基于关联规则算法的电子商务商品推荐系统设计与实现
2021-11-01宋倩
宋倩
(咸阳职业技术学院 财经学院, 陕西 咸阳 712000)
0 引言
随着信息技术的发展,人们在享受科技带来便利的同时也受到了信息过载的困扰,对于电子商务领域同样如此。如何帮助用户获得满意商品是电商企业获取利润和提升自身信誉的关键,电子商务商品推荐系统应运而生,将数据挖掘技术应用于用户日常购物活动的场景之中,利用关联挖掘算法分析历史数据来实现潜在商机预测,既为用户节约了寻找感兴趣商品的时间,也为商家提升了销量及用户忠诚度。
1 需求分析
1.1 功能需求
电子商务的商品推荐系统主要是根据收集的用户浏览行为以及历史消费记录分析其兴趣偏好、挖掘预测潜在购买商机进行推荐。其中最关键的是个性化以及实时性。系统的主要功能体现在以下几个方面。
(1) 数据采集:提取相关记录及行为数据。
(2) 数据预处理:剔除无用数据、确保数据完整。
(3) 用户兴趣分析:构建用户兴趣模型,分析积累用户兴趣商品库。
(4) 关联规则库:根据挖掘算法构建关联规则库。
(5) 商品推荐:推荐用户感兴趣的商品。
1.2 关键参数
(1) 置信度:降低关联规则中“规则爆炸”情况,提升算法精准率。
(2) 时效度:在实际场景中,人们的购物习惯是在不断变化的,距现在时间越近的相关浏览记录或购买记录越能代表当前的需求偏重点。
(3) 兴趣度:在电子商务领域可以反映用户兴趣的因素有很多,包括购买、浏览、收藏、评分、评论等。兴趣度体现为将多种商务行为经过算法策略得出的兴趣程度的权值[1-2]。
2 相关技术
2.1 数据挖掘
数据挖掘是一门新兴的技术,是多学科综合形成的产物,指的是从海量不完整的、存在脏数据的、比较模糊的数据集中抽取出未知的有潜在价值的、有意义的模式或规律的计算过程,主要包括数据清洗、数据集成、数据选择、数据转换、数据挖掘、数据评估及数据展示。
(1) 清洗与集成:数据质量是保证挖掘出来的知识可靠性的基础,需要清除重复数据、不完整数据、脏数据,并将多个数据源的数据集成到一起完成后续操作。
(2) 选择与转换:选择将进行数据挖掘的目标,针对不同数据类型进行统一化处理,消减特征维数,降低不必要的计算。
(3) 挖掘与评估:运用相关的聚类、分类算法进行数据计算,从挖掘结果中根据一定的评估标准选出有意义的知识。
2.2 关联规则
关联反映的其实是事物之间的依赖关系,其中两个或多个属性之间的取值如果呈现规律,则认为有关联关系,根据其中一项属性值即可预测其他属性值。在数据挖掘领域中基于关联规则挖掘的研究是其中的重要研究方向。关联规则挖掘的基本概念如下。
(1) 数据项与数据项集:设I={i1,i2,…im)是m个不同项的集合,则每个ik(k=1,2,…,m)代表数据项,I为数据项集。
(2) 事务:事务T是数据项集的非空子集,每个事务与唯一标识符对应,记为TID。多个事务构成事务集D。

(4) 关联规则:X⟹Y用的形式表示,其中X⊂I,Y⊂I且X∩Y=Ø,表示如果X项集在某一事务中出现,则Y也会出现。
(5) 关联规则置信度:置信度指的是包含X和Y的事务数与包含X的事务数的比值,置信度越高,关联规则的可靠性越好。计算式为式(1)。
confidence(X⟹Y)=|{T:X∪Y⊆T,T∈D}|/
(1)
|{T:X⊆T,T∈D}|
(6) 最小支持度和最小置信度:最小支持度用来过滤出现频率低的项集,最小置信度用来剔除可靠性低的关联规则。
3 关键算法
3.1 FP_Growth算法
FP_Growth算法采用模式增长的方式来发现频繁项集,首先建立一棵频繁模式数FP_tree,存放事务集的所有频繁项集,然后将树中压缩后的事务集划分为一组条件事务集,每个事务集关联一个频繁项,分别挖掘每个条件事务集。该算法可以明显压缩被搜索的事务集[3-4]。
3.2 CTE-MARM算法
由于FP_tree频繁项集查找时存在节点多、递归调用次数多等问题,本文针对电子商务商品推荐的个性化应用性问题,对FP_Growth算法做出优化与改进,提出一种基于FP_Growth算法的约束事务扩展多层关联规则挖掘算法CTE-MARM(Constraint Transaction Extension—Multi-level Association Rule Mining),以此提升挖掘效率、减少冗余规则。主要改进项如下。
(1) 对每条事务基于K层次约束扩充,将每个事务项的前k-1个祖先项添加到当前事务,之后剔除重复项,既约束数量的扩展又可以保证发现关联规则。
(2) 创建FP_tree时对每个节点添加两个域:ConditionMemory用来存放结点前缀路径上的结点、IsVisited用来判断当前结点是否被遍历,避免多次回溯。
(3) 增加风险度阈值指标,确保事务约束扩展层次k选值合理。
4 用户兴趣模型
用户兴趣模型是电子商务商品推荐系统的核心,是确保推荐质量的关键模块。首先,构建商品-用户行为特征矩阵。

good1…goodj…goodn点击次数ccWc1…wcj…wcn访问次数rcWr1…wrj…wrn停留时间stWs1…wsj…wsn用户评价e1We1…wej…wen
然后,向量空间模型采用三元组〈用户,商品集,兴趣集〉的形式,〈useri,goods,interests〉,其中,
useri为具体用户;
goods为商品集合,goods=〈good1,good2,…,goodj,…goodn〉;
interests为兴趣度集合,interests=〈IRi1,IRi2,…,IRij,…IRin〉;
IRij为用户i对商品j的兴趣度。
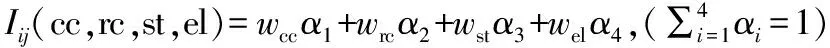
通过三元组记录用户感兴趣的商品集,按IRij降序排列,采用TOP-N策略,选取IR值前N个商品形成“用户-兴趣商品链”。另外,还需要考虑其他数据挖掘出的关联规则,利用改进的CTE-MARM算法进行关联挖掘,如果有用户-兴趣商品链表中的goodi存在强关联规则的goodk,则将goodk也添加到三元组中[5-6]。模型构建流程如图1所示。
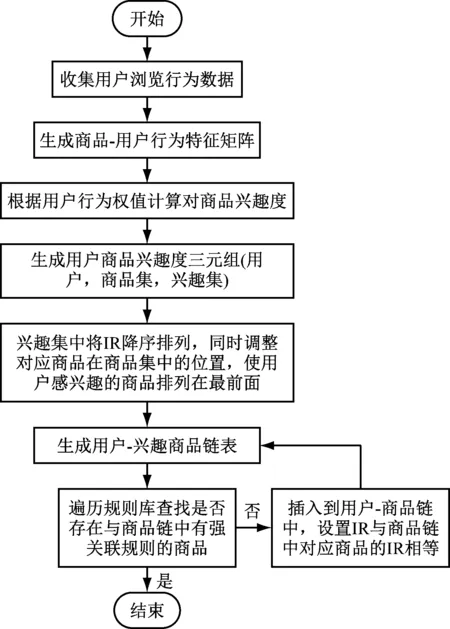
图1 用户兴趣模型构建流程
5 电子商务商品推荐系统设计
5.1 开发环境
数据库:MySQL
编译环境:JDK+Tomcat
开发工具:MyEclipse
开发语言:Java、JavaScript、MySQL
5.2 总体设计
基于关联规则算法,本文将电子商务商品推荐系统功能划分为数据采集及清洗、用户兴趣分析、构建关联规则库、TOP-N推荐4个部分,整体架构设计如图2所示。
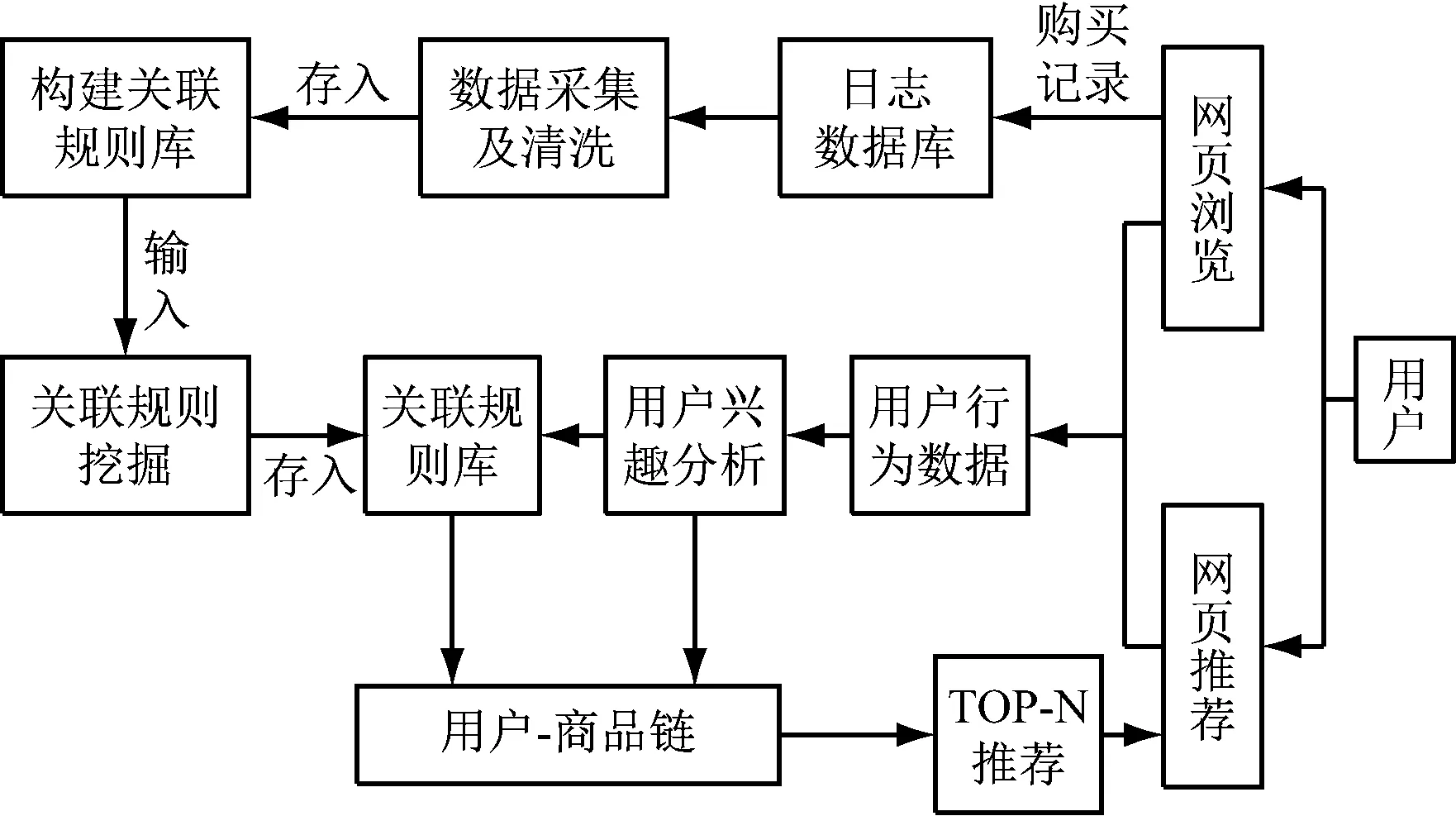
图2 系统整体架构图
(1) 数据采集及清洗模块:数据采集包括两类数据,一类是已购买记录,一类是各种商务行为数据。这两类数据是关联规则挖掘以及用户兴趣度分析的基础。另一方面,由于原始数据包含很多杂乱、模糊、残缺的脏数据,为提升挖掘效率需要对原始数据进行清洗,通过检测空订单、检测交易记录中商品是否存在,剔除交易记录中无关字段等方法对数据完成简化处理[7-8]。
(2) 用户兴趣分析模块:负责建立和更新兴趣模型,前台自动获取用户行为,存于相应数据库表,按照前文阐述的计算兴趣度算法构建用户-兴趣商品链。与关联规则库联合,查找强关联商品,作为TOP-N推荐模块的输入。
(3) 构建关联规则库模块:采用前文介绍的CTE-MARM算法根据具体需求来挖掘指定层次间的关联,约束层次k的值设置为2,针对事务交易表按置信度高低挖掘出规则存于规则表。
(4) TOP-N推荐模块:在关联规则库中查询与用户兴趣模型中存在强关联关系的商品进行网页可视化展示。
5.3 数据库设计
鉴于电子商务商品推荐系统的行为分析及商品推荐功能,构建数据库E-R模型,如图3所示。
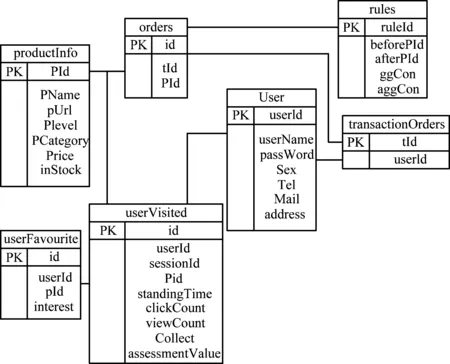
图3 数据库E-R图
其中,核心数据库表如下。
(1) 用户信息表user:主要包括用户ID、注册名称、密码、性别、联系方式、地址。
(2) 商品信息表productInfo:主要包括商品ID、名称、链接、层次、类别、价格、库存。
(3) 事务交易表transactionOrders:主要包括事务交易ID、用户ID。
(4) 购物记录表orders:主要包括唯一标识ID、事务交易ID、商品ID。
(5) 用户行为表userVisited:主要包括唯一标识ID、用户ID、商品ID、点击次数、重复访问次数、浏览时间、是否收藏、评价得分。
(6) 关联规则表rules:主要包括唯一标识ID、规则前件商品ID、规则后件商品ID、商品间置信度、类别与商品间置信度。
(7) 用户兴趣表userFavourite:主要包括唯一标识ID、用户ID、商品ID、兴趣度。
6 系统测试与验证
为验证本文构建模型及推荐商品的准确性,将3 000个用户的购买信息作为测试数据,通过人工统计的结果、人工分析的用户习惯以及系统计算结果进行对比,每测试一次后,将数据重新交叉组合,共测试5次,得到结果如图4所示。
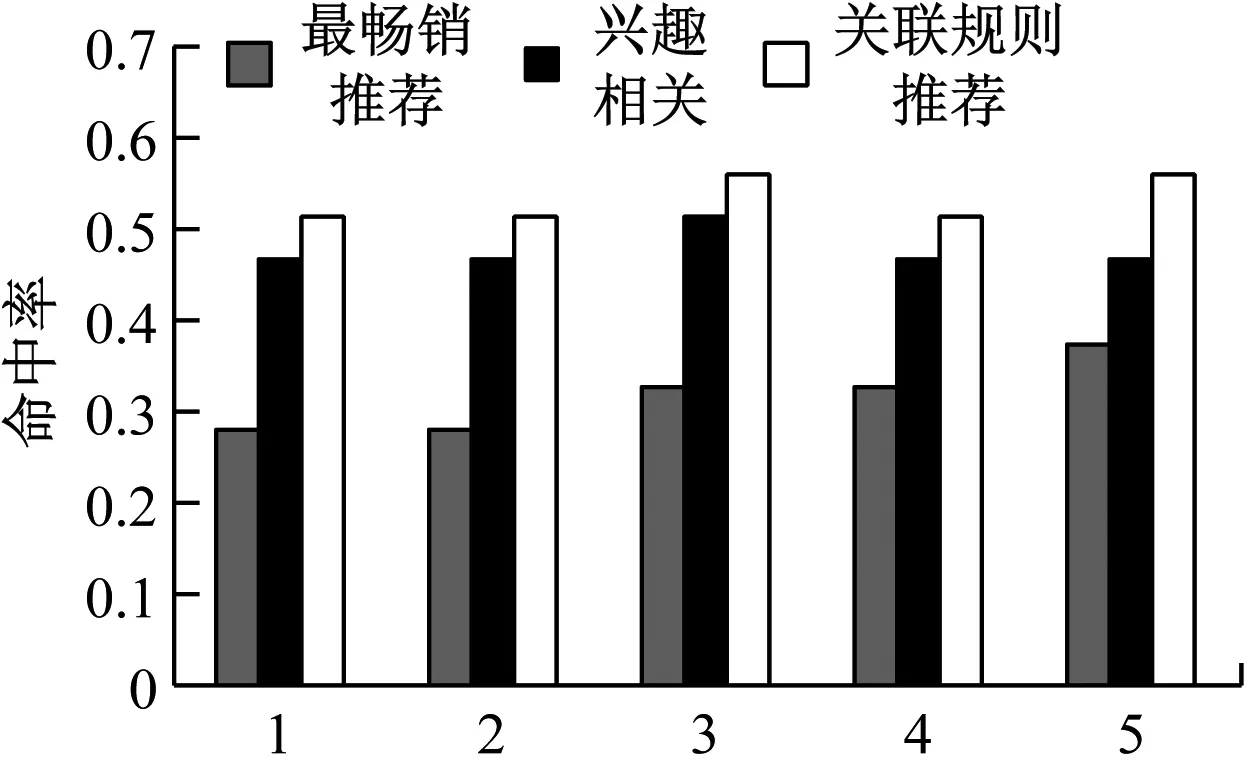
图4 人工分析与系统算法结果命中率分析
结果表明,人工分析的最畅销商品命中率为31.8%,人工分析用户兴趣推荐的命中率为51.1%,而基于关联规则算法构建的电子商务商品推荐系统推荐的商品命中率为55.8%,相对来说系统算法更为有效,命中率比较高,符合最初设计预期[9]。
7 总结
本文利用优化改进的CTE-MARM算法提升挖掘效率,构建关联规则库,并通过用户兴趣模型实现用户-兴趣商品链分析,两者联合起来为用户提供TOP-N商品推荐,经验证具有较高实用性。但在多层关联挖掘算法优化方面还需进一步探索,在商品推荐命中率提升方面还需要考虑更多的影响因素与技术手段。
