基于网格搜索优化的XGBoost 模型的股票预测
2021-11-03孙丽丽方宏彬朱星星胡蕾明齐龙武
孙丽丽,方宏彬,朱星星,胡蕾明,齐龙武
(安徽大学 经济学院,安徽 合肥 230601)
近几年机器学习作为人工智能领域一个重要的分支,以其强大的算法功能和学习能力被广泛应用于各领域的预测和决策工作任务中。目前已有大量学者利用机器学习来对金融时间序列进行分析和预测,如黄卿等为预测股指期货高频数据1分钟下的价格变动方向,使用了XGBoost(extreme gradient boosting)模型,实验证明了XGBoost 的预测能力要比SVM(support vertor machine)和传统的神经网络强[1]。另外有大量学者基于BP(back propagation)网络以及贝叶斯神经网络的学习和网络调参,将神经网络模型应用于股票预测,论证了神经网络很好地实现了股票价格短期预测[2-5]。Liu 等提出一种新的SVM 模型,使用灰色关联度计算权值应用到SVM 中,对特征加权,利用移动时间序列窗口对所有数据进行测试,实现了数据集的扩展[6]。大多学者着力于使用SVM 来构建股票预测模型,研究出一系列因子选股以及股票择时策略,应用到股票价格预测,实验证明其对股票市场有很好的预测性能[7-11]。王燕等使用网格搜索算法对XGBoost 模型进行参数优化构建GS-XGBoost 的金融预测模型,发现GSXGBoost 金融预测模型在股票的短期预测中具有更好的拟合性能。他们又提出了提出离散小波变换与优化的XGBoost 算法结合的股价预测模型(DWT-ARIMA-GSXGB)模型,用以预测金融时间序列数据,实验结果表明此模型的预测股票开盘价的预测值和实际值误差要小于其他四种对比模型(XGBoost,ARIMA,GSXGB,DWT-ARIMAXGBoost[12-14]。另有学者发现,传统的计量经济模型会假设随机扰动为常量,但很多实际研究发现这种假设并不严谨尤其是对金融领域而言,因此有学者研究了自回归条件异方差(ARCH)以及广义自回归条件异方差(GARCH)模型来刻画金融时序数据的波动集聚效应[15-17]。彭燕等利用LSTM(long short-term memory)递归神经网络预测股票走势,通过改变LSTM 层数以及LSTM 隐藏层神经单元个数进行训练测试,提高了预测准确率30%[18]。有的学者基于粒子群、特征选择以及遗传算法对LSTM 模型进行训练与调试,结果表明LSTM 模型能够对股票市场做出良好的预测[19-22]。近年来有不少学者将机器学习作为文本挖掘和自然语言处理的强大工具,并将其应用到股票的价格走势预测中,得到了较为准确的预测精度[2324]。
从已有研究成果来看,虽然有很多学者利用XGBoost 模型来对股票价格进行预测,但国内对此方面的研究甚少。鉴于此,本文创新性的利用网格搜索算法对XGBoost 模型进行参数优化,应用到股票价格预测中。
1 理论介绍
1.1 XGBoost 模型
XGBoost 是梯度提升算法GBDT(gradient boosting decision tree)的加强版本,它在优化目标函数时利用泰勒二阶展开式,并且在损失函数中增加了正则项用于控制模型的复杂度。XGBoost优化的目标函数如下:
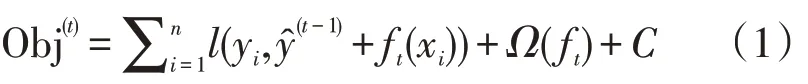
式中:Obj(t)表示第t次训练的目标函数;yi表示第i个样本的真实值;为第t-1 轮模型的预测值;l即为损失函数;ft(xi)表示输入为xi时第t轮的函数值;Ω(ft)为正则化项;C为常数。
利用泰勒二阶展开将(1)写为下面的形式:
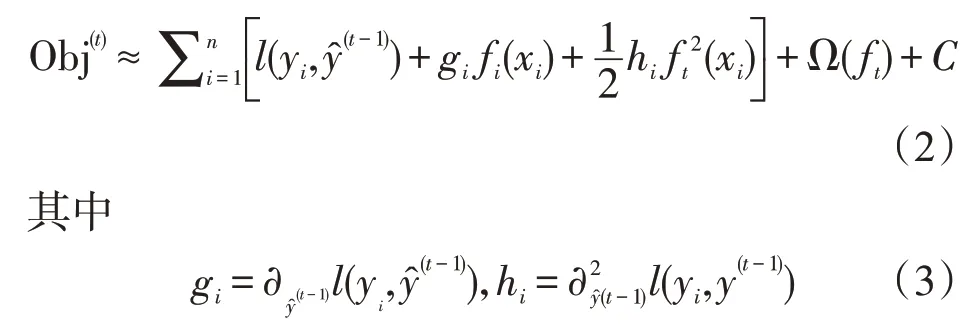
训练模型时,(2)可以用下式表示
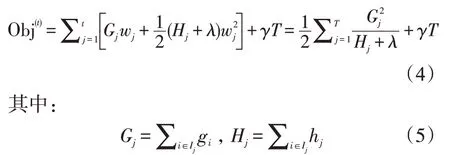
在(4)和(5)式中,Ij被定义为每个叶子结点j上面样本下标的集合Ij={q(xi)=j},q(xi) 表示为每个叶子上面样本的集合。这一步是由于XGBoost目标函数第二部分增加了两个正则项:叶子节点个数T和叶子节点的分数w。
1.2 网格搜索算法优化的XGBoost 的构建
1.2.1 GirdSearch-CV
网格搜索与交叉验证是一种穷举算法,将所有算法需要的参数可能取值列举成网格。参数值的各种排列组合自动选择出模型需要的最优参数组合,这种自动调参的机制需要评分机制来支持,就是交叉验证法。以3 折、5 折和10 折交叉验证最为常用。交叉验证会给每个参数组合进行打分,算法最终选择评分机制最高的那个参数组合进行建模。
1.2.2 GC-XGBoost 的构建过程
Step 1:获取股票数据,对数据进行清洗、插值等数据预处理工作;
Step 2:将数据分为两部分:训练集和测试集。首先进行XGBoost 模型建模,并将模型用于对训练数据进行训练,模型训练好将此模型对测试集数据进行测试,记录预测的评估指标值。此步即为XGBoost 原模型建模。
Step 3:同样用XGBoost 模型建模,但此时需要列举出XGBoost 所有参数的排列组合形成网格,然后进行的XGBoost 建模便是基于所有的参数组合,并且需要一种评分机制来给每种模型实施打分操作,此机制就是交叉验证的方法,最终选择出评分最高的那个参数组合的XGBoost 模型,也就是GC-XGBoost 模型(GridSearch-CV-XGBoost)。
1.2.3 GC-XGBoost 算法
GridSearch-CV-XGBoost 算法简称为GCXGBoost 算法。其步骤如下:
Step 1:数据清洗预处理;
Step 2:学习训练XGBoost模型;
Step 3:构建评分机制指标;
Step 4:网格搜索优化XGBoost模型参数,重新得到新XGBoost模型,即为GC-XGBoost模型
1.3 评估的指标
建立一个新的模型,需要评价其性能好坏。有很多可以评估股票预测模型性能的指标,常见的有三种:分别是用来衡量观测值和真实值之间偏差的均方误差MSE(mean squared error),反映预测值产生的误差大小的平均绝对误差MAE(mean absolute error)以及可用于比较不同量纲下模型性能好坏的R方值R2。本文选取这三个指标来综合评价以及对比模型。
MSE 是误差平方和除以样本量得到的,而误差平方和是线性回归模型的拟合过程中预测值和真实值之间的误差的平方和。这个值越小表示预测值与真实值越接近,拟合效果越好。MSE 的计算公式:
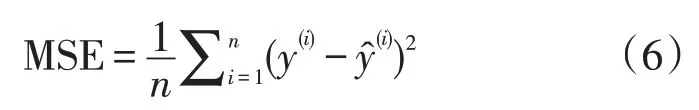
MAE 是绝对误差的平均值。为了避免误差正负抵消的情况发生,另外一种方法就是采用绝对值进行计算,能够将真实值与预测值之间的误差大小的情况较好的反映出来,其值越小,预测效果越好。计算公式:
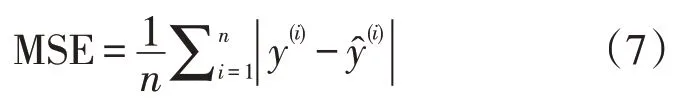
(3)R2是用来表示模型拟合效果的,值越大,表示拟合效果越好;值越小,表示拟合效果越差甚至判断出模型不合适。计算公式:
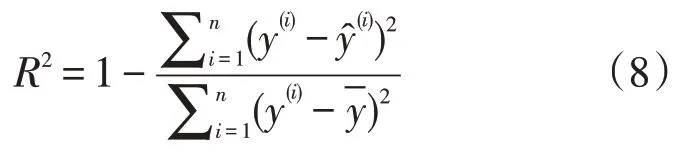
2 实证分析
本文实验所用的软件是python3.7,所用到的库和包有numpy,pandas,matplotlib,sklearn,xgboost 以及tushare 包。为了使模型预测股票价格更有说服力,本文选取了贵州茅台这只股票2001年8 月27 日至2020 年4 月17 日的每日开盘价、最高价、最低价、交易量以及收盘价等数据,以收盘价作为预测目标变量,共计4 448 个样本。所有数据通过python 自带的tushare 包下载。
贵州茅台是白酒行业中的一只看涨的股票,在前几年的价格一直是稳中上升的趋势,今年疫情期间,所有大盘指数看跌,股票行业持续亏损,几乎所有股票都暴跌很多个点。然而在这个突发的事件给所有股民带来不利影响的同时,贵州茅台的价格在此时却迅速攀升,较前几年的涨势更加迅猛,甚至疫情初期突破千元,股价走势长期看有一个明显的转折。此时用模型对此阶段的价格进行预测能够很好的反映了模型的预测能力。图1 贵州茅台的开盘价、收盘价、最高价和最低价整体走势。

图1 贵州茅台价格走势图
从图1 可以看出,茅台价格在2017 年之前一直都呈稳重上升趋势,最近几年价格涨势较猛,尤其今年疫情期间,突破至“千元茅台”,对这段时间价格经历的波折进行建模预测很有意义,可以验证模型是否能很好的拟合这段时间的价格走势。
图2 可以明显看到,在疫情期间茅台价格呈现了明显波动起伏趋势,但总体趋势是上升的。可以很好构建机器学习模型来对价格进行预测,验证其模型的预测性能。
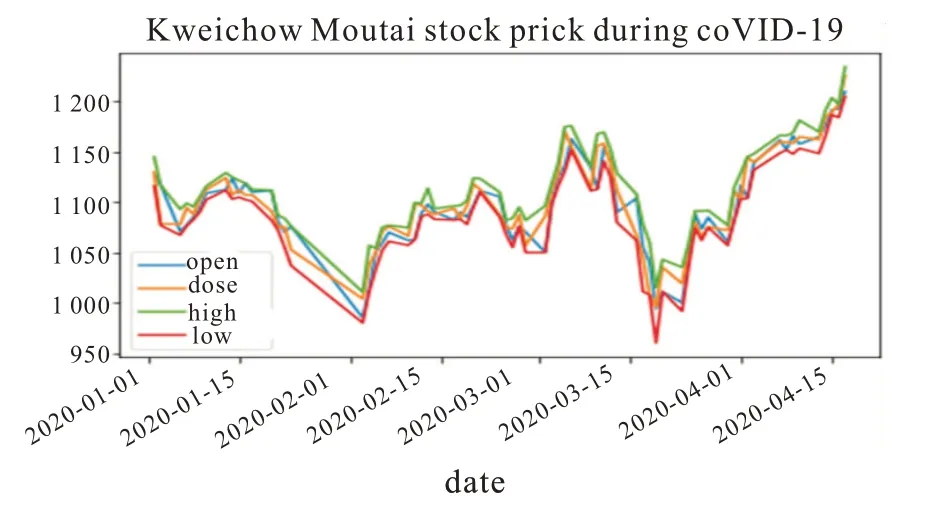
图2 疫情期间茅台价格走势
在构建GC-XGBoost 模型预测前,需要对数据进行插值,标准化等预处理,再把总共的样本数据集4 448 条记录划分成训练集和测试集两个数据集合。测试集选取后面连续30 天的数据,前面剩余的数据全部取出用来训练模型,将训练好的模型来预测最后30 天的价格,最后与真实价格作对比,给出模型各个评估指标的值来评价模型的预测性能。本次首轮实验采用的是默认参数的模型也就是XGBoost 原模型进行训练,用最后30天数据作为测试集进行预测,最后得到的实验结果如图3。
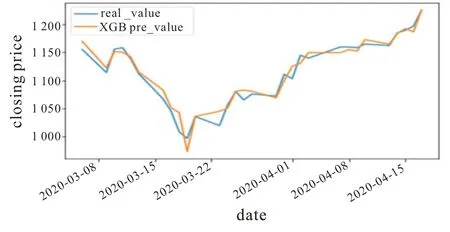
图3 XGBoost 原模型预测值与真实值对比图
从图3 可以看到,XGBoost 原模型整体上已经很好地拟合了股票价格的波动趋势,有少数的点预测结果较差。并且考虑到XGBoost 原模型采用的是预排序,在迭代前会对节点做预排序,遍历所有分割点,数据量稍大时耗时严重,并且很多叶子节点的分裂增益较低,没有必要继续进一步的分裂,这就带来了一些不必要的开销。因此,我们提出基于网格搜索的算法来自动学习到最优参数,降低占用内存以及数据分割的复杂度。为了进一步说明基于网格搜索的XGBoost 模型预测性能相较于原模型有所提升,现在将上述第一轮实验结果与GC-XGBoost 模型在股票预测中的性能进行比较,进行第二轮实验,通过两种模型的重要评价指标来评价模型的性能好坏。实验为保持数据的一致性,同样采用贵州茅台股票相同时间内的股票价格数据进行训练和测试,这里使用相同的股票训练数据集来训练基于网格搜索算法优化参数的XGBoost 模型,再用同样最后30 天数据作为测试集进行预测,最后得到的基于测试集实验结果如图4 所示。
在使用网格搜索算法和交叉验证法中,我们需要设置的XGBoost 模型重要参数有学习率,树的棵树数,树的深度,最小的叶子权重等等,这里得到最优参数学习率learning rate 为0.3,n_estimators 为100,max_depth 为8,min_child_weight为1,根据经验将CV 设置为3。从图4 可以看出,在经过网格搜索算法优化后的XGBoost 模型很好的追踪了股票价格的波动趋势,能够更好的拟合价格的趋势图,表明改进的模型XGBoost 预测性能有所提升。

图4 网格搜索优化的XGBoost 模型预测值与真实值
两轮实验中针对测试集得到两种模型实验结果评价指标的对比如表1 所示。
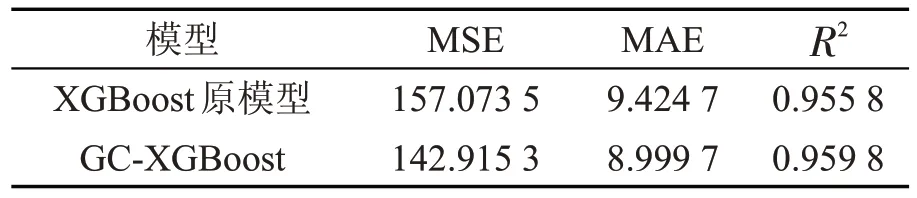
表1 贵州茅台收盘价的两种模型预测对比
对于MSE 和MAE,其值越小,表示预测的误差越小,结果越精确,模型就越好。对R2,其值越大,表明预测值与真实值拟合度越高,模型预测性能越好。从表1 可以看到,无论是XGBoost 原模型还是基于网格搜索算法改进的XGBoost 模型,对于前两个评价指标MSE 和MAE 都较小,后一个指标R2较大,接近于1,说明了这两种模型对于股票价格都有很好的预测能力,对于股票价格的走势拟合效果较好。同时,改良后的XGBoost 模型也就是GC-XGBoost 模型的MSE,MAE 相比较XGBoost 原模型更小,R2比XGBoost 原模型更大,说明基于网格搜索优化参数后的XGBoost模型的预测性能有了很好的提升,提出的GC-XGBoost 模型可以更好地实现对股票价格准确预测的目的。
3 小结
本文提出了基于网格搜索算法优化参数的XGBoost 模型,将其应用到股票价格的预测中,利用贵州茅台收盘价对模型性能进行实验验证,采用MSE,MAE 和作为评估指标,实验对比改进后的XGBoost 模型对于股票预测有很好的拟合能力,并且预测效果要优于XGBoost 原模型的预测性能,说明基于网格搜索优化参数的算法能够提升XGBoost 模型的预测性能。但是模型的预测性能总体提升度不高,后期需要结合其他方法在对数据的质量上进行改善,并且将改善后的模型应用于其他多种金融产品如股指期货上,进一步完善模型的稳定性,给更多股民带来有意义的投资参考意见。
