网络服务DDoS攻击主动防御框架
2021-11-02柴新忠龚梦瑶
柴新忠,李 凯,龚梦瑶,赵 原
(1.上海中船船舶设计技术国家工程研究中心有限公司 基础设施部,上海 200235; 2.中国船舶及海洋工程设计研究院 军船二部,上海 200021)
0 引 言
动目标防御(MTD)[1-4]是一种主动防御技术,其通过主动洗牌,可以在真正的攻击行为启动之前破坏网络攻击链的初始阶段。例如,最具代表性的动目标防御方案MOTAG[5]提供了一种针对在线服务的洗牌方法。MOTAG机制被部署在代理服务器中,使外部攻击者对不断变化的IP地址感到迷惑,并通过快速筛选和屏蔽恶意用户,使得流量在网络边界处得到净化。在此基础上,文献[6]根据会话请求的强度,选择性的将切换速度加快或者减慢,通过coupon-collecter模型建模所有间谍被筛选出的概率,文献[7]通过负载均衡器实现对用户的认证,文献[8]增加了用户批量迁移功能。此外,使用软件定义网络(software defined network,SDN)[9]等新技术的相关研究也在不断增加,推动了MTD的发展。通过主动的周期性重映射,文献[10]构建用户与主服务平面之间的间接控制平面。文献[11]应用双代理零和博弈,避免DDoS攻击或代理收割攻击。文献[12]将协作和自学习的跳变概念引入到动目标防御中。在入侵行为感知的基础上,最大化防御系统的策略空间和不可预测性。
尽管动目标防御为受保护的网络对象提供了安全防护,但是与静态防御手段相比需要更频繁地进行切换,因此也将高消耗引入到系统中[13,14]。安全防护和资源消耗之间的平衡让防御者陷入了两难的局面,阻碍了动目标防御的大规模应用。很少有研究关注提高动目标防御的适应性和成本效益的方法。
针对上述问题,本文提出了一种动态洗牌周期的主动防御框架,命名为DQ-MOTAG。在模型中,量化了动目标防御的运行成本和安全性能之间的权衡。提出了一种基于深度强化学习的算法,为洗牌周期提供学习管理和敏捷调整。通过基于实时威胁分析的迭代更新,细粒度洗牌策略以经济的方式收敛到足够的安全性。在阿里云中实现了防御方案的原型系统,并根据实际的服务需求进行了重构和改良。通过一系列实验,验证了该系统对多种主流攻击的防御具有可行性、安全性和节能性。
1 模型介绍
在本节中,我们将对威胁模型与系统模型分别进行详细的阐述。
1.1 威胁模型
首先,我们介绍威胁模型。我们假设间谍用户可以与僵尸网络进行通信,将目标服务器的IP地址与端口号告诉攻击的组织者,然后引导僵尸网络向目标发起大规模的DDoS攻击(比如CC攻击),被攻击的服务器则会因为资源耗尽而无法继续正常提供在线网络服务。同时,间谍用户没有任何实质性的恶意行为,仅仅是不断地收集目标的相关信息,如嗅探目标主机的IP地址及端口号,这意味着传统的入侵检测机制将无法有效工作,无法将正常用户和间谍用户有效地区分开,因此这种间谍行为是十分隐蔽的。另一方面,间谍用户可能会有一些策略来躲避常规检测,例如间谍可能不会持续性引导僵尸网络发动DDoS攻击,从而使自身行为与正常用户行为机会无差异,显著减少了被甄别出的概率。
1.2 系统模型
其次,我们描述DQ-MOTAG的主要框架。图1展示了DQ-MOTAG的系统概况,主要由3个主要的组件组成:反向代理服务器、控制服务器和应用服务器。应用服务器提供一些在线实时服务例如多媒体视频,因此它是我们系统需要保护的对象。只有反向代理服务器可以与应用服务器进行通信,因为来自未经身份验证过的IP地址的网络请求将被过滤环过滤,过滤环是由放置在应用服务器周围的许多高速路由器组成,只允许来自有效代理节点的接入流量。此外,控制服务器通常具有较强的计算能力,可用于调整洗牌周期、对于每一个用户进行信用评分等决策。反向代理是一定数量的具有动态IP地址的分布式服务器,它在用户和应用服务器之间中继通信。这种机制有助于帮助应用服务器隐藏自己的IP地址。每个用户与指定的反向代理保持通信,且仅能探测到当前连接的反向代理IP地址。我们设计的DQ-MOTAG不同于传统MOTAG系统的地方在于去除了认证服务器这个脆弱的环节,替代采用了DNS服务器来完成初始反向代理IP分配。由于针对DNS服务器的防御研究广泛而成熟,所以这部分的安全性可以保证。
2 DQ-MOTAG的主要运行流程
在本节中,我们将对DQ-MOTAG的主要运行流程进行阐述。本部分构建的DQ-MOTAG系统主要是对网络流媒体平台进行主动防御,原因在于流媒体对时延与带宽均具有较高的要求,若DQ-MOTAG能够在保证流媒体服务正常运行的情况下,高效保证安全性,那么DQ-MOTAG将可以部署在大部分的在线网络服务平台。
如图2所示,DQ-MOTAG防御系统工作流程如下,首先用户需要完成身份认证,控制服务器建立反向代理和用户的映射表,完成后返回有效期固定的秘钥,用户完成注册后会直接由DNS服务器分配初始反向代理地址。随后客户端和反向代理建立全双工连接,进行视频加载。当反向代理服务器遭受到DDoS攻击时首先告知控制服务器,随后控制服务器根据洗牌规则进行洗牌并重新建立反向代理和客户端映射并将结果通知反向代理,反向代理收到结果后通过全双工连接通知客户端更换连接,随即客户端和新的反向代理建立连接。同时保证该过程对合法用户透明,即观看视频并无卡顿或重定向等重连反应。需要保存在数据库中的信息流为用户信息和用户对反向代理服务器的映射关系,NMTD系统中的认证用户需要在系统中完成注册,反向代理不对信息进行存储,而是将信息传递至控制服务器处进行信息的存储和查询。同时反向代理的视频模块负责视频的串流和内容的反向代理。在反向代理内部部署有成熟的入侵监测系统,能够监测DDoS攻击流量,一旦系统监测到被攻击,则会触发攻击系统的评分机制,从而进行动态目标防御。
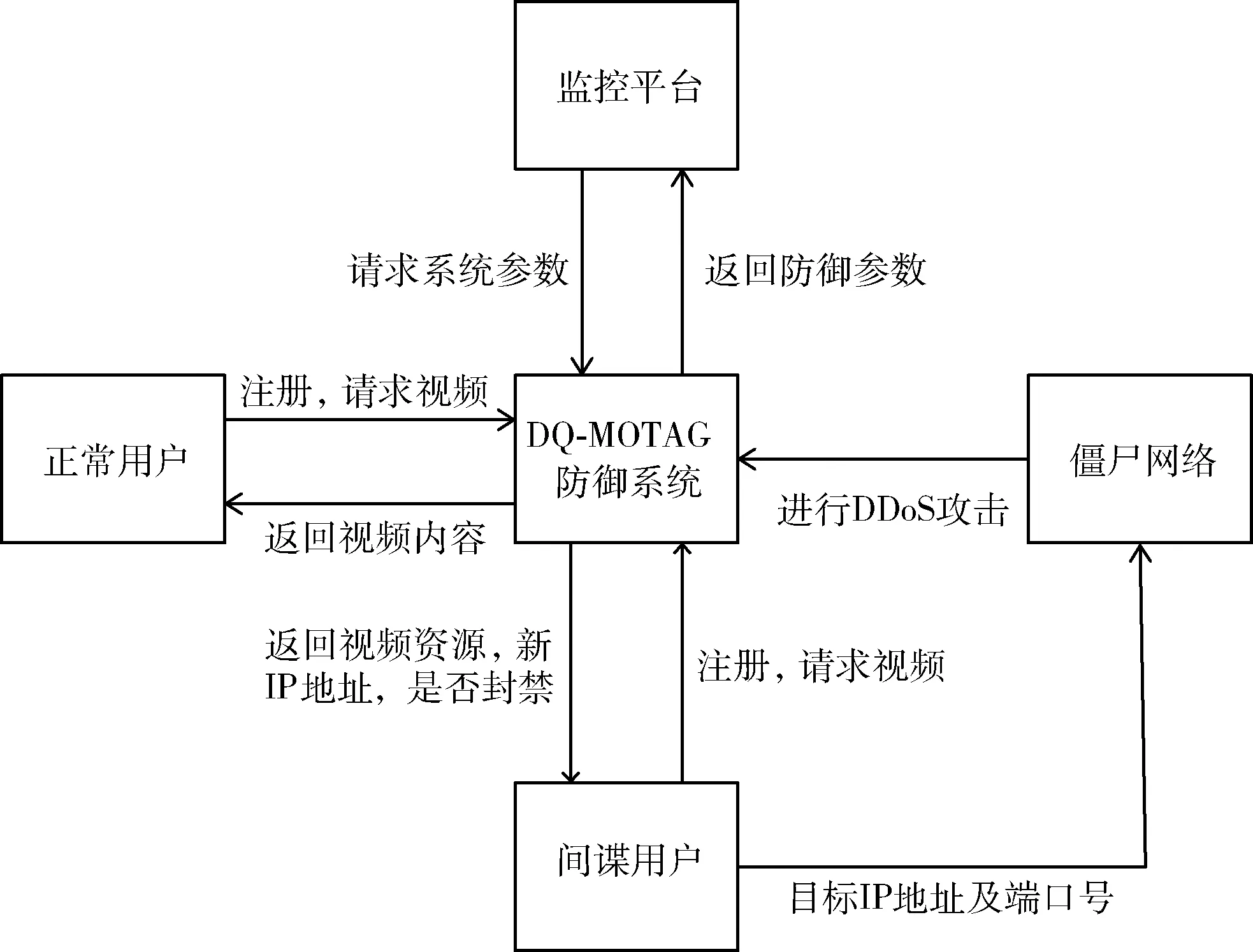
图2 DQ-MOTAG系统运行流程
接下来,我们将阐述洗牌的详细过程。在开始时,每个被访问的用户将被随机分配到一个激活的反向代理节点。如果一些反向代理在初始分配后受到攻击,应用服务器将降低这些受到攻击的代理中用户的信用评分。然后,应用服务器将在反向代理组中反复洗牌客户到反向代理的分配,以区分间谍用户和正常用户并隔离间谍。由于应用服务器无法知道用户中谁是实际的间谍,为了保护正常用户,应用服务器将在洗牌过程中随机重新分配所有用户到反向代理的映射关系。通过多次的洗牌过程,间谍的信用评分将会越来越少,直到被DQ-MOTAG系统封禁。在一定数量的间谍用户和可用的反向代理服务器中,可以激活更多的反向代理作为洗牌代理,以加速洗牌进程。在本文中,我们假设DQ-MOTAG系统采取最普遍使用的随机洗牌算法,即切换时随机分配用户连接到其它的反向代理服务器。此外,虽然洗牌过程是独立的,但每个用户的信用评分是基于历史行为的累积值。如果存在一些间谍用户保持不引导攻击的状态来让DQ-MOTAG系统相信他们是正常用户,那么他们也不会对系统造成额外的损害。
3 基于深度强化学习的自适应切换周期机制
在本节中,我们首先介绍了深度强化学习的总体概述。其次,我们提出一种基于深度强化学习的MOTAG系统来动态调整洗牌周期,其目的是寻得防御性能与网络资源消耗的最优平衡。
3.1 深度强化学习的概述
强化学习被认为是机器学习中重要的组成部分,能够帮助MOTAG系统探索最优的洗牌周期来最大化防御性能的同时减少网络资源消耗。强化学习能够通过选择动作at优化长期奖励rt在网络状态st的情况下。我们定义Vπ(s)为通过洗牌周期选择策略得到的状态价值函数,其可以表示为如下的公式
其中,E是期望算子,γ是折扣因子,k是索引。最优洗牌周期选择策略π*能够被定义为Vπ*(s)=maxπVπ(s)。在实际问题中转移动态性通常难以计算。在这种情况下,强化学习例如无模型算法Q-learning被广泛应用于学习最优解。在通常Q-learning算法中,往往基于Bellman公式来评估Q值函数,表示如下
Qt+1(s,a)=Qt(s,a)+α{r+γ[maxa′Qt(s′,a′)]-Qt(s,a)}
其中,Qt(s,a)是在网络状态s和动作a下的Q值,α是Q-learning算法的学习速率。但是,当状态动作空间越来越大时,学习过程将会消耗大量的时间并且收敛十分缓慢。在这种情况下,Q-learning已经不适合解决庞大状态空间下的马尔科夫决策问题了。
为了解决一般Q-learning中的上述挑战,深度强化学习[15]在近年内表现出了显著的优势。受益于神经网络的快速发展,大规模状态空间可以表达为神经网络替代原来的二维矩阵,其可以降低学习过程的时间复杂度。此外,深度Q-learning相比于Q-learning主要存在着两方面的提升,分别是经验重放和两部分Q网络。经验重放技术存储历史经验对到重放经验池,可以表达为et=(st,at,st+1)。深度Q-learning从经验重放池中选出历史样例来用于训练神经网络参数。在两部分Q网络中,目标Q值可以表示为y=r+γmaxa′Q(s′,a′;θ-),并且通过目标Q网络进行计算。同时,目标网络的神经网络参数每隔几个时隙更新一次。
3.2 基于深度强化学习的自适应切换周期算法
传统代理切换型系统一般具有固定时间间隔的洗牌周期,无论系统中的接入间谍数量是多是少,总是高强度的进行洗牌切换操作,保持了较高的安全级别,但会浪费大量的网络资源。因此,我们需要设计一种自适应调整切换周期的算法来实现当系统中的接入间谍数量较高时,系统保持高速的洗牌切换,尽可能保障安全性;当系统中的接入间谍数量较低时,则会降低洗牌切换的速度,尽可能降低切换造成的网络资源消耗。
在一个代理切换型动目标防御系统中,我们假设一共有N个反向代理节点,M个接入的用户并且每个方向代理节点最多可以分配L个接入用户,有N×L≥M。时间间隙可以被定义为△T,从而时间可以表示为t=time/△T。为了将深度Q学习算法应用到自适应调整洗牌周期中,我们首先给出网络状态、动作和奖励的定义,表示如下:

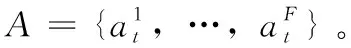
(3)奖励:设计奖励函数是为了评估动态洗牌周期的高效性。DQ-MOTAG的目的是寻求最优洗牌周期基于奖励函数。在本文中,简单而不失一般性,我们定义一个普适的奖励函数如下
其中,δ和β都是系数,Gi(t)代表在t时刻反向代理i遭受DDoS攻击的次数,Z表示时隙的总数量。这个奖励函数说明越多数量的DDoS攻击,奖励越低。另一方面,更长的洗牌周期意味着更少的网络资源消耗。通过这个奖励函数,深度Q-learning最终能够发现防御性能与资源消耗之间的平衡。在本文中,我们关注的是设计一个基于深度强化学习的自适应洗牌周期机制。尽管我们设计的奖励函数看上去结构较为简单,但它具有普适性且能够被应用于更加复杂的场景。
接下来,将给出我们设计的基于深度Q学习的自适应洗牌周期机制的伪代码,其展示在算法1中。
算法1:MOTAG系统中基于深度强化学习的自适应洗牌周期
(1)设置贪婪因子和学习速率
(2)初始化经验重放缓存
(3)初始化主Q网络的参数
(4)初始化目标Q网络的参数
(5)Fork=1,2,…,Kdo
(6) 选择一个随机的初始状态
(7) Fort=1,2,…,Zdo
(8) 生成一个随机概率p
(9) 通过下述方式选择动作
(10) Ifp<=εthen
(11) 随机选择一个动作
(12) Else
(13)at=argmaxaQ(S,a;θ)
(14) End if
(15) 执行洗牌周期选择动作at并且观测反馈的奖励rt。
(16) 获得下一个状态St+1。
(17) 将经验(st,at,rt,st+1)存储到经验重放缓存中。
(18) 从重放记忆中取一系列样例(sx,ax,rx,sx+1)。
(19) 对目标深度Q网络中的目标Q值进行计算:
(20) 通过梯度下降法最小化损失函数更新主Q网络
(21) 将主Q网络的参数每隔N个时隙拷贝到目标Q网络中。
(22) End for
(23)End for
DQ-MOTAG系统在没有先验知识的前提下探索不同的洗牌周期。从初始网络状态开始直到完成Z×△T时隙后被称为一个episode。在每个episode中,DQ-MOTAG通过贪婪策略选择不同的洗牌周期并且能够获得相应的奖励,然后当前状态将会转移到下一个状态((15)行~(16)行)。接下来,神经网络里的参数将会通过经验重放机制来更新((17)行~(21)行)。
4 仿真实验
为了验证DQ-MOTAG能够显著减少网络资源消耗并同时保持高效的防御性能,我们在极客云服务[16]进行了一系列的仿真实验,服务器参数为Intel i7 2.8 GHz CPU,显卡为GeForce RTX 2080 Ti和16 G内存。软件环境为python3.6中的Tensorflow 1.14.0。
首先我们验证随机洗牌算法的有效性。为了体现系统的高并发性,我们设置接入系统的用户数量为400个,反向代理服务器60个,不断地进行随机洗牌,收敛后结果如图3所示。

图3 随机洗牌算法的收敛结果
图3中的结果表示经过不断的洗牌后,正常用户的评分均匀分布在1000~3000的区间内,而恶意间谍的评分均匀分布在5000左右,可以说明随机洗牌算法能够有效地将正常用户与恶意间谍区分开,因此基于随机洗牌算法进行后续的仿真实验。
其次,我们设置了两种不同规模的仿真环境来验证自适应切换周期算法的优越性。环境I有5个反向代理服务器、24个正常用户和6个恶意用户。同时,我们设置神经网络为6个全连接层,数量分别为30,10,26,18,11,10。环境II有10反向代理服务器,64个正常用户和16个恶意用户。同时,我们设置神经网络为6个全连接层,数量分别为80,60,52,38,24,10。不论是MOTAG还是DQ-MOTAG,我们均采用随机洗牌策略,恶意用户发动攻击的概率为0.5。如果用户的信用评分超过5000,则用户将会遭受封禁。与具有代表性的MOTAG系统相比,环境I下的收敛结果如图4、图5所示。
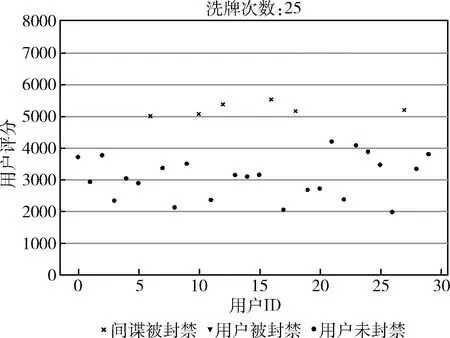
图4 环境I中MOTAG的收敛结果
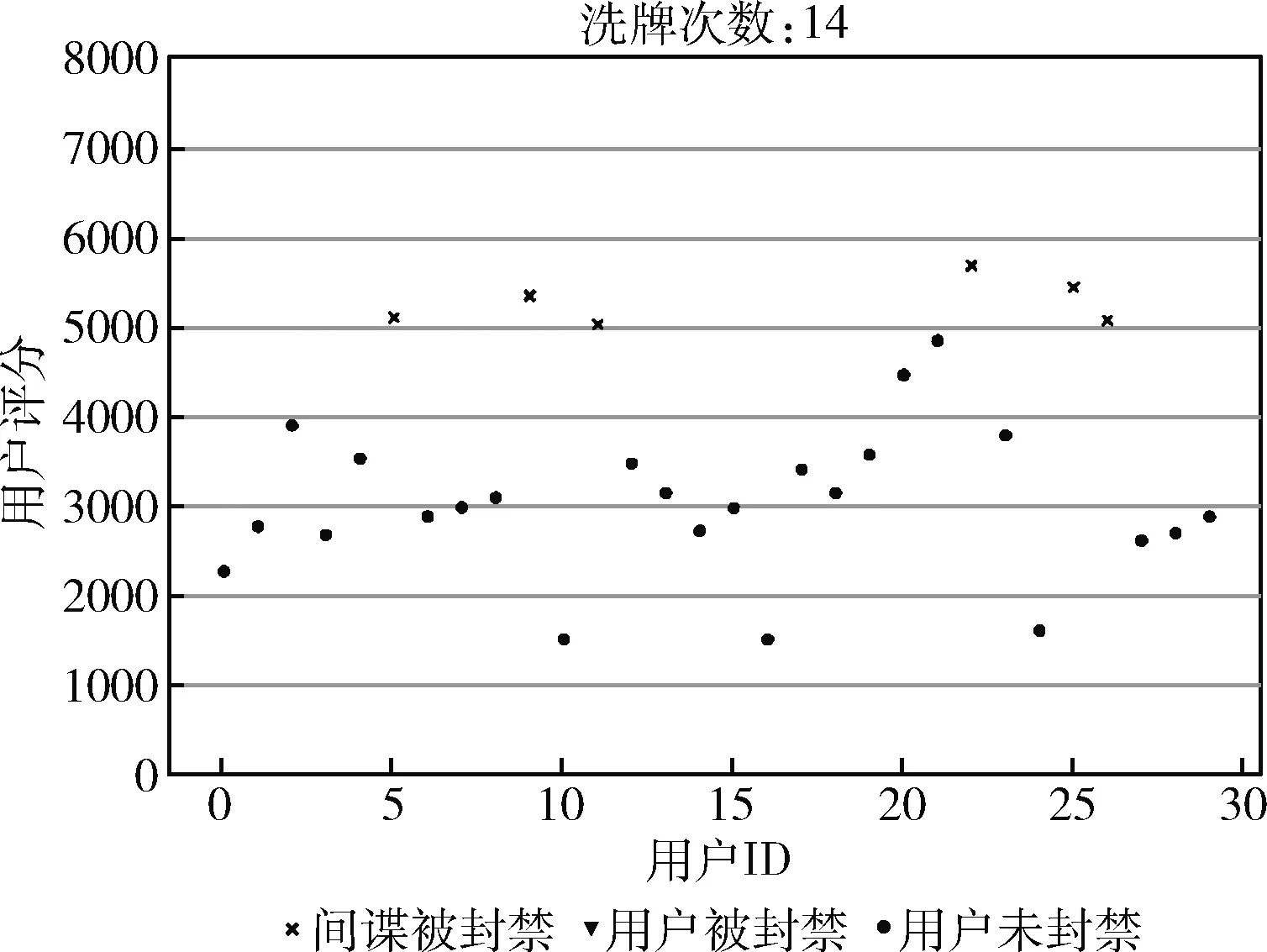
图5 环境I中DQ-MOTAG的收敛结果
如图4所示,我们能够发现所有的恶意用户都会在24轮洗牌中遭到封禁并且没有正常用户遭到误封。相似地,从图5中,我们能够发现所有恶意用户在我们提出的DQ-MOTAG系统同样遭到封禁并且没有正常用户遭到误封。但是DQ-MOTAG仅使用了14轮洗牌就完成了对恶意用户的搜寻过程。这些结果说明DQ-MOTAG和MOTAG相比能够在保证高效防御性能的同时降低网络资源消耗。
为了进一步验证DQ-MOTAG的有效性,我们在更大规模的环境II中进行了相似的实验。图6中的结果说明所有恶意用户在30轮洗牌后都将遭到封禁但是仍然存在两个正常用户被误封情况,意味着误封率为12.5%。另一方面,如图7中DQ-MOTAG系统在12轮洗牌后封禁了所有的恶意用户但同样存在两个正常被错误封禁,意味着误封率同样为12.5%。基于上述的实验,我们能够给出的结论是DQ-MOTAG系统具有和著名MOTAG系统相似的防御性能,但MOTAG系统能够减少洗牌的轮次,通过自适应的学习机制,说明DQ-MOTAG能减少资源消耗并且适合更多种的场景。

图6 环境II中MOTAG的收敛结果

图7 环境II中DQ-MOTAG的收敛结果
5 结束语
在本文中,我们提出了一种基于深度强化学习的系统被称为DQ-MOTAG。首先,我们给出了DQ-MOTAG的总体概述。其次,我们设计了一个基于深度强化学习的算法来自适应地调整洗牌周期,其目的在于显著减少网络资源消耗的同时保持相似的防御性能。最后,我们进行了一系列的仿真实验来验证我们系统的性能提升。在未来工作中,我们将考虑具有不同级别的混合反向代理来处理信用评分。
