基于CNN-LSTM 网络的在线多任务销售预测模型
2021-11-03张顺香
王 旭,廖 涛,张顺香
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
销售预测是指可以通过历史存储的销售数据,分析出数据之间存在的关系或者数据的发展趋势,然后运用数学方法构建出针对指定销售问题的销售预测模型,最终预测公司未来几年的销售情况[1];因此预测是企业对供应链和运营过程进行优化时必要的一步[2-3]。
除此之外,在现实世界中具有时间序列特点的数据随处可见,甚至遍布于各行各业。根据数据时间序列的特点,找出这些序列的发展特性,再从中提取出精准的信息,有助销售预测模型的构建[5]。因此,时间序列预测不仅在工业尤为重要,而且在学术界亦是如此。Adhikari 等[6]人指出“研究人员做了很多努力来开发有效的模型,并想以此来提高时间序列的预测精度”。
然而,由于进行销售时间序列预测时,预测场景往往会发生变化,但研究人员却没有充分了解每种方法的局限性和适用性。近一步说,这些销售预测模型的通用性差,特别是在进行多任务、长时间销售预测的情况下,因使用不适用于给定时间序列的方法进行预测可能会导致企业季度或年度战略的失败[7]。针对这个问题,本文通过构建CNN-LSTM 网络的销售预测模型,将长短期记忆网络(long short-term memory,LSTM)和卷积神经网络(convolutional neural networks,CNN)网络结合起来,在保留LSTM 网络可以长距离记忆抽取特征的基础上,加入的CNN 网络能更深层地识别时序数据的特征,从而以最小的信息损失进行建模。并且在整个模型训练过程中加入在线闭环调整方法,能够根据预测结果与真实值之间的误差,动态的调整模型,以确保预测模型的效果长期保持高精度,进一步提升销售预测模型的预测效果。实验表明,基于CNN-LSTM 网络的在线多任务销售预测模型取得了较好的效果。
1 相关工作
在过去的几十年里,管理者及研究人员通常会采用HW(Holt-Winters model)、神经网络、ARIMA(auto-regressive integrated moving average model)等方法进行相关的销售时间序列预测[8],在少量数据和特定的预测任务背景下,这些预测模型让预测误差保持在可接受的范围内。Andrew等使用79 个月的餐馆销售数据,将计量经济学方法与时间序列方法进行比较。他们的结果表明,SARIMA 方法在初始期和七个月的预测期都有更好的表现[9]。然而,这项研究只针对一家餐厅,并没有对多任务时间序列预测任务进行总结。Makatjane 等使用南非19 年的月度汽车销量数据,发现HW 相对于SARIMA 方法具有更强的预测能力[10]。Udom 使用移动平均法、HW 法和SARIMA 法对塑料行业中单个分销商的五种不同产品的销售额进行了预测,并以MAPE 为评价指标,发现SARIMA 方法对销售额的预测效果较好[11]。姜晓红以某电商平台数据为例,运用时间序列法ARIMA 模型预测各种商品在全国和区域性未来一周的需求量;并与简单移动平均法预测结果做对比,发现ARIMA 模型有更高的精准度[12]。Frank 等人采用单季节指数平滑法(single season exponential smoothing model,SSES),HW和ANN(Artificial Neural Network)用于女装销售预测[13]。他们发现神经网络显示出令人满意的拟合优度统计量,但在比较实际销售和预测销售方面,HW 方法表现的更好。早期机器学习中的神经网络无法利用内部记忆的特点对序列数据进行处理,其无法在长距离范围内捕获时间序列的特征,例如循环神经网络(recurrent neural network,RNN)有时会出现梯度消失和长期依赖的问题。
虽然以上文献均采用销售数据进行预测,但得出的结果并不一致。在对不同的时间序列进行建模时,各种方法能够取得的性能通常会和数据中的时间维度特征相关,而随之各种优化后的机器学习算法在预测任务上通常会展现出比传统模型更高的预测性能时,更多的人选择用这些方法来处理时间序列数据。黄鸿云基于改进的多维灰色模型(GM(1,N))和神经网络来预测销量,其中多维灰色模型对销售数据建模,神经网络对误差进行校正,并通过对阿里天猫销售数据来评估混合模型的表现[14]。张文雅通过网格搜索方法优化了支持向量机的超参数,并用汽车销售数据来对优化后的算法进行了验证,根据结果可以发现优化后的算法拥有更好的预测性能[15]。王辉等利用Stacking 集成策略能够融合多机器学习算法的优点,将各算法结合,结果发现,Stacking 模型取得了比单个模型更高的精度和泛化能力[16]。罗嗣卿通过DBSCAN 算法解决了K-means 算法对噪声数据敏感的问题,并结合ARIMA 模型以蓝莓干销售数据验证了改进后的算法的精确性[17]。从上述研究可以发现,虽然优化后的机器学习算法应用于当前模型预测研究领域已经取得了较高的精度和泛化能力,但还存在结果难以解读,且针对不寻常的数据组,结果可能无用等问题。
在近几年时间内,深度神经网络中的LSTM在时序预测上显示出了强力的性能[18-19],为了验证LSTM 网络是否能够取得比传统模型更好的预测效果,Weytjens 等人还将SARIMA 和Prophet 与ANN 和LSTM 方法进行比较,研究以预测现金流为任务场景[20]。在研究中引入了一种新的绩效衡量方法,即利益机会成本(Interest Opportunity Cost,IOC),并利用IOC 作为成本函数对模型进行评价,最终得出结论:LSTM 是预测现金流的最佳方法。而在多任务预测中,Yu 等使用LSTM 方法预测销售情况,他们分析了66 种产品在45 周内的数据[21]。研究结果表明LSTM 为66 种产品中的17 种提供了准确的预测,而并非全部数据。由于考虑到这些数据几乎没有季节性这一特点,单用一个LSTM 网络进行多任务的销售预测会面临时间序列长度不够的情形,究其原因,是单个LSTM 网络并不能稳定地识别序列数据中的时序特征。
以上的研究工作虽然为离线场景下的销售预测提供了可靠方法,但随着云计算、分布式数据库存储技术的发展,企业往往会要求模型能够进行实时在线预测。并且,随着企业推广能力的增强,企业的营业点会分布在各个范围内,要求模型要能够进行在线的多任务预测,这使得模型要能够高效地识别出时序数据中的深层次特征,即数据的时空相关性。为适应这一场景,本文提出并且设计了一种基于CNN-LSTM 网络的在线多任务销售预测模型。该模型能够高效识别出时序数据中的深层次特征,以最小的信息损失来进行建模,并且根据预测结果与实际结果的差值进行动态的调整模型,以确保预测效果长期保持高精度。
2 基于CNN-LSTM 的在线销售预测
2.1 CNN-LSTM 网络模型
CNN-LSTM 网络由CNN 和LSTM 共同串联组成,如图1。
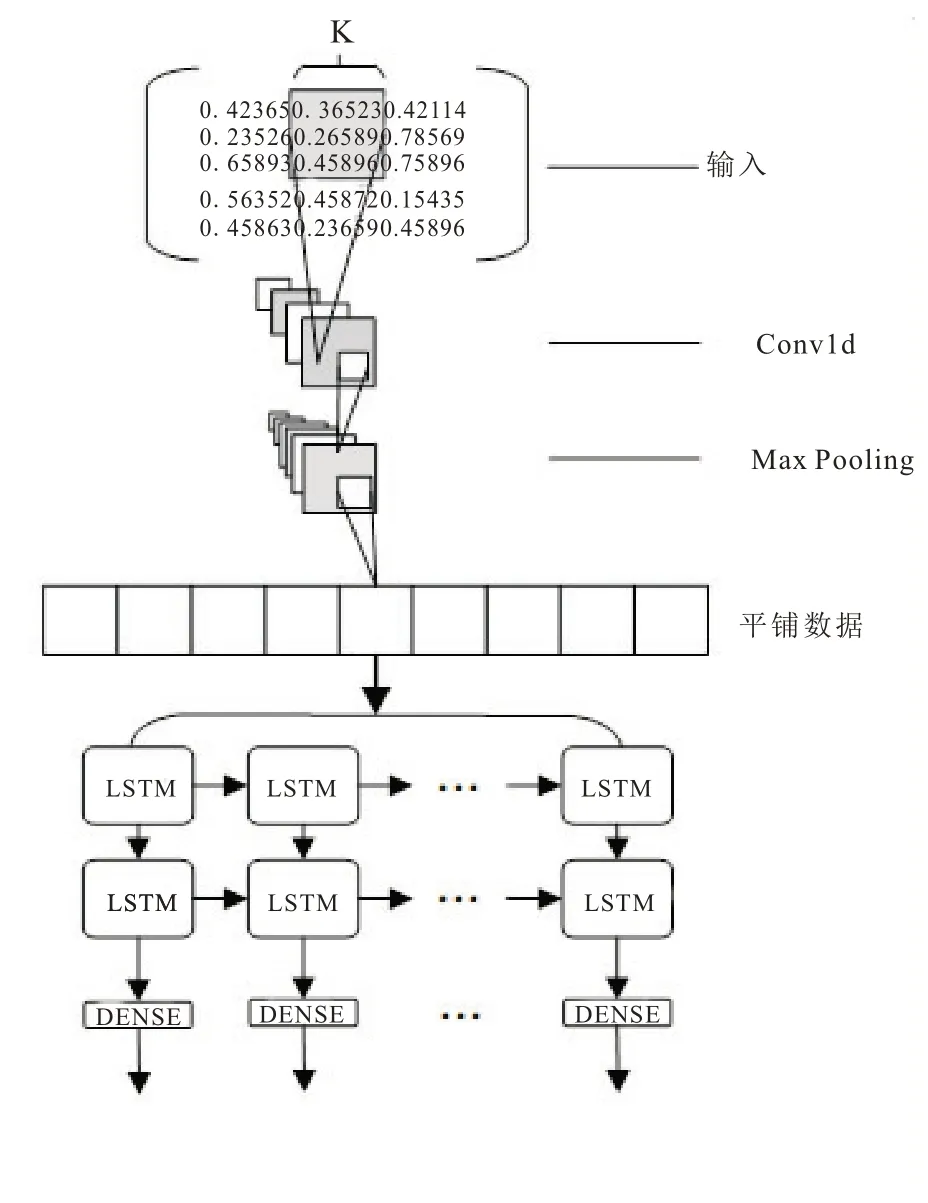
图1 CNN-LSTM 模型架构
模型能从滑动窗口与预处理后的时间序列数据中提取复杂特征,用于销量预测,并能记忆复杂的不规则趋势。模型的底层由CNN 组成,用来提取时序数据结构中的特征;LSTM 使用经CNN 层处理后的特征向量以及对应的目标向量作为输入,经过LSTM 得到的输出作为全连接层的输入,最终得到预测结果;通过对比模型在训练集和测试集上的损失,取得迭代后的模型作为最终模型来预测。
2.2 模型理论
设X={x1,x2,…,xn} 为包括了时间信息的CNN[22]的输入向量。
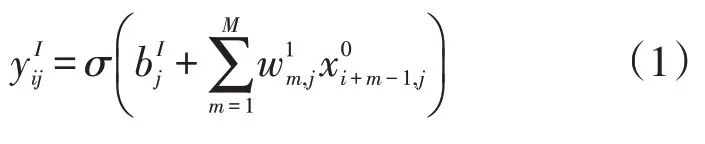

由于模型中CNN 的卷积层设置了三层,而卷积层参数误差容易造成估计均值的偏移,所以CNN 网络的池化层采取最大池化方式,从而减少这种误差。如式3,其中T、R分别为Pooling 窗口的滑动步长以及输出矩阵。池化层的优点在于不仅能够有效地减少过拟合的可能性还能减少计算量从而保留更多纹理信息,同时提取时间信息中更高维的信息。

LSTM[23]是CNN-LSTM 的下层,存储关于通过CNN 提取重要特征的时间信息。来自前一CNN 层的输出值被传递到门单元,门单元由输入,输出和遗忘门组成,并用于通过乘法运算确定每个单独存储器单元状态的机制。构成LSTM 的存储器单元通过激活每个门控单元来更新它们的状态,其被控制为0 和1 之间的连续值,其隐藏状态ht每t步更新一次。

式(4)、(5)、(6)表示了LSTM 的输入门、遗忘门和输出门,每个门的输出由符号:i,f和o表示。式(7),(8)表示通过输入,遗忘和输出门确定的单元状态和隐藏状态,它们用c和h表示。W是每个门单元的权重矩阵,b是偏置。Pt包含时间信息的关键特征作为池化层在t时刻的输出并用作LSTM 存储单元的输入。通过LSTM 来为CNN-LSTM 网络模型进行时序建模能够提供比传统的RNN 模型更好的预测性能。表示逐点乘积。
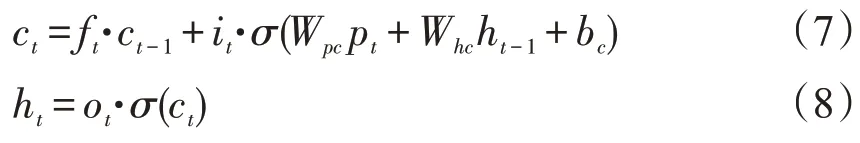
2.3 基于闭环调整的在线学习方法
又由于信息化技术在企业中的应用非常广泛,这使得企业的销售数据能够快速更新,帮助模型根据线上的反馈数据,实时快速地进行模型调整。区别于离线学习模型,在线学习是一种模型的训练方法,本质上是基于反馈的权重调整机制。
在线学习模型的训练流程包括:将模型的预测结果展现给管理者,并暂时存贮在缓冲区,然后收集用户的反馈数据,再用来训练模型,从而形成闭环的系统。在线学习的原理与自动控制系统相似,但又不尽相同,二者的区别是:在线学习的优化目标是将整体的损失函数最小化,而自动控制系统则是要求最终结果与期望值的偏差最小。多数学者提出的预测模型的训练方法大都是静态、离线的,不会与实时采集的数据状况有任何交集,虽然可能在某一段时间内取得的预测效果好,但不能确保预测效果长期的保持高精度。而在线学习模型的训练方法则不同,其会根据线上预测的结果动态的调整模型。如果模型预测错误,本身会及时做出修正,该方法与模型之间的交互流程如图2 所示。
首先,初始化模型参数的权重,根据滑动窗口算法选取训练样本实例,使训练样本持续到来,从而减少过多样本带来的阻塞。第二步,使用实时训练的模型预测出当前结果,做出相应的决策。第三步,将预测值和实测值进行比较,依据损失函数得出误差(loss)。第四步,利用损失函数的梯度更新当前的决策,反向传播更新模型的权重,直到损失值很小或者不再下降,即当损失函数是连续凸函数时,在线梯度下降可以达到最优。
3 实验分析
3.1 数据准备
实验数据来自宁波M 公司在电商平台上的真实数据,企业提供了从2015 年1 月1 日至2019年8 月31 日10 家商店的50 种商品共913000 条销量时序数据。目的是预测出2019 年9 月1 日到11 月30 日的每个店铺中每个商品的销量。预测评价指标采用平均绝对百分比误差(Symmetric mean absolute percentage error,即SMAPE)来 衡量,其计算公式为:

3.2 数据处理
首先对收集来的真实数据先进行去符号,去标签等预处理进行数据清洗;对于CNN 网络来说,首先输入数据要能够包含年、月、周、日的时间信息以及对应的销量信息作为特征;其次LSTM 的输入数据要包含一定时间间隔内的过去的销量,这个时间间隔可以是多步,也可以是一步。考虑到不同年份之间销量的线性关系,将时间间隔设置为一步,即生成对应时间过去一天的销售数据,数据处理的完整流程如下:

表1 模型输入数据处理流程
处理完成后的数据共有1826 行,1019 列。将时间信息与过去一天的销售量信息共519 列作为输入数据。其中,item_i_store_j_sales 代表商店j中商品i 的销量。
此外,由于数据的输入将采用追加方式将其在训练的过程中不断地输入到CNN-LSTM 模型中来进行模型调节。由于神经网络的数据输入会造成一定的抖动,所以采用滑动窗口算法来消除这种抖动,定义窗口大小为N,步长n,时间间隔T,窗口中的第一天为θ。具体流程为:选取时间跨度为N 的数据量输入到模型中并训练模型,当时间间隔不变时,就执行N=N-θ+n(窗口滑动),并以此循环往复。本次实验的初始阶段选取窗口大小为7 天,步长、时间间隔为1 天。在实际的程序设计中,由于滑动窗口模块被封装,因此使用者只需改变全局变量即可。其具体流程如下图:

图3 基于滑动窗口的数据输入机制
3.3 CNN-LSTM 模型参数设置

表2 CNN-LSTM 网络参数选择
在CNN 全连接层中,为了防止模型过拟合,使用dropout 策略来调整参数,并将保留概率设置为0.2。实验通过观察验证集上的误差以及使用网格搜索方法来确定最终模型的超参数,表5 按网络结构顺序展示了各层的参数选择。
3.4 CNN-LSTM 模型与单一LSTM 模型的预测误差比较
本文用CNN-LSTM 模型与单个的LSTM 模型进行预测误差的对比,还分析了在训练过程中加入的在线学习算法,证明其为模型的预测效果带来的提升。
表3 显示了部分混合模型、单一模型的预测值以及真实值,真实值为数据中2019 年相应时间的商品实际销售值。表4 显示了混合模型与单一模型在整个测试集上的SMAPE(平均绝对百分比误差)。

表3 混合模型与单一模型的部分预测结果

表4 混合模型与单一模型的SMAPE
从表3 中可以看出,相比于单一的LSTM 模型,CNN-LSTM 模型对产品销售的预测结果与编号1-5 的产品实际销量是最接近的,进一步验证了加入的CNN 网络的有效性。从表4 可以观察到,CNN-LSTM 网络在整个测试集上的误差比单一的LSTM 低了4 个百分点。当预测的数量或规模进一步增加时,误差的降低能够为企业减少供应链的成本。此外,为了体现在线学习算法为模型带来的预测性能的改善,实验随机抽取了10 号店铺的50 号商品作为观察目标,观察离线模型与采用在线学习的模型在不同时间跨度上的预测效果,如图4,图5 和图6 所示。
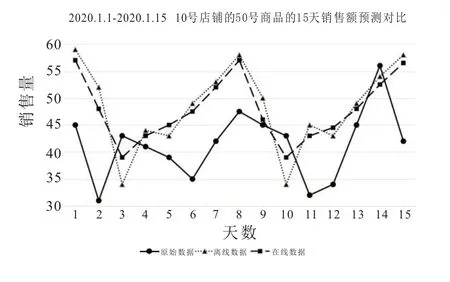
图4 时间跨度为15 天时的预测效果比较

图5 时间跨度为30 天时的预测效果比较

图6 时间跨度为60 天时的预测效果比较
可以明显的观察到,使用在线学习方法后,模型在三个时间段上预测的误差在大部分的时间内要小于离线模型所预测结果的误差。虽然在短期预测时,两者都未取得良好的预测效果,但是由于缺乏更多维度的特征,一些时序点可能是异常值或者是商店进行了对销售影响大的活动,例如周年庆或者节假日打折促销。同时,混合模型在长时间预测效果上显示了准确的趋势,因此对于模型在异常值上表现不佳的情况,可以视为模型并没有产生过拟合的情况或者模型的鲁棒性很好;除此之外,管理者通过自身的运营经验也可以设置一个置信区间来弥补缺陷。
3.5 CNN-LSTM 模型与其他模型的预测误差比较
为了证明CNN-LSTM 模型比其他方法具有更好预测性能和泛化能力,实验不仅比较了混合模型与单一LSTM 模型的预测性能,还与采用经济预测方法、回归预测方法以及机器学习方法进行了预测效果的比较,各模型在测试集上的SMAPE 如表5:
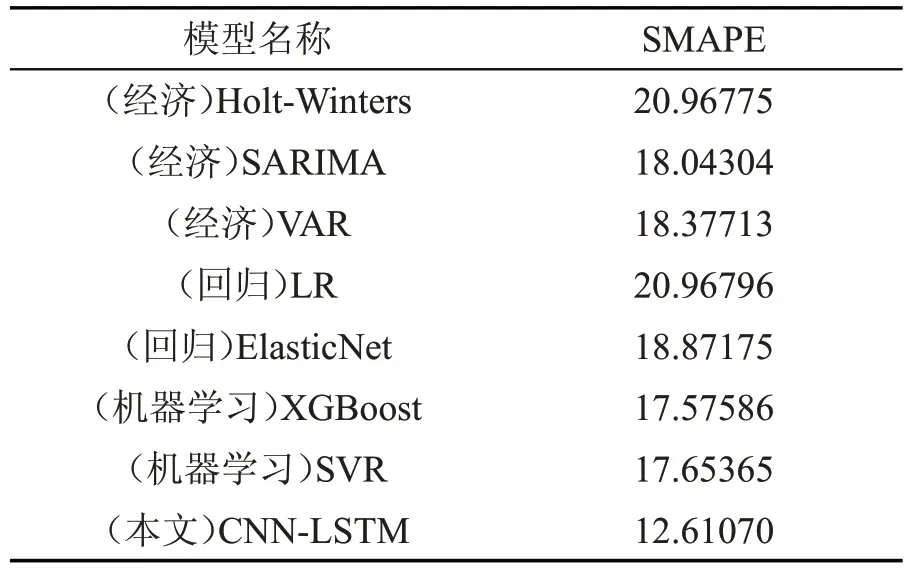
表5 其他模型的SMAPE
从表5 可以看到:模型Holt-Winters 与LR 取得的误差是所有误差中最大的,XGBoost 模型虽然取得了其中最小的误差,但是误差仍然比本文提出并使用的CNN-LSTM 网络模型要高。一方面是因为CNN-LSTM 模型能够高效地识别出时序数据中的深层次特征,即数据的时空相关性,提高实验结果的准确率;另一方面是因为本文使用的数据集经过一系列预处理,使得输入的数据格式更加规范,方便特征的提取。
4 小结
本文针对目前销售预测模型无法解决在线、多任务销售预测问题,提出了CNN-LSTM 模型,并在模型训练过程中采用闭环在线训练方法对模型进行进一步的调整。实验证明:CNN-LSTM 网络以最小的信息损失来进行建模和去噪,使得模型保留了更多的时间信息和规则,且模型更具可靠性;而在训练过程中加入的在线学习方法也使得模型在预测准确性上得以提高。实验以SMAPE 为评价标准来衡量模型的预测性能,结果表明:混合模型不仅取得了最小的误差,而且可靠性比单一的LSTM 模型更好,在辅助企业的库存管理、经营管理、供应链管理中有较高的应用价值。由于CNN-LSTM 模型总体的训练时间较长,因此在今后的研究中可以考虑将模型在分布式环境下进行计算。
