基于BERT 模型的安全生产事故多标签文本分类
2021-11-03吴德平王晓东
吴德平,时 翔,王晓东
1. 江苏安全技术职业学院网络与信息安全学院,江苏 徐州221011;2. 常州工学院计算机信息工程学院,江苏常州213002;3. 徐州市广联科技有限公司,江苏 徐州221116
安全生产管理是一项复杂而极其重要的工作,对安全生产事故全面剖析和研究十分必要。安全生产中的事故伤害可分为事故类别、伤害方式、不安全行为和不安全状况,利用自然语言处理(natural language processing,NLP)技术对安全生产事故及原因分类,为安全生产监管、事故隐患排查和分析奠定基础,对进一步强化安全生产指导具有重要意义。
以往文本分类通过利用稀疏词汇的特征来表示文本,再用线性模型进行分类。近年来,主要是采用深度学习得到文本的特征表示,如利用word2vec 模型学习文本中词向量的表示,得到文本的语义表示实现文本分类[1]。 又如利用TextRank 算法把文本分割成若干组成单元,构建节点连接图,用句子之间的相似度作为边的权重,通过迭代计算句子TextRank 值,抽取排名高的句子组成文本摘要[2]。采用长短时记忆网络(long short-term memory networks,LSTM)实现分类。
2018 年google 推出的基于转换器的双向编码表 征(bidirectional encoder representation from trandformers,BERT)模 型 在MultiNLI、SQuAD、SST-2 等11 项NLP 任务中取得卓越的效果。BERT 模型在大规模语料库或特定领域的数据集上通过自监督学习,进行预训练以获得通用的语言表示,在下游任务中进行微调完成相应的任务。BERT 模型的缺点之一是使用词向量表示文本内容时,最大维度为512。当输入文本长度小于512时,模型性能良好。BERT 是句子级别的语言模型,该模型能获得整句的单一向量表示。BERT 预训练模型对输入文本进行向量化,能有效提高中文文本语义的捕捉效果[3-4]。
安全生产事故报告或案例文本通常都有事故单位的情况、事故发生经过、应急处理情况、事故原因分析、事故责任认定、事故处理意见等内容,文本从几百字到数万字不等,内容长短不一,由于BERT 模型支持的最长序列字数为512,需要对原始文本进行处理。本文结合安全生产事故的文本特点,先对文本进行摘要处理,再利用BERT 模型进行多任务分类,实现安全生产事故分类水平的提升。
1 相关工作
1.1 文本摘要方法
文本摘要方法主要为抽取式摘要和生成式摘要,抽取式摘要方法根据单词和句子的特征从文档中选择核心语义句,并将它们组合以生成摘要,句子的重要性取决于句子的特征统计。抽取式摘要最大化地保证摘要内容来自于原文,避免生成不准确甚至是错误的信息。抽取式摘要的缺点是抽取对象是文本中的句子,当要抽取的数值确定时,会有正确的摘要句没被抽取,造成摘要内容的丢失,而被抽取的摘要内容也会有一定的冗余。生成式摘要则使用了一系列自然语言处理技术,用于理解给定文档中的主要内容,生成更加简明精炼的句子来构成摘要。生成式摘要与抽取式摘要相比,摘要更准确,更灵活,更符合编写习惯。结合安全生产事故文本较长的特点以及BERT 模型对算力较高的要求,本文采用抽取式+生产式摘要相结合的方法完成文本的摘要。
1.2 基于BERT 模型的中文长文本处理及分类
对于长文本的处理,一般分为3 种方法:截断法,Pooling 法,压缩法。截断法大致分为头截断、尾截断、头+尾截断3 种。截断的比例参数是一个可以调节的参数。Pooling 法将整段的文本拆分为多个片段,进行多次编码。压缩法是在断句后将整个篇章分割成片段,通过训练小模型,将无意义的片段剔除,如剪枝法、权重因子分解法、知识蒸馏法等方法。
为提高处理效率,本文采用截断法,对原始文本首先按照头+尾截断,然后去停用词,进一步精简文本,最后构建数据集。针对中文长文本摘要和多标签分类的难点,设计分3 步实现多标签分类:第一步使用基于BERT 预训练模型实现抽取式文本摘要;第二步使用基于华为的中文预训练语言模型——哪吒训练模型实现生成式文本摘要;第三步通过基于精简的BERT(a lite bidirectional encoder representation from transformers,AlBERT)训练模型,借助迁移学习的思想进行多标签多任务分类,最终在数据集上取得了较好的多标签分类效果[5-6]。
2 文本摘要模型及实验
2.1 抽取式文本摘要模型
抽取式文本摘要,生成摘要不连贯、字数难以控制、目标句主旨不明确。而BERT 预训练模型能在一定程度上克服以上缺点。BERT 模型应用于具体领域的任务是通过使用预训练和微调实现,预训练的目的是在输入的词中融入上下文的特征,微调的目的是使BERT 适应不同的任务。其创新点在于将注意力模型Transformer 的双向训练应用于NLP,经过双向训练的语言模型比单一向语言模型能更好地理解语言环境和流程。BERT 中文长文本摘要模型如图1。
模型中数据集经过分词并添加一些标识符。在第一个句子前面添加[CLS]标识符,借助首句最前面的特殊符[CLS],用来分类输入的两个句子间是否有上下文关系。每个句子的最后添加[SEP]标识符,起到分割句子的作用。整个模型结构通过BERT 接一个平均池化层得到句子向量[7],即通过预训练获取一个句子的定长向量表示,将变长的句子编码成定长向量。Average pooling 主要对整体特征信息进行抽取,local 主要是对特征映射的子区域求平均值,然后滑动这个子区域。模块间采用average pooling 既能在一定程度上减少维度,更有利于下一级模块进行特征提取。利用膨胀门卷积神经网络(dilate gated convolutional neural network,DGCNN),它是基于CNN+ Attention的高效模型。Attention 用于取代池化操作来完成对序列信息的整合。Dense 层将前面提取的特征,经dense 层作非线性变化,再映射到输出空间。对于图1 中的句子对,句子的特征值是1,则保留的摘要,句子的特征值是0,则该句舍弃,从而达到文本抽取式摘要的目的。
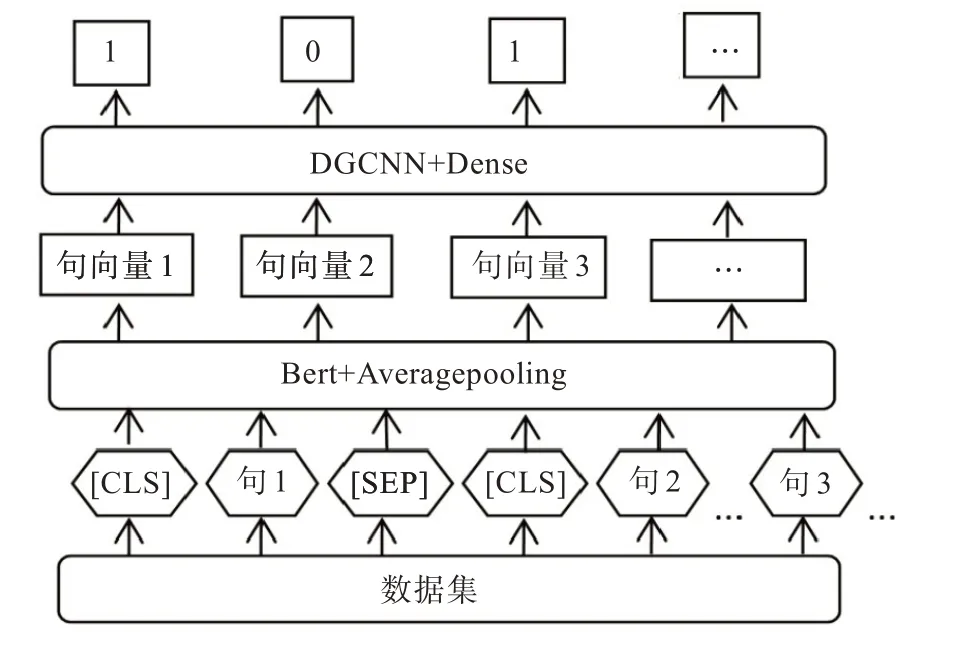
图1 抽取式文本摘要模型Fig. 1 Extractive summarization model
2.2 生成式文本摘要模型
为了进一步减小文本的长度,通过抽取式模型输出的摘要,再作为生成式摘要模型的输入,最终生成输出得摘要。 生成式摘要通过改进型BERT 来实现,模型如图2 所示。BERT 使用的是训练出来的绝对位置编码,有长度限制,为便于处理长文本,采用基于华为的NEZHA 预训练语言模型,利用改模型相对位置编码,通过对位置差做截断,使得待处理词、句相对位置在有限范围内,这样,输入序列的长度不再受限,处理后的语句再通过生产式指针网络(pointer generator networks,PGN)模型生产摘要。 PGN 模型[8]可视为基于attention 机制的seq2seq 模型和pointer network 的结合体,该模型既能从给定词汇表中生成新token,又能从原输入序列中拷贝旧token,其框架如图2 所示。图2 中原文本中各token 的Wi经过单层双向LSTM 将依次得到编码器隐藏状态序列,各隐藏层状态表示为Ht。对于每一个时间步长t,解码器根据上一个预测得到单词的embeding,经LSTM 得到解码器隐藏层状态St,为了在输出中可以复制序列中的token,将根据Ht,St和解码器输入Xt计算生成概率:

图2 生产式文本摘要模型Fig. 2 Abstractive summarization model

式(1)中,WTh、WTs、WTx、Bptr均为 模型要 学习的 参数。Pgen的作用是判断生成的单词是来自于根据Pvocab在输出序列的词典中采样,还是来自根据注意力权重ai,t在输入序列的token 中的采样,最终token 分布表示如式(2):
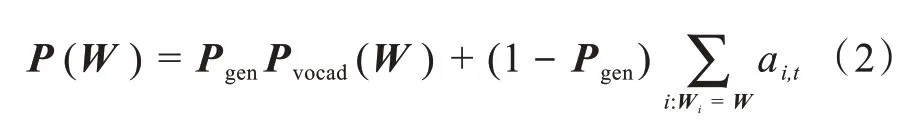
其中i:Wi=W表示输入序列中的token 的W,模型会将在输入序列中多次出现的W的注意力分布相加。当W未在输出序列词典中出现时,Pvocab(W)=0;而当W未出现在输入序列中时,

显然,该模型基于上下文向量,解码器输入及解码器隐藏层状态来计算生成词的概率p,对应Copy 词的概率为1-p,根据概率综合编码器注意力和解码器输出分布得到一个综合的基于input 和output的token 分布,从而确定生成的语句。
2.3 文本摘要实验及讨论
实验对2 000 个20 种事故类别的案例集进行处理,采用基于召回率的摘要评价(recalloriented understudy for gisting evaluation,ROUGE)作为评价指标,以衡量生成的摘要与参考摘要之间的“相似度”,采用ROUGE-1、ROUGE-2和ROUGE-L作为标准,即计算一元词、两元词及最长公共子序列的重叠程度。本文提出的模型在训练集上得到ROUGE 评价结果如表1 所示,同时还给出了其他模型的ROUGE 结果[9-11]。
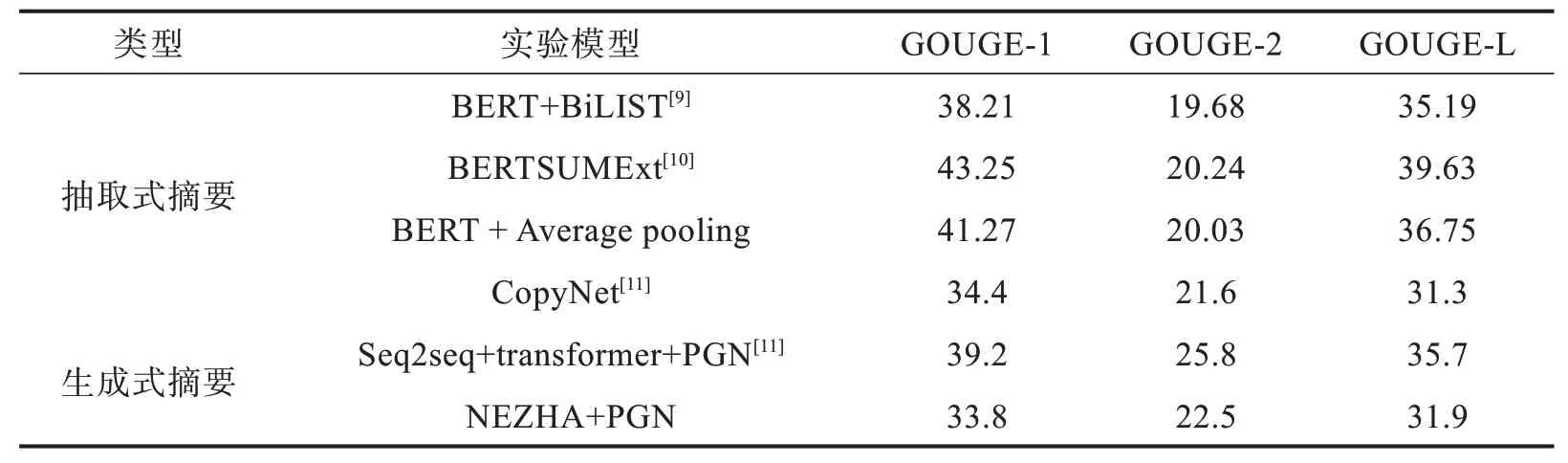
表1 不同模型实验结果对比Tab. 1 Comparison of experimental results of different models %
第一个抽取式模型BERT+BiLIST 是将BERT预处理后的文本向量经过一个基于规则的基本篇章单元识别模型,再经过基于Transformer 的神经网络抽取模型,生成最终的摘要。第二个抽取式模型BERTSUMExt,将多层Transformer 应用于句子表示,从输出中抽取文档特征,再经LSTM 层学习特定摘要特征。本文抽取式中文摘要采用的NER 模型式chinese_L-12- H-768_A-12 预训练模型,通过BERT + Average pooling 计算文本向量表示,最后通过CNN+ Attention 的模型抽取摘要。
第一个生产式摘要模型CopyNet 通过深度递归生成解码器的Seq2seq 模型,利用递归学习目标摘要中隐含信息来提高摘要质量。第二个生产式摘要模型Seq2seq +transformer+PGN 采用基于自注意力的transformer 机制,组合指针生成网络input-feeding 方法。本文生成式中文摘要采用华为的NEZHA 预训练语言模型,经过基于attention机制的Seq2seq 模型生产摘要。
实验数据如表1 所示,本文提出的模型较其他模型相比,最终结果相差不大,一方面,其他模型的评价结果当前已达到很高水平[12],另一方面,采用的数据集存在的差异,包括中文和英文差异,也存在不同领域之间的差异。同时,考虑到算力等因素,本实验采用的两个模型能够提取文本的关键信息,为长文本进行多标签分类提供可能。
3 文本多标签分类及实验
多标签分类就是要将安全生产的事故案例标记为物体打击、车辆伤害等20 类事故类别之一;碰撞、爆炸等15 种伤害方式之一;防护、保险等装置缺乏或缺陷等4 大类不安全状态之一;操作失误等13 大类不安全行为之一,共有52 个标签。
3.1 分类模型
多标签文本分类ALBERT 预训练模型,该模型最小的参数只有十几兆字节,能较好解决模型参数量大、训练时间过长的问题,效果比BERT 低1%~2%。同时,在没有足够的安全生产类标注数据的情况下,采用迁移学习来提高预训练的效果。本文采用基于样本的迁移学习方法,模型如图3 所示。模型主要通过自制的安全生产事故数据集对模型进行预训练,建立分类精度较高、特征提取能力强的学习模型。TextCNN 模型能有效抓取文本的局部特征,经过不同的卷积核提取文本信息,再通过最大池化来突出各个卷积操作,从而提取特征信息,拼接后利用全连接层对特征信息进行组合,最后通过binary crossentropy 损失函数来训练模型,将标量数字转换到[0,1]之间,再对52 个标量分组分类。

图3 多标签文本分类模型Fig. 3 Multi-label text classification model
3.2 分组分类算法及实验
当前多标签的学习算法[13-15],按解决问题的方式可以分为基于问题转化法和基于算法适用法两类。问题转化法通常只考虑标签的关联性。而考虑多标签的相关性时可将上一个输出的标签当成下一个标签分类器的输入。对于事故类别、伤害方式等52 个标签,若采用类似于二分类方法,所有标签将分布在[0,252-1]空间内,数据会很稀疏,耗费大量资源。因此,采用基于算法适用法来实现多标签分类算法。设置TextCNN 参数字长为300,卷积核数目为256,卷积核尺寸为5,标签为52。再利用tf.argmax()对模型训练获得的52 个标量,求得4 组列表[0,19:1]、[20,34:1]、[35,38:1]、[39,51:1]中最大数的索引,最后映射到相应标签即可,分类结果如表2所示。可以看出,同一事故类别的标签数越多,分类的准确率越低。另外,考虑算力的因素,本文安全生产事故文本数据集数量上相对偏少,也导致分类准确率不够高。
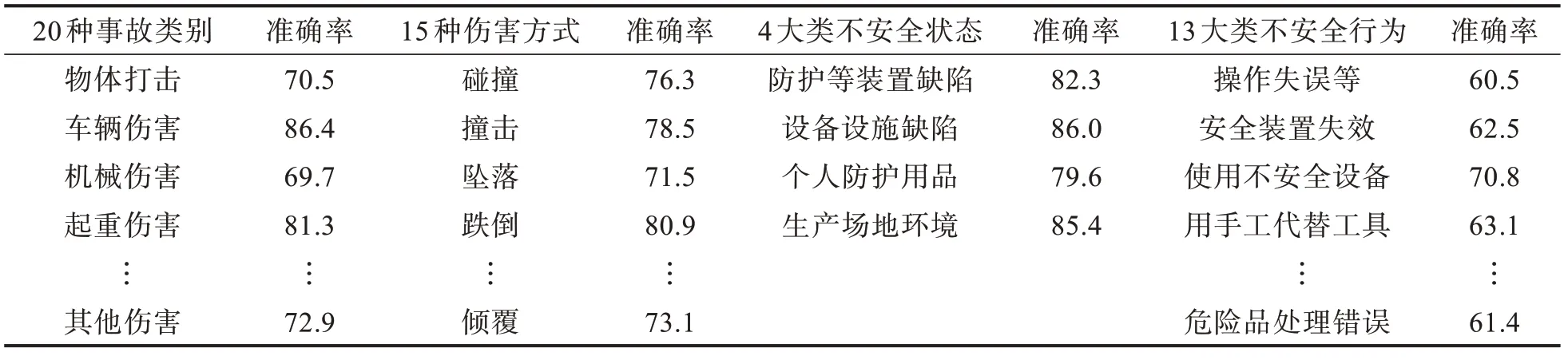
表2 多标签分类准确率Tab. 2 Multi-label classification accuracy %
4 结 论
目前,虽然在一定程度上实现了安全类中文长文本的多标签分类,但数据集的构建需要做大量的工作,事故伤害类别多,成因复杂,要做好安全生产伤害事故及原因的文本分类,还面临不少挑战。数据是研究的基石,只要进一步完善大规模、高质量的数据集,优化各种模型及参数,就能进一步提升文本分类准确性。
