并行H-mine算法在智慧校园学生行为分析中的应用①
2021-11-02符睿
符 睿
(广东轻工职业技术学院信息化建设中心,广东 广州510000)
0 引 言
近年来,大数据技术在高校学生管理和教学质量方面得到了广泛的应用,为挖掘学生行为提供了一定的技术支撑[1]。随着并行化技术的发展以及校园大数据的不断增长,将两者技术的融合也成为当今的一种趋势。将并行大数据技术应用于智慧校园,一方面能够快速提取海量校园数据中学生的行为特点,另一方面通过学生的行为规律调整教学模式,制定出具有针对性的措施,为高校的教学以及学生管理提供相应的辅助决策[2]。根据并行H-mine算法能够实现对于校园大数据的分析,有效挖掘出学生的行为特征,从而为学生行为提供更加清晰直观的分析数据,以期为高校学生管理提供一定的参考价值。
1 智慧校园并行H-mine算法设计
1.1 基于Spark平台的并行H-mine算法
作为一种可扩展、高性能、可预测的算法,Hmine算法在实际的计算过程中首先需要遍历数据集,统计频繁1项集[3]。选取每一行的数据作为单位,筛选出其中大于最小支持度中的项,经过升序排序每行中的项,从而得到频繁项投影;
其次,使用HStruct来表示F-list,可简称为F-list HStruct,并对其中的频繁项进行升序排序。然后对F-list HStruct中的频繁项逐一加以遍历,依次连接每一行中首个数据项一致的频繁项,等所有F-list HStruct中的频繁项遍历结束,从数据集中的第一个数据项开始分区,并进行遍历操作,直至完成遍历,则结束操作,否则进行上一步[4]。最后对分区中的数据集进行遍历,并统计其中的频繁项,在此基础上对分区数据集再次进行分区;当分区遍历结束,需要进一步判断循环数与1的关系,如果大于1,则返回上一层进行循环;如果小于1,则返回到步骤四,对该分区数据集重新分区;倘若该分区没有遍历结束,则返回到步骤五重新对上个分区数据集进行划分。
在Spark平台中,一个job由多组任务组成,且每一组任务对应一个Stage,
任务分为Result Task与Shuffle Map Task两种类型[5]。最初在Spark应用程序的基础上对有向无环图(DAG)进行构建;其次,以RDD的关系为依托对有向无环图进行划分,有向无环图实现多个Stage的分类。分区在窄依赖进行转换时需要在Spark平台上交由一个线程完成。分区在宽依赖进行转换时,只有当父RDD shuffle得到满足并执行后,才能逐步进行子Stage的运算[6]。具体过程如图1所示。
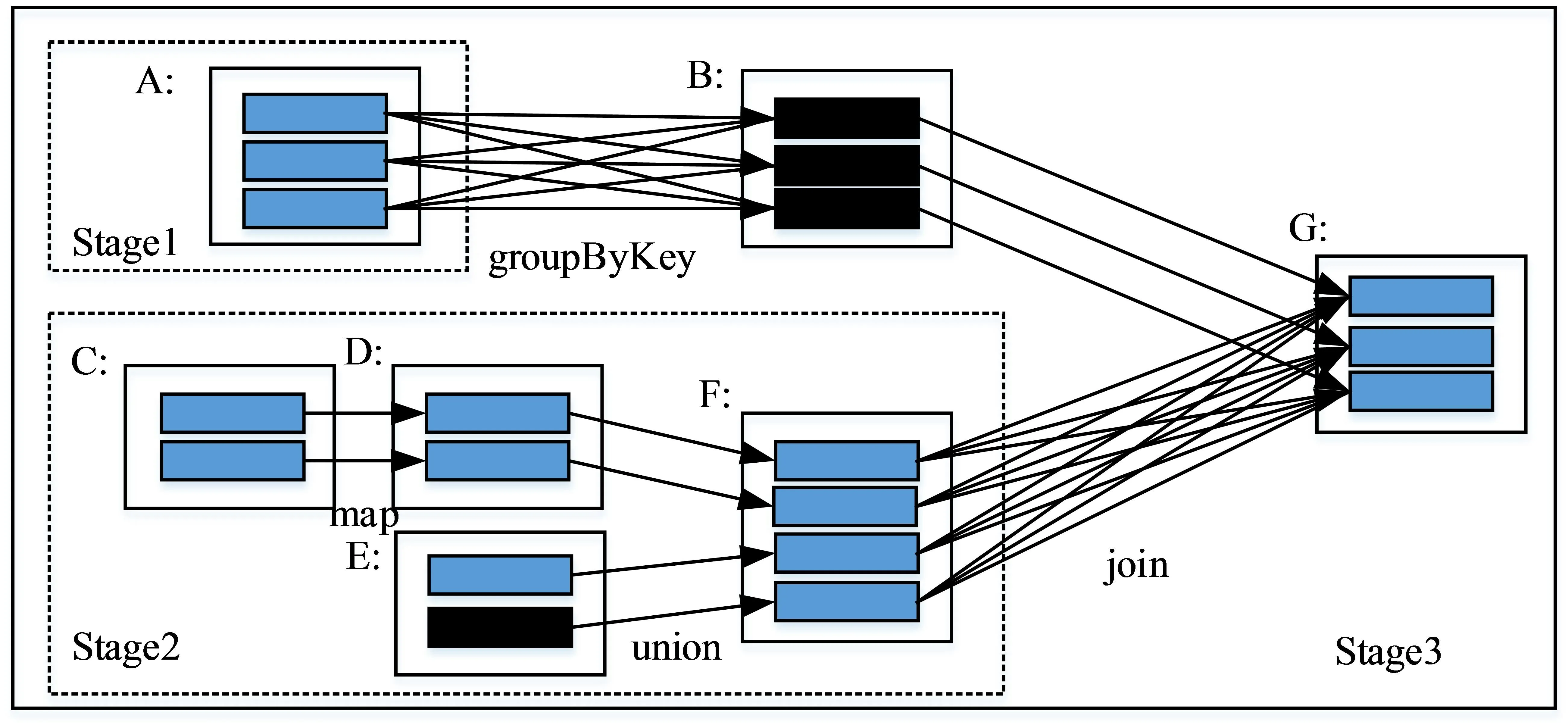
图1 Spark处理过程
为了保证Spark平台处理数据的精确性,数据的格式首先设定为<行内容,行号>,在行内容中,空格的作用为各个数据项的分隔符,同时满足数据的格式在每个数据项上一致的分隔符(比如<d s a f 2>),这个例子所代表的含义是行号为2,行内容为<d s a f>[7]。在行内容的末尾加上行号一方面能够保证在相对位置的前提下行内的秩序;另一方面也能在统计频繁1项集时不影响程序的正常运行。经过上述操作,要想在平台实现并行Hmine算法,首先需要进行F-list并行计算,其次以F-list为基础,将其转化为HStruct并行方法,再次经过负载均衡方法,最后进行并行挖掘频繁项集。
频繁项投影作为H-mine算法在频繁项集挖掘中最为关键的一步,即是能在相对位置不变的情况下,F-list能够满足最小支持度的数据项,且保证有序的行内元素[8]。在挖掘之前,需要对F-list进行转化,使其符合此次算法的Structure数据结构的要求,由此算法在Spark环境中集成时,需要对F-List进行并行处理。经过处理转化之后,从而可以对频繁项集进行挖掘,由F-list HStruct的频繁项<A,B,C,E>,投影形成四类频繁项集。Flist HStruct若 含 有{x1,x2,…,x n}n项 数 据 项,那么x k(1≤k≤n)为前缀的频繁项一共有2n-k个,此时x k一直处于第一位,且第t(t>k)与x k都能组合在一起,即可为数据项中最好的情况。针对频繁(n-k+1)项集而言,利用集合的无序性,在x k后(n-k)个数据项存放的位置与顺序没有任何关系,比如{x k x k+1x k+2…x n}与{x k x k+2x k+1…x n}属于同一频繁(n-k+1)项集。其中,以x k作为前缀的频繁项集一共包含(n-k+1)种,依次为频繁项集1,2,…,(n-k+1),统计并相加每一个频繁项集中的频繁项个数,从而即可得到以x k为前缀的频繁项总个数,如公式(1)所示。
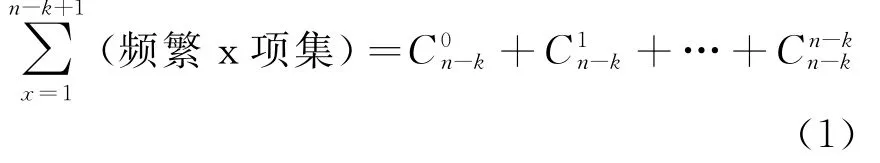
由二项式定理可得公式(2)。
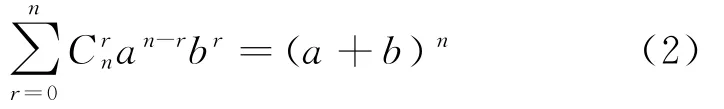
当a=1且b=1,可以求得公式(3)。

经上述三个公式联合可得公式(4)。
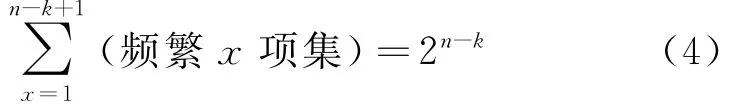
1.2 智慧校园学习行为数据处理
“智慧校园”的普遍应用,提供给学校大量的学生行为记录数据,通过分析学生数据,对学生学习的多维学生行为特征进行提取,逐步建立分层模型[9]。首先定义一个学生行为特征集合,从学生的特征库中提取学生行为指标以及个人信息,以此构建学生行为特征集合,如公式(5)所示。

在该模型的基础上,为了区分模型中不同特征的贡献度,还需赋予学生特征集合不同的特征以不同的权重,同时满足,如表1所示,为学生信息与行为特征的设定。
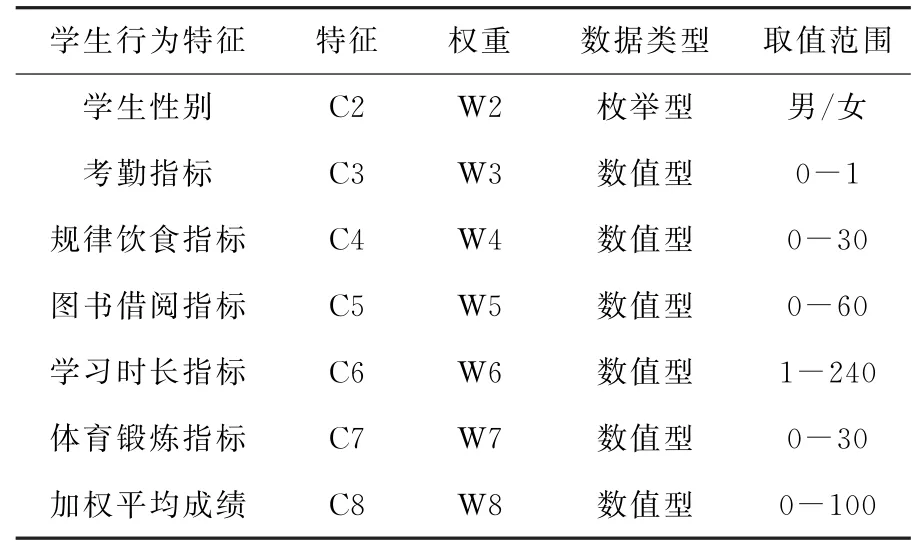
表1 学生个人信息以及行为特征指标
在成绩、课程、图书馆签到、消费数据等多源数据的基础上,此次系统数据以此挖掘与分析智慧校园学生行为的频繁项集10]。异构性问题在数据处于多种系统的情况下容易发生,为了针对性地解决该问题,在多源中的字段使用数据抽取的办法进行中间处理,从中可以得到中间表,系统工作流程如图2所示,利用动态批处理方法对中间表进行处理。其中,选择窗口作为单位,滑动距离为十四天,长度为一学年,然后对各类数据进行预处理,并将同一类条件下的学号进行全连接,将此过程中生成的数据作为输入数据应用于并行H-mine算法中,最后进一步对学生行为中的频繁项集进行挖掘,以此更好地分析学生行为,为校园学生的管理工作提供一定的参考。

图2 系统工作流程
由于中间表的数据全都来源于原始数据,且离散型数据为H-mine算法的输入数据类型,因此还需按照一定的标准,对每一种数据进行离散化的操作,也就是将连续属性转化为类别属性,首先依次排序连续属性,其次在n-1个特定分裂点上划分连续属性值为n个区间,最后映射得到同一类别上的区间值。通过对离散化数据的预处理之后,从中可以获取图书馆签到次数、早餐次数、平均成绩、缺勤次数、消费水平五类离散化表,选择学号相等作为连接条件进行全连接。在此基础上即可实现对校园学生行为的处理与挖掘。
2 并行H-mine算法应用效果分析
2.1 性能测试结果分析
此次性能测试选取三台虚拟机模拟并行的过程,在软件的配置上,选取的是Linux的操作系统,Spark平台的配置环境采用Hadoop2.7.3与Spark2.2.0对平台程序进行运行。以源稀疏数据对H-mine算法与MRH-mine算法进行两组对比实验,将源系数数据复制50和500份加以测试,运行每一个算法10次,取出相应的均值,即可得到算法运行的时间。如图3(a)所示,选取0.01、0.03、0.05、0.08、0.1、0.2、0.3、0.4、0.5为九个支持度,并对10568条数据量进行测试,将此数据分别应用到并行H-mine算法与MRH-mine算法之中。其中,在上述支持度下,并行H-mine算法的运行的最长时间与最短时间分别为5.9309s、5.3725s;MRH-mine算法的运行的最长时间与最短时间分别为7.4165s、6.918s,由此可以看出,当数据量达到10568条时,从整体上来说,MRHmine算法明显高于并行H-mine算法的运行时间,同时随着不断增大的支持度,两种算法的运行时间展现出平稳的发展趋势。

图3 H-mine算法与MRH-mine算法运行时间对比
当数据量是5284000条时,从图3(b)可知,并行H-mine算法在上述支持度下的运行的最长时间与最短时间分别为21.29s、12.576s;MRHmine算法的运行的最长时间与最短时间分别是34.645s、17.0798s。相比于MRH-mine算法,并行H-mine算法运行时间优化效果更为显著,其中当支持度小于0.1时,并行H-mine算法运行时间以较快的速度下降,当支持度大于0.1时,运行时间较为平稳;MRH-mine算法的整体运行时间呈下降趋势,且运行时间对支持度较敏感,由此并行H-mine算法在运行时间上总是优于MRH-mine算法,性能较为优良。
2.2 学习行为实验结果分析
在输入数据为稀疏数据的前提下,往往包含较多的空值,更加适用H-mine算法挖掘学生数据中的频繁项。从图4可以看出,当H-mine算法频繁项集进行挖掘时,需要设置支持度以及最大频繁项长度两大参数。支持度即为同一时间一个或多个特征在总体中的比例,频繁项的个数与支持度的设置有着直接的关联。频繁项的最大长度为最大频繁项长度,通常设置为特征的个数,此次实验将其设置为8。数据支撑为经过预处理之后的输入数据,设置实验的支持度分别为0.01、0.03、0.05、0.08、0.1、0.2、0.3、0.4、0.5,将九种不同的支持度在并行H-mine算法中进行应用,分为九次实验,在频繁项中九种不同的支持度对应的总个数分别为1239、491、274、153、102、32、10、6、2。当支持度大于0.2时,频繁项因其个数较少,不能用于分析;将最小支持度设为0.1,此时频繁项共有102个,因此利用此次算法中的频繁项集对学生行为加以分析。
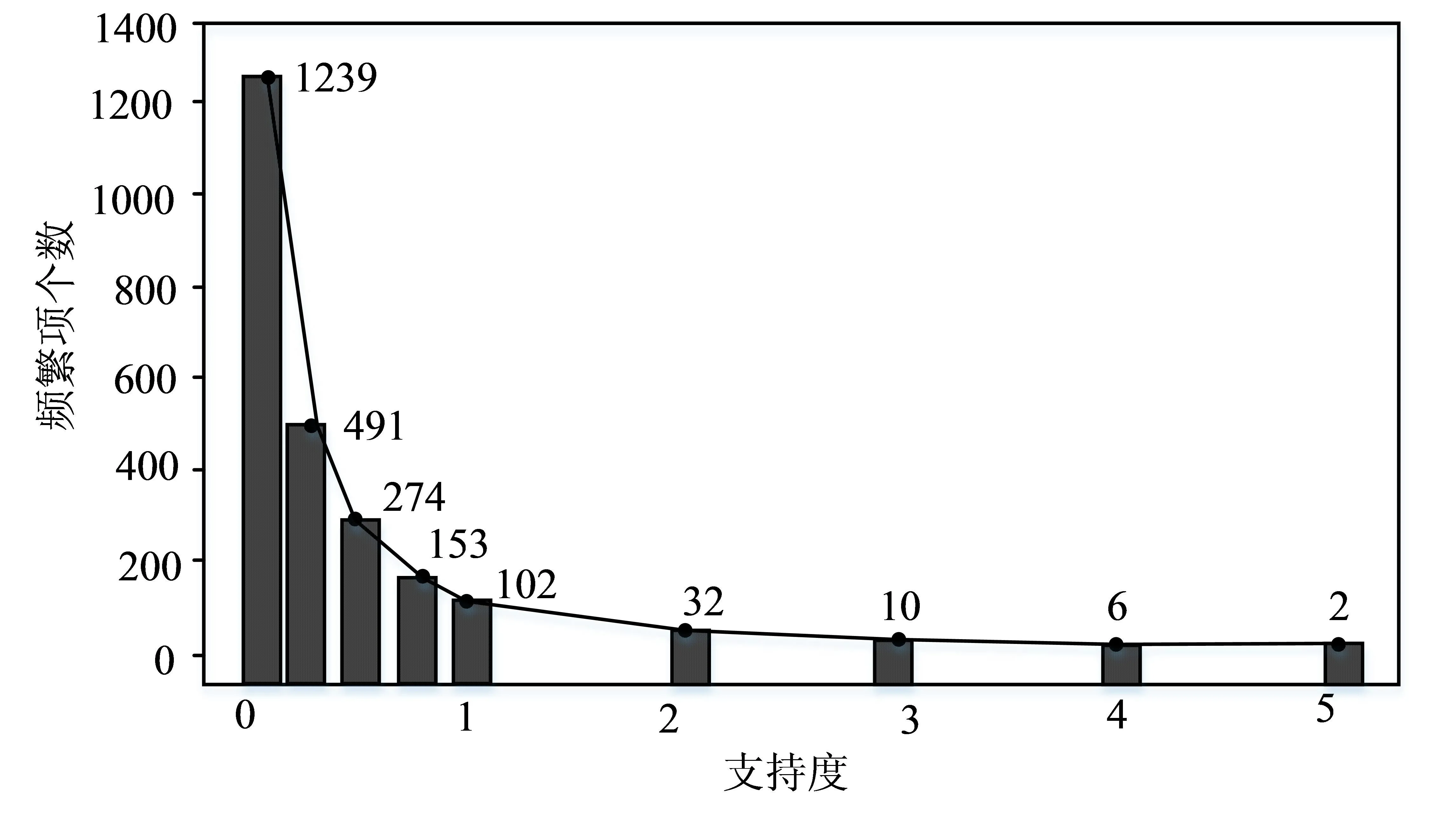
图4 支持度与频繁个数的关系
选取研究对象数据的成绩进行排名,根据正态分布,分为好、中、差三类,并设置标签为“1”、“2”、“3”,分别占总人数的19.84%、60.02%、20.14%,在此基础上对成绩排名数据和校园行为进行分析,以此将最初的行为数据转化为与学业成绩有关的行为特征。为了避免数据误差过大,以一号学院为对象,对学生行为数据进行独立分析。如图5所示,针对一号学院三类学生的饮食就餐情况进行统计,一类学生、二类学生、三类学生在早餐就餐的平均次数分别为121.08、107.04、116.68,在午餐就餐的平均次数分别为186.73、193.59、186.45,在晚餐就餐的平均次数分别为174.53、196.74、176.47,从整体上来说,三类学生早餐就餐次数远远少于午餐和晚餐次数,一定程度上说明大多数学生存在饮食无规律的状况,其中,相比较而言,三类学生中第一类学生早餐次数最多,显示出此类学生具备更为良好的饮食习惯。
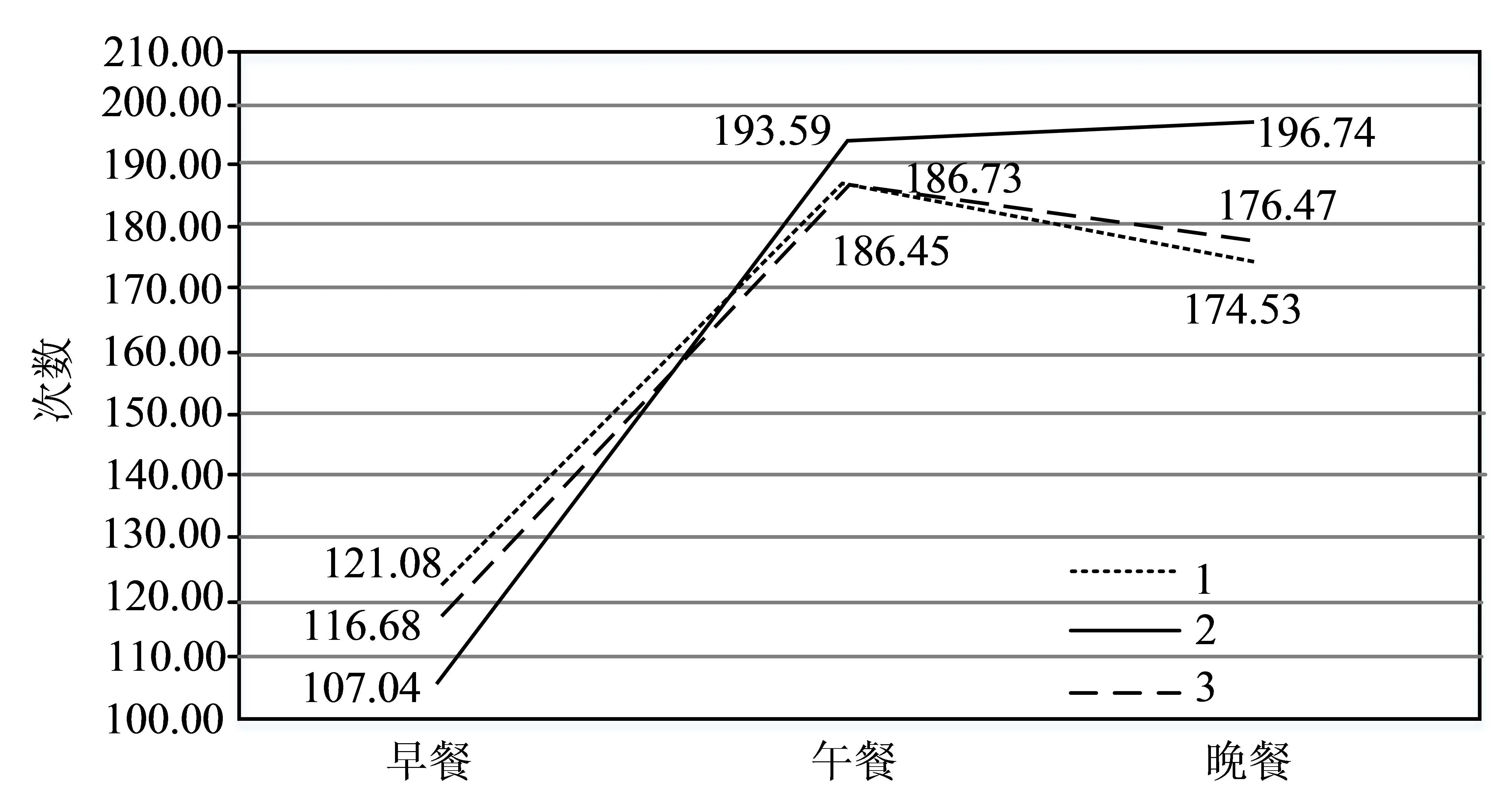
图5 一号学院三类学生的三餐统计数据
如图6所示,从考试与非考试期间三类学生去借书、文印中心、图书馆次数的不同可以看出,学生去图书馆的平均次数都远远高于去借书和去文印中心的平均次数,统计所有学院学生在两个学年内到图书馆借书的数据,第一类学生、第二类学生、第三类学生平均借书分别为52本、48本、42本,随着学生类别的差异,借阅书籍、图书馆自习的行为处于下降趋势。具体而言,第一类学生学习与借阅习惯较为良好,第三类学生学习行为相对较少,说明比较缺乏切实可行的的行动力,由此即可实现智慧校园学生行为的分析。

图6 在考试与非考试时间段三类学生行为(平均次数)比较
3 结 语
传统的数据统计方法面对日益增长的大量数据很难做到高效处理,并行化技术与大数据技术的不断发展,使得并行处理大数据成为可能,使其更好地服务于当今智慧校园服务体系建设。通过将校园大数据与并行H-mine算法以及Spark平台相结合,使用该算法挖掘频繁项集,进而使用该频繁项集对学生行为进行分析。根据性能测试和实验结果表明,H-mine算法有极好的可扩展性以及较为良好的综合性能,能够进一步提升挖掘效率,极大的节约了内存并能处理更大规模数据集,从而为校园管理提供辅助决策。此次并行Hmine大数据挖掘算法的集成方法虽取得了一定的成果,但仍存在一些不足,并行H-mine算法并行度还有待提升,并行度在H-mine算法中在两个分区之间是并行的,但分区之内存在明显的串行现象,提高分区内的并行度将作为后续研究的一个方向。
