融合PSⅡ光化学活性的茄子光合速率预测模型研究
2021-11-04蒲六如
蒲六如,高 攀,2,李 斌,2,,2,胡 瑾,2
(1西北农林科技大学机械与电子工程学院,咸阳 712100;2农业农村部农业物联网重点实验室,咸阳 712100)
在植物生长过程中,光照为植物的光合作用提供基本能量,是十分重要的环境因子[1];CO2为作物进行光合作用提供主要原料,对增加作物产量和品质具有重要作用;温度也是影响光合速率与呼吸速率的重要参数[2]。光合作用是植物将光能转换为可用于生命过程的化学能,并进行有机物合成的生化反应[3],是植物物质积累与生理代谢的基本过程,直接影响干物质累积程度[4]。同时净光合速率(Pn)是评价植物生长的一个重要指标[5],对其精准预测是现代设施农业环境调控的基础,综合考虑温度、CO2浓度等对植物光合作用的影响,可以准确预测不同环境中植物的生长发育的Pn[1]。在光合作用研究中,叶绿素荧光是一个重要指标,不参加PSⅡ光化学反应的光能辐射部分称为固定荧光Fo,与植物叶片中的叶绿素含量有关;参与PSⅡ光化学反应的光能辐射部分称为可变荧光产量Fv[6],与PSⅡ反应中心相对活性大小相关;二者比值为PSⅡ光化学反应的PSⅡ光化学活性(Fv∕Fo)[7]。
目前,有关植物光合速率预测模型的建模方法研究已有很多,智能算法对光合速率建模精度等方面有较大提升[8]。李婷等[9]针对番茄采用BP神经网络建立了光合速率预测模型,适用于利用环境因子预测光合模型,是一种常用的神经网络,能较好地预测光合速率[10],但是BP神经网络对于复杂数据的适应性弱于随机森林算法(RF)[11],且其未考虑植物叶片本身状态差异对Pn的影响。张海辉等[12]考虑叶位对植物Pn的影响,融合叶位参数建立茄子光合速率预测模型,有效提高了光合速率预测模型适用性,但研究只针对叶位不同的植物叶片,并未考虑相同叶位的叶片在叶龄、健康、形态等方面存在不一致的情况,其对不同生理状态叶片光合速率的预测存在缺陷。胡瑾等[13]选取PSⅡ反应中心处于开放态时光化学的反应效率(Fv∕Fm)表征植物内部光合能力,有效提高了光合速率预测模型的精度,但是徐澜等[14]研究表明,Fv∕Fo对环境因子的敏感度高,对植物光合能力的表征更准确,可以更加准确地反映植物光合机构的状态。
对植物的光合速率进行研究不能只考虑外部的环境因素或叶位因素,也要考虑植物的内部生理状态,建立融合叶片内部状态与外部环境因子的植物光合速率预测模型是当前亟待解决的问题。本研究在已有植物光合速率预测模型研究的基础上,引入反映植物内部状态的关键荧光参数PSⅡ光化学活性Fv∕Fo、耦合光照强度、温度和CO2浓度等外部环境因子建立茄子光合速率预测模型,并设计多因子嵌套试验,获取1 320组光合速率数据样本。采用RF算法,利用上述数据样本进行训练,得到最终光合速率预测模型,实现对不同生理状态茄子叶片光合速率的精准预测,以期为设施农业环境因子调控奠定基础。
1 材料与方法
1.1 试验材料
试验以茄子(Solanum melongenaL.)品种‘长茄305’为试验对象,在西北农林科技大学农业农村部农业物联网重点实验室(34°7′39″N,107°59′50″E,海拔648 m)进行。将试验对象置于CO2人工气候箱(达斯卡特,RGL-P500D-CO2)中,并用基质(Pindstrup substrate,丹麦)栽培的方式进行培育。CO2人工气候箱内相关环境参数具体设置为:光周期昼夜分别为14 h、10 h,温度昼夜分别为25℃、16℃,空气相对湿度昼夜分别为60%、50%,CO2浓度为400μmol∕mol。将长势相同的优良四叶一心茄子苗54株随机平均分成6组,培养于6组不同光照环境,光合光子通量密度(Photosynthetic photon flux density,PPFD)依次为50μmol∕(m2·s)、90μmol∕(m2·s)、140μmol∕(m2·s)、220μmol∕(m2·s)、280μmol∕(m2·s)、340μmol∕(m2·s),并控制其他环境因子和管理方式相同。由于不同植株摆放位置不同、同一植株不同枝叶的伸展不一,其与光源距离有差异,叶片实际接受有效光量子辐射不同。处理15 d至茄子植株叶片形态产生明显差异,确保同时存在形态不一的厚小和薄大的叶片。选取各培养箱中差异明显的植株为试验样本进行试验数据采集。
1.2 试验方法
每片茄子叶片暗荧光参数皆利用MINI-PAM-Ⅱ型调制叶绿素荧光仪(WALZ公司,德国)测取,首先利用暗适应叶片夹将茄子叶片暗适应20 min,然后利用仪器设定的程序进行暗荧光参数测定,并记录Fv∕Fo值。对应叶片的光合参数是利用LI-6800型便携式光合速率测试仪(美国)进行测试,光合测试与荧光测量位于叶片同一位置。以温度为依据划分5个温度组,分别为34℃、31℃、28℃、25℃、22℃。每个培养箱中分别取出1个叶片,共6个叶片放入同一个温度组中。测量试验环境由光合速率测试仪的不同模块设定。在嵌套试验中设置叶室CO2浓度分别为1 300μmol∕mol、1 000μmol∕mol、700μmol∕mol、400μmol∕mol共4个梯度;PPFD设定为1 500μmol∕(m2·s)、1 300μmol∕(m2·s)、1 000μmol∕(m2·s)、700μmol∕(m2·s)、600μmol∕(m2·s)、500μmol∕(m2·s)、400μmol∕(m2·s)、250μmol∕(m2·s)、100μmol∕(m2·s)、50μmol∕(m2·s)、0μmol∕(m2·s)共11个梯度。由于短时间内叶片内部生理状态不会剧烈变化,暗荧光参数几乎不变[15],所以每片采用相同暗荧光参数在固定温度下进行CO2与光照强度嵌套光合试验。每组试验样本数据包括光照强度、温度、CO2浓度、暗荧光参数Fv∕Fo以及光合速率,共获取1 320组试验数据,剔除98组粗大误差数据后,最终得到1 222组试验样本数据。
2 模型构建
在试验采集所得数据样本集中,以CO2浓度、PPFD、温度和当前叶片Fv∕Fo作为输入,以Pn作为输出,利用RF算法构建植物光合模型,模型构建过程主要包括训练集与测试集的选取、模型核心参数确定、模型构建及模型验证。算法流程图如图1所示。
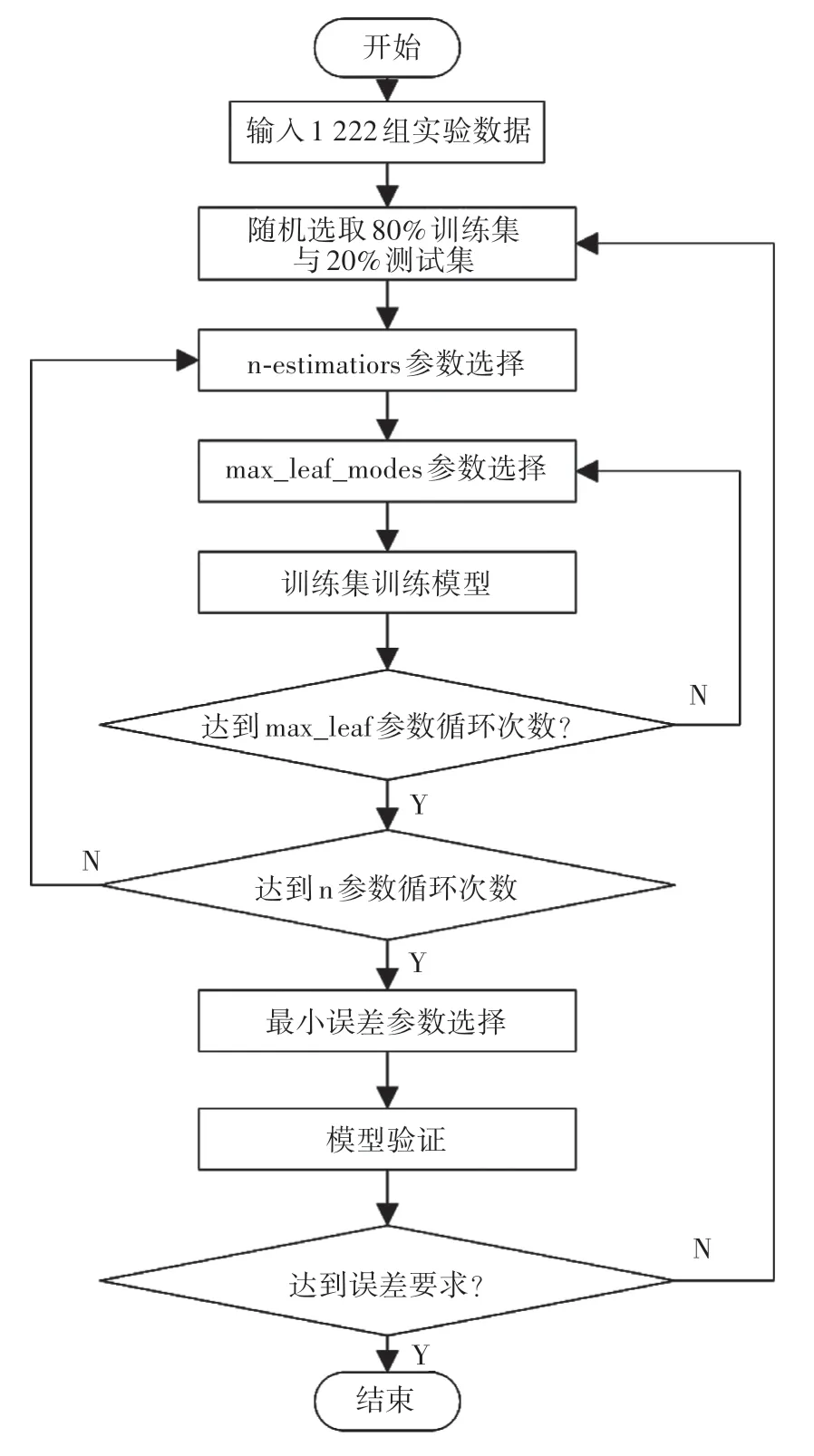
图1 RF算法流程Fig.1 RF algorithm flow chart
2.1 数据预处理
利用随机森林训练模型之前,首先需将所采集的不同维度的样本数据进行线性归一化处理,使其处于同一个数量级,在区间[0,1]上,以避免数据之间差异过大而导致样本不均衡,使所训练模型偏移。
2.2 训练集与测试集的选取
基于上述的试验过程、结论以及数据预处理,将试验所获取的1 222组以CO2浓度、PPFD、温度和当前叶片Fv∕Fo作为输入向量,以Pn作为输出向量的试验样本作为本模型的机器学习数据集。随机将其分为五组,其中四组作为训练集,占总数的80%。其余的一组作为测试集,占总数的20%。
2.3 参数选取对模型性能影响分析
最优决策树棵数n_estimators(n)是随机森林算法中最主要的参数。决策树是随机森林算法的基本单元[16],决策树的构造是由一个随机向量所决定。随机森林算法的本质是组合多个弱分类器,使其误差减小的一种分类算法[17]。决策树数量的选取对模型的拟合结果有很大的影响,而且对与不同的对象而言,性能达到最优时的值是不同的[18]。取值过小会造成“欠拟合”的情况,而取值过大有可能会造成“过拟合”。
为了提升模型的精度与速度,首先利用试参法确定参数寻优的范围。对参数n进行试参法得到n关于测试集拟合度的影响曲线如图2所示。
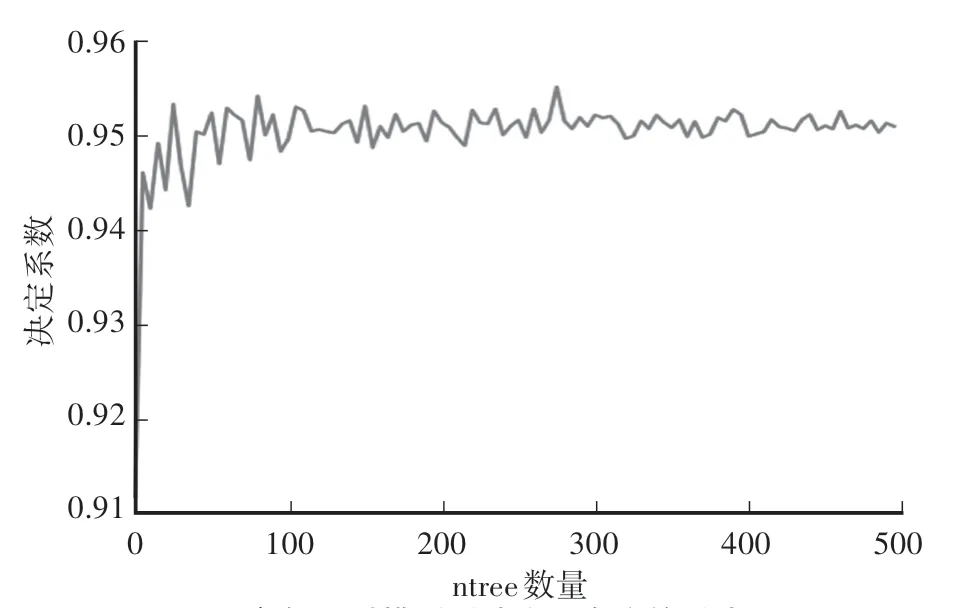
图2 参数n对模型测试集拟合度的影响Fig.2 The influence of parameter n on the fitting degree of the model test set
当参数n小于50时测试集拟合度变化非常剧烈;在50—150时有下降的趋势;当n在150—300时变化趋于平稳,并且可以取得最大值;但当n大于300时测试集拟合度有所下降。所以设置随机森林算法中参数n的索引范围为[150,300],同时设置参数n的步长为5。最优决策树的选取是通过每棵决策树通过因变量的观测值Yi(i=1,2,…,n)的加权平均所得到的对应的预测值[19],用公式表达为:

式中,ωi(x)为每个观测值Yi∈(1,2,…,n)的权重。
固定决策树棵数时,用试参法可以获得参数max_leaf关于测试集拟合度的影响曲线如图3所示。
如图3所示,当参数max_leaf小于100时,对测试集拟合度的影响非常大,当取值为200—350时趋于平稳且有所提高。当取值大于350时波动增大,变得不稳定。所以设置随机森林算法中参数max_leaf的索引范围为[200,350],同时设置参数max_leaf的步长为5。
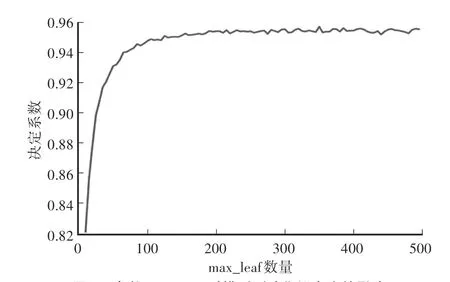
图3 参数max_leaf对模型测试集拟合度的影响Fig.3 The influence of the parameter max_leaf on the fitting degree of the model test set
采用网格寻优的方法来验证两个参数对误差的影响关系,设置参数n和max_leaf寻优步长为5,构建出归一化均方差曲面(图4)。可以看出,叶节点数在索引范围[200,350]和n在索引范围[150,300]时误差趋于平稳且最小。

图4 参数n,max_leaf变化下归一化误差曲面Fig.4 Normalized error surface under the change of parameter n,max_leaf
通过异校验,利用网格寻优法完成算法参数优化获得最佳参数n为190,max_leaf为275。
3 模型验证与对比
3.1 建模方法对比
从训练集拟合精度,决定系数两个方面来验证利用随机森林所建立的模型与常用的基于梯度下降法的二次多项式多元非线性回归算法NLR、BP神经网络算法、及以网格支持向量机算法SVR进行了算法性能对比,对比结果如表1。

表1 不同模型误差的比较Table 1 Comparison of different model errors μmol·m-2·s-1
如表1所示,随机森林算法对于多因子耦合的光合速率数据的误差显著低于BP神经网络,二次多项式多元非线性回归和网格支持向量机算法,具有最高训练精度,拟合能力强.比较而言,二次多项式多元非线性回归均方根误差达到10.594 4μmol∕(m2·s),而BP神经网络和网格支持向量机均方根误差分别为7.400 5μmol∕(m2·s)和6.623 2μmol∕(m2·s)。因此随机森林算法在上述算法中性能最佳,对光合速率预测模型建模效果最优。
3.2 模型验证
为了证明PSⅡ光化学活性Fv∕Fo对模型的影响,分别按照上述流程图中的步骤完成未融合PSⅡ光化学活性Fv∕Fo和融合PSⅡ光化学活性Fv∕Fo的模型构建,验证结果如图5所示。
如图5(a)所示,不考虑引入PSⅡ光化学活性而仅以环境因子为输入建立出的光合速率预测模型,对未知数据的预测值与真实值相比,差异显著,而融合PSⅡ光化学活性荧光参数后的预测值与真实值较为接近。基于随机森林算法,融合PSⅡ光化学活性Fv∕Fo的植物光合速率预测模型测试集真实值与预测值拟合公式为:

图5 不同输入下的预测模型对比Fig.5 Comparison of prediction models under different inputs

未融合PSⅡ光化学活性Fv∕Fo的测试集真实值与预测值拟合公式为:

融合PSⅡ光化学活性Fv∕Fo的模型直线斜率为0.952,纵轴截距为0.02,决定系数为0.950 7,均方根误差为1.266 8μmol∕(m2·s)。未融合PSⅡ光化学活性Fv∕Fo的模型直线斜率为0.796,纵轴截距为0.09,决定系数为0.830 4,均方根误差为2.021 0μmol∕(m2·s)。对比未融合PSⅡ光化学活性Fv∕Fo的模型拟合公式,含有PSⅡ光化学活性Fv∕Fo的模型截距小且斜率更接近1,均方根误差更小。表明了暗荧光参数Fv∕Fo对模型的影响显著。引入暗荧光参数Fv∕Fo使模型实测值与预测值更接近,相关性更高,提升了模型泛化能力和预测精度。上述现象的出现应该是在相同的外界环境条件下,由于不同叶片自身光合能力差异的限制,使作物的光合速率产生明显差异,从而导致仅考虑环境因素的光合速率模型在对不同生长状态叶片进行光合速率预测效果不佳。而由于PSⅡ光化学活性Fv∕Fo是一种直接反映作物光合反映中心活性的暗荧光参数,其一定程度反映了不同叶片自身光合能力差异,将其和多环境参数耦合建模,实现了对作物自身生长状态和外界环境的协同考虑,从而有效提升了不同生长状态茄子叶片的预测精度。
4 结论
本研究基于随机森林算法,融合对茄子光合速率影响颇大的荧光参数——PSⅡ光化学活性Fv∕Fo和外界环境因子,建立了茄子光合速率预测模型。利用网格寻优法完成算法参数优化,获得最佳参数n为190,max_leaf为275。然后通过采用多种建模方法,对比各项模型性能评价指标,结果表面随机森林回归模型对光合速率预测模型中的复杂数据具有良好的适应性。基于训练数据集建立融合Fv∕Fo的茄子光合速率预测模型,其决定系数为0.950 7,均方根误差为1.166 8μmol∕(m2·s),最大绝对误差为5.293 0μmol∕(m2·s),平均相对误差为0.131 5μmol∕(m2·s),较其他模型而言是最优的。采用相同方法建立不含Fv∕Fo的光合速率预测模型,其对未知数据预测精度远低于本研究所建立的模型,验证了PSⅡ光化学活性Fv∕Fo对茄子光合速率的影响。试验结果表明加入Fv∕Fo后,模型对植物光合速率预测更精准,可以推广到其他作物的光合速率预测。本研究为对不同状态植物叶片的光合速率精确预测奠定基础。
