基于偏微分的非线性代数方程组并行模型设计
2021-11-04种孝文
种孝文
(白城师范学院 数学与统计学院,吉林 白城 137000)
0 引言
非线性代数方程组并行模型的工作是在并行机上完成大规模的数据计算。非线性代数方程组可以解决计算机校验、图像切割、数据分析、项目工程等相关领域的问题[1-2]。为了提高非线性代数方程组的计算精度并简化方程组计算的复杂度,本文设计了基于偏微分的非线性代数方程组并行模型。由于并行计算机的处理对象具有规模大、复杂度高的特点,考虑到以上因素,本文通过降噪算法完成对传统非线性代数方程组的优化。另外,该方程组并行模型还融合了多分裂迭代算法和偏微分方程,有效降低了模型计算过程的复杂度,达到了提高模型计算精度的目的。
1 非线性代数方程组并行模型设计
1.1 并行算法思路设计
在设计并行算法时,首先检索待计算的数据库,对内部的数据进行预处理,转变数据格式,处理公式如下:
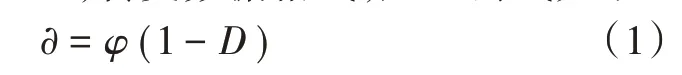
式中:∂表示预处理后的数据;D表示当前时刻所属数据库内部数据的水平集合;φ表示检索数据的梯度算子[3-4]。
数据并行运算过程如图1所示。

图1 数据并行运算过程
根据初始化操作完成对数据的预处理,然后根据数据规模和计算类型选择对应的权函数。权函数的作用是平衡迭代计算过程中模型计算的误差,并且确定数据计算任务的核心关联量。在确定数据的核心关联量后,随之确定数据整体关联量的迭代下降流,计算公式如下:
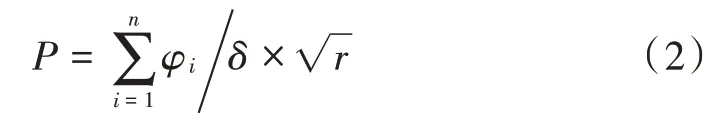
式中:δ表示数据库内数据流的约束分子;r表示数据的字节数[5-6]。
然后对内部有效数据进行关联切割。非线性代数方程组并行算法的切割原则是随机组合数据关联度最小的三个数据分子[7-9]。为了降低算法的误差,本文通过数据能量函数计算数据关联系数。关联切割过程如图2所示。
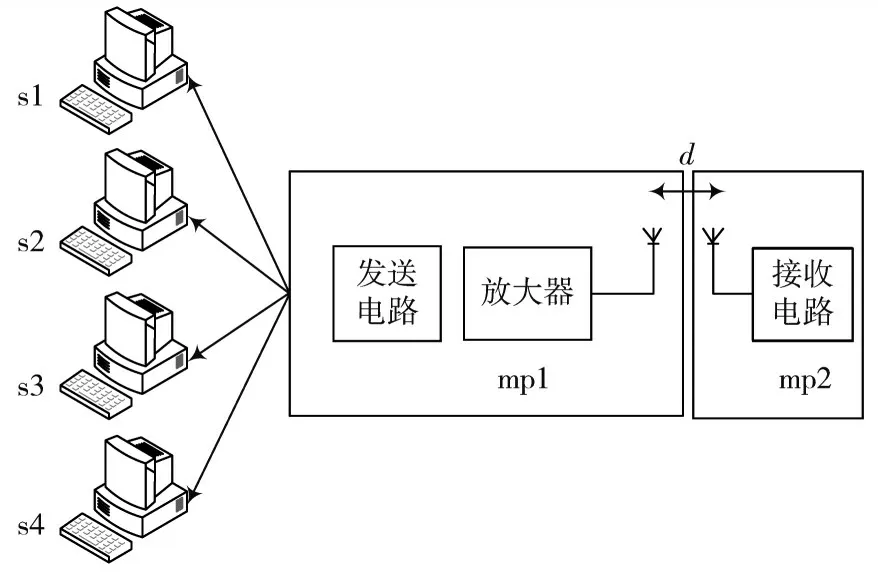
图2 关联切割过程
在此基础上,结合波前控制算法,将切割处理好的数据块重新构成一个可调用分解的数据体系,该过程计算公式如下:
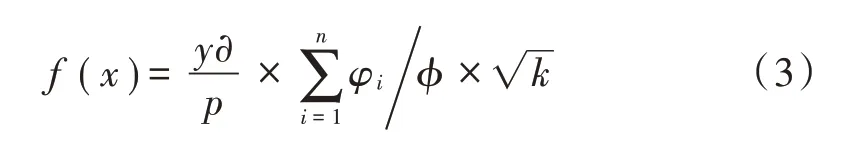
式中:y表示数据边缘算子;φ表示拉普拉斯算子;k表示数据集成的高斯运算积[10-12]。
并行数据如图3所示。
图3 并行数据
相对于上述传统的并行计算过程,非线性代数方程组并行算法的优点是:在处理相同规模的数据时,并行模型可以在一定程度上减少数据计算过程的负载和开销,保证模型的计算能力。将预处理后的数据在非线性代数方程组并行模型上模拟分布,一旦矩阵的绝对对角数值为0时,则并行模型的迭代分量无需另行计算,直接代入设定值1即可。这种做法可以节省计算时间、提高计算效率。
1.2 并行数据去噪处理
对并行数据实施去噪处理的目的是:在提高数据精度的同时,保证数据处理的有效性。因为去噪过程具有数据还原性和数据销毁性,因此这一运算流程是不可逆的,但是在最初模型数据录入时存在数据备份,因此不需要担心流程误操作造成的影响。
数据去噪处理过程如下:
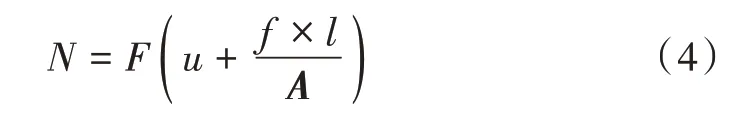
式中:N表示去噪后的数据;F表示数据的权重系数;u表示非线性方程组并行模型的光滑数据项;A表示非负非减函数;l表示数据块的序列号。
本文设计的数据去噪算法不仅有效地消除了冗余数据,同时也避免了模型在处理数据过程中因出现格式错误而终止模型计算的情况。数据处理过程如图4所示。
图4 数据处理过程
1.3 四阶偏微分方程分析
由于弧度数据降噪的总变数总是比直线无噪数据的总变数大。因此,基于偏微分的非线性代数方程组并行模型可表示为以下优化问题:
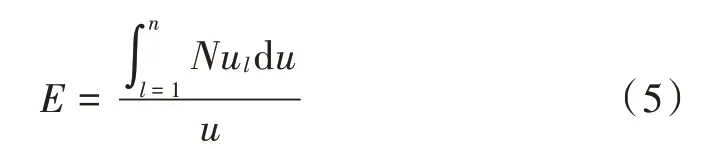
式中:n表示数据块数量;u表示数据计算阈值。
基于此,随着计算次数的增加,非线性代数方程组并行模型能够达到最大去噪标准[13]。在这一过程中,研究发现在数据波动情况较为平坦的区域中,方程的扩展性能会增强,其可将数据乱码的区域扩展成平滑区域,从而提高多个数据节点集成为一个整体的数据切割块过程中的转变效果。在越平坦的区域上,数据扩展态势也会越强烈,最终使所有数据都转化成片段式的常数区域,这时数据切割块中的各个数据节点都具有独立性,并且数据块边缘的数据节点也具有完整性[14-15]。
综上所述,本文设计的非线性代数方程组并行算法可以成功地降低数据噪声信息并实现减噪最大化。但其缺点在于数据降噪过程中可能出现过度扩展情况,且数据被切分为非常小的结构体,增加了数据融合计算的复杂度,从而产生“弧度效应”,为此,本研究设计了一个四阶偏微分方程来消除“弧度效应”带来的影响。
1.4 并行模型的实现
在上述研究的基础上,设计如下并行模型的实现过程。为了将偏微分方程与非线性代数方程组并行算法的集成契合度最大化,本研究规定基于偏微分的非线性代数方程组并行模型的并行差分格式如下:
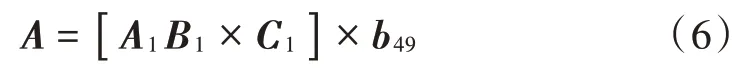
式中:A1B1表示50×50阶对角阵;C1表示50×50阶三角对角阵;b49表示50×50矩阵库。
因为非线性代数方程组并行模型需要对数据块进行切割处理,切割过程中只是保证了单位数据的完整性,却忽略了待计算数据的有效性。因此,上述规定的基于偏微分的非线性方程组并行差分格式重新制约了被切割数据的有效性,从而有效保证计算结果的精度。模型矩阵内的所有数据序号按照切割顺序排列即可。根据上文提到的相关算法,总结出基于偏微分的非线性代数方程组的并行模型计算流程如图5所示。
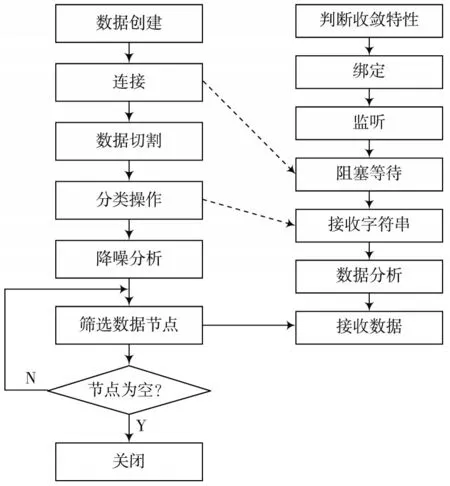
图5 基于偏微分非线性代数方程组的并行模型计算流程
步骤1:对待计算的数据进行初始化处理,输出一系列有效的数据,然后利用非线性代数方程组并行算法对所有的数据进行切割分类操作。
步骤2:对经切割得到的小数据包进行降噪分析,过程中会舍弃部分失效的数据节点,处理完成后,再重建数据并补录到非线性代数方程组并行模型内。
步骤3:调用偏微分方程,检验模型内部的数据是否具有收敛特性。如果具有收敛特性,则停止处理,按照计算任务处理模型内的数据,输出结果即可;如果模型内的数据不具备收敛特性,则重复步骤1,直至最终模型内的数据全部具有收敛性特征,输出计算结果,并行模型完成计算任务。
2 实验与研究
为了检验上述设计的基于偏微分的非线性代数方程组并行模型的实际运算能力,设计了如下对比实验。利用本文模型与传统基于拟牛顿法的并行模型和基于粒子群算法的并行模型同时针对同一非线性代数方程组进行分析计算,记录三种模型在运算过程中的搜索次数,并计算出各自的运算成功率,进而能够更加科学地分析出三种模型的计算准确度和运算效率。
将同一组非线性代数方程组导入到运算模型程序中,数据经过变换处理,得到对应的负常曲率的曲面,根据得到的曲面进行变换求解。导入的非线性方程组如下:
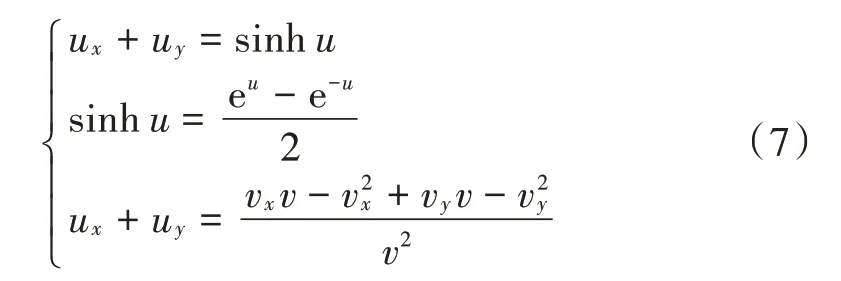
首先,将方程和存在未知函数的部分进行转化,使其转化为含有未知函数的等价多项式非线性方程:
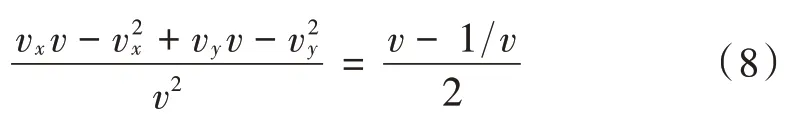
然后,根据平衡原则对其进行展开,得到含有未知函数的非线性方程解的表达式:
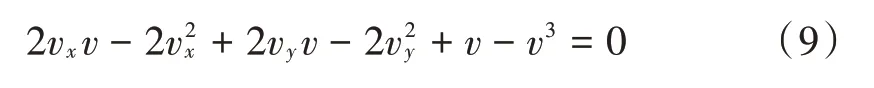
对上述表达式进行求约化解,经过多次搜索运算得到多个方程组精确解的函数表达,然后借助波形函数模型构建程序,通过求解运算得到方程组精确解的最终结果。为了进一步提高计算的精准度,可以加深运算的程度,增加求解的运算搜索次数,使计算结果更加精确。三种模型的运算成功率对比结果如图6所示。
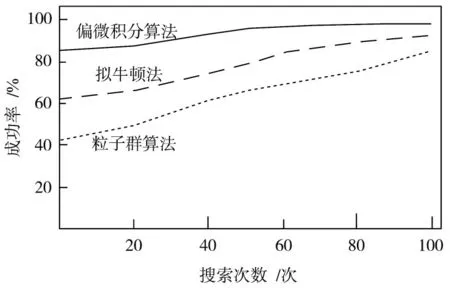
图6 三种模型运算成功率对比图
如图6所示,相比于传统模型来说,本文模型采用的偏微积分算法的成功率更高。在运算搜索次数为50次时,本文模型的计算成功率已超过90%,而此时基于拟牛顿法的并行模型的计算成功率大约为76%,而基于粒子群算法的并行模型的计算成功率在64%左右,由此可见本文模型的运算精准度更高,运算分析的稳定性、安全性更强。三种模型的运算搜索速度对比结果如图7所示。
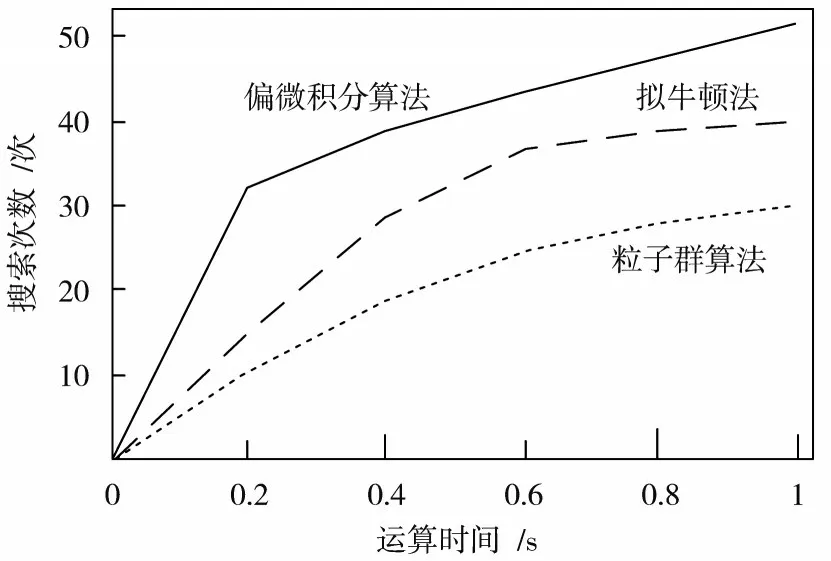
图7 三种模型运算搜索速度对比图
从图7可以看出,本文模型比传统模型的计算速度更快。根据图7中显示的数据可知,在相同的运算时间内,本文模型进行了更多次数的搜索和运算,在0.4 s时,本文模型已经进行了40次左右的运算搜索,而此时基于拟牛顿法的并行模型的搜索次数大约是28次,粒子群算法的并行模型的搜索次数更少,只有19次左右。
由此可见,本文设计的基于偏微分的非线性代数方程组并行模型具有更快的计算速度和更高的运算精准度,能够提高非线性代数方程组并行求解的运算成功率,从而促进整体运算工作效率的提高。由此可以证明,本文模型在目前的非线性代数方程组求解运算方面具有更强的竞争优势,有利于促进大数据运算处理技术的进一步发展。
3 结语
在对基于微偏分的非线性代数方程组并行模型进行降噪处理时,面临的难点不仅仅是处理数据的边缘性,还有数据错误冗余的问题。将不具备正常格式的数据直接销毁,既可以减少模型的计算量,又提高了模型的计算精度。经过实验证明,本文设计的基于偏微分非线性代数方程组并行模型可以提高计算机的处理速率,相信以本文的论证作为研究基础,结合实时的数据计算算法,能够在一定程度上促进非线性代数方程组并行模型的发展。
