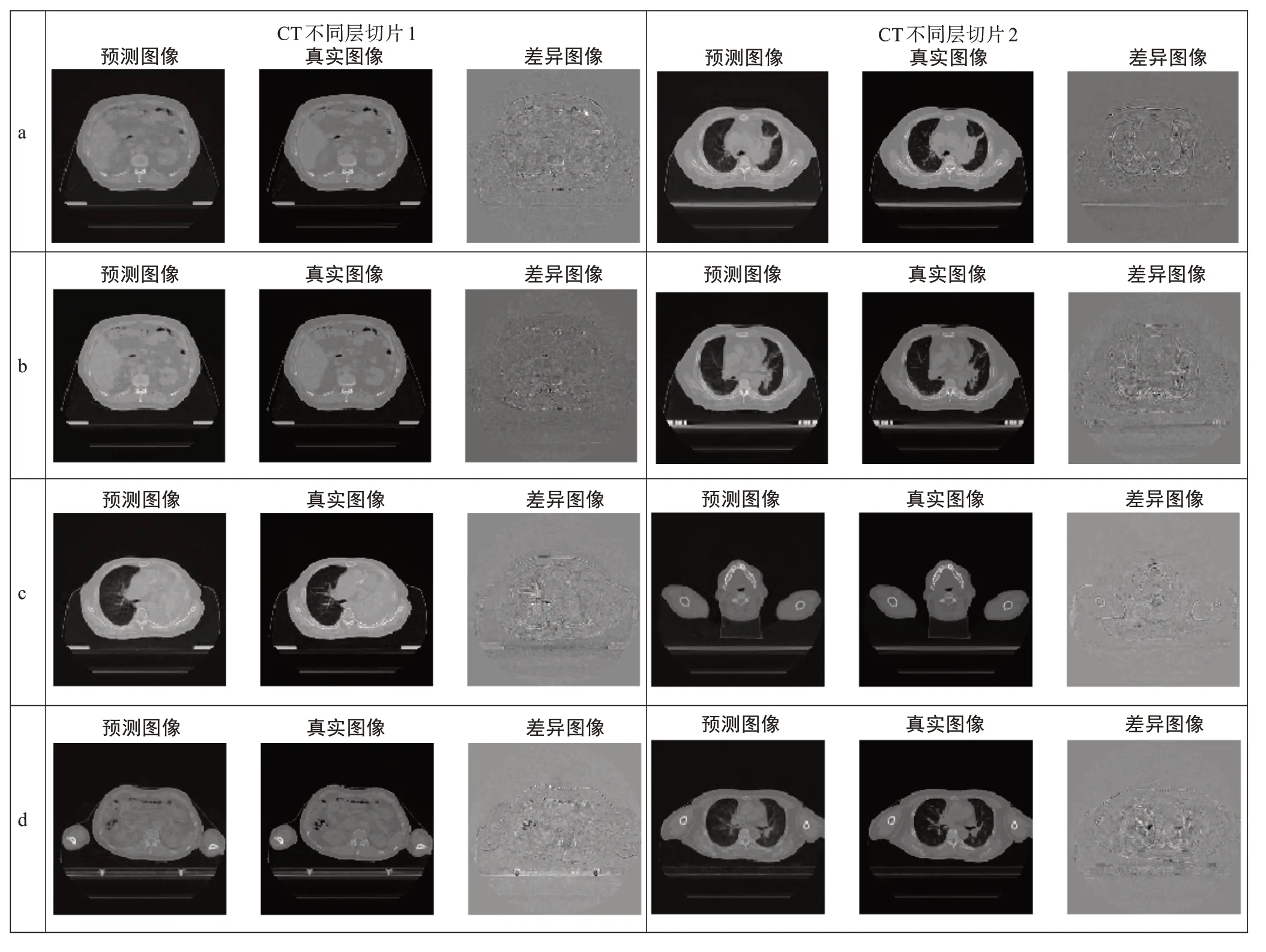
图3 CT重建结果Fig.3 CT reconstruction results
3 讨论
许多不同的3D 体积可以产生对应的2D 放射影像,然而将这一过程进行反转是非常具有挑战性的。为了减少重建过程中数据采集量和成像剂量并提高重建速度,本研究提出一种基于深度学习的CT 单视图断层成像3D 重建方法。不同于传统的CT 重建方法,本研究利用深度学习,仅使用单个视图就能在短时间内完成CT 重建。与现有的深度学习方法相比,本研究将重建对象由1例患者推广为多例患者,实现了针对不同例数患者的CT 单视图断层成像3D 重建,而不必再对每例患者单独进行重复的数据增强及模型训练,节省约70%的训练时间。
本研究中的方法证实了通过深度学习构建一个普适于更多患者的网络模型的可行性,有望简化临床上的CT 成像设备,并可以为目前放射治疗中图像引导遇到的问题提供潜在的解决方案。未来我们还会对本研究的神经网络模型做进一步的优化,并使用更多例数的小批量患者数据得到普适性进一步提高的模型。
