基于主辅特征和深度学习的钓鱼网页检测方法
2021-11-02邹联扬乔鱼强
冯 健,邹联扬,乔鱼强,叶 鸥
(西安科技大学 计算机科学与技术学院,陕西 西安 710054)
0 引 言
当前,已有的网络钓鱼检测方法显得力不从心[1]。一方面,为了应对钓鱼网页不断增加的隐蔽性,已有研究致力于提取更多的特征,从而将原始数据表示为简单且具有较大关联性的高维特征,这增加了模型的训练负担;另一方面,传统基于机器学习的检测方法本质上属于浅层结构算法,在面向钓鱼网页这种复杂高维数据时其泛化能力受到制约,亟待提升检测效果。
提出一种基于主辅特征的双通道混合式深度学习模型。在总结现有研究成果的基础上,从钓鱼网页中提取了多种显著特征;依据重要程度对这些特征进行量化,并归为主要特征和辅助特征两类;分别以主要特征和辅助特征作为输入,构建双通道卷积神经网络(convolutional neural network,CNN)和双向长短时记忆网络(bi-directional long-short term memory,BiLSTM)相结合的深度学习模型,从而有效检测钓鱼网页。模型既能有效利用已有人工特征,又能很好地借力混合式深度学习网络强大的学习能力,因此有效提高了钓鱼网页检测的准确率和效率。
1 相关研究
当前钓鱼网页检测已获得大量研究,分为传统方法和深度学习方法。
1.1 传统方法
这类方法主要包括4个子类:①基于黑名单的检测方法:仅根据URL等信息进行简单匹配,实施简单、没有误报,但不能识别未在黑名单上列出的钓鱼网页。代表性的应用包括谷歌Chrome等著名浏览器[2]。②基于启发式规则的检测方法:通过对钓鱼网页之间存在的相似性进行分析得到关键特征,设计围绕这些特征的启发式规则,依据规则实现未知网页的对比判定。典型的系统包CANTINA+[3]、PhishDetector[4]等。启发式检测可以实时检测出大部分未被举报的钓鱼网页,但前提是钓鱼网页的统计特征是唯一的,且采用模糊匹配技术,因此误判率较高。③基于视觉相似性的检测方法:将待检测网页转换成图片文件,通过图像处理技术比较待测网页和目标网页的特征向量[5]。典型的方法有文献[6]提出的EMD算法。此类技术对于在视觉上跟目标网页并不相似的钓鱼网页无能为力。④基于机器学习的检测方法:将钓鱼网页检测看成分类或聚类问题,运用分类或聚类算法构建检测模型[7]。在人工抽取网页特征的基础上,分类方法根据已标记样本的特点构造分类规则或分类器[2],而聚类方法将无标签网页聚集为若干簇,再通过对簇进行标记来区分钓鱼网页和正常网页[8]。此类方法因具有良好的适应性和扩展度,且检测准确率高,在上述4类方法中已成为主流方法。
机器学习方法的效果通常取决于所提取特征的质量,因此研究的重点是如何选择和提取更有效的特征。钓鱼网页常见的特征包括URL词汇特性(如URL长度、特殊字符个数等)、网页身份特征(如Whois、DNS信息等)、页面内容特征(如页面布局、网页主题等)[7]。为了抵御攻击方的逃避攻击,提取的特征数量越来越多,如Chrome提取了2130维特征[2],使得建模的复杂度大幅提升。
1.2 深度学习方法
近年来,已有研究者将深度学习应用到钓鱼网页检测上[9-15],如文献[9-12]采用深度学习方法直接对URL进行自动特征提取,区别是采用了不同的深度神经网络,包括循环神经网络(recurrent neural network,RNN)[9]、降噪自动编码器(denoising autoencoder,DAE)[10]、CNN[11]和LSTM[12]。另一方面,也有研究试图从原始页面内容中自动学习钓鱼网页的特征,如文献[13]采用深度信念网络分别提取了钓鱼网页原始和迭代两种类型的特征,文献[14]则基于Word2vec模型抽取钓鱼网页的系列语义特征。尽管上述研究都能对钓鱼网页进行有效检测,但也存在以下问题:①大都采用原始的、单一的输入,如URL或页面内容,不依赖人工构造的特征,因此未能有效利用传统方法中经过大量研究分析、人工提取的多方面特征;②往往采用单一的深度学习模型,特征提取能力及非线性拟合能力有限,学习效果有待提升。
在深度学习的研究应用中,CNN因其善于提取数据的局部特征,成为最广泛应用的模型之一,但却缺乏学习上下文特征信息关联的能力;而LSTM作为一种时间递归神经网络,恰好适合于处理序列类型信息,因此近年来将CNN和LSTM相结合应用于各类问题的研究大量涌现并取得了成功。受此启发,为了解决深度学习在钓鱼网页检测应用中存在的问题,本文拟采用CNN和LSTM相结合的方案解决钓鱼网页的检测问题。同时为了克服LSTM仅考虑输入的上文信息、忽略下文信息的缺陷,采用具有双向时序性结构的BiLSTM将上下文信息同时纳入模型的考虑内,进一步提升模型的检测性能。另外,为了有效利用已有研究指出的人工特征,不同于已有的深度学习方法从原始信息端到端提取特征[9-12],本文将人工提取出的多方面特征作为输入,提出基于多输入的混合深度学习模型。
2 方 法
2.1 问题定义
钓鱼网页检测问题是将待测网页判定为钓鱼网页或正常网页,因此可看作二分类问题。考虑一组N个网页,{(p1,y1),…,(pi,yi),…,(pN,yN)},其中pi为第i个网页,i=1,2……N,yi∈{c1,c2}表示网页i的标签,其中类别c1是钓鱼网页,而c2是正常网页。分类过程首先获得网页的特征表示pi→xi,其中xi∈Rm是网页pi的m维特征向量。然后学习判别模型f∶x→y,再利用判别模型对待测页面进行类别判定。
2.2 系统架构
提出的模型称之为基于主辅特征的双通道CNN-BiLSTM模型(primary and secondary features and CNN-BiLSTM,PSCB),其架构如图1所示。由4部分组成:①数据采集。实现爬虫分别从PhishTank和Alexa网站爬取钓鱼网页和正常网页,从每个网页中人工提取多方面特征;②主辅特征向量构建。以特征的信息增益表达特征的重要程度,并根据重要程度归类构建主要特征向量和辅助特征向量;③模型训练。将主辅特征向量通过不同通道输入到CNN-BiLSTM混合式深度学习网络进行训练;④加权融合。对两通道的输出进行加权融合,并据此进行待测页面的类别判定。
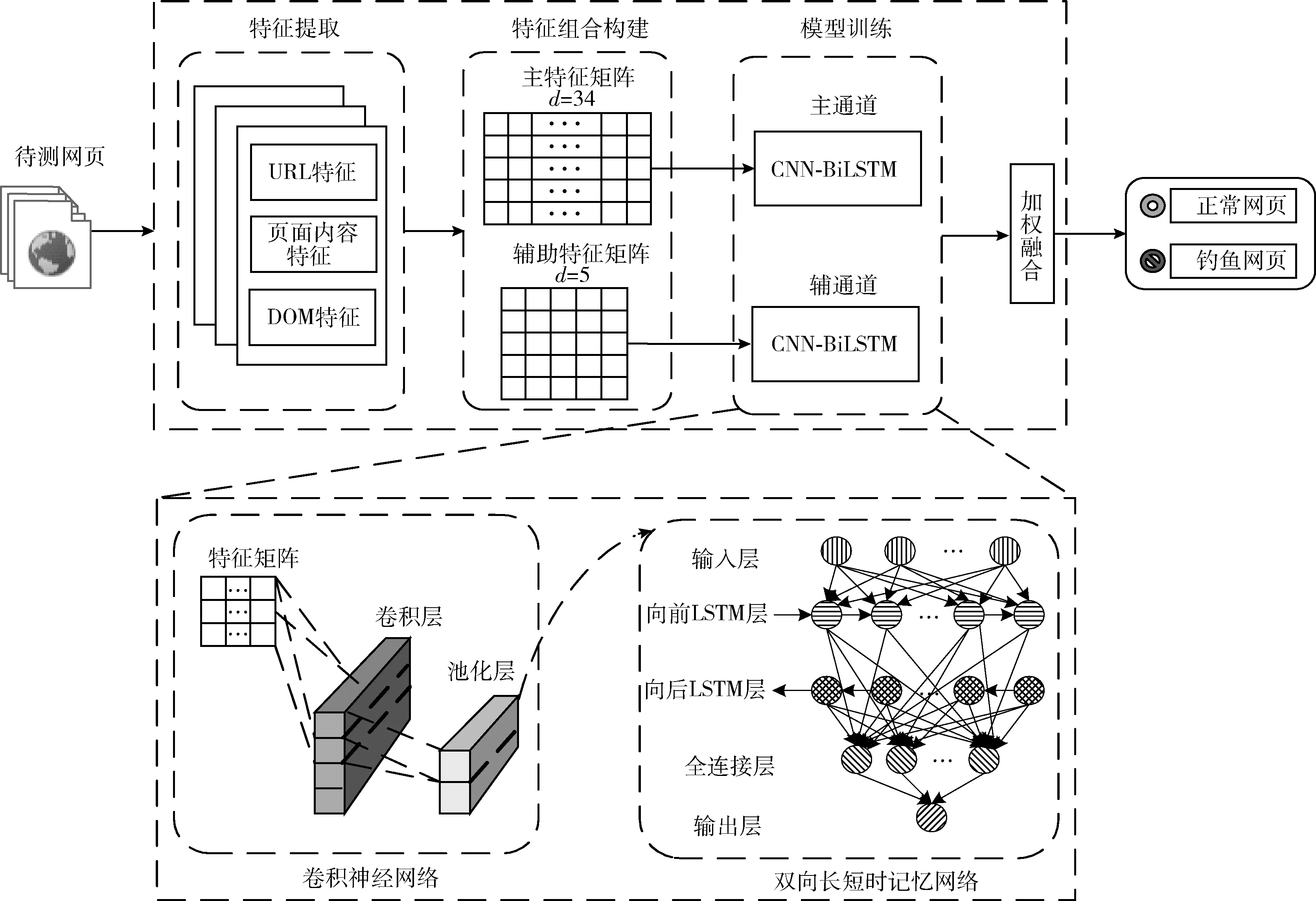
图1 PSCB模型结构
2.3 多特征提取
钓鱼网页具有生命期短和隐蔽性高的特点,仅依据单一特征无法进行有效检测。为了保证特征的多样性和显著性,通过对大量网页的分析和已有研究的整理,从网页的URL、页面内容和文档对象模型(document object model,DOM)结构3个角度采集了39维原始特征,全方位表示网页i的各种特性。
(1)URL特征
从URL中提取的特征包括URL外观特征,如URL中是否包含IP地址、URL长度等,以及第三方服务特征,即DNS特征、Whois特征以及网页排名等特征。表1列出部分典型特征。

表1 部分URL特征
(2)页面内容特征
本文将基于HTML的特征分为4类。为了计算前两类特征的值,这里定义几个符号:L表示当前HTML标记属性中的链接数,LE表示当前标记属性中的空链接数,LC表示当前标记属性中指向当前域的链接数。下面给出4类特征的简单描述。
1)空链接特征
对于不同标记属性中的空链接,计算特征值ME
(1)
2)指向本域名的特征
对于标记属性中指向非本域名的链接,计算特征值MC
(2)
3)布尔类型特征
包括标题属性和关键词属性。
4)长度特征
HTML文本长度特征是本文提出的两种特征之一。表2列出了页面内容中的部分典型特征。

表2 部分页面内容特征
(3)DOM结构特征

图2 两种新型特征
2.4 主辅特征向量构建
随着对钓鱼网页分析刻画的不断完善,使得钓鱼网页检测特征呈现高维化特点。特征维度的增加以及数据量的增长,造成模型计算复杂度呈几何倍数扩大,导致检测时间复杂度高、占用资源多和检测效率低。为突出不同特征对分类效果的影响并提高计算效率,使用信息增益来衡量不同特征相对于类别信息的重要程度,从39维原始特征构建出主要特征向量和辅助特征向量。
设X=(x1,x2,…,xm)为样本特征属性,其中m为特征维数;Y=(y1,y2,…,yn)为类别标签,n为类别数。信息增益计算公式如下
IG(Y,X)=H(Y)-H(Y|X)
(3)
(4)
(5)
式中:X表示网页特征,Y表示网页类别。IG(Y,X)为信息增益值,H(Y)表示Y的熵,H(Y|X)是条件熵,j表示第j个特征项。P(Y=yi)表示类别Y=yi的概率,P(X=xj)表示特征X=xj的概率,P(Y|X=xj)为表示出现特征X=xj时,类别属于Y=yi的概率。xj的信息增益值越高,则表明它和类别Y之间相关性越强,对分类结果影响也就越大。
信息增益的取值范围是[0,1]。根据39种特征的信息增益值分布,将信息增益值大于0.1的34种特征作为主要特征集合,小于0.1的5种特征作为辅助特征集合。5种辅助特征对分类检测结果起到辅助作用。
2.5 双通道CNN-BiLSTM分类
为有效处理主要特征和辅助特征,将它们通过不同通道分别输入结构相同的CNN-BiLSTM混合网络进行训练,即构建主辅两个模型。其中CNN的主要目标是提取数据的局部特性并有效降低数据维度,而BiLSTM则对特征之间相关性进行处理,深入挖掘特征信息本质。
2.5.1 CNN层
莫扎特的音乐天赋是后人不可企及的,他的奏鸣曲蕴含着他真实的情感,所以莫扎特的作品充满着对人性的慰藉。莫扎特的奏鸣曲在世界范围的音乐领域里已经占据了绝对性的主导地位,毋庸置疑,它也成为后人学习奏鸣曲的典范。随着时间的推移,莫扎特的音乐不仅没有被人们遗忘,相反我们对于莫扎特的作品依旧在努力研究着。在学习莫扎特的音乐时,我们要学会领会其中的音乐内涵和思想,以此来加深对莫扎特的理解,从而更好的演奏莫扎特的音乐作品。
本文设计的CNN为浅层网络,由一个卷积层和一个池化层组成。在卷积层,同时有多个卷积核对输入特征向量进行卷积运算,生成多个特征图;在池化层,通过最大池化降低特征图维度。卷积层的输入是由主辅特征分别构建的二维矩阵V。对于某个卷积核W,卷积后的矩阵Rj为
Rj=f(W⊗Vj∶j+h-1+b)
(6)
其中,h为卷积核的高度,b为偏置,⊗为卷积运算,f(·)为relu激活函数。为了减少网络参数、同时提取最重要的特征,对卷积操作后的特征图采用1-Maxpooling的池化操作
xj=max(Rj)
(7)
式中:xj为通过池化操作得到的特征向量。
2.5.2 BiLSTM层
BiLSTM由正向和反向两个方向上的LSTM链接而成,将CNN池化层输出特征向量作为BiLSTM的输入。LSTM利用记忆单元结构代替一般神经网络的隐含层,其单元结构如图3所示[16]。
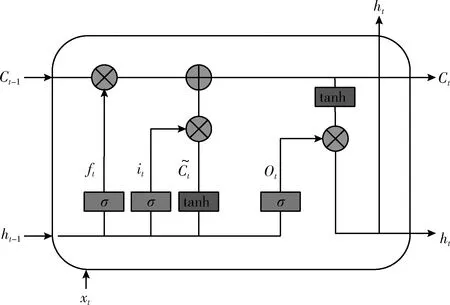
图3 LSTM单元结构
LSTM的记忆单元主要由输入门、输出门以及遗忘门组成,第t个单元更新过程的公式参见文献[16]。在第t个单元上,BiLSTM最终将两个方向得到的特征向量合成后作为输出。
2.5.3 双通道加权融合
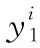
(8)
其中,C为类别标记集合,k代表输出类别编号,wk为不同分类器的权重。这样设计旨在通过区分不同分类模型的重要性,使预测结果较好的模型拥有更大的决策权,从而提升预测效果。
3 实验结果与分析
为了验证PSCB模型的有效性,设计了3组实验,试图回答以下问题:
(1)问题1:本文所采用的所有特征是否有效?新提出的两种特征有效性如何?
(2)问题2:区分主要特征和辅助特征对于PSCB模型的意义如何?如何选择融合权重以使模型最有效?
(3)问题3:PSCB模型与传统机器学习方法相比,性能是否有提升?
3.1 实验准备
3.1.1 实验环境及数据集
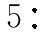
3.1.2 评价标准
实验采用分类问题常用的评价指标,包括准确率(Accuracy)、精确率(Precision)、真正率(true positive rate,TPR),也即召回率(Recall Rate)、假正率(false positive rate,FPR)和F1(F1-Score),计算方法参考文献[4]。
3.1.3 模型参数
通过大量实验,确定PSCB模型的最优参数设置见表3。
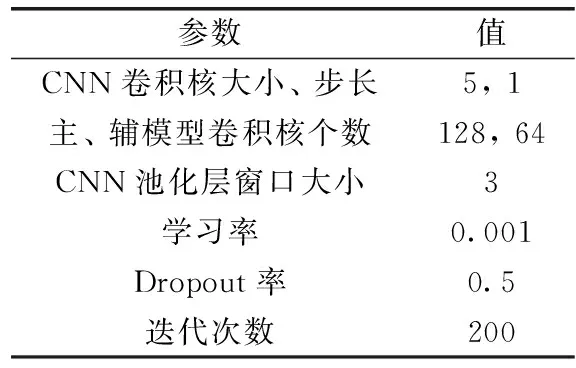
表3 PSCB参数
3.1.4 基线算法
与PSCB进行对比的各种主流的分类算法包括:传统机器学习算法如支持向量机(support vector machines,SVM)、朴素贝叶斯(naive bayes,NB)和k最近邻(k-Nearest Neighbor,kNN);经典单一深度学习网络CNN、RNN、LSTM、BiLSTM;以及不区分主辅特征情况下采用的混合式深度网络CNN-BiLSTM。
3.2 结果评估
3.2.1 人工提取特征的有效性实验
为了回答问题1,本组实验先不区分主要特征和辅助特征,而是分两种情况建立模型检测钓鱼网页:①使用37种经典特征作为各基线算法的输入;②加入两种新特征:DOM长度和HTML文本长度形成39种特征,并作为输入。通过不区分主辅特征的混合式深度学习网络CNN-BiLSTM和单一深度学习网络的分类性能对比来分析这些人工特征的有效性,表4和表5分别给出实验结果。
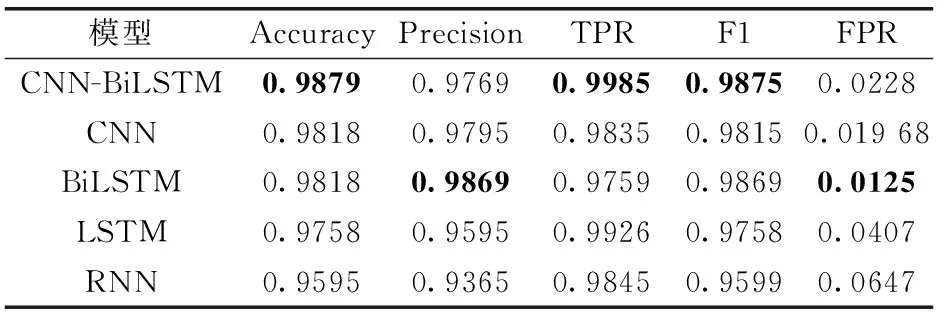
表4 使用37种人工特征的检测结果

表5 使用39种人工特征的检测结果
从上述表4和表5中可以看出,首先,以人工特征作为不同深度学习模型的输入,其检测精度都很高,这说明人工特征可以作为有效检测钓鱼网页的依据;其次,各模型的指标在加入两种新型特征后都有所提升,验证这些新特征对于有效区分钓鱼网页和正常网页有明显的作用;最后,在这些深度学习模型里,单一模型的检测效率明显低于复合模型,这说明复合模型比单一模型更能学习到钓鱼网页的潜在特征,值得深入研究和应用。
3.2.2 区分主辅特征的有效性实验
为了回答问题2,首先设置主模型和辅模型分类结果的融合权重组合,通过融合结果对比选定最优的权重比例;然后在最优权重比例下,对不区分主辅特征的CNN-BiLSTM(3.2.1实验中的最佳模型)和区分主辅特征的PSCB模型的分类精度和效率进行对比。表6和表7给出了实验结果。

表6 主辅模型融合权重
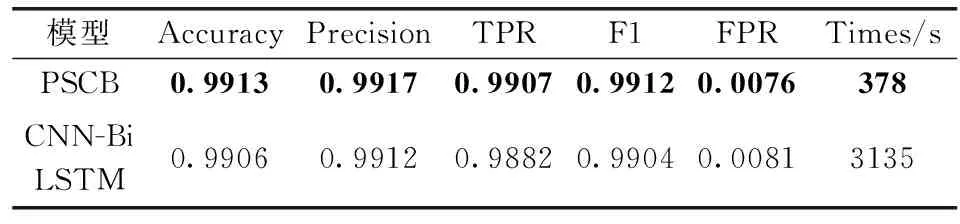
表7 CNN-BiLSTM和PSCB对比

3.2.3 与传统机器学习方法的比较实验
本组实验将PSCB与SVM、NB以及kNN进行比较以回答问题3。表8给出预测结果,图4进一步展示了各方法对应的ROC曲线。
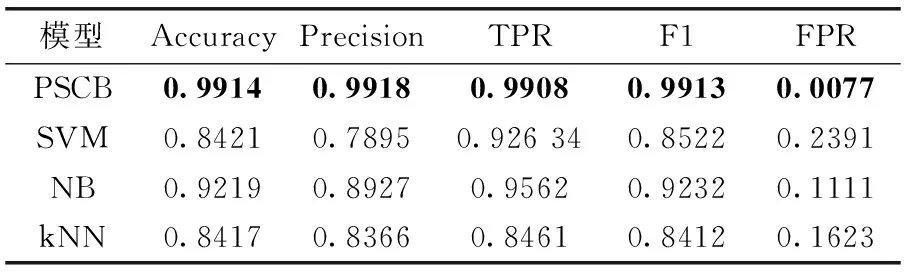
表8 与传统机器学习方法对比
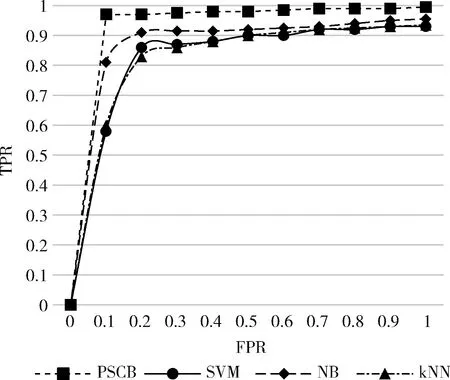
图4 ROC曲线
由于采用了混合式深度学习网络,PSCB相比传统机器学习方法拥有更多的隐层,包含更多的非线性变换,使得其学习复杂模型的能力大大增强。从表8可以看出,PSCB分类效果远好于传统机器学习方法。图4为ROC曲线,根据曲线下的面积可知PSCB模型的预测效果最好。
综上可见PSCB模型以人工特征为输入是可行的,两种新特征也对分类结果产生了积极的影响。主辅特征的区分、双通道复合深度学习模型的采用能有效提升钓鱼网页的检测效果。
4 结束语
提出一种基于多种人工特征和双通道复合深度学习的钓鱼网页检测模型PSCB,有以下特点:①采用全方位特征表达:从对大量已知正常网页和钓鱼网页中采集URL、网页内容、DOM结构等特征来表达网页的基本特性;②根据信息增益评价特征的重要程度,将多个特征分为主要特征集合和辅助特征集合;③基于双通道复合深度学习网络CNN-BiLSTM构建检测模型。实验验证,PSCB模型取得了很好的检测效果。
在PSCB中,原始输入特征由人为确定。随着攻防竞争的不断升级,钓鱼网页的一些典型特征逐渐消失,新的特征不断出现,人为发现新特征的方法费时费力。当前,表示学习技术的发展如火如荼,研究如何利用最新的表示学习技术进行钓鱼网页潜在特征的自动发现是下一步的研究重点。
